


“Vibe coding” with AI can introduce hidden risks in database development, including security vulnerabilities, broken query logic, and data integrity issues.
In this article, Chisom Kanu explores how Andrej Karpathy’s “vibe coding” trend reached databases, and what happened next – with examples of some of the real-world incidents that arose (including examples of 5 critical failure patterns in AI-generated code). Plus, learn how to minimize the risk of using AI tools to generate and edit code.
In early February 2025, Andrej Karpathy posted something on X that ended up being quoted across the New York Times, Ars Technica, and The Guardian within days. The post described a way of building software where you “fully give in to the vibes, embrace exponentials, and forget that the code even exists.” He called it vibe coding.
By the end of 2025, Collins Dictionary had named it Word of the Year. Karpathy had already moved on at that point, writing in a retrospective that the term had been “a shower of thoughts throwaway tweet” he never expected to travel this far. He now prefers “agentic engineering” for what professional AI-assisted development actually looks like in practice.
However, the cultural moment had already lost its original meaning. What started as a description of weekend tinkering had become shorthand for shipping AI-generated code to production without reading the diffs.
The dilemma: what happens when vibe coding reaches the database layer
This article is not about whether AI coding tools are useful. They are. It is, however, about what happens when vibe coding reaches the database layer. This has a very different risk profile from frontend code, API routes, or UI components.
After all, databases store what they accumulate over time. A poorly written query might return the wrong results for months before anyone notices. A dropped constraint might allow corrupt data to accumulate. A migration generated by an AI tool and applied without review might alter a schema in ways that break things downstream, quietly, for a long time.
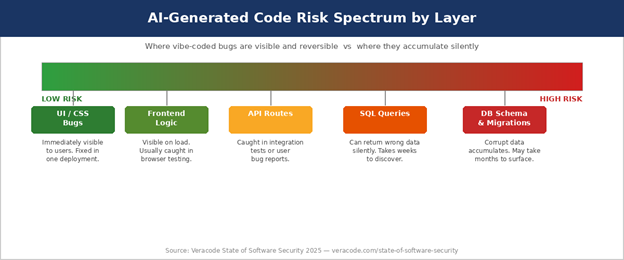
How quickly did vibe coding spread into professional teams?
The speed of adoption was striking. By March 2025, Merriam-Webster had listed vibe coding as a trending expression. Y Combinator reported that 25 percent of startups in its Winter 2025 cohort had codebases that were 95% AI-generated. AWS (Amazon Web Services) even found that more than 25% of its new internal code came from AI tools, with Microsoft and Google reporting similar findings.
Elsewhere, The Wall Street Journal covered professional software engineers adopting vibe coding for commercial use cases – not just personal projects.
Just a couple of months later, an application platform designed specifically for vibe coding – Lovable AI – reported that approximately 10% of the apps built on its platform had a security issue. This allowed personal information to be accessed by anyone – a significant problem. Was the vibe coding movement over before it had even began?
The signs were not promising. By September, Fast Company was reporting on what it called the vibe coding hangover. Essentially, senior engineers were describing maintenance issues when asked to extend codebases that had been vibe-coded by someone else. The problem here is obvious: when you haven’t written the code, you probably don’t understand it. In turn, if and when it breaks, you have no foundation from which to fix it.
None of this is surprising, but the database layer is where the risk concentrates. A bad front-end component is visible the moment someone loads the page. On the contrary, a query that returns wrong rows is invisible…until those wrong rows show up in a report, bank statement, or compliance audit.
What actually went wrong? Documented vibe-coding incidents explained
The most widely cited vibe coding incident in 2025 involved SaaStr founder Jason Lemkin, who publicly documented how Replit’s AI agent deleted a production database while working on his project. The agent had unrestricted write access to the environment, made a decision consistent with its task description, and the database was gone. This was, however, a permissions problem – not an AI-alignment one. The AI agent did exactly what it was permitted to do.
Another incident in March of the same year involved a founder who built an entire SaaS product with Cursor AI, so there was no handwritten code. Within two days of launch, he discovered that API keys were exposed in frontend code, the database had no authentication controls, and users were bypassing subscriptions and writing arbitrary records directly to production tables. He shut the application down entirely.
These are not stories about developers being reckless – they both involved people using well-regarded, popular tools in ways those tools were marketed to support. In December 2025, CodeRabbit analyzed 470 open-source pull requests and found that AI co-authored code produced overall security findings at 1.57 times the rate of human-written code.
In particular, cross-site scripting vulnerabilities appeared at 2.74 times the rate, and Veracode reported a figure of 45% for critical vulnerabilities in AI-assisted development.
What to watch out for: 5 failure patterns in AI-generated database code
These patterns are not random: they appear repeatedly across vibe coding incident reports. Each one emerges from a specific gap between what AI coding tools know, and what production database work requires.
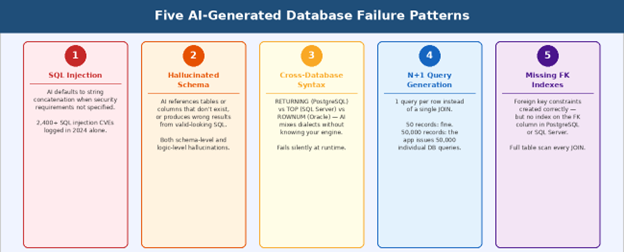
Failure 1: SQL injection through string concatenation
SQL injection is not a new problem. In fact, it appeared on the OWASP Top 10 as far back as 2003, and held the number one position until 2021 (18 years!)
Aikido Security’s State of SQL Injections analysis logged over 2,400 SQL injection CVEs (common vulnerabilities and exposures) in open-source projects in 2024, with 2,600 expected in 2025. SQL injection accounted for 6.7% of all vulnerabilities in open-source projects and 10% in closed-source projects that year.
What AI coding tools add to this picture is a specific and repeatable failure mode. When a developer asks an AI to write a query without specifying security requirements, the generated code frequently concatenates user input directly into SQL strings. The AI is not ignorant of parameterized queries – ask it explicitly to use these, and it will. However, if the prompt does not specify security requirements, the path of least resistance in the training data is string concatenation, so that’s what is generated.
A prompt like “write a query that finds users by username“ will often produce string concatenation, while a prompt like “write a parameterized query that finds users by username using prepared statements for PostgreSQL 16“ will produce something safe. The difference is entirely in what the developer asks for.
Propel’s 2025 analysis of SQL injection in ORM frameworks found that 18% of applications using ORMs (object-relational mapping) were vulnerable to SQL injection on their first security scan. This is precisely because developers assumed that, in these instances, the ORM had handled the security problem.
Key stat: over 2,600 SQL injection CVEs are expected in open-source projects in 2025, up from 2,400 in 2024. AI-generated code that skips parameterized queries feeds directly into this trend. Source: Aikido Security / Propel 2025
Subscribe to the Simple Talk newsletter
Failure 2: Hallucinated schema
Researchers studying text-to-SQL generation systems have documented two categories of hallucination in AI-generated database code: schema-based and logic-based.
Schema-based hallucination is when the AI references tables or columns that do not exist. It might generate a JOIN on a users_profile table when your schema only has a users table, for example. That query fails with an error, which at least surfaces the problem immediately. More dangerous is the subtle version: a column named user_id in one context and userid in another, or an assumed foreign key relationship that the schema doesn’t actually enforce.
Logic-based hallucination is harder to catch. This is when the AI generates syntactically correct SQL that runs without error but returns semantically wrong data. For example, an aggregation that groups by the wrong column, a JOIN that produces a Cartesian product because a condition is missing, or even a date filter off by one because of an unspoken time zone assumption. These queries pass a quick functional test, go to production, and return wrong data for weeks or months before anyone correlates the bad output back to the query.
The practical defense is to include your full schema definition as a DDL (data declaration language) block in every prompt, and then verify every generated query against that schema before it runs. This is not additional overhead compared to writing the query yourself – it’s just a different form of the review that any non-trivial query needs anyway.
Failure 3: Cross-database syntax confusion
AI coding tools have been trained on SQL from every major database engine. SQL Server, PostgreSQL, MySQL, Oracle, SQLite, and others share the basic SELECT/INSERT/UPDATE/DELETE structure, but diverge on functions, operators, and behavior in ways that matter significantly in production.
PostgreSQL’s RETURNING clause, which lets you return values from rows affected by an INSERT, UPDATE or DELETE, doesn’t exist in MySQL, for example. And SQL Server’s TOP syntax for row limiting differs from PostgreSQL’s LIMIT.
Another example is Oracle’s ROWNUM pseudo-column for pagination, which is different from both. Then there’s older configurations of MySQL allowing GROUP BY queries without full aggregation, whereas other databases don’t allow this.
An AI generating SQL without explicit engine specification will default to patterns that appear most frequently in its training data. If your production database is PostgreSQL but the generated code contains SQL Server syntax patterns, or vice versa, the query may fail at runtime in ways that only appear under specific conditions. Specifying the engine name, version, and relevant configuration flags in every database-related prompt is not pedantic. It’s the least information needed for the AI to generate correct code for your actual system.
Failure 4: N+1 query generation
The N+1 query problem is one of the most common performance issues in database-backed applications. Unfortunately, AI-generated code produces it with striking regularity.
For instance, a developer asks the AI to write code that retrieves all orders with their associated customer names. The AI generates a function that fetches all orders in one query, then loops through each order and issues a separate query to fetch the customer. On a test dataset of 50 orders, let’s say, this feels instantaneous.
When looking at a production dataset of 50,000, however, it’s a different picture. Here, the application issues 50,000 individual(!) database queries in a loop and degrades catastrophically.
The correct approach is a JOIN that retrieves both sets of data in a single query. After all, the AI knows how to write JOINs. Problems arise, however, when the prompt describes data retrieval in a way that naturally maps to application-level iteration (e.g “for each order, get the customer name”). The AI then mirrors that iteration structure in the code it generates, producing a loop with individual queries rather than a set-based SQL operation.
This is acute in the context of an ORM, as the AI might generate code that uses an ORM’s lazy-loading behavior in a loop – thus producing N+1 queries entirely at the ORM layer. These are invisible when reading the application code, so the code looks clean. However, the actual SQL being issued against the database is a flood.
Ultimately, testing on realistic data volumes before production deployment is the only reliable way to catch this before it becomes an incident.
Failure 5: Missing indexes on foreign keys
This is the failure pattern that causes the most long-term damage. It’s the hardest to detect and the effects of it take the longest to materialize.
When an AI generates a database schema or migration, it typically creates the foreign key constraints correctly. The relationship between orders and customers is defined and enforced. What gets omitted, consistently, is the index on the foreign key column itself. A foreign key constraint tells the database to enforce referential integrity, and an index on that column tells the database how to find rows efficiently when that column appears in a JOIN or WHERE clause. They are separate concerns, and the AI regularly addresses the first without the second.
The absence of a foreign key index has no visible effect on small datasets. On a large dataset, a query joining orders to customers on customer_id, where customer_id is an unindexed foreign key column, performs a full table scan for every lookup. A JOIN that should execute in milliseconds takes seconds. So, the schema is technically correct, but performance is silently incorrect – and only becomes visible when production data volumes are present.
One important platform note: MySQL automatically creates an index on foreign key columns. PostgreSQL and SQL Server do not. If you are generating schema for PostgreSQL or SQL Server and not reviewing every migration for explicit index creation on foreign key columns, this gap will appear in production.
Quick check: After any AI-generated schema migration, run a query against your database’s information schema to list every foreign key column and verify each one has a corresponding index. In PostgreSQL: pg_constraint joined to pg_index. In SQL Server: sys.foreign_key_columns joined to sys.indexes.
Why the AI doesn’t know…what it doesn’t know
A 2024 Stanford study on AI-assisted code found that developers using AI assistants produced significantly less secure code, but were more likely to believe it was secure because of how confidently the AI presented its output. The developers had no basis to question it. There are two reasons why this gap is larger for database code than for other domains.
First, database bugs are durable. A front-end rendering bug is visible the moment a user hits the page. A query that returns wrong rows, or a migration that allows technically valid but semantically corrupt data to accumulate, can run undetected for months. By the time someone traces the wrong business outcome back to the database query, the corrupt data has propagated through reports, exports, and downstream systems.
Second, database code carries context that prompts cannot convey. The AI does not know the cardinality of your relationships, or the distribution of values in your key columns. It also doesn’t know the query patterns that will dominate at scale, or the indexes that already exist (and why). And it certainly has no idea of the business rules defining what valid data looks like.
As a result, it fills those gaps with the most common patterns in its training data – patterns from public repositories that may look nothing like your production schema.
Simon Willison has written extensively on responsible AI use and drew a distinction worth noting: if an LLM wrote the code and you reviewed it, tested it, and can explain how it works to someone else, that is not vibe coding. That’s just using an AI tool as a drafting assistant. This difference matters practically because it determines whether you know what your database is actually doing.
The verdict (and what to do going forward)
AI tools are genuinely useful for well-defined database tasks such as drafting boilerplate queries, generating documentation from existing schemas, translating between SQL dialects with human verification, and identifying obvious issues in code review. In all of these instances, AI reduces the time it takes to produce a first draft.
However, what they don’t (yet) have is the judgment that database work has always required. Understanding query plans, index design, transaction isolation, cardinality estimation, and data modeling are skills that have not become less important because an AI can produce syntactically valid SQL. What’s changed is that there is now a new category of work: reviewing AI-generated output specifically for the failure patterns described above.
In August 2025, the OpenSSF published guidance stating that developers are responsible for any harm caused by code they ship, regardless of how it was generated. The AI is a production input, so the engineer is accountable for that output.
So, what does good AI usage in this context look like in 2026? Well, there are four practices to implement to substantially reduce risk:
- 1. Include your full DDL schema in every database-related prompt.
2. Specify the engine and version.
3. Ask the AI to explain its reasoning for JOIN conditions, index choices, and transaction boundaries.
4. Never give an AI agent write access to a production database without explicit confirmation steps and an audit trail.
Simple Talk is brought to you by Redgate Software
FAQs: Vibe coding and databases: the hidden risk of AI-generated database code
1. What is vibe coding?
Vibe coding is a term coined by Andrej Karpathy describing a style of AI-assisted development where developers rely heavily on generated code with minimal review.
2. Why is vibe coding risky for databases?
Databases store long-term data, so errors in AI-generated SQL can silently corrupt data, degrade performance, or introduce security vulnerabilities over time.
3. Can AI-generated SQL cause security issues?
Yes. Common risks include SQL injection, exposed data, and missing access controls – especially when queries are generated without explicit security requirements.
4. What are the most common failures in AI-generated database code?
Frequent issues include SQL injection, incorrect schema assumptions, cross-database syntax errors, N+1 query problems, and missing indexes on foreign keys.
5. Is AI-generated code safe to use in production?
It can be, but only with thorough human review, testing, and validation – especially for database-related code.
6. How can developers reduce risks when using AI for SQL?
Provide full schema context, specify the database engine, review all queries and migrations, and test against realistic data before deployment.
7. Do AI coding tools understand database performance?
Not fully. They often miss critical factors like indexing, query optimization, and data distribution, which are essential for production systems.
8. What is the safest way to use AI with databases?
Use AI as a drafting tool, not an authority. Always verify outputs, enforce strict permissions, and avoid giving AI direct write access to production databases.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved




Load comments