
Recently a customer asked me to work on a pretty typical project to build a process to import several CSV files into new tables in SQL Server. Setting up a PowerShell script to import the tables is a fairly simple process. However, it can be tedious, especially if the files have different formats. In this article, I will show you how building an ETL with PowerShell can save some time.
Typically a project like this is broken into two parts: write the PowerShell code to read the CSV file and insert the data into the appropriate table and writing the SQL Schema (and possibly stored procedure) to hold the data.
First, I want to note that this is far from the only way to handle this process. In some cases, writing this in an SSIS package or other third-party tool may be better. Also, if you deal with very large data files, there are faster ways of handling the data.
The Problem
I’ll be honest. I find the process of building an ETL for a CSV file to be tedious. There’s nothing super hard about it, but one has to be attentive to details such as the name of the columns, what delimiters are used, and how quotes, both single and double, are used. I may craft everything by hand if I have just one or two files to import.
In my most recent case, though, I had to import approximately two dozen files. After doing one or two by hand, I finally gave in and decided to leverage some code to semi-automate the process. That said, this code is a work in progress (and is available on Github) and is far from a complete solution. Doing it this way decreased my time to write the code and schema to import a file from 10-15 minutes to under 2 minutes.
CSV Files
I’ll start by stating the obvious: for a so-called standard, CSV files often vary in format. The two most significant variances tend to be how a value is defined and how it’s separated. Generally, two values are separated by a comma, hence the name Comma Separated Values. Instead, you may often see a file that has a CSV extension with values separated by a semicolon ; or a vertical bar | or another character. One could argue these aren’t technically CSV files, but given they often share the same extension of either .csv or .txt, I’ll consider them CSV files.
Sometimes the files can get very complicated. Often when data is exported to a CSV file, it may contain numbers or other values that have embedded commas. The value in the source may be $12,689.00 and get exported exactly like that, complete with the comma, and it may or may not include the $. However, if it is exported with the comma, it’s important not to read that as two separate values, one with a value of $12 and the other with a value of 689.00.
A common solution is to encapsulate values with a delimiter such as single quotes ‘ or double quotes “. These can help, but single quotes, in particular, can cause problems when you have names such as O ‘Brian. Does that get exported as ‘O’Brian’ or ‘O”Brian’ or even ‘O”’Brian’? The middle one may seem nonsensical to some, but doubling the ‘ is a common way to escape the quote in SQL. For others, though, that may cause additional parsing problems, so it ends up being doubly escaped. Of course, then one has trouble parsing that and wonders if it really should be two fields, but the comma was missed.
There’s a final complication that I have often found. Above the assumptions are that the data is valid and makes sense but is simply a bit complicated. But what happens when a text field is being exported, and the original field has data that might be considered weird but exists. For example, I’ve never seen the name O, ‘Neill in the real world, or an address of 4,230 “Main Street, Everytown, ‘USA, but I can assure you, you’ll eventually come across a CSV file that has a similar address exported, and it’ll mess everything up.
This discussion is not meant to be a primer on CSV files but a warning that any solution to automate their import will have to deal with many messy edge conditions and often simply bad data. This means my solution below is far from perfect, and you will most likely have to adapt it to your specific needs. If you feel so inclined, I welcome additions to the script in Github.
Create Some Data
Before continuing, you will need some fake data. Create a text file called User_Database.csv and add the following (or download it from Github):
“First_Name”,”Last_Name”,”City”,”Payment”,”Payment_Date”,”Notes”
“Bruce”,”Wayne”,”Gotham”,”1,212.09″,”3/12/2021″,”Is a millionaire who’s into bats.”
“Clark”,”Kent,Metropolis,”310.56″,”2/10/1999″,”Newspaper reporter who wears fake glasses.”
“Diana”,”Prince”,”DC”,”$1,947.22″,”8/8/2015″,”Has her own plane, she claims. No one’s seen it.”
