Simple Talk Editor in Security, Privacy & Compliance In 2026, engineering teams are quietly accepting more risk. Here’s why 11 takeaways from the Simple Talk podcast on security vs speed in databases: why teams misjudge risk, how AI amplifies... 17 May 2026 4 min read 22
Lukas Vileikis in PostgreSQL PostgreSQL is removing MD5 authentication for passwords. Here’s what it means for your databases PostgreSQL is phasing out MD5 authentication across versions 18–21, replacing it with SCRAM-SHA-256. Here's what it means for your database... 15 May 2026 7 min read 3
Dejan Lukić in Security, Privacy & Compliance How to build a privacy-aware analytics layer with SQL (4 top techniques) Learn how to build privacy-aware analytics with SQL using masking, aggregation, and pseudonymization. Stay GDPR-compliant without exposing PII.… 13 May 2026 11 min read 21
Grant Fritchey in Databases Why database ownership is so fragmented in 2026 – and what you can do about it Learn why database ownership is so fragmented in 2026 - and how best to overcome this challenge, with proven methods... 12 May 2026 7 min read 1
Pat Wright in Cloud How to ensure success following a cloud migration Learn how to optimize performance, reduce costs, improve security, and ensure long-term success after moving from on-prem to the cloud.… 11 May 2026 5 min read 11
Lukas Vileikis in Databases Why COALESCE might be the most useful SQL function you’re not using right Learn how the SQL COALESCE function works, with practical examples for handling NULL values, setting defaults, and writing cleaner, more... 07 May 2026 7 min read 31
Pat Wright in Cloud How to ensure successful deployment of a cloud migration Practical cloud migration go-live tips: planning, team readiness, rollback strategy, testing, and post-migration checks for a smooth deployment.… 06 May 2026 3 min read 11
Greg Low in SQL Server What are managed identities in SQL Server 2025? A complete guide Learn how managed identities in SQL Server 2025 enhance security by eliminating passwords and enabling seamless Microsoft Entra authentication for... 05 May 2026 6 min read 1
Pat Wright in Databases How to utilize testing to ensure a successful cloud migration Learn how to ensure successful migrations by testing applications, tracking bandwidth, and fixing issues before going live.… 04 May 2026 3 min read 1
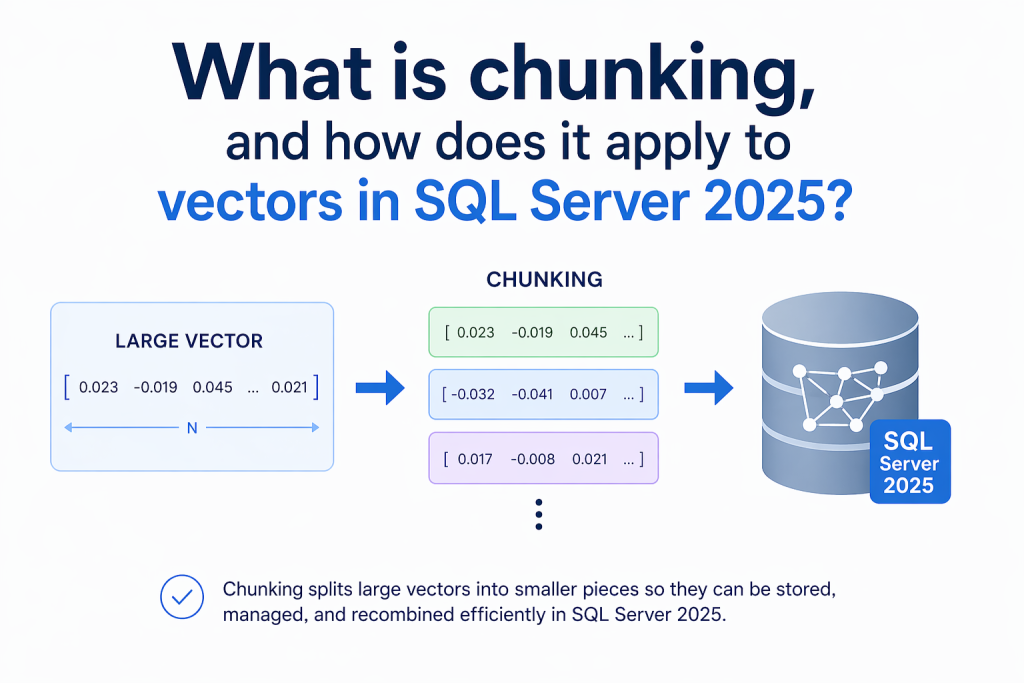
Greg Low in SQL Server What is chunking, and how does it apply to vectors in SQL Server 2025? Learn what chunking is, why it matters for embeddings, and how SQL Server 2025 enables efficient AI-powered vector search.… 01 May 2026 7 min read 22
Pat Wright in Cloud Why over-communication is critical to the success of a cloud migration Cloud migration success depends on clear, consistent communication. Learn how dashboards, targeted updates, and regular check-ins keep teams aligned and... 30 April 2026 3 min read 21
Lee Asher in PostgreSQL What is fillfactor in PostgreSQL – and when should you adjust it? Learn how to optimize PostgreSQL performance with fillfactor - including how it affects HOT updates, indexing, and update-heavy workloads.… 29 April 2026 7 min read 51
Simple Talk Editor in Databases What are the top database platforms in 2026? A look at the latest data Explore 2026 database market trends: AWS, Microsoft, Oracle, and Google Cloud Platform remain dominant as MongoDB, Snowflake, and Databricks steadily... 28 April 2026 6 min read 4
Chisom Kanu in AI Vibe coding and databases: the hidden risks of AI-generated database code Explore how Andrej Karpathy’s “vibe coding” trend reached databases. Uncover risks, real incidents, and 5 critical failure patterns in AI-generated... 27 April 2026 15 min read 3
Pat Wright in Databases What should you move first in a cloud migration? 5 key guidelines Learn how to choose which application to move first in a cloud migration with five practical guidelines covering risk, impact,... 24 April 2026 3 min read 2
Animesh Goyal in AI When, and when not, to use LLMs in your data pipeline “Let’s add LLMs to the pipeline” has become a familiar refrain in modern data teams, but turning that idea into... 16 April 2026 10 min read 51
Greg Low in SQL Server Can SQL Server 2025’s REGEXP_SPLIT_TO_TABLE fix STRING_SPLIT in T-SQL? Learn how to split strings efficiently in T-SQL using STRING_SPLIT and the REGEXP_SPLIT_TO_TABLE function in SQL Server 2025. Discover limitations,... 15 April 2026 5 min read 1
Fabiano Amorim in SQL Server Cross-database ownership chaining in SQL Server: security risks, behavior, and privilege escalation explained Learn how cross-database ownership chaining works in SQL Server, how permissions are evaluated, and why it can introduce security risks... 13 April 2026 12 min read 2
Lukas Vileikis in Security, Privacy & Compliance Everything you need to know about MongoBleed (CVE-2025-14847) Learn what MongoBleed (CVE-2025-14847) is, how the vulnerability leaks MongoDB server memory, which versions are affected, and how to protect... 08 April 2026 6 min read 11
Pat Wright in Cloud How to minimize downtime in a cloud migration Plan cloud migration with minimal downtime. Learn key cutover strategies, testing methods, and critical questions to avoid data loss and... 03 April 2026 3 min read 2