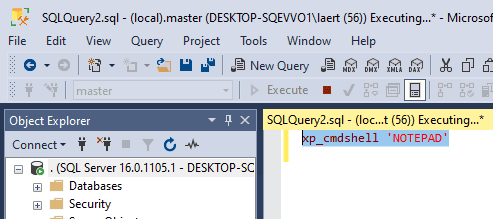
Laerte Junior in Sysadmin SQL Server 2022 on Ubuntu 24.04 step by step Microsoft does not yet support this edition of Ubuntu, but there are some workarounds to make it work. This should... 20 May 2025 5 min read 211
Laerte Junior in PowerShell Fun with PowerShell Asynchronous Imagine a candle that is lit and takes 1 hour to burn out. Now imagine one hundred candles. How many... 03 February 2025 7 min read 532
Grant Fritchey in Other What Did AI Ever Do for Me? Let me start with a simple confession, and I hope it’s not too shocking for anyone; I’m old. When I... 09 September 2024 3 min read 2
Phil Factor in General Storing and Retrieving the Initialization and Configuration Data for Applications All developers hit the problem of how and where to store and set their configuration, profile, or initial data. A... 05 September 2024 14 min read 21
Laerte Junior in PowerShell PowerShell Proxy Functions: Extend Any Cmdlet Without Modifying It PowerShell proxy functions let you extend or modify any existing cmdlet without changing its source - add new parameters, change... 01 July 2024 9 min read
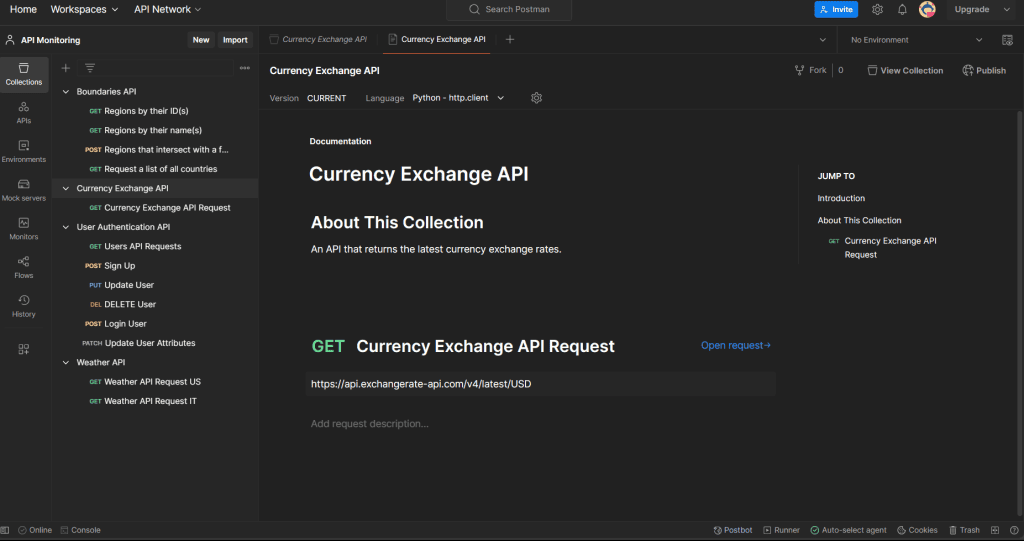
Chisom Kanu in General API Monitoring- Key Metrics and Best Practices Have you ever wondered how your favorite apps seem to do everything automatically, communicate with each other so smoothly, and... 14 June 2024 21 min read
PowerShell Laerte Junior in PowerShell Automating BCP with PowerShell I was talking with a good friend that has an environment with terabytes of information and to create a homolog... 09 February 2024 8 min read
PowerShell Laerte Junior in PowerShell PowerShell Dynamic Parameters and SQL Server Have you ever been in a situation that you want to call a cmdlet or a function with a parameter... 05 January 2024 6 min read
General Goodness Woke in General Applying Agile Principles to IT Incident Management Agile development has grown in popularity in recent years due to its success in delivering software on time and on... 24 August 2023 13 min read
PowerShell Greg Moore in PowerShell Working with PowerShell strings Knowing how to manipulate strings is critical in any language. In this article, Greg Moore explains working with PowerShell strings.… 24 November 2021 12 min read
PowerShell Greg Moore in PowerShell Building an ETL with PowerShell There are many ways to load data into a SQL Server database. In this article, Greg Moore demonstrates how to... 22 September 2021 11 min read
PowerShell Greg Moore in PowerShell PowerShell editors and environments part 2 In this article, Greg Moore demonstrates two additional PowerShell editors: Azure Data Studio Notebooks and Visual Studio Code.… 15 March 2021 12 min read
PowerShell Greg Moore in PowerShell PowerShell editors and environments part 1 There is no shortage of PowerShell editors and environments for developing and running scripts. Greg Moore explains some of his... 02 February 2021 11 min read
PowerShell Greg Moore in PowerShell How to Use Parameters in PowerShell Part II PowerShell is a basic skill any administrator working in Windows or Azure should know. After writing his first article about... 18 August 2020 17 min read
PowerShell Greg Moore in PowerShell How to Add Help to PowerShell Scripts PowerShell scripts are the tool of choice for many admins, but how do you make them easy for others to... 13 May 2020 12 min read
PowerShell Greg Moore in PowerShell SQL Server and Undocumented Extended Procedures Smart DBAs automate tasks whenever possible. In this article, Greg Moore shows the need to use caution when using undocumented... 03 March 2020 11 min read
PowerShell Greg Moore in PowerShell Comments and More in PowerShell Comments are helpful when programming in any language, and PowerShell is no exception. In this article, Greg Moore demonstrates how... 03 January 2020 12 min read
PowerShell Allen White in PowerShell Serialising PowerShell Objects with Export-CLIXML and Import-CLIXML: Portable Object Storage for Scripts and Pipelines Using Export-CLIXML and Import-CLIXML to serialise PowerShell objects to portable XML format - persisting complex objects across script runs, passing... 17 December 2019 17 min read
PowerShell Greg Moore in PowerShell PowerShell Countdown Timer: Build a Windows Forms GUI Timer Build a PowerShell countdown timer using Windows Forms and .NET. Starts with a simple timer form, adds start/stop/reset controls, and... 03 December 2019 12 min read
PowerShell Greg Moore in PowerShell PowerShell Parameters: A Practical Guide Learn to define and use parameters in PowerShell scripts with the Param() block. Covers mandatory parameters, default values, data types,... 17 September 2019 12 min read