“Hal”,”Jordan,Coast City,”$1,967.10″,”6/12/2020″,”Likes pretty jewelry”
“Oliver”,”Queen”,”Star City”,,”6/13/2020″,”Rich dude with an arrow fetish”
There is a typo or two in there as well as various other possible issues that might need to be dealt with.
Next Steps
Imagine you’ve been tasked with importing the above file into SQL Server on a daily basis. If it were just this one file, you most likely would create the SQL Server table by hand and then perhaps write up a PowerShell script to read the data and insert it into the database. If you’re proficient, it might take you no more than 30 minutes. As I mentioned above, however, often the case isn’t importing a single file type; you might be charged with importing a dozen or two different types of files. Creating the tables and ETL scripts for this could take a day or more.
Before you can import the data from the file, you need to create the table.
If I’m working with a single table, I’d create the script for this table by hand, and it would look something similar to the following:
|
1 2 3 4 5 6 7 8 9 |
Create Table Users_By_Hand ( First_Name nvarchar(100), Last_name nvarchar(100), City nvarchar(100), Payment Decimal(10,3), Payment_Date Date, Notes nvarchar(max) ) |
This script didn’t take long to create, less than 5 minutes, and it’s exactly what I want in this case. Again, if I’m writing an ETL for 20 or 30 or more different files, that time adds up. Because I’m a fan of stored procedures over direct write access to tables, I still have to write the stored procedure to insert data.
This time I will take a different approach and use the source file itself to help me do my work. Create the following script and call it Create-SQL_Table.ps1 replacing the file location.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
$object = "Users" $filename = "User_Database.csv" $first_line = get-content P:\$filename -First 1 $fields = $first_line.split(",").Replace('"','') $table = "Create Table $object`_by_PowerShell ( " foreach ($field in $fields) { $table += " $field nvarchar(100) " } $table += ")" write-host $table |
When you execute it, you will see that it has built a script for table creation with the following format:

If you wanted to, you could add an invoke-sqlcmd and cause the table to be created automatically. I don’t recommend this because it’s not exactly the same as the handcrafted table, but with a few minor edits, you can make this the same as the handcrafted table.
It doesn’t take much of a leap to imagine how one could wrap the above script in a foreach loop and have it create a table script for every file in a directory. Before you do that, I want to expand this script, making it a bit more useful and to clean up the code.
Save the following script as Create-SQL_from_csv.ps1.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 |
$object = "Users" $filename = "User_Database.csv" $first_line = get-content P:\$filename -First 1 $fields = $first_line.split(",").Replace('"','') function create-Sql_table($object, $fields) { $table = "Create Table $object`_by_PowerShell ( " foreach ($field in $fields) { $table += " $field nvarchar(100) " } $table += ")" return $table } function create-Sql_Insert_Procedure($object, $fields) { $procedure = "Create or Alter Procedure Insert_$object " foreach ($field in $fields) { $procedure += "@$field nvarchar(100)`, " } $procedure = $procedure.TrimEnd(", ") $procedure += " AS Insert into $object (" foreach ($field in $fields) { $procedure += "$field`, " } $procedure = $procedure.TrimEnd(", ") + ") values (" foreach ($field in $fields) { $procedure += "@$field` , " } $procedure = $procedure.TrimEnd(" , ") + ")" return $procedure } $createdTable = create-Sql_table -object $object -fields $fields $createdProcedure = create-Sql_Insert_Procedure -object $object -fields $fields Write-Host $createdTable write-host $createdProcedure |
Notice that I’ve added code to create the stored procedure and moved it and the previous code into functions. This makes the code a bit more readable and easier to edit and update.
When you run this, it will create the same table as before, but it will also create a stored procedure that looks like below:
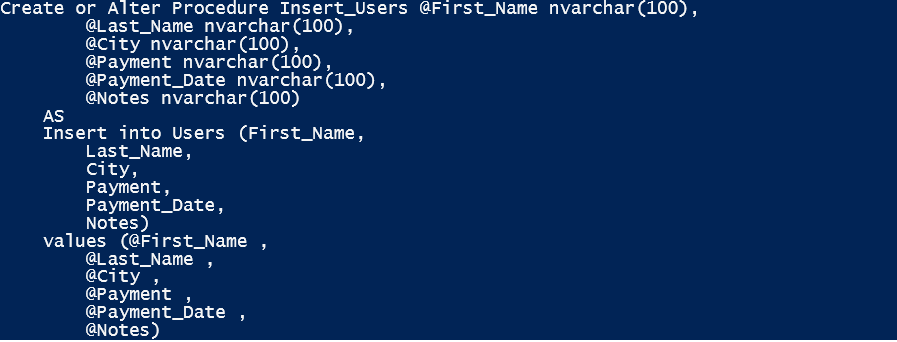
Once again, you may need to edit details, such as the datatypes and sizes, but those are minor edits compared to creating the stored procedure from scratch.
If you need other stored procedures, for example, one to select data or another to update or delete data, you can script out the stored procedures in a similar manner. Note that these will require you to hand-edit them as your primary key will no doubt change from file to file, so it’s harder to write a generic set of procedures for this.
The above code handles creating the SQL side, but you still need to import the data into the table. A common method I use to handle data like this is to create a PowerShell Object and then read in a row of data into the object and then insert that. Note that this is flexible but far from the fastest way of doing things. That said, it does allow me to leverage the stored procedure.
For this step, add the following function to the above script and save it as Create-SQL_and_PS_from_csv.ps1.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
function create-PS_Object($Object, $fields) { $objectcreate = "$object = New-Object -TypeName psobject " foreach($field in $fields) { $field = $field.trim('"') $objectcreate += "$object_name | Add-Member -MemberType NoteProperty -name $($field.replace(' ','_')) -Value $("`$"+$object).'$($field)'.Replace(""'"",""''"") " } return $objectcreate } |
And then below the line: $createdProcedure = create-Sql_Insert_Procedure -object $object -fields $fields
add $createdPS_Object = create-PS_Object -object $object -fields $fields
This will create the code to create a new PowerShell Object. Notice that there’s some extra code appended to the end of each line which handles cases where a field may include a single quote, such as O’Brian or, in the above data the field: “Has her own plane, she claims. No one’s seen it.” You can add further Replace expressions as required to fit your data.
When this script runs, you will now have all the pieces available to cut and paste into scripts to create the necessary SQL scripts and to create the necessary PowerShell Object. It should look similar to below:
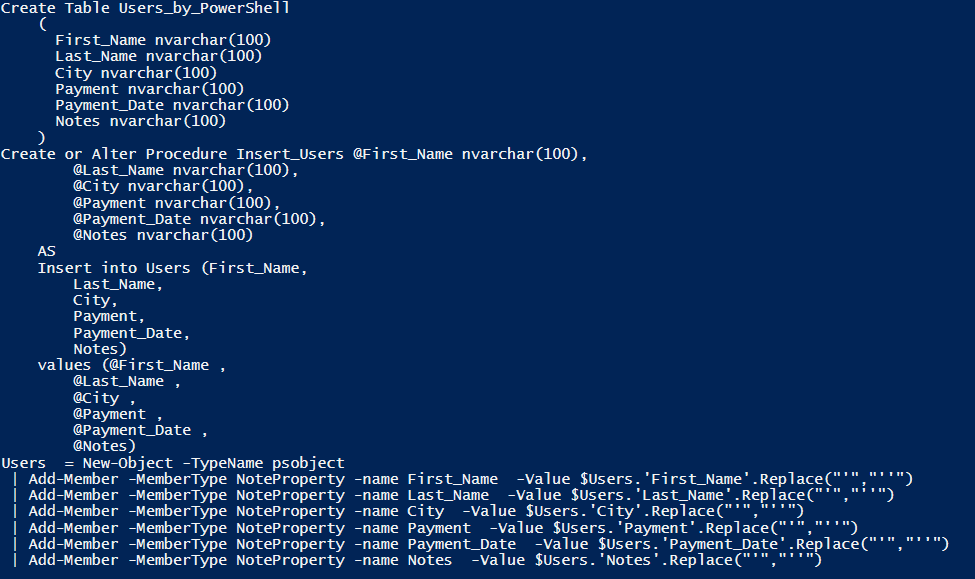
However, I think this is a bit hard to read. At Github there is a final version of this script called: Create-SQL_and_PS_from_csv_Final.ps1.
This adds some simple formatting for the output and also prompts for the name of the CSV file. Running this on the test file looks like this:
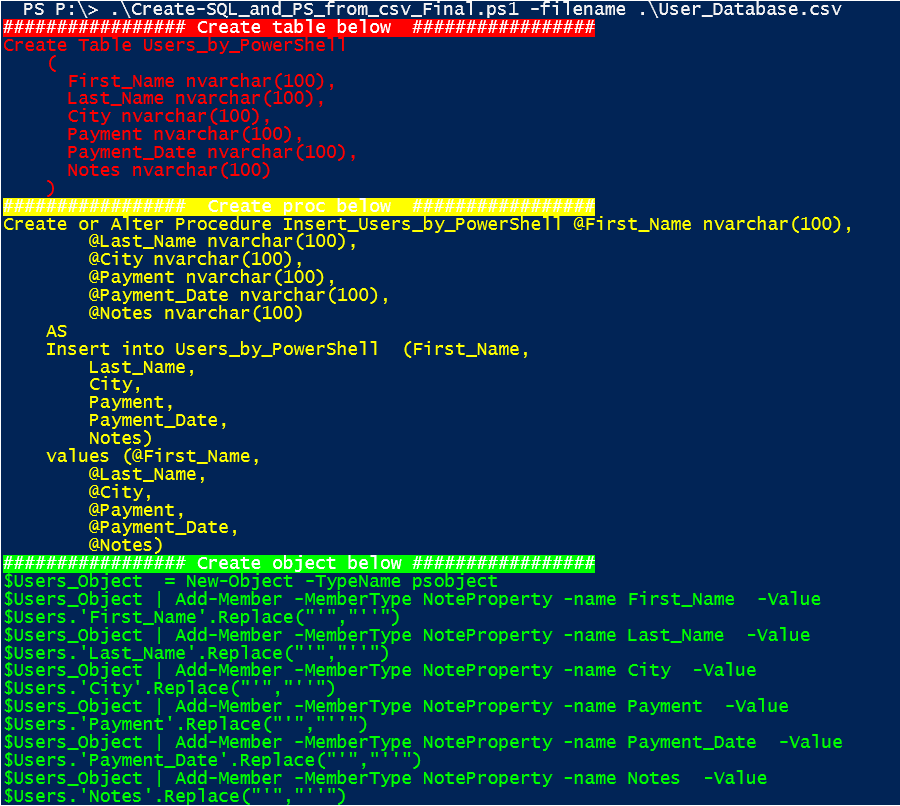
As you can see now, each of the objects the file creates are clearly color coded and easier to cut and paste as needed.
Conclusion
This sort of script is ripe for customization for your specific needs and can be expanded as required (for example, perhaps creating a deletion sproc as part of it.)
The value is not for setting up ETL for a single file but for when you have a dozen or more and want to automate much of that. With enough effort, a script such as this could do all the work for you. However, before you reinvent the wheel, I would also recommend checking out the dbatools cmdlet Import-DbaCSV. It may do much of what you need. In the meantime, happy importing!
If you like this article, you might also like How to Use Parameters in PowerShell Part I – Simple Talk (red-gate.com)
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments