
I’ve recently fielded two questions from different customers regarding how to best work as a team committing database changes to Git.
While there are a wide variety of branching models which work well for databases with Git — Release Flow, GitFlow, or environment-specific branching models – almost every successful Git workflow emphasizes two things:
- Using feature branches (also known as topic branches) for the initial development of code
- Using Pull Requests to merge changes from feature branches into a mainline or shared code branch
These two patterns are very common because Git encourages workflows that branch and merge often, even multiple times in a day. (To learn more about branching, read Branching in a Nutshell.)
In other words, Git is a powerful VCS and has very complex functionality at hand. In my experience, becoming familiar with patterns of branching, merging, and conflict resolution have helped make Git’s complexity easier to understand and have helped me feel like I’m working with Git – rather than constantly fighting against Git.
A pleasant side effect is that this also makes working with Git more fun: I’m able to work more frequently with common commands that work predictably and focus more on my work, rather than resolving an unexpected error.
What does this workflow look like?
If you’re not an experienced Git user, this probably sounds quite abstract. Here is a diagram of an example workflow which may help you visualize it. This workflow diagram shows a workflow with time flowing from left to right:
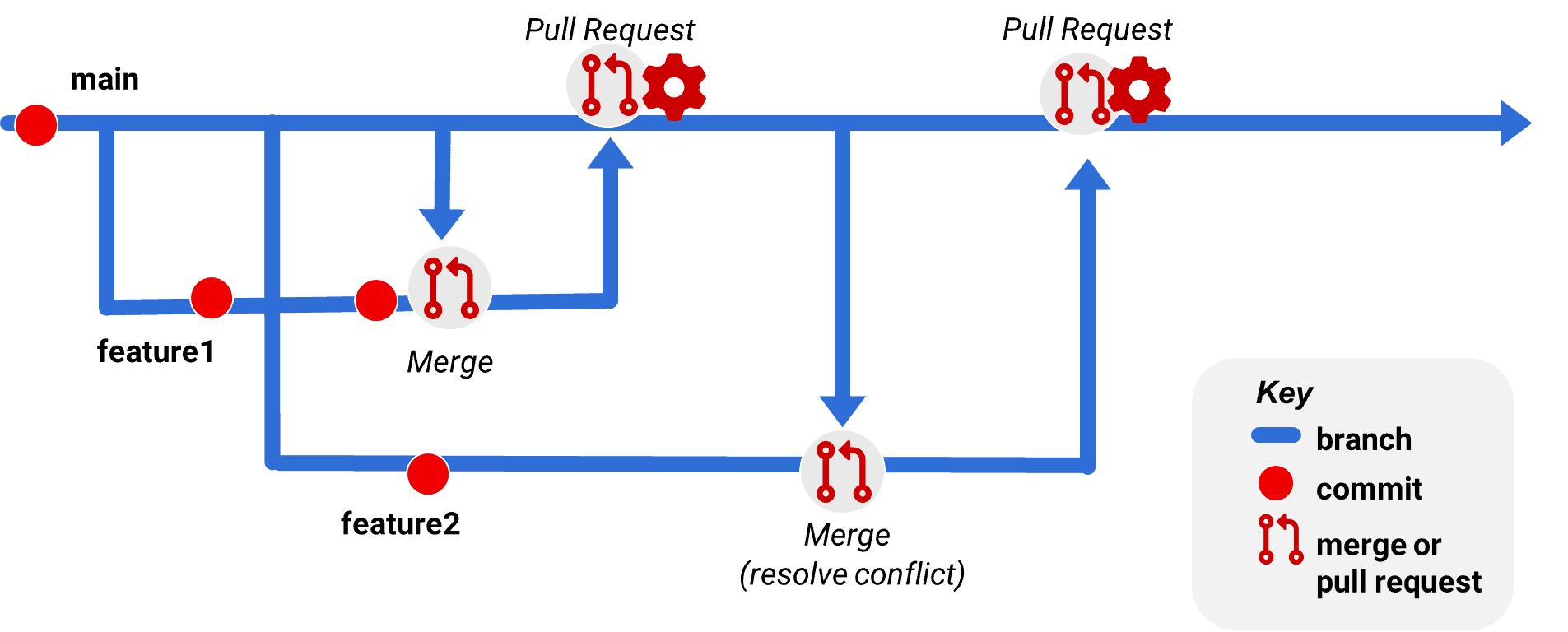
In this workflow, there is a main branch. The main branch represents a mainline of code – it could be named master; it could be named trunk; the naming is up to your preferences. In this example, everything merged into the main branch is expected to be code that has been reviewed and is considered to be ready to be deployable to a QA environment via automation.
Let’s say that our developers are working with the free Git client in VSCode and are using a tool like Redgate’s SQL Source Control, Redgate Change Control, or SQL Change Automation to script their database changes and manage the state of their development databases. (I’m mentioning specific Redgate tools here because I’m very familiar with how they work – if you’re using other tools, they may follow similar flows as this. A lot depends on how the tool has been designed, how much of a Git client is implemented inside the tool, the types of files it uses, and the naming conventions of the files.)
A developer, Amy, has used VSCode’s Git client to create a branch named feature1 off main. Here’s how feature1 progresses:
- Amy works in a dedicated development database and uses their database development tool of choice (SQL Source Control, Redgate Change Control, SQL Change Automation) to generate database code and commit it to their local clone of the Git repository.
- After the second commit to feature1, Amy merges from the main branch into feature1 to check if any other commits have been made to main since the feature1 branch was created. In this case, there have been no commits to merge in.
- When Amy believes their feature is complete, they do a final code generation and commit with their database development tool, then push the feature1 branch to the upstream repository.
- Amy then creates a Pull Request in the upstream Git repository to merge feature1 into main.
- The Pull Request process may run a build against the code and automatically add the appropriate reviewers. It also supports discussion and interaction about the change.
- The Pull Request is approved and completed, resulting in Amy’s changes in feature1 being merged into main.
Another developer, Beth, creates the branch feature2 from main using VSCode’s Git client.
Beth happens to do this a short time after Amy created the feature1 branch, but before Amy used a Pull Request to merge her changes back into main.
- By the time Beth decides that feature2 is ready to be shared, Amy already merged feature1 back into main via Pull Request.
- Beth uses the Git client in VSCode to pull down main and see if anything has changed in it recently – and she finds that there have been changes.
- Beth merges the main branch into feature2 and discovers that some of the files she changed when generating and committing code with her database tool was also changed in main.
- This is presented as a conflict by the Git client in VSCode. The Git client asks Amy to resolve it for the feature 2 branch.
- Amy has three choices for each file: she may decide to keep only her own changes which she made to feature2, take only the “incoming” changes (from main), or accept both and combine them. Amy may additionally make changes to the files involved in the conflict, such as fixing up commas or making other manual edits.
- After deciding how to merge the changes (let’s say they are compatible changes and she decides to combine them), Amy saves the modified files in VSCode. She then stages (“adds”) them and commits the changes into the feature2 branch. This commit concludes the merge process.
- At this point, it’s useful for Amy to validate that the merge has resulted in valid SQL and to update her development database with any changes she has accepted. She can do this by opening her database development tool and “apply” updates to her development database.
- When ready to merge changes into main, Amy pushes her commits upstream in the feature1 branch, and follows the same Pull Request workflow described above to merge changes into main.
Q: Can the developers work in a shared database?
In this workflow, developers are working in isolated feature branches and sharing changes by merging. What if each developer doesn’t have their own copy of the database to associate with their feature branch?
First off, dedicated development databases solve many problems and promote better quality code. Troy Hunt outlines why this is the case in his post, The unnecessary evil of the shared development database from 2011. Although this post is a classic, it’s still highly relevant, and the only thing that has changed is that SQL Server Developer Edition is now completely free (it was inexpensive at the time the article was written).
That being said, if you must use a shared development database, you can try to work around the limitations. You may need to take special configuration steps, depending on the tool. For example, if you are using SQL Source Control, you may use a “custom” connection to access a shared database via Git. You may be able to use object locking in your database tool to mitigate the risks of overwriting each other’s work, but you will still see changes in the shared development databases made by other people appear as suggested changes which you could import to version control, which can be very confusing.
Essentially, even if you are sharing a single branch, using a distributed version control system such as Git – where developers each maintain their own local copy of the repo and do not all push and pull to the repo simultaneously – makes using a shared database environment for development awkward.
Whether or not you are using shared or dedicated databases, it is worth your while to get into the practice of using individual feature branches and a Pull Request workflow because of the following benefits.
Building good practices
There are five major things which I really like about this workflow:
1. Team members may share changes safely and easily – Imagine that Amy and Beth do the same changes as above at the same times, but they are both working in the main branch. If either Amy or Beth attempts to push new commits to the main branch and it has been updated since they last pushed, they will get an error that the origin has changed and they cannot push.
What if Amy or Beth is working on an experimental change that they’d like to get feedback on from a team member, without having to integrate other changes? There isn’t a good way to do that when they are sharing the branch.
2. You may push changes upstream regularly without fear – It’s convenient to work in a distributed VCS like Git because you can work in a disconnected fashion when you need to. If you’re using a hosted Git repo like Azure DevOps Services or GitHub and your internet connection fails, no problem! You can still commit locally. However, I think it’s also a good practice to back up your changes by regularly pushing them upstream to the repo. If you have a hardware failure locally or accidentally delete the wrong folder, no worries, you haven’t lost work. Working in a private topic branch means you can push your branch up to the upstream repo anytime without worry about needing to handle a conflict.
3. It makes merging purposeful and frequent – In the scenario where Amy and Beth are both working simultaneously on a shared branch, if one of them pushes a commit, the other will need to merge the changes the next time they pull. This may be done automatically by a Git client if there is no conflict, but if they are working on any of the same files, when pulling they will need to pause to go resolve the conflict. Because this occurs only sometimes on a pull, this feels like a distraction and a break in flow.
To contrast, if Amy and Beth have the habit of working in their own feature branches, they can develop a habit of periodically comparing their branch with mainline branches at the origin, and deciding when they want to merge in changes from those branches. This tends to make merges happen at a point when the developer is ready to consider the merge—not when they might be thinking about solving another problem.
3. It allows frequent commits – Many times when people begin working in a shared branch in Git, it isn’t just any branch – it’s a mainline branch. In other words, it’s a branch that regularly (and perhaps automatically) deploys code to an environment. Doing your early development work in a shared mainline branch like this has some bad effects: it means you are either less likely to experiment, or you are less likely to commit your changes regularly. After all, what if you commit something that is an experiment which you don’t want to get deployed? Well, you’re going to have to undo those commits – that’s not hard, but do you want a commit history full of doing things and then undoing them? Getting into the habit of working in feature branches gives you much more freedom: you can commit and undo commits knowing that at the time you get to a Pull Request, you’ll have some options on squashing your commit history easily when you merge in. Or, if you prefer not to squash commit history, you can always create a temporary feature branch from your existing feature branch to play around with some changes before you decide what you want to do.
5. It encourages early change review and communication – So far, I’ve mainly talked about using Pull Requests as the way in which you merge changes from one branch into another. This is only a small bit of the value PRs give you. PRs often function as a major point of communication and review. Most hosted Git options even allow you to do things like automatically add reviewers and require a specific number of reviewers for a PR to be approved. When a PR is opened, you may also have it automatically run a build and test the code, potentially even deploying it to an environment for the reviewers to examine. In short, PR workflows promote communication and review early in code development. The workflow can be a strong foundation for ensuring you have quality code.
Q: What if I forget to use a feature branch?
If you want everyone to use a PR workflow, you may choose to protect some branches. Many hosted Git providers allow ways to do this: you can configure protected branches in GitHub, create a branch policy in Azure DevOps, or set Branch Permissions in BitBucket, for example. The protections or policies are generally enforced upstream at the origin. If you commit changes locally to a protected branch and attempt to push them, this will result in an error that you’re not allowed to change the upstream branch directly. In this case, you can usually create another branch locally off your updated main branch and proceed from there. If you have some work in progress that you aren’t ready to commit, you may want to stash it.
A detailed video example – “SQL Source Control and VSCode: Handling Git Conflicts”
In this video, I’m using a dedicated development database model with the following setup:
- Azure DevOps Services Organization and Project – this hosts the upstream Git Repo.
- The upstream repo is used to push and pull changes for Git clients doing the work. The upstream Git Repo is also where Pull Requests are created, reviewed, approved, and completed.
- I have cloned two copies of the same Git repo to my local workstation so that I can simulate working as two people, each in their own local repo.
- SQL Source Control – this compares the SQL Server database to the code in the Git Repo.
- It identifies when there are changes in the development database to commit to the repo, automatically scripts changes to commit to the repo, and helps keep the development database in sync when new changes come from the Git repo.
- I’ve already created a SQL Source Control project and committed it to the repo. Both of my local copies of the repo begin with having pulled down copies of the project.
- VSCode and Azure Data Studio – These free tools from Microsoft share the same free Git client. In this example I use these tools to manage my merge conflicts.
- I’m using VSCode to represent one user and Azure Data Studio to represent the other, simply because I can set different color schemes in them and it makes it easier for me to track.
- I have the free GitLens extension installed in both VSCode and Azure Data Studio. This extension makes it easy to see details of commit history and has many more useful options. This is totally optional, simply nice to have in my experience.
A list of chapters is below if you’d like an overview, or if you’d like to jump to specific sections.
Chapters in the video:
- 00:00 Overview of the demo setup
- 02:07 Demo begins of a merge conflict when working in the same branch as your teammates
- 03:17 Why conflicts occur as interrupts if we work in the same branch in Git
- 04:35 Interpreting Git conflict messages in SQL Source Control
- 05:58 Resolving a merge conflict within your current branch
- 08:37 Why working in private feature branches is a common practice for Git users
- 10:42 Traveling back in time with the GitLens extension
- 12:07 Resetting SQL Source Control after resetting in Git
- 14:30 Demo begins of working in a feature branch in SQL Source Control, and proactively merging from main when we’re ready
- 15:17 Checking out a new branch in VSCode
- 18:18 Merge changes from the upstream main branch into our feature branch. I have enabled VSCode to regularly fetch changes, so I haven’t manually ‘fetched’.
- 20:38 Resolving the conflict in VSCode
- 23:40 Staging and committing to complete the merge
- 25:05 Applying changes we made in VSCode to our dev database in SQL Source Control
- 26:06 Pushing our changes to the central Git repo and creating a Pull Request
- 29:00 Approving and completing the Pull Request
Branching and merging in Git is not as hard as it may seem at first glance!
If you are new to Git, this can seem daunting to learn.
While Git can be quite complex, I have found that hands-on experience with Git and practicing in a test project got me a long way, and it happened faster than I expected. The branching workflows described in this article have also made my work in Git flow easier, which has made it less frustrating and more fun.
I hope this pattern proves useful to your team as well.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments