
“Database migrations made easy” and “Version control for your database” are a couple of headlines you will find on Flyway’s official website. And let me tell you this, those statements are absolutely correct. Flyway is a multi-platform, cross-database version control tool with over 20 supported databases.
From all my years of experience working as an Architect for monolith and cloud-native apps, Flyway is by far the easiest and best tool on the market to manage database migrations.
Whether you are an experienced data professional or starting to get involved in the world of data, this article is the foundation of a series that will get you through this fantastic journey of database migrations with Flyway.
Background history
Flyway was created by Axel Fontaine in early 2010 at Google Code under the Apache 2.0 license. According to Axel’s words, it all started when he searched for a tool that allows integrating application and database changes easily and simply using plain SQL. To his surprise, that kind of tool didn’t exist, and it makes total sense to me because there were not many options back at that time.
Just to get you in context of what I’m talking about in the previous paragraph, everything we know as DevOps today was conceived around 2009. David Farley and Jez Humble released the recognized “Continuous delivery” book in 2010. Therefore, Axel was, without question, a pioneer in deciding to write his own tool to solve this widespread software development problem: Make database changes part of the software deployment process.
Flyway acceptance was great among the developer community, leading to high-speed growth and evolution. For example, the list of supported databases grew, additional support to multiple operating systems was added, and many more features were included from version to version.
The next step in Flyway’s evolution was Pro and Enterprise editions’ launch back in December 2017, which was a smart decision to secure the project’s progression and viability. Without question, Flyway was already the industry-leading standard for database migrations at that time.
Around mid-2019, Redgate Software acquired Flyway from Axel Fontaine. Redgate’s expertise in the database tooling space opens the door to Flyway for new opportunities in expansion, adoption, and once more evolution!
Database migrations
You are probably already familiar with the term Database migration which can mean several different things within the context of enterprise applications. It could mean to move a database from one platform to another or move a database from a previous version of the DBMS engine to the most recent one. Another common scenario these days is moving a database from an on-premises environment to a cloud IaaS, PaaS solution.
This article is not related to any of these practices mentioned above. This article will get you started with database migrations in the context of schema migrations. Yes, this is another kind of database migration which means the practice of evolving a database schema with incremental, reversible, and consistent changes through a simple approach. This approach enables integrating database changes with version control and application deployment processes.
Before digging deeper into this topic, I would like to address the basic requirements of database migrations. Trust me, this topic is fascinating and full of great information that will help you adopt this practice. Whether you are a software developer, database administrator, or solutions architect, understating database development practices like this is essential to become a better professional.
Evolutionary Database Design is the title of an article published on Martin Fowler’s website in May 2006. It is an extract of the Refactoring databases book by Scott Ambler and Pramod Sadalage, also released in 2006. This lecture goes above and beyond explaining the evolution of database development practices through the years, providing techniques and best practices to embrace database changes in software development projects, especially when adopting agile methodologies.
The approach described in this book sets the stage for a collection of best practices that should be followed to be successful.
DBA and developer collaboration
Software development practices like DevOps demand that people with different skills and backgrounds to collaborate closely, knocking down silos and bottlenecks between multiple teams, like the usual separation between development and operations.
In a database development effort, collaboration is crucial to the success of the project. Developers and DBAs should work in harmony, assessing the impact of the database changes proposed before implementing them. Anybody can take the initiative to start the conversations around whether the database code is optimal, secure, and scalable, or simply to make sure it is following best practices.
Version control
Without question, everybody benefits from using version control. All the artifacts that are part of a software project should be included to keep track of the contributor’s individual changes. Starting from the application code, unit and functional tests, database scripts, and even other code types such as build scripts used to create an environment from scratch, known today as Infrastructure as Code.
All databases changes are migrations
All database changes created during earlier stages of the development phase should be captured, no exception. This approach encourages treating database change files like any other artifact of the application, making sure to save and commit these change files to the same version control repository as the application code to be versioned along together.
Migration scripts should include but are not limited to any modification made to your database schema like DDL (Data definition language) and DML (Data manipulation language) changes or data correction changes implemented to solve a production data problem.
Everybody gets their own instance
It is very common for organizations to have shared database environments. This scenario is often a bad idea due to the imminent risk of project delays caused by unexpected resource contention problems. Or, in other cases, delays are caused by interruptions made by the development team itself. A person working on some database objects modified the objects that were part of a last-minute database schema refactoring.
Everyone learns by experimenting with new things. Having a personal workspace where one can endeavor to explore a creative way to solve a problem is excellent! More importantly, being able to work free of interruptions increase productivity.
Leveraging technologies like Docker containers to create an isolated and personal database development environment/workspace seems like a good way to resolve this issue. Other solutions like Windows Subsystem for Linux (WSL) take this approach to a whole new level, providing an additional operating system on top of the Windows workstation.
Leverage continuous integration
Continuous Integration —CI, for short— is a software development practice that consists of merging all changes from a developer’s workspace copy to a specific software branch.
Best practices recommend that each developer should integrate all changes from their workspace into the version control repository at least once a day.
There is a plethora of tools available to set up a continuous integration process like the one recommended above. The one to choose depends on the size of the organization and budget. The most popular are Jenkins, Circle CI, Travis CI, and GitLab.
According to the theory behind this practice, there are few key characteristics a database migration tool should meet:
- All migrations must have a unique identifier
- All migrations must be recorded in a migration history table
- All migrations should be repeatable and reversible
All these practices and characteristics sound attractive to speed up a database development effort. However, the question is: How and what can we use to approach database migrations easily? Worry no more, Flyway to the rescue!
![]()
What is Flyway?
Flyway’s official documentation describes the tool as an open-source database migration tool that strongly favors simplicity and convention over configuration designed to facilitate continuous integration processes for any database on any platform.
Migrations can be written in plain SQL, of course, as explained at the beginning of this article. This type of migrations must follow the specific syntax rules of each database engine such as PL/pgSQL for PostgreSQL, T-SQL for SQL Server, PL/SQL for Oracle, etc.
Flyway migrations can also be manually executed through its command-line client or programmatically using the Java API, Docker containers, or Maven and Gradle plugins.
It supports more than twenty database engines by default. Whether the database is hosted on-premises or cloud environment, Flyway would not have a problem connecting by leveraging the included JDBC driver library shipped with the tool.
Flyway folder architecture
At the time of this writing (December 2020), Flyway’s latest version is 7.3.2. which has the following directory structure:

* Screenshot is taken from Flyway official documentation
As you can see from the folder structure, it is very straightforward; the documentation is so good that it includes a brief description for some of the folders. Let’s take a look in-depth look and define each one of these folders.
The conf folder is the default location where Flyway will look for the database connectivity configuration. Flyway uses the simple key-value pair approach to set and load specific configurations via the flyway.conf file. I will address the configuration file in detail in future articles; for now, I will stick to this simple definition.
Flyway was written in Java, hence the existence of JRE and lib folders. I strongly recommend leaving those folders alone; any modification to the files within these folders will compromise Flyway’s functionality.
The licenses folder contains the teams, community, and third-party license information in the form of a text file; these three files are available for you if you want to take a look and read all details about each type of license.
The drivers folder is the place where all the JDBC drivers mentioned before can be found in the form of jar files. I believe this folder is worth to be explored in detail to see what is shipped with the tool in terms of database connectivity through JDBC.
