Much of the material that I’ll discuss in this article comes from the excellent work done by Scott W Ambler and Pramodkumar J. Sadalage who wrote the book ‘Refactoring Databases: Evolutionary Database Design’ and maintain the site http://www.agiledata.org/. Just as Martin Fowler’s original book ‘Refactoring: Improving the Design of Existing Code’ introduced the world to the methodology of refactoring code, their book, and website, introduces us to the concepts and disciplines needed to refactor databases.
My aim is to draw attention to their work and shine some light on related topics that are specific to the SQL that we developers use to interact with the database.
Most developers have accepted, and even embraced, the need for a discipline of refactoring application code.By contrast, Refactoring a database is still regarded as an alien concept. I’ll be arguing in this article that refactoring the database is just as important as refactoring code.
The task of refactoring an application, whether it is the database or the application code, is undertaken with the objectives of
- Improving maintainability
- making it more understandable
- Making it easier to make changes
- Making it easier to add new features
- learning the system
Some Background Information
Not all applications are created equal. For some of them, the task of refactoring the database is only marginally more complicated than that of refactoring code. For others, it can be an arduous task that could take more than a year to complete.
The following diagrams illustrate the two extremes.
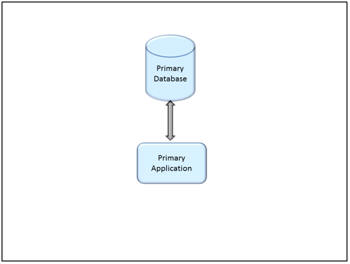
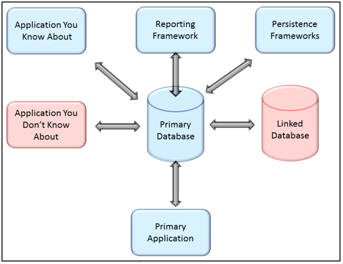
Some Applications may have a single database and a single application using that database.Other applications may include multiple linked databases, with associated systems for reporting and ETL, serving several applications, not all of which may even be known to the developers. Changes to your database must be coordinated across all of these various systems.
If you work with databases in the complex extreme, you may be tempted to use this complexity as a reason not to refractor the database. It is particularly daunting to face the risk that there may be applications that you don’t know about. This is a true risk, but it is also a symptom that warns that refactoring is probably long overdue. Not knowing what dependent systems may be affected if you make a particular change is not a reason to avoid the change.It is compelling opportunity to learn your system better and better understand and record these dependencies.
I have often found myself in this situation. Many different things may cause it: Key people may have left, taking critical knowledge with them. You may have just discovered a “departmental” solution that has been elevated to the enterprise; you may be starting a new job or working on a new project.
The Basic Process: An Overview
The basic process when you have only a single application and its database is straightforward, really no different from refactoring your code. Test before you make the change. Make a small change.Test after each change. Rerun all tests at each stage.
When there is more than one application involved, things get more complicated. Each affected application may not necessarily be updated on the same release schedule. The system will need to work with some applications using the old structure and some applications using the new structures. In both cases, the end result should be the same from the application perspective.
Part of the refactoring process is ensuring that all applications work properly during the transition period and that all of the structures that are added in order to to support this transition period are subsequently removed once all applications are using only the new structures.
The time line is similar to this:
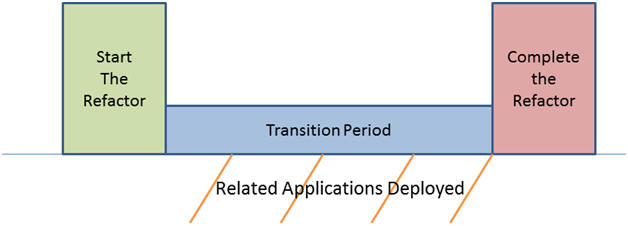
During the transition period, all of the related applications should be updated so that, at the end of the transition period, any code or structures added to support the transition can be removed safely. The transition period needs to be long enough to allow all affected applications to have at least one release cycle to accommodate the change. In some cases, this could be a couple of months. In other cases, this may take over a year.
we are often left to our own devices to track what changes have been applied where and what systems need to be updated.
Unfortunately, there is currently only limited tool support for carrying out these refactors and we are often left to our own devices to track what changes have been applied where and what systems need to be updated. Version control helps, but it is still often a challenge to know when we can safely say that a refactor has been completed. Scott and Pramod recommend a simple one column / one row DatabaseConfiguration table to track what version each of your databases are in. This makes it easy to see what version a specific database is in, but it does not provide much detail about what that version means. I have found that I’ve needed a slightly more complex data model to provide the relevant details.
The Refactor table identifies the refactorings that have been started. The InterfacingSystem table identifies the various dependent systems thatinterface with this database and may be affected.The RefactorTracking table tracks which systems have been updated to accommodate the refactor. Ideally when the refactor is initiated, a record will be inserted into the RefactoringTracking table for each of the Interfacing Systems. Any system that is not impacted could immediately update the RefactorVerifiedDate. Otherewise each system would update their corresponding record when the change necessary to accommodate the refactor was deployed. Once every Interfacing System has verified the refactor, any supporting structures can be removed and the refactor considered complete.

The task of actually carrying out a refactoring is still complex and tedious, but hopefully vendors will soon catch up and fill in the gap with useful tools. Tools to help perform the actual refactors are beginning to become available. Red Gate’s SQL Prompt will help carry out many of the refactoring in the catalog, but I still want more. My ideal tool would keep track of this metadata across all environments. I want a tool to help track data similar to the tables outlined above. We need tools to help us track the status of all of the refactorings that we have in progress.
An Introduction to the Catalog
Scott and Pramod maintain a catalog of database refactorings. The catalog is broken up into categories:
- Structural Refactorings
- Data Quality Refactorings
- Referential Integrity Refactorings
- Architectural Refactorings
- Method Refactorings
The Structural Refactoring will help correct problems with the way tables are structured. Some of these refactorings include:
- Drop Column: This is usually the end result of moving a column or simply removing a column that is no longer used.
- Rename Column: This is used to improve the name of a column without moving it
- Split Column: This is used to improve the usage of a column when a column contains multiple pieces of information that should be split over multiple columns such as storing City State, and ZipCode in a single column.
- Drop Table: This is often the end result of multiple Move Columns
- Rename Table: This is used to clarify a table’s meaning
- Split Table: This is used to split the columns in a table between two tables.
These refactorings can be used to clean up naming conventions, clarify object names, or improve how the database models the business.
The Data Quality category includes refactorings to improve the integrity of the data stored or standardize its usage. This may improve data integrity, improve or lessen the need for data scrubbing, or make the data usage more obvious. Some of these refactorings include:
- Add Lookup Table: This is used to provide a referential constraint on the data in a column
- Apply Standard Type: This is used to ensure that the same data type is used for similar columns throughout the database. You may need this to standardize on the size of varchars, the precision of numerics, etc.
- Introduce Common Format: This is used to standardize the formatused to store data.I have often had to use this to remove edit masks from phone numbers and social security numbers, etc.
The Refactoring of Referential Integrity helps to ensure that data referenced in other tables is available and ensures that related records are removed when the master record is removed. Some of these refactorings include:
- Add Foreign Key Constraint: This is used to add a foreign key constraint to have the database enforce a relationship between two tables.
- Introduce Cascading Delete: Used to instruct the database to delete related records when a parent record is deleted.
- Drop Foreign Key Constraint: This is used to stop the database from guaranteeing the relationship between two tables. This seems counter intuitive but is sometimes needed for performance reasons and may be needed if the referential rules between two tables is not consistent across all applications.
- Introduce Soft Delete: This is used to modify the data access semantics to check a new flag to determine if a record is still logically in the database. The record will continue to be there, only this flag is updated when a record is deleted. This is often needed to audit tracking.
- Introduce Hard Delete: This is used to undo an Introduce Soft Delete refactor. You may need to do this to reduce the size of the table or to simplify queries
The Architectural Refactorings are indented to improve how external systems interact with the database. Some of these refactorings include:
- Add Mirror Table: Creates an exact copy of table in a new database. This is often used to improve performance. Care must be taken to keep the new table in synch with the original, but the mirror table can take load off of the original database and improve response time for the mirror database
- Use Official Data Store: This is often used to clean up issues where your application is not using an accurate (up-to-date) copy of the data. Sometimes this may be used to undo Add Mirror Table, but usually this is used clean up where multiple applications have created data stores for a type of data not knowing that there is an official data store.
- Migrate Method To Database: This is used to centralize application logic in the database. This may be done to improve reuse or to improve performance. If the business logic is very data intensive, it may be more efficient to implement the logic in the database instead of dragging all of the logic to the application level. This can also be used to improve security. Application logic cannot bypass the database if the logic is implemented in the database. Also sensitive data could be read, interpreted, and acted on without having to be transferred and exposed outside of the database.
- Migrate Method From Database: This is used to move application logic to the applications that needed it. This may be needed because different applications have different logic, to improve scalability, to simplify maintenance. It is often easier to skilled DotNet developers to maintain DotNet code than it is to find skilled T-SQL experts to maintain T-SQL code.
The Method Refactoring category includes refactorings related to the code in the database. As such, many of these will be more similar to Martin Fowlers original list of refactorings. Some of these refactorings include:
- Add Parameter: This is used to add a parameter to a stored procedure. This will often improve reusability and reduce the number of stored procedures that are needed. If you have a stored procedure to get the sales numbers specific to each region, you can reduce this down to one by having a stored procedure that takes the sales region as a parameter and can be used for any sales region.
- Decompose Conditional: This is used to simplify the logic in a stored procedure. In some ways this is harder in SQL than in a high level programming language because languages like CSharp are so much more expressive. On the other hand, T-SQL opens new possibilities.
- Rename Method: This is used to make the purpose of the stored procedure more clear or to follow naming conventions. Consider usp_Account_Sel_0318 vs GetAccountsByRegion.
- Introduce Variable: This is used to introduce variables for intermediate steps ina complex calculation or conditional to make the code easier to follow.
This category also includes more database centric refactorings such as:
- Replace literal with table lookup: This is used to make the code easier to read and easier to change. Instead of hard coding constants in the stored procedure, you can store them in a lookup table and retrieve them as needed.
There is a great deal of discipline and technique defined in each of these refactorings. The more comfortable you are with these refactorings, the easier it will be to know how to resolve problems when you find them. Also being familiar with these refactorings and how they are carried out will make it easier to spot problems before they become obvious.
Refactoring SQL
Many of these refactorings will greatly simplify our SQL statements, but there is also a need for a category of SQL Refactorings that are concerned with the way that the actual SQL is written. With that in mind, I propose the following refactorings as examples:
- Apply Formatting
- Expand Column Names
- Replace Dynamic Filters
- Replace Dynamic Order By
This is far from a complete list and just the beginning of what could grow into a lengthy list with some healthy discussion. The first two entries are very basic and simplistic. The last two deal exclusively with a recurring problem that I often see, dynamic SQL in stored procedures.
Apply Formatting
Clean up inconsistent formatting to make the code easier to read.It is no secret that poorly formatted code is difficult for us lowly developers to read and follow. The computer has no trouble reading the SQL no matter how poorly formatted it may be. We on the other hand need any help we can get.
Original Code
|
1 2 3 4 5 6 |
SELECT *,[LinePrice]+ValueAddedTax AS TotalPrice FROM (SELECT *, 0.125*[LinePrice] AS ValueAddedTax FROM (SELECT UnitPrice, Quantity, [UnitPrice]*[Quantity] AS LinePrice FROM [OrderDetails] ) AS InnerQuery AS NextLevel |
Revised Code
|
1 2 3 4 5 6 7 8 |
SELECT * ,[LinePrice] + Valueaddedtax AS Totalprice FROM (SELECT * ,0.125 * [LinePrice] AS Valueaddedtax FROM (SELECT Unitprice ,Quantity ,[UnitPrice] * [Quantity] AS Lineprice FROM [OrderDetails]) AS Innerquery) AS Nextlevel |
Tools such as Red Gate’s SQL Prompt automate reformatting SQL according to the style rules that you define. Style is very subjective, but regardless of the finer points that you prefer, properly formatted SQL is easier to follow and understand. We will address concerns with the wild card character next.
Expand Column Names
Replace the * wild card with an explicit list of columns As a short cut we will often use this construct
|
1 |
select * from dbo.Employee |
The problem is that this makes your code more brittle and susceptible to changes in the data model. The wild card can easily mask problems with database structure changes. If a stored procedure uses this syntax, it may be harder to track where renaming a column may cause problems.
Revised Code
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
SELECT [EmployeeId] ,[FirstName] ,[LastName] ,[MiddleInitial] ,[DateOfHire] ,[StartDate] ,[EmployeeTypeId] ,[PositionId] ,[ReportsTo] ,[DepartmentId] ,[LocationId] . . . FROM [dbo].[Employee] |
The Revised Code shows the columns expanded. Now with the column names all expanded, if we want to later apply a Rename Column refactoring to either the DateOfHire or StartDate columns to have more consistency in naming conventions, this stored procedure will more easily be flagged as an affected dependency.
SQL Prompt will also automate expanding such wild cards
Replace Dynamic Filters
Programmers often feel the need to create SQL ‘on the fly’ by assembling strings of SQL and then sending them to SQL Server. This is usually called ‘Ad-hoc SQL. This is often done from the client application to do dynamic filtering of results, but is also often done in stored procedures. You can eliminate the need to build a dynamic SQL statement simply to conditionally add filtering clauses to a SQL statement.
We may often find that a search stored procedure may include optional parameters that do not need to be included in the search criteria. A common implementation is to build a SQL statement in a string and then execute the string. The optional elements in the where clause are added only if the corresponding parameter is not null.
Original Code
|
1 2 3 4 5 |
If @FirstName Is Not Null Set @whereString = @whereString + ' And FirstName = ''' + @FirstName + ''''; If @LastName Is Not Null Set @whereString = @whereString + ' And LastName = ''' + @LastName + ''''; |
Revised Code
|
1 2 |
where FirstName = isnull (@FirstName, FirstName) and LastName = isnull (@LastName, LastName) |
In the revised code, there are no if statements. There are no SQL strings, but the final result set will still be the same. If the parameter is null, we will be comparing the value in the column to itself which will never cause the row to be filtered out.
Potential Trade offs
There is a potential performance hit. You need to verify that the resulting query does not compromise your indexing strategy. The original code also has a potential performance hit as the database will need to evaluate the logic, build the SQL statement, parse the SQL and may even need to build an execution plan every time.
Replace Dynamic Order By
Another frequent motivator for using Ad-hoc SQL is to allow for different ordering of the same result set. You can eliminate the need to build a dynamic SQL statement simply to specify how the result set should be sorted. This will then allow it to be done more efficiently by calling a stored procedure.
We may often want to allow the database to handle sorting the result set but still allow the user to specify how results should be sorted. A common implementation is to build the SQL statement in a string and specify the ORDER BY based on an input parameter.
Original Code
|
1 2 3 4 5 |
IF (@orderby IS NOT NULL AND DATALENGTH(@orderby) > 0) BEGIN set @sql = @sql + N' ORDER BY ' + @orderby END exec sp_executesql @sql |
Revised Code
|
1 2 3 4 5 6 7 8 |
select . . . from dbo.employee where . . . ORDER BY CASE WHEN @orderby = '' THEN EmployeeId end, CASE WHEN @orderby = 'FirstName ASC' THEN FirstNameend asc, CASE WHEN @orderby = 'LastName ASC' THEN LastNameEND ASC, CASE WHEN @orderby = 'FirstName desc' THEN FirstNameend desc, CASE WHEN @orderby = 'LastName desc' THEN LastNameEND desc |
The revised code builds the ORDER BY clause using the same parameter with the same meaning without having to build the SQL statement dynamically and force the database to parse it every time.
A similar technique can be used to provide support for paging the result set.
Potential Trade offs
If the @OrderBy parameter does not have one of the expected values, it will silently failin the sense that it will not sort by the intended column.
The last two refactoring operations will eliminate 2 of the most common needs for “dynamic” SQL in stored procedures. By using Ad-hoc SQL rather than stored procedures, code is harder to read, and makes it harder to track dependencies in the database. It is a worthy goal to replace Ad-hoc SQL with static SQL in our stored procedures.
Conclusion
Scott W Ambler and Pramodkumar J. Sadalage have brought the same thought and discipline to database refactoring that Martin Fowler originally brought to refactoring software.The techniques of Refactoring database are at the same stage as were those of refactoring code when Martin Fowler first got started. There is limited tool support and is the techniques are not yet widely accepted.
Better tool support will come. Red Gate is already leading the charge with tools like SQL Prompt, SQL Dependency Tracker, and SQL Compare. More tools are likely on the horizon as the importance of this discipline becomes more widely known.
The techniques are well thought out and mature. Do not be afraid to branch out into refactoring databases. The database does not need to be the last bastion to resist evolutionary designs.
Load comments