Edward Pollack in SQL Server 5 T-SQL features that should already exist (2026 SQL Server wish list) 2026 T-SQL wish list covering native Parquet imports, arrays, OVERLAPS, simpler licensing, and cloud storage — features SQL Server still... 26 June 2026 14 min read
Fabiano Amorim in SQL Server Exposing a SQL injection vulnerability you’ve never heard of (what it is, how it works, and key takeaways) How a Unicode lookalike character bypassed REPLACE-based sanitization in a trusted SQL Server system procedure - and what it teaches... 19 June 2026 11 min read 31
Lukas Vileikis in Career Why you should still become SQL-certified in 2026 (and how to achieve it) Is SQL certification still worth it in 2026? Learn how it boosts credibility, career opportunities, and helps you stay competitive... 18 June 2026 10 min read 2
Greg Low in SQL Server Vector search in SQL Server: VECTOR_DISTANCE, VECTOR_SEARCH, and index trade-offs Learn how to use VECTOR_DISTANCE and VECTOR_SEARCH in SQL Server to find semantically similar data. Covers vector indexes, performance trade-offs,... 17 June 2026 7 min read 1
Chisom Kanu in Databases It’s 2026. Why are databases still failing GDPR compliance audits? GDPR erasure failures are often database engineering problems, not legal ones. Learn how relational schema design, backup retention, and audit... 11 June 2026 13 min read 1
Greg Low in SQL Server How to call an Ollama-based AI text embeddings model from SQL Server 2025 Learn how to call locally hosted Ollama embedding models from SQL Server using sp_invoke_external_rest_endpoint, CREATE EXTERNAL MODEL, and AI_GENERATE_EMBEDDINGS.… 08 June 2026 5 min read 11
Greg Low in SQL Server How to host an AI text embeddings model for SQL Server using Ollama Learn how to install Ollama locally to generate text embeddings for SQL Server vector search, plus configure a Caddy proxy... 01 June 2026 5 min read 21
Edward Pollack in T-SQL Programming Demystifying PIVOT and UNPIVOT in T-SQL Learn how to use T-SQL PIVOT and UNPIVOT operators with clear examples — from basic row-to-column transforms to dynamic SQL... 20 May 2026 12 min read 4
Fabiano Amorim in SQL Server SQL Server security vulnerabilities you weren’t aware of: how tampered indexed-view metadata can break cross-database isolation Indexed view tampering in SQL Server backups can expose cross-database data after restore. Learn how restore-boundary attacks work and how... 18 May 2026 18 min read 2
Simple Talk Editor in Security, Privacy & Compliance In 2026, engineering teams are quietly accepting more risk. Here’s why 11 takeaways from the Simple Talk podcast on security vs speed in databases: why teams misjudge risk, how AI amplifies... 17 May 2026 4 min read 22
Lukas Vileikis in PostgreSQL PostgreSQL is removing MD5 authentication for passwords. Here’s what it means for your databases PostgreSQL is phasing out MD5 authentication across versions 18–21, replacing it with SCRAM-SHA-256. Here's what it means for your database... 15 May 2026 7 min read 3
Dejan Lukić in Security, Privacy & Compliance How to build a privacy-aware analytics layer with SQL (4 top techniques) Learn how to build privacy-aware analytics with SQL using masking, aggregation, and pseudonymization. Stay GDPR-compliant without exposing PII.… 13 May 2026 11 min read 21
Lukas Vileikis in Databases Why COALESCE might be the most useful SQL function you’re not using right Learn how the SQL COALESCE function works, with practical examples for handling NULL values, setting defaults, and writing cleaner, more... 07 May 2026 7 min read 31
Greg Low in SQL Server What are managed identities in SQL Server 2025? A complete guide Learn how managed identities in SQL Server 2025 enhance security by eliminating passwords and enabling seamless Microsoft Entra authentication for... 05 May 2026 6 min read 1
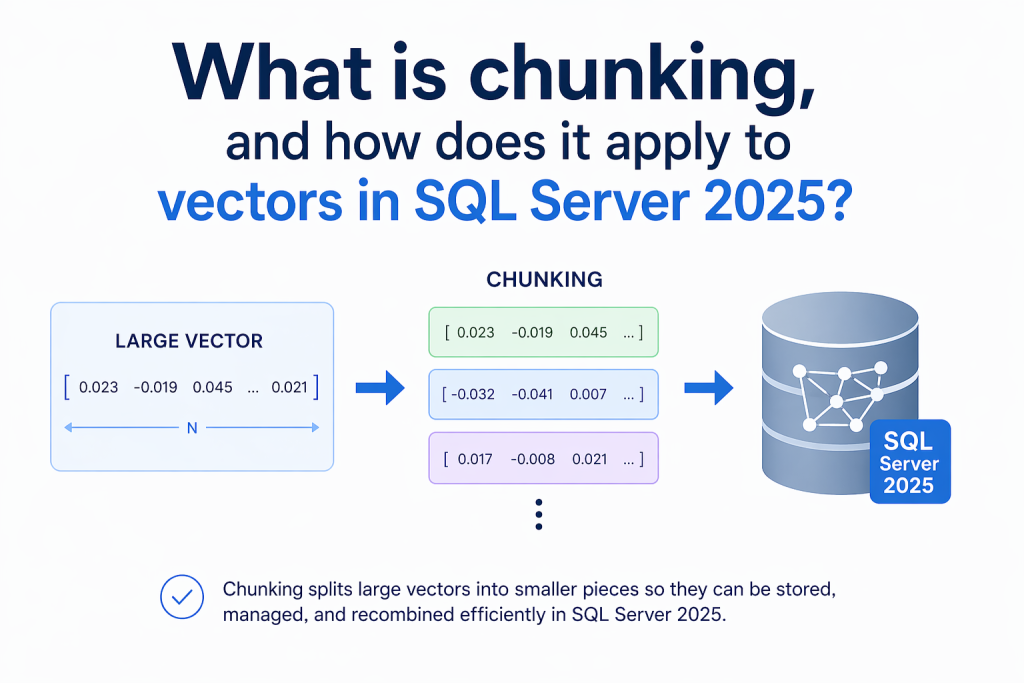
Greg Low in SQL Server What is chunking, and how does it apply to vectors in SQL Server 2025? Learn what chunking is, why it matters for embeddings, and how SQL Server 2025 enables efficient AI-powered vector search.… 01 May 2026 7 min read 22
Simple Talk Editor in Databases What are the top database platforms in 2026? A look at the latest data Explore 2026 database market trends: AWS, Microsoft, Oracle, and Google Cloud Platform remain dominant as MongoDB, Snowflake, and Databricks steadily... 28 April 2026 6 min read 4
Animesh Goyal in AI When, and when not, to use LLMs in your data pipeline “Let’s add LLMs to the pipeline” has become a familiar refrain in modern data teams, but turning that idea into... 16 April 2026 10 min read 51
Greg Low in SQL Server Can SQL Server 2025’s REGEXP_SPLIT_TO_TABLE fix STRING_SPLIT in T-SQL? Learn how to split strings efficiently in T-SQL using STRING_SPLIT and the REGEXP_SPLIT_TO_TABLE function in SQL Server 2025. Discover limitations,... 15 April 2026 5 min read 1
Fabiano Amorim in SQL Server Cross-database ownership chaining in SQL Server: security risks, behavior, and privilege escalation explained Learn how cross-database ownership chaining works in SQL Server, how permissions are evaluated, and why it can introduce security risks... 13 April 2026 12 min read 2
Greg Low in SQL Server Everything you should know about the SQL Server Resource database Learn what the SQL Server Resource database is, why it exists, how it affects patching/ upgrades, and what to do... 25 March 2026 5 min read 22
 4
4