
SQL Server backup strategy starts with two questions: how much data can the business afford to lose (Recovery Point Objective – RPO), and how quickly must the database be available after a failure (Recovery Time Objective – RTO)? The answers to RPO and RTO determine the recovery model (FULL for point-in-time recovery, SIMPLE for daily full backup scenarios, BULK-LOGGED for large data loads) and the backup chain (full backups only, or full + differential + transaction log backups).
This article walks through the full decision chain – from SLA to recovery model to backup type to restore strategy and restore practice – with practical guidance for junior DBAs building their first production backup policy.
The series so far:
- DBA in training: So, you want to be a DBA...
- DBA in training: Preparing for interviews
- DBA in training: Know your environment(s)
- DBA in training: Security
- DBA in training: Backups, SLAs, and restore strategies
- DBA in training: Know your server’s limits
- DBA in training: SQL Server under the hood
- DBA in training: SQL Server high availability options
A DBA’s job is getting the right data to the right people as quickly as possible.
Consider that first part – getting the right data. How do you do that? By having the data in the first place. The best way to ensure that you have the data is to look at your company’s needs, recommend availability options, and most importantly, do backups. Few things will get a DBA fired more quickly than not having backups available when they are needed. It may be years before you ever have to restore a database from a backup, but the backups had better be there when you need to do one.
Conference sessions and books have been written on the subjects of backup/restores, SLAs, and availability options, and they are so good that I’ll just give you a brief overview here. You’ll gravitate to your need-to-learns soon enough.
As soon as you have a list of the SQL Server instances you will be managing, you need to understand three acronyms thoroughly:
- SLA
- RPO
- RTO
Did you just read those sets of three letters and wonder what I’m talking about? Don’t worry; I will explain.
Service Level Agreements (SLA)
Service Level Agreements (SLA) are a set of agreements between you and the business. Among other points (which may vary by the organization), they cover RPOs and RTOs.
Recovery Point Objective (RPO)
RPO is broadly defined as “how much data can you afford to lose if the data has to be recovered”.
Recovery Time Objective (RTO)
If RPO is a measure of how much data can be lost, RTO is a measure of how much time the business can afford to be down if data recovery becomes necessary. In other words, how long until you are back online and ready to go?
Ask to read over the SLA – in particular, the RPO and RTO. If there isn’t one, then find out what would need to be done to put one in place. Then, determine whether anyone has ever tested the numbers to ensure that they are possible.
Finally, try doing some tests yourself (not on Production!). In particular, try implementing some database restore strategies in test and see how long they take. If the numbers in the SLA appear too low or inconsistent with what your tests are showing, now is the time to note that and to consider alternatives to recommend. There are high availability options that can greatly improve your downtime if your instances are on-premises, and if your company uses a cloud option, RPO and RTO are configurable there as well. However, your restores are another matter. If your restores are taking too long no matter what you do, or you think the numbers in the SLA are unachievable for some other reason, your test results might help to facilitate the discussion of what revisions need to be made to the agreement, and what the costs of those changes will be for the company.
Backup and Restore Strategies
You may use options to increase the availability of your databases, but it would be a mistake to assume that having an availability strategy by itself guarantees the safety of your company’s data. You may, for instance, have Always On availability groups. These are groups of one or more databases that are copied out to at least one other location. If something would happen to the primary instance, the database administrator has the option to either manually or automatically “failover” to the other location with a minimum of downtime. Availability groups can have issues or fail outright. Worse, you may find yourself in a situation where a data entry mistake occurs. Maybe someone did a data update (or worse, a delete) with an incorrect or absent WHERE clause, for instance. That is when the phone starts ringing, and the incidents come in.
What, you have no backups? Houston, we have a problem. The best availability insurance you can provide for your company is to have tested, proven backups, and a layered practiced restore strategy.
Okay, you may think. I know I need to take backups, no matter what, but how do I test and prove them? Why do I need to practice restoring them?
The answer is simple: Because things go wrong with backups, too, and if you haven’t even tested them, you could be putting your business at risk of data loss. Make sure to do everything possible to ensure that doesn’t happen to you. I will start from the beginning by talking about recovery models and backup/restore strategies.
Protect your data. Demonstrate compliance.
Recovery Models
Whenever you are asked to create a new database (or if one is created during a deployment) one of your first questions should be centered around what recovery model the data owner needs. Here are your options:
FULL recovery
This is used for point-in-time restores – for example, a business user might request that you restore the database to a week ago at 7:15 in the morning. Point-in-time restores allow you to restore your database to any point in time, rather than just the time the backup was taken. If your data changes frequently, this is probably the option you need.
With FULL recovery, everything that happens on the database is recorded to the transaction log. That means that the log now has enough detail to go back to a moment in time and put the data to the exact state it was then – which affords you that point-in-time flexibility. It is important to understand that though you may take a full backup, your transaction log won’t be cleared until you do a log backup. If you forget to set up transaction log backups on this recovery model, the transaction log will balloon like a kinked water hose until eventually, it brings database activity to a screaming halt.
BULK-LOGGED recovery
You would use this primarily when you are loading a good amount of data into some tables. The load will be minimally logged, affording it speed and efficiency, but losing the detailed playback mechanism that makes point-in-time possible.
Not every operation qualifies for minimal logging. Some operations that do are:
- Bulk INSERT and SELECT
- SELECT INTO
- Creating indexes
- TRUNCATING tables
- Partition switching
The BULK-LOGGED recovery model is intended for temporary situations. However, there is a catch with point-in-time restores. The point-in-time capability is lost for any transaction log backups that contain bulk operations, along with tail log backups. Once the bulk operation is complete, switch the recovery model back and perform a FULL backup to start another chain.
SIMPLE recovery
Use this if you don’t need point-in-time recovery, because you won’t be able to do log backups with this. This is a great recovery model if your data changes infrequently. The transaction log will checkpoint periodically, which means that it writes any dirty pages and log records to disk. This prevents the log from becoming bloated.
How do you figure out your recovery model? There are a couple of easy ways. The first is just to use TSQL:
|
1 2 3 |
SELECT name, recovery_model_desc FROM sys.databases WHERE name = 'AdventureWork2012'; |
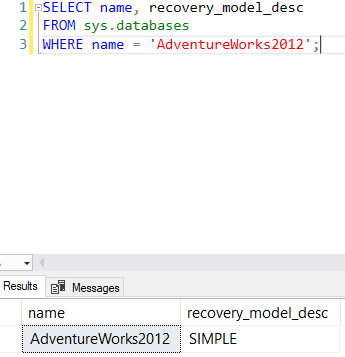
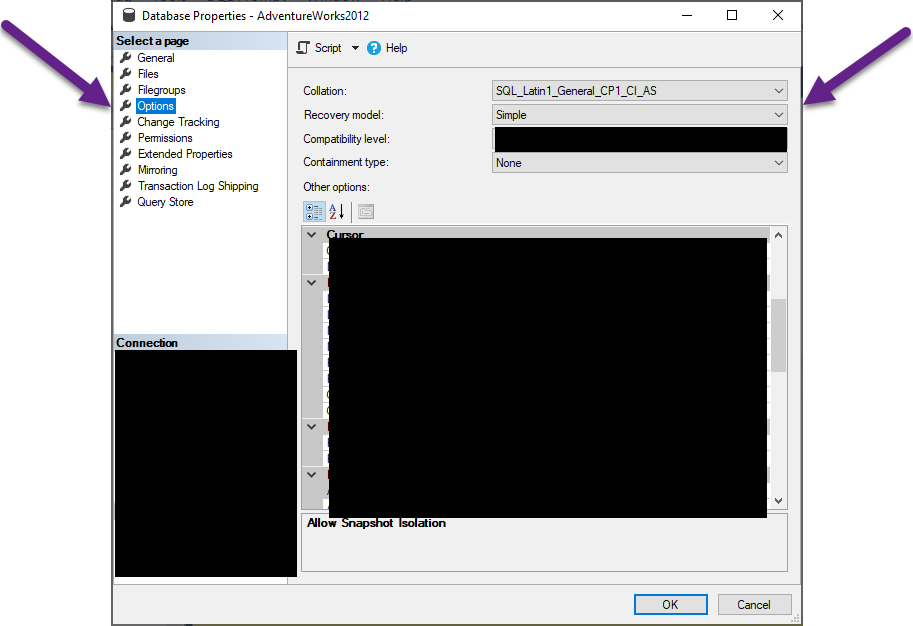
You could also just right-click on the database in the question and go to the Options window:
Backup Strategies
Once you have determined your recovery model, you can begin to think about backup strategies. How do you formulate a backup strategy? You think about how it is going to meet your RPO and RTO numbers. There are a number of ways to do this, but one of the most common starting points is to choose a combination of backup types and practice some restores to see if it is going to meet your goals.
What do I mean? When you are starting to look at backup strategies, begin with these options:
FULL backups
A FULL backup does just that – it backs up the database. It is your first step for all things backup-related, as it establishes the backup chain. In other words, the other backup types I am going to tell you about are tied to this one. You will use FULL backups no matter what the recovery model is. How frequently you use FULL backups will depend on the size of the database and your restore strategy. Most of the databases that I have worked with have received a FULL backup daily, but they could be once every few days, or even once a week.
You may find that when you start at a company, you have backup software such as Redgate’s SQL Backup or SQL Agent jobs already in place to manage your backups. You, however, should know how to do backups yourself. To do a FULL backup, I’ll pretend to do a backup of the AdventureWorks2012 database.
Using TSQL:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
BACKUP DATABASE [AdventureWorks2012] TO DISK = N'<location\filename here>' WITH NOFORMAT, INIT, NAME = N'AdventureWorks2012-Full Database Backup', SKIP, NOREWIND, NOUNLOAD, COMPRESSION, STATS = 10, CHECKSUM; GO DECLARE @backupSetId AS INT; SELECT @backupSetId = position FROM msdb..backupset WHERE database_name = N'AdventureWorks2012' AND backup_set_id = ( SELECT MAX(backup_set_id) FROM msdb..backupset WHERE database_name = N'AdventureWorks2012' ); IF @backupSetId IS NULL BEGIN RAISERROR(N'Verify failed. Backup information for database ''AdventureWorks2012'' not found.', 16, 1); END; RESTORE VERIFYONLY FROM DISK = N'<location\filename here>' WITH FILE = @backupSetId, NOUNLOAD, NOREWIND; GO |
To do a FULL backup using the GUI (right-click the database, go to Tasks, then Select Backup…). Then match your screen to this on the General tab:
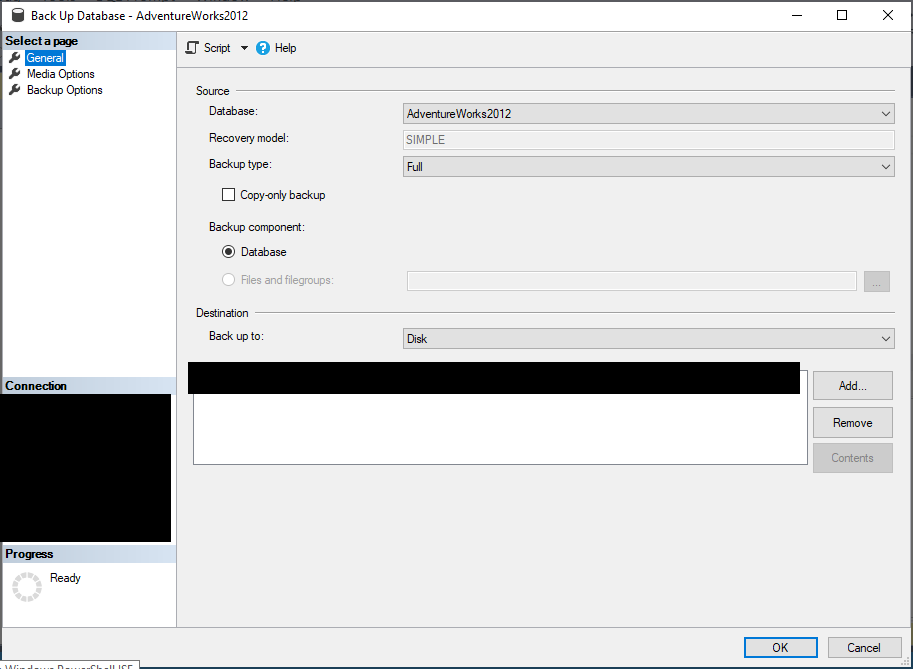
Fill in media options here:
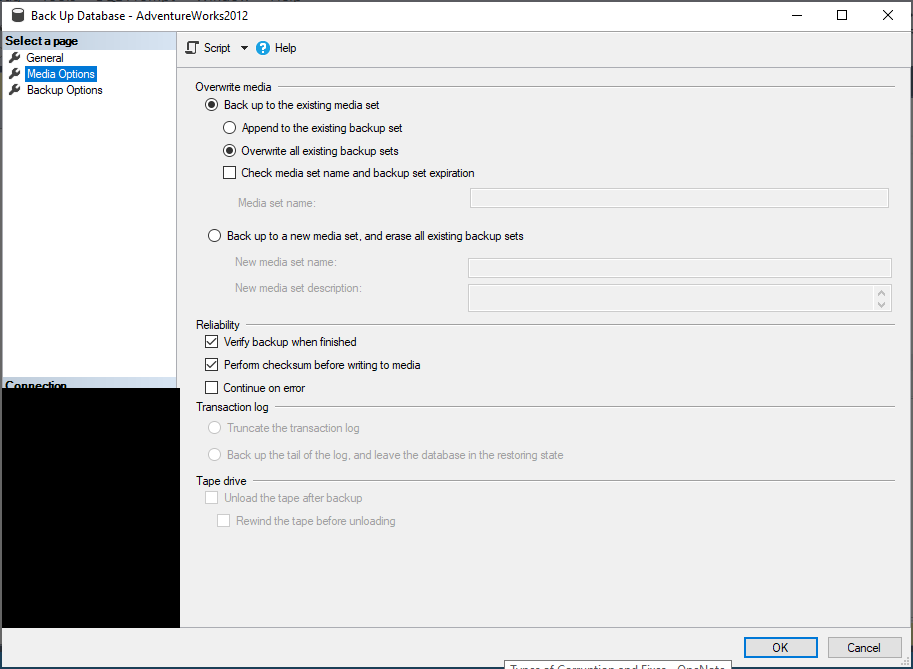
Fill in backup properties here:
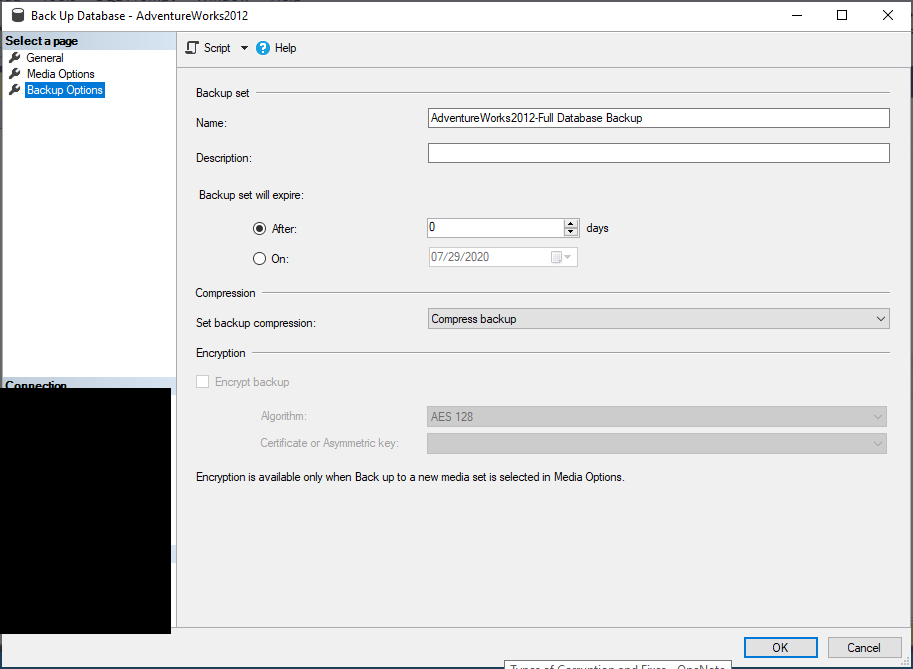
There is a special option with FULLs called WITH COPY_ONLY that allows you to take a FULL backup without breaking your existing backup chain.
To do the COPY_ONLY backup, just add that option after the WITH clause (when using TSQL) or check the Copy-only backup box on the General window of the GUI.
DIFFERENTIAL backups
The differential backup (or “diff”) is an optional (but useful) part of the backup chain. It covers all the changes since the last full backup. These restores from these backups tend to be much faster than restores from FULL backups, so taking diffs can save you some restore time. Because it covers all the changes since the last full, it can give you some extra flexibility – although not point-in-time recoverability – and it will be important for your business users to understand that.
How many diffs do you do? The company you work for probably has an established backup schedule which includes how many differential backups it does a day per server, so you won’t need to customize to an individual database. If you find that there is no automated backup strategy and it falls to you to determine to set the schedule, start with diffs every six hours and see where that gets you with your practice restores. If you find that differential backups aren’t being done, suggest them! Differential backups lend efficiency, flexibility, and speed to your backup and restore strategies.
To do a differential backup:
Using TSQL:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
BACKUP DATABASE [AdventureWorks2012] TO DISK = N'<filename, backup name here>' WITH DIFFERENTIAL, NOFORMAT, INIT, NAME = N'AdventureWorks2012-Differential Database Backup', SKIP, NOREWIND, NOUNLOAD, COMPRESSION, STATS = 10, CHECKSUM; GO DECLARE @backupSetId AS INT; SELECT @backupSetId = position FROM msdb..backupset WHERE database_name = N'AdventureWorks2012' AND backup_set_id = ( SELECT MAX(backup_set_id) FROM msdb..backupset WHERE database_name = N'AdventureWorks2012' ); IF @backupSetId IS NULL BEGIN RAISERROR(N'Verify failed. Backup information for database ''AdventureWorks2012'' not found.', 16, 1); END; RESTORE VERIFYONLY FROM DISK = N'<filename, backup name here>' WITH FILE = @backupSetId, NOUNLOAD, NOREWIND; GO |
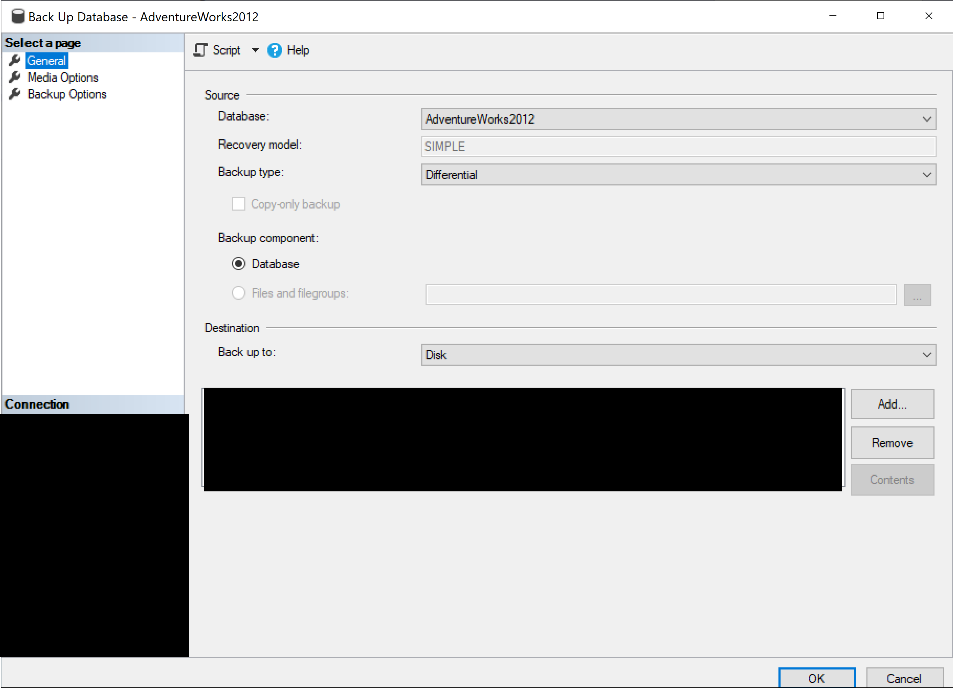
Using the GUI, right-click the database, go to Tasks, then choose Select Backup… For Backup Type, select Differential.
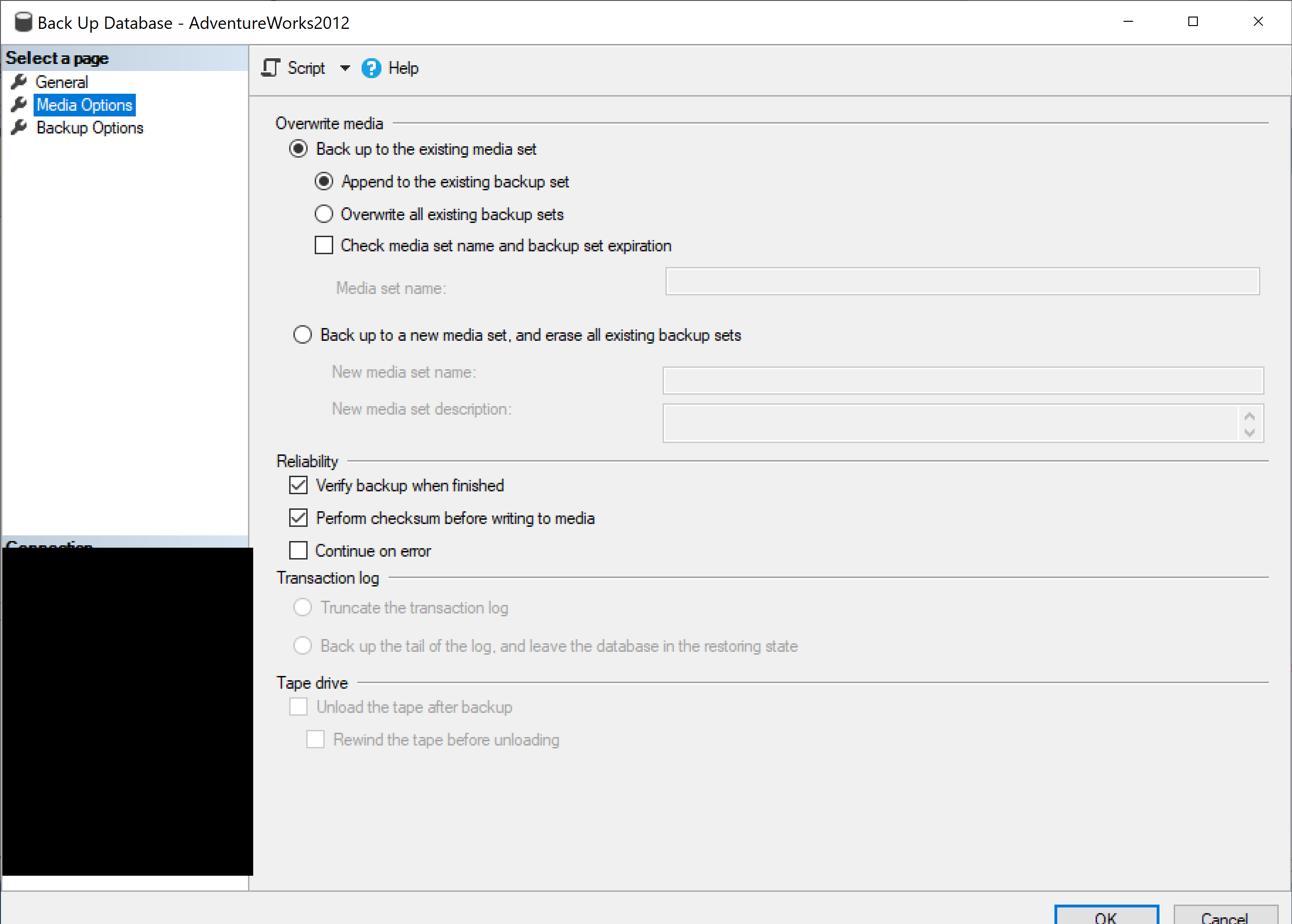
Fill out the Media Details as shown.
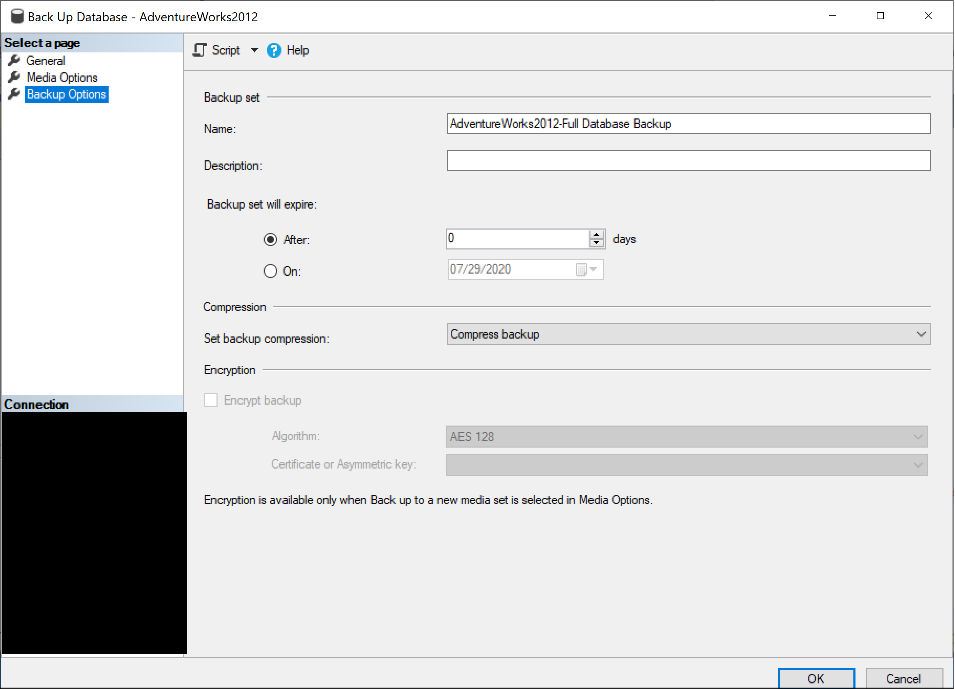
Change the expiration compression properties on the Backup options page.
TRANSACTION LOG backups
This is the magic behind the point-in-time restore option. This does just what you probably think it does – it backs up the transaction log (or “log”). It also clears the log (which prevents that log bloat that I spoke about before).
You may have thought that a FULL backup clears the transaction log and are wondering why it doesn’t. A FULL backup will take enough of the log to keep the database transactionally consistent, but SQL Server doesn’t know at that point if your database is in FULL recovery or SIMPLE. The recovery mode takes care of whether the transaction log undergoes CHECKPOINT, not the backups.
Using TSQL to do a log backup (Note: To do a log backup on AdventureWorks2012, which is in SIMPLE recovery, I had to put it into FULL recovery.).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
BACKUP LOG [AdventureWorks2012] TO DISK = N'<filelocation, backup name>' WITH NOFORMAT, INIT, NAME = N'AdventureWorks2012-Log Backup', SKIP, NOREWIND, NOUNLOAD, COMPRESSION, STATS = 10; GO DECLARE @backupSetId AS INT; SELECT @backupSetId = position FROM msdb..backupset WHERE database_name = N'AdventureWorks2012' AND backup_set_id = ( SELECT MAX(backup_set_id) FROM msdb..backupset WHERE database_name = N'AdventureWorks2012' ); IF @backupSetId IS NULL BEGIN RAISERROR(N'Verify failed. Backup information for database ''AdventureWorks2012'' not found.', 16, 1); END; RESTORE VERIFYONLY FROM DISK = N'<filelocation, backup name>' WITH FILE = @backupSetId, NOUNLOAD, NOREWIND; GO |
Using the GUI, launch the backup dialog as before, but this time, select Transaction Log as the backup type.
Change the Media Options as shown.
Change the backup options as necessary.
There are other backup/restore options, such as striped backups, filegroup backups, file backups, and partial backups (to name a few) which can help facilitate speedy restores in certain cases. I would recommend getting very comfortable with the basics first. Not sure where to look? Books Online has very good documentation, and there are other sites, such as Simple Talk and SQLSkills, that will help fill in the holes and answer questions as they occur.
Restore Strategies
You do backups in case you ever need to restore them. If you are a DBA for long enough, you’ll likely have to do this. I am only going to cover basic restores here; Books Online can walk you through more specialized restore options, such as filegroup, piecemeal and page restores.
FULL Restores
A full restore is the one that will take the longest, but it is the easiest to do. Just restore the closest FULL backup to your restore point. If you are only taking FULLs, you will only have one restore to do, so I will start with that.
Using TSQL, a basic FULL restore with no other backups involved would look like this:
|
1 2 3 4 |
USE [master]; RESTORE DATABASE [AdventureWorks2012] FROM DISK = N'<location, name here>'; GO |
Alternatively, you can use the GUI by right-clicking the database, then going to Tasks > Restore > Database, and clicking through the screens as you fill them in.
The GUI also makes it easy to make copies of the database. Returning to the Restore Database GUI, this time, I’ll make a copy of the AdventureWorks2012 database called AdventureWorks2012Copy by modifying the name in the Destination Database window:
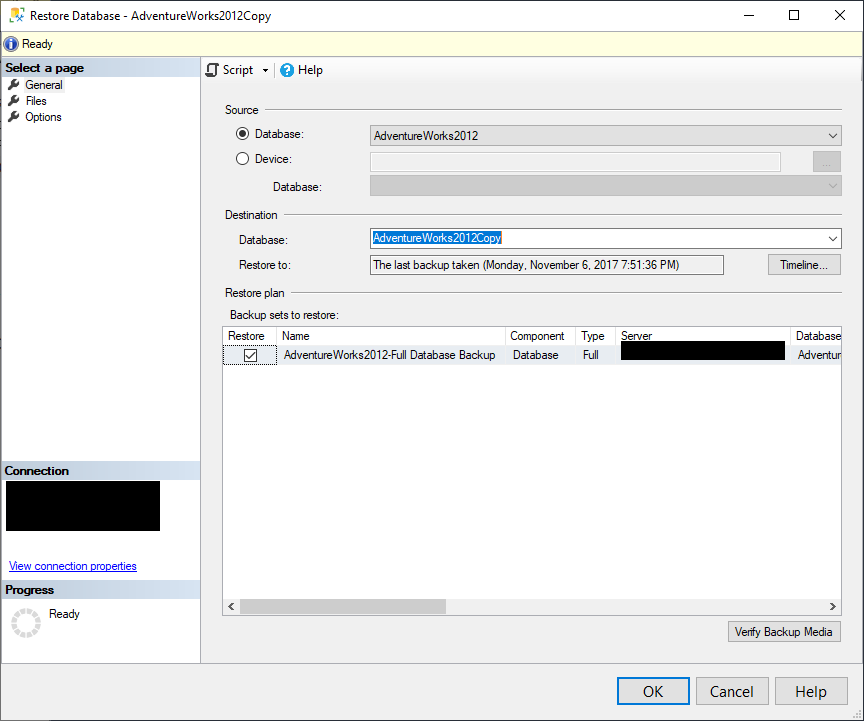
I could change the file locations if needed as well by going to the Files tab and clicking the ellipses next to the file names in the Restore As windows:
Finally, here is the Options tab:
Since this is a new database, I won’t be overwriting.
And, of course, by hitting the Script button at the top, SQL Server will make the script for me, which is convenient for documenting tickets, or better learning the syntax.
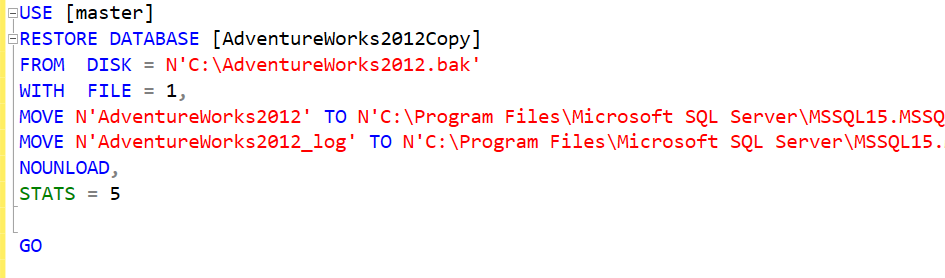
What does all of this code mean? It means that you are restoring a database called AdventureWorks2012Copy. FROM DISK shows the location. WITH FILE shows there is 1 file. MOVE shows where the files for the new database will wind up. NOUNLOAD is an old argument that just means that if the restore is happening from tape, the tape won’t be unloaded from the drive once you are done. The STATS argument is there to show your progress. In this case, it will update the messages tab for every five percent of the restore.
And here are the results.
I will edit some of the output for brevity, but it looks something like this:
5 percent processed.
10 percent processed.
15 percent processed.
20 percent processed.
…
95 percent processed.
100 percent processed.
Processed 24184 pages for database ‘AdventureWorks2012Copy’, file ‘AdventureWorks2012’ on file 1.
Processed 2 pages for database ‘AdventureWorks2012Copy’, file ‘AdventureWorks2012_log’ on file 1.
Converting database ‘AdventureWorks2012Copy’ from version 706 to the current version 904.
Database ‘AdventureWorks2012Copy’ running the upgrade step from version 706 to version 770.
RESTORE DATABASE successfully processed 24186 pages in 0.637 seconds (296.620 MB/sec).
Completion time: 2020-10-23T14:54:57.2214045-05:00
Notice the five percent stats and also the other messages. It shows the number of pages processed for the data and transaction log files, any upgrade conversions it does, and at what rate.
Restores with FULL and Differential Backups
Chances are you will need to have more than just a FULL backup restored. You are more likely to have backup chains involved, with a combination of FULL, differential, and log backups. These restores look a little different. To start as simply as possible, with a database that only uses a FULL and differential backup. One of the main things you want to keep in mind is that you have to tell SQL Server when it is done restoring. That is where the NORECOVERY/RECOVERY keywords come in. Using WITH NORECOVERY is like telling SQL Server, “Yes, restore that, but you are not done – there’s more!” The RECOVERY keyword tells SQL Server to finalize the restore. Here is an example of what that might look like:
|
1 2 3 4 5 6 7 8 |
USE [master]; RESTORE DATABASE [AdventureWorks2012] FROM DISK = N'<location, name here>' WITH NORECOVERY; --but wait, there is at least one more backup coming! RESTORE DATABASE [AdventureWorks2012] FROM DISK = N'<location, name here>' WITH FILE = 2, RECOVERY; -- Okay, you’re all done. |
If you have a database in FULL recovery, using differential backups can dramatically cut down on the number of transaction log backups you need to restore. When practicing restores using diffs, you start with restoring the last FULL and then skip to the most recent diff to the restore point you have been given. For example, say you have a backup strategy of one FULL backup every day at 6 PM, differential backups every four hours round the clock, and transaction log backups every ten minutes. You are asked to restore a database to yesterday at 8 AM. You would go to the night before yesterday and find that 6 PM FULL backup. Then go to the 8 AM differential backup. That’s it. You don’t need any log backups; the diff will get you there all on its own. In this scenario, you’re done, saving you the pain of assembling a long chain of log backups!
To use another example, if you have a backup strategy of one daily FULL backup, diffs every six hours, and log backups every 15 minutes, then you could save up to 24 log backup restores by using a differential backup. The benefit of not having to restore the extra log backups is not primarily in time saved because log backups are generally pretty fast. Nor is the biggest benefit not having to assemble the log restore chain in the first place (although that is not to be underestimated). The big benefit is in reduced risk; if anything happened to go wrong with one of those extra log backups, you lose the data from that point on.
Restores with FULL, Differential, and Transaction Logs
When practicing your restores, a restore strategy for the log backups will look like this:
- Closest FULL backup before the restore time specified
- Closest DIFF backup to the restore time
- Every LOG backup between the DIFF and the end time. To get your point-in-time, simply use the WITH STOPAT command and specify a time.
This code uses TSQL to restore a FULL, a diff, and two log backups:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
USE [master]; RESTORE DATABASE [AdventureWorks2012] FROM DISK = N'<location, name here>' WITH NORECOVERY; GO RESTORE DATABASE [AdventureWorks2012] FROM DISK = N'<location, name here>' WITH FILE = 2, NORECOVERY; GO RESTORE LOG [AdventureWorks2012] FROM DISK = N'<location, name here>' WITH NORECOVERY; GO RESTORE LOG [AdventureWorks2012] FROM DISK = N'<location, name here>' WITH RECOVERY; GO |
Or, for a point-in-time restore:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
USE [master]; RESTORE DATABASE [AdventureWorks2012] FROM DISK = N'<location, name here>' WITH NORECOVERY; GO RESTORE DATABASE [AdventureWorks2012] FROM DISK = N'<location, name here>' WITH FILE = 2, NORECOVERY; GO RESTORE LOG [AdventureWorks2012] FROM DISK = N'<location, name here>' WITH NORECOVERY; GO RESTORE LOG [AdventureWorks2012] FROM DISK = N'<location, name here>' WITH NORECOVERY, STOPAT = ‘January 1, 2020 8:03 AM’; RESTORE DATABASE AdventureWorks2012 WITH RECOVERY; GO |
There is an extra special bit of magic called a tail-of-the-log backup, which is one last log backup, allowing you to get as close to the present moment as it possibly can, should you need it. You’ll find it in the GUI for the restores.
Restore Practice
You can have the best set of backups around, but if you haven’t practiced doing restores (and especially if you don’t have an idea of how long they take), it can mean unexpected downtime and money for the business, and a bad day at the office for you.
I’ve shown you how to use TSQL or the GUI to do restores, but if you want to meet the numbers on your SLA, you will want to automate your backup and restore processes. This means either using backup software such as Redgate’s SQL Backup or using a free solution such as Ola Hallengren’s Backup Solution and writing your automated restore process. Whatever direction you choose, it should be well tested and vetted before you adopt it.
So, how to test your backups and restores? This is, after all, the whole reason for having backups in the first place – to have them in case you need to do a restore. Having a staging environment is a perfect chance to do this. Write a process to blow away the databases from the previous evening and restore your previous night’s backups. Then run a DBCC CHECKDB on them. This process will show that as of the time of your test, the backup is good. Lather, rinse, repeat.
Layering Your Backup Strategy
You have tested your backups by restoring them. You have confirmed that you can restore in the time allotted by your SLA. You have congratulated yourself and breathed a sigh of relief. You’re all good now, right?
No, not necessarily.
Why would that not be enough? Well, can something happen on the file share to corrupt that backup later on? Possibly. This is why you want a layered backup strategy.
As a DBA, you always want to be thinking, What if it breaks? This is one job where you are paid to scare yourself a little. This is never more true than with your backups. Having a layered backup strategy allows you to have a Plan B, a Plan C – as many plans as you think are necessary. For instance, supplementing your backups with server-level snapshots provides a little more security. You may not have the same restore-point flexibility with server-level snapshots, but with this combination, you can significantly reduce your chances of being caught tongue-tied when the alarm bells start going off. You can also copy off your backups to another file share or location. The point is not to put all of your eggs in one basket.
Conclusion
Understanding how recovery models work, what backup options are available to you, and how to use that knowledge to ensure that you can deliver the right data as quickly as possible is one of the most fundamental tools you will have in your tool belt as a DBA. Understanding the concepts laid out here is the beginning of that knowledge for you. As time goes on, you will learn more advanced concepts as the needs of your business dictate, or as your curiosity leads you to greater professional growth. This is only the beginning but learning these things and being able to do them well will be of great benefit as you strive to get the job, or grow in the profession.
FAQs: DBA in training: Backups, SLAs, and restore strategies
1. What is the difference between RPO and RTO in SQL Server backup planning?
RPO (Recovery Point Objective) defines how much data loss is acceptable – if RPO is 1 hour, you cannot lose more than 1 hour of transactions, so transaction log backups must run at least hourly. RTO (Recovery Time Objective) defines how long recovery can take – if RTO is 2 hours, you must be able to restore and bring the database online within 2 hours of failure. RPO drives backup frequency and type; RTO drives the restore strategy and may require standby databases or AlwaysOn Availability Groups for near-instant failover.
2. Which SQL Server recovery model should I use?
FULL recovery model – use when the business requires point-in-time restore capability. Requires full backups + regular transaction log backups. Logs grow until backed up. SIMPLE recovery model – use when point-in-time restore is not required. Log is auto-truncated; transaction log backups are not possible. Suitable for dev/test environments. BULK-LOGGED – use during large bulk data loads to minimise log growth. Switch to FULL before and after bulk operations in production. Default to FULL for any production database where data loss would have business impact.
3. How do I design a SQL Server backup chain?
A standard production backup chain for a FULL recovery model database: (1) Weekly or nightly FULL backup – establishes the base restore point. (2) Daily DIFFERENTIAL backups (optional) – reduces restore time by capturing only changes since the last full. (3) Hourly (or more frequent) TRANSACTION LOG backups – enables point-in-time restore and limits data loss to the log backup interval. To restore to a point in time: restore the most recent FULL, apply the most recent DIFFERENTIAL (if any), then apply all LOG backups up to the target time.
4. How often should I test my SQL Server restores?
Restore testing should happen regularly – at minimum quarterly for production databases, more frequently if the backup chain changes. A backup that has never been tested is of unknown value. The test must go beyond ‘restore succeeded’ – verify data integrity, confirm the database comes online, and confirm the restore completed within the SLA’s RTO window. Document the restore time and use it to validate your RTO commitment. Many DBAs automate restore testing to a secondary server using Ola Hallengren’s DatabaseBackup or similar tools.
Simple Talk is brought to you by Redgate Software
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments