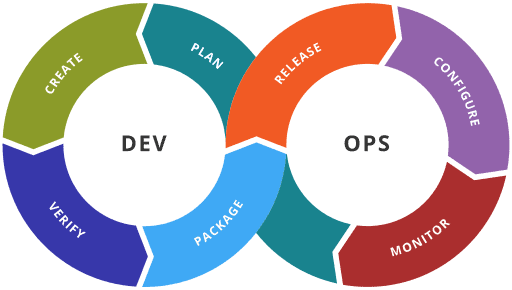
Bravin Wasike in DevOps DevOps anti-patterns: what they are and how to avoid them Learn the top DevOps anti-patterns, their risks, and how to avoid them to improve CI/CD, collaboration, automation, and deployment reliability.… 19 March 2026 13 min read 21
Database DevOps Robert Sheldon in Database DevOps Sharing knowledge in communities of practice Communities of practice bring people together to share ideas and learn from each other about a common interest. In this... 16 August 2021 12 min read
Editorials Kathi Kellenberger in Editorials How different roles view database DevOps Redgate released the 2021 State of Database DevOps Report in February, and I wrote a short article talking about the... 20 April 2021 4 min read
Editorials Kathi Kellenberger in Editorials Key insights from the 2021 State of Database DevOps survey This is the fifth year that Redgate has surveyed IT professionals about their organization’s DevOps practices. Each year, the number... 15 February 2021 4 min read
Database DevOps Mike Cuppett in Database DevOps Recruiting DBAs for DevOps DBAs are in great demand, but what if you are recruiting a DBA for DevOps? Mike Cuppett explains how to... 04 February 2021 10 min read
Database DevOps Carlos Robles in Database DevOps Database version control: Getting started with Flyway Flyway is a multi-platform, cross-database version control tool. Carlos Robles explains Flyway’s history and shows how it works.… 06 January 2021 14 min read
Culture Robert Sheldon in Culture Ten tips for attracting and retaining DevOps talent To stay competitive and bring value to customers, organisations are adopting DevOps, but finding people experienced in DevOps can be... 07 December 2020 10 min read
Database DevOps Kendra Little in Database DevOps Feature branches and pull requests with Git to manage conflicts Feature branching and pull requests are two important concepts when using Git. In this article, Kendra Little explains these patterns... 07 December 2020 14 min read
Editorials Kendra Little in Editorials Three ways that taking the State of Database DevOps Survey helps the community Redgate has recently opened the 2021 State of Database DevOps Survey. Whether or not your organization does DevOps, I would... 16 November 2020 2 min read
Database DevOps Robert Sheldon in Database DevOps 10 DevOps strategies for working with legacy databases The database is often left behind as organisations embrace DevOps. In this article, Robert Sheldon explains how to successfully bring... 29 October 2020 11 min read
Kendra Little in Editorials Why database folks should care about User Research I attended a training session at Redgate this week by Chris Spalton. Chris’ session topic was “An Introduction into Planning... 27 October 2020 4 min read
Database DevOps Grant Fritchey in Database DevOps What is database continuous integration? Have you ever longed for a way of making the delivery of databases more visible, predictable and measurable? Do you... 07 October 2020 9 min read
Database DevOps Kendra Little in Database DevOps The Two Ways Containers Will Revolutionize Database DevOps Containers have already transformed the way application development works, but adoption has been slower for databases. Finally, the revolution is... 17 August 2020 8 min read
Grant Fritchey Database Lifecycle Management: Deployment and Release Grant Fritchey covers database lifecycle management. So often, the unexpected delays in delivering database code are more likely to happen... 20 June 2020 35 min read
Database Administration Robert Cain in Database Administration How to Create an Ubuntu PowerShell Development Environment – Part 3 Running SQL Server in a container may seem daunting at first, but it’s easy once you understand the handful of... 28 May 2020 20 min read
Database DevOps Phil Factor in Database DevOps How to Document SQL Server Tables with PowerShell & Extended Properties Use PowerShell to parse SQL Server table DDL scripts, extract comments and column descriptions, and store them as extended properties.... 16 April 2020 24 min read
Editorials Kathi Kellenberger in Editorials DevOps is Essential for Analytics The term DevOps was coined in the early 2000s to improve the speed and resiliency of the delivery of features... 20 March 2020 3 min read
Database DevOps William Brewer in Database DevOps The Staging Phase of Deployment Despite some humorous examples of deployments gone wrong, failures are not funny. William Brewer explains why staging is so important... 17 March 2020 12 min read
Database DevOps Phil Factor in Database DevOps But the Database Worked in Development! Checking for Duplicates As developers should not have access to production data, it’s possible that duplicate values can sneak in during migrations. In... 10 February 2020 13 min read
Editorials Kathi Kellenberger in Editorials Key Findings from the 2020 Database DevOps Survey Each year Redgate Software runs a survey to learn more about how organizations practice DevOps, especially when it relates to... 04 February 2020 3 min read