I will use my existing Flyway 7.3.2 environment for macOS. I’ll start by verifying my current Flyway version using the flyway -v command:

Good, as you can see, I’m on the 7.3.2 version. This is the same version used from the official documentation screenshot that describes the folder structure. Now, I will find the actual folder where Flyway is installed using the which flyway Linux command:

Using the command tree -d, I can list all folders inside the Flyway installation path:
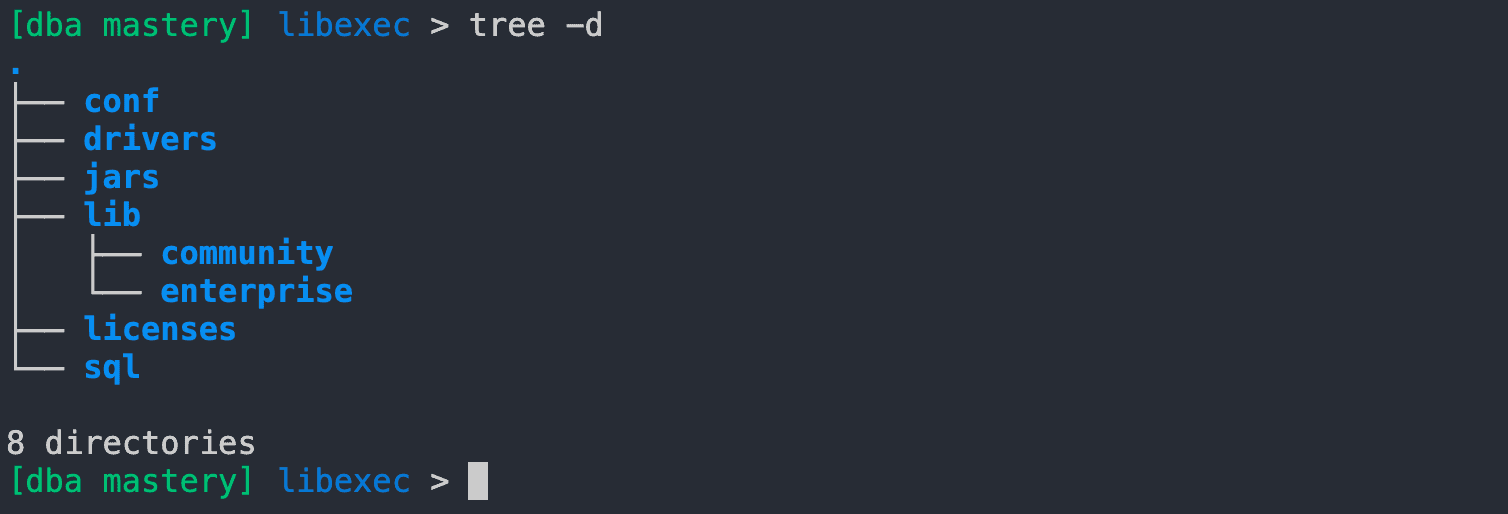
Then I simply have to navigate towards the drivers folder and list all files inside this path using the ls -ll Linux command:
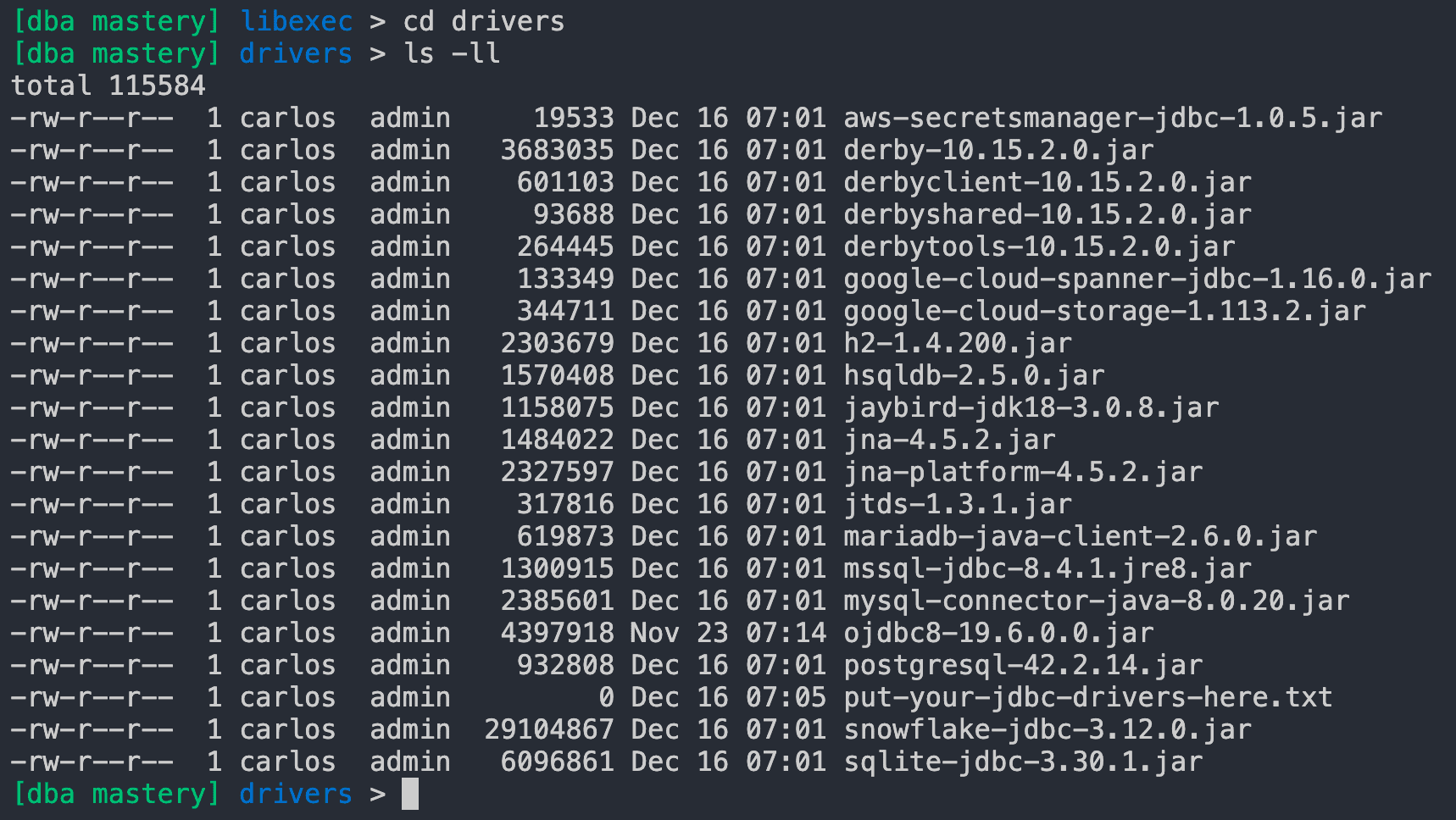
Look at that long list of JDBC drivers in the form of jar files; right of the box, you can connect to the most popular database engines like PostgreSQL, Microsoft SQL Server, SQLite, Snowflake, MySQL, Oracle, and more.
Following the folder structure, there are the jars and sql folders where you want to store your Java or SQL-based migrations. Flyway will look at these folders by default to automatically discover filesystem (SQL scripts) or Classpath (Java) migrations. Of course, these default locations can be overridden at execution time via a config file and environment variables.
Finally, there are the executable files. As you can see, there are two types: One for macOS/Linux (Flyway) based systems and one for Windows (Flyway .cmd) systems.
How it works
Take a look at the following visual example, where there is an application called Shiny Soft and an empty shell database called Shiny DB. Flyway is installed on the developer’s workstation, where a couple of migrations were created to deploy some database changes.
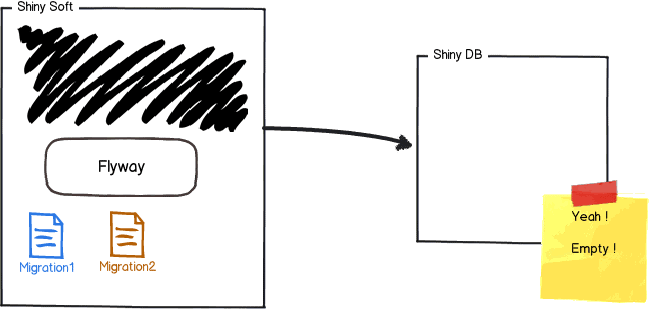
The first thing Flyway will do when starting this project is to check whether the migration history table exists. This example begins the development effort with an empty shell database. Therefore, Flyway will proceed to create the flyway_schema_history table on the target database called Shiny DB.
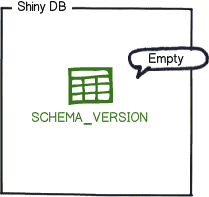
Right after creating the migration history table, Flyway will scan and apply all available migrations on its default location (jars / sql)
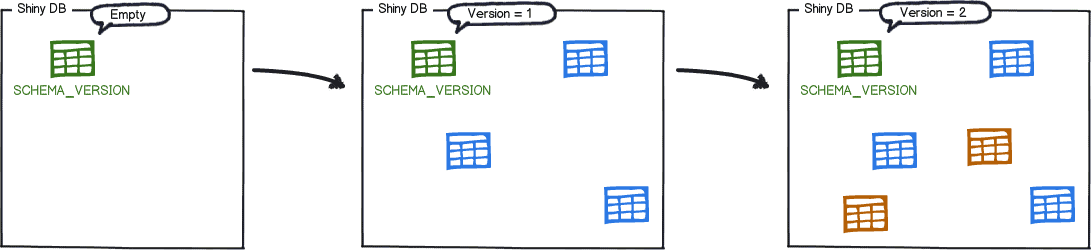
Simultaneously, the flyway_schema_history was updated with two new records, one for each of the migrations available (Migration 1 and 2).
This table will contain a high level of detail that will help you to understand better how the database schema is evolving. Take a look at the following example:

As you can see, there are two entries. Each has a version, description, type of migration, the script used, and more audit information.
This metadata is valuable and crucial to Flyway functionality. Because it helps Flyway keep track of the actual and future version of your database. And yes, Flyway is also capable of identifying those migrations pending to be applied.
Imagine a scenario where Migration 2 needs to be refactored, creating just one table instead of two. What you want to do is to create a new file called Migration 2.1. This migration will include the DDL instructions to drop the two existing tables and create a new one instead.
Flyway will automatically flag and update this new migration as pending in the flyway_schema_history table; however, it will not apply such migration until you decide to do it.
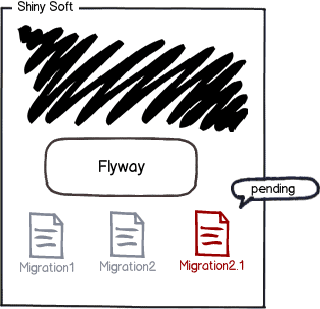
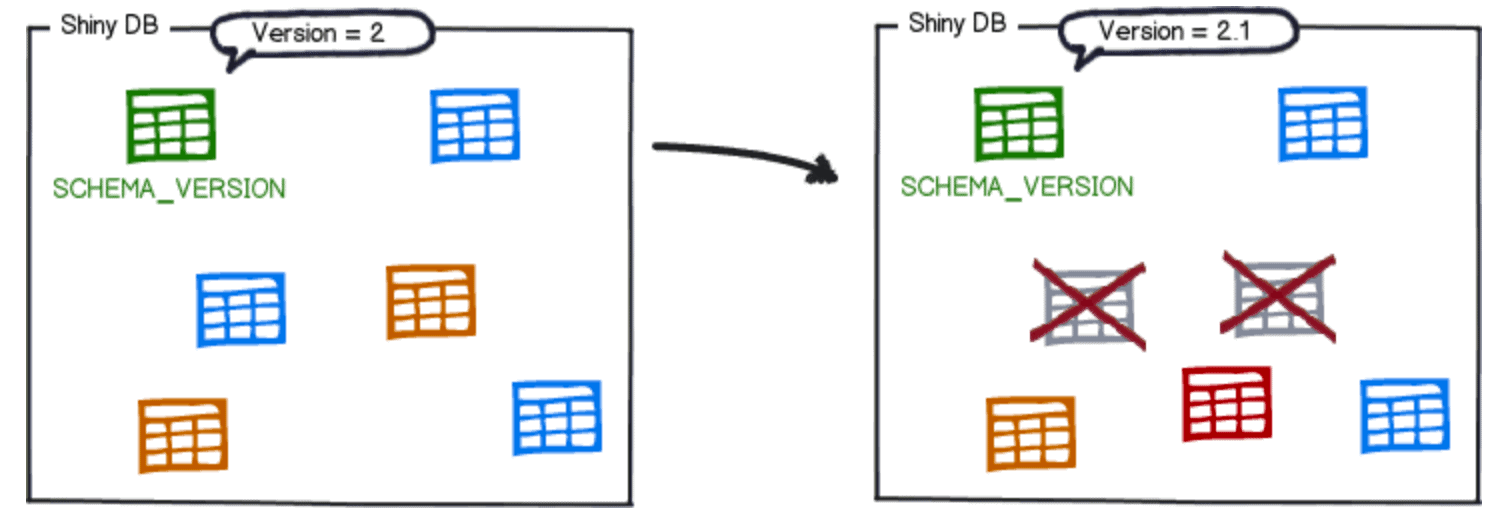
Once Migration 2.1 is applied, Flyway will update the flyway_schema_history table with a new record for the latest migration applied: 
Notice the third record that corresponds to the database version 2.1 is not a SQL script. Hence the type column record shows JDBC; instead, this was a Java API type migration successfully applied to perform a database refactoring change.
Advantages
At this point, you should be a little bit more familiar with Flyway. I briefly described what it is and how it works. Now, stop to think about what advantages you will get, including Flyway as the central component of your database deployment management.
In software development, as with everything you do in life, the longer you take to close the feedback loop, the worse the results are. Evolving a monolithic legacy database, where any database change is performed following the state-based database deployment approach, could be challenging. However, choosing the right tool for the job should make your transition to a migration-based deployment easier and painless.
Embracing database migrations with Flyway could not be easier. Whether you choose to start with SQL script-based migrations or Java classes, the learning curve is relatively small. You can always rely on Flyway’s documentation to check, learn, and get guidance on every single command and functionality shipped with the tool out of the box.
You don’t have to worry about keeping a detailed control of all changes applied to your database for starters. All the information from past and future migrations are held with great detail in Flyway’s schema history table. This is not just a simple control table. What I like about this schema history table is the level of detail about every single migration applied to the database. You will be able to identify the type of migration (SQL, Java), who, when, and exactly what was changed in your database.
Another major paint point solved by Flyway is the database schema mismatch. This is a widespread and painful problem encountered when working with different environments like development, test, QA, and production. Recreating a database from scratch, at the same time specifying the exact schema version you want to deploy, is a powerful thing. A database migration tool like Flyway will ensure to apply all those changes that belong to a specific version of your application. Database changes should be implanted with application changes.
Conclusion
This article provides a foundation and detailed explanation of Evolutionary database design techniques and practices required to approach database migrations with tools like Flyway.
I also included a summary of Flyway as a database migration tool, starting from the early days, explaining why and how this tool was born. It finally explored its folder structure and components and provided a visual and descriptive example of how this tool approaches database migrations with ease.
Please join me in the next article series, focusing on explaining how to install Flyway’s command-line tool for Linux/macOS and Windows. Also, explore all details related to its configuration through config files and environment variables.
If you enjoyed this article, Carlos Robles will present Getting more control over database deployments with Flyway at Redgate Summit on February 18. To learn more from Carlos, register now to secure your free place.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments