
How do you know if your SQL Server is struggling — before users start complaining? The answer is baselining: understanding what normal looks like for your servers so you can spot trouble early. This guide – Part 6 of the ‘DBA in Training’ series – walks through the four key resource areas every DBA needs to monitor — drive space, I/O latency, CPU, and memory.
You’ll learn how to track database growth, what “bad” latency actually means in practice, how implicit conversions can silently destroy CPU performance, and why Page Life Expectancy is a less reliable memory indicator than most people think. Practical queries and tool recommendations are included throughout.
The series so far:
- DBA in training: So, you want to be a DBA...
- DBA in training: Preparing for interviews
- DBA in training: Know your environment(s)
- DBA in training: Security
- DBA in training: Backups, SLAs, and restore strategies
- DBA in training: Know your server’s limits
- DBA in training: SQL Server under the hood
- DBA in training: SQL Server high availability options
Having taken steps to map your database applications to the databases and address your security and backups, you need to turn your attention to your server’s limits.
What do I mean by limits? Certainly, this is an allusion to how you will monitor your server drive capacity, but I also mean how you will track resource limits, such as latency, CPU, memory, and wait stats. Understanding all of these terms, what normal values are for your server, and what to do to help if the values are not normal, will help to keep your servers as healthy as possible.
These measures are big, in-depth topics in and of themselves. This will only serve to get you started. Links to more in-depth resources are included with each topic, and you will doubtless find others as you progress through your career.
Drive Space
Whether you are hosting servers on-prem or in the cloud, and however your drives may be configured, you need to know how much space your files are consuming, and at what rate. Understanding these measures is essential to helping you to both manage your data (in case you find that it is time to implement archiving, for instance) and your drives (i.e., you’ve managed your data as carefully as you can, and you simply need more space). It is also vital to help you to plan for drive expansion and to provide justification for your requests. Whatever you do, avoid filling the drives. If your drives fill, everything will come to a screeching halt, while you and an unhappy Infrastructure team drop everything to fix it. If you are using Azure Managed Instances, you can increase the space as well. Storage limits and pricing in the cloud will depend on a number of factors – too many to explore here.
How can you monitor for drive capacity? Glenn Berry to the rescue! His diagnostic queries earned him the nickname “Dr. DMV”, and they are indispensable when assessing the health of your servers. They consist of nearly 80 queries, which assess nearly anything you can imagine at the instance and database levels. He is good about updating these once a month, and they work with Azure as well as SQL Server. If you do not like manually exporting your results to Excel and prefer using PowerShell instead, his queries work with that as well. This should get you started. This example (Query 25 of his SQL Server 2016 Diagnostic Information Queries) will give you the information you need for drive space:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
SELECT DISTINCT vs.volume_mount_point, vs.file_system_type, vs.logical_volume_name, CONVERT(DECIMAL(18, 2), vs.total_bytes / 1073741824.0) AS [Total Size (GB)], CONVERT(DECIMAL(18, 2), vs.available_bytes / 1073741824.0) AS [Available Size (GB)], CAST(CAST(vs.available_bytes AS FLOAT) / CAST(vs.total_bytes AS FLOAT) AS DECIMAL(18, 2)) * 100 AS [Space Free %] FROM sys.master_files AS f WITH (NOLOCK) CROSS APPLY sys.dm_os_volume_stats(f.database_id, f.[file_id]) AS vs OPTION (RECOMPILE); |
Tracking the results of this diagnostic query should help to get you started in monitoring your space and checking where you are. Regular tracking of your drive space will help you to see how quickly it is growing and to help you plan when (and how much) to expand them.
To help you track your database growth, you might try something like this query, which I have used countless times. It comes from here and is based on backup file sizes:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 |
DECLARE @startDate DATETIME; SET @startDate = GetDate(); SELECT PVT.DatabaseName ,PVT.[0] ,PVT.[-1] ,PVT.[-2] ,PVT.[-3] ,PVT.[-4] ,PVT.[-5] ,PVT.[-6] ,PVT.[-7] ,PVT.[-8] ,PVT.[-9] ,PVT.[-10] ,PVT.[-11] ,PVT.[-12] FROM ( SELECT BS.database_name AS DatabaseName ,DATEDIFF(mm, @startDate, BS.backup_start_date) AS MonthsAgo ,CONVERT(NUMERIC(10, 1), AVG(BF.file_size / 1048576.0)) AS AvgSizeMB FROM msdb.dbo.backupset AS BS INNER JOIN msdb.dbo.backupfile AS BF ON BS.backup_set_id = BF.backup_set_id WHERE BS.database_name NOT IN ( 'master' ,'msdb' ,'model' ,'tempdb' ) AND BS.database_name IN ( SELECT db_name(database_id) FROM master.SYS.DATABASES WHERE state_desc = 'ONLINE' ) AND BF.[file_type] = 'D' AND BS.backup_start_date BETWEEN DATEADD(yy, - 1, @startDate) AND @startDate GROUP BY BS.database_name ,DATEDIFF(mm, @startDate, BS.backup_start_date) ) AS BCKSTAT PIVOT(SUM(BCKSTAT.AvgSizeMB) FOR BCKSTAT.MonthsAgo IN ( [0] ,[-1] ,[-2] ,[-3] ,[-4] ,[-5] ,[-6] ,[-7] ,[-8] ,[-9] ,[-10] ,[-11] ,[-12] )) AS PVT ORDER BY PVT.DatabaseName; |
This gives you an idea of how quickly the databases on your servers have grown over the last twelve months. It can also help you to predict trends over time if there are specific times of year that you see spikes that you need to get ahead of. Between the two, you will have a much better idea of where you stand in terms of space. Before asking for more though, your Infrastructure and network teams will thank you if you carefully manage what you have first. Look at options to make the best use of the space you have. Perhaps some data archival is an option, or compression would work well to reduce space. If you have a reputation for carefully managing space before asking for more, you will have less to justify when you do make the request.
If you have SQL Monitor, you can watch disk growth and project how much you will have left in a year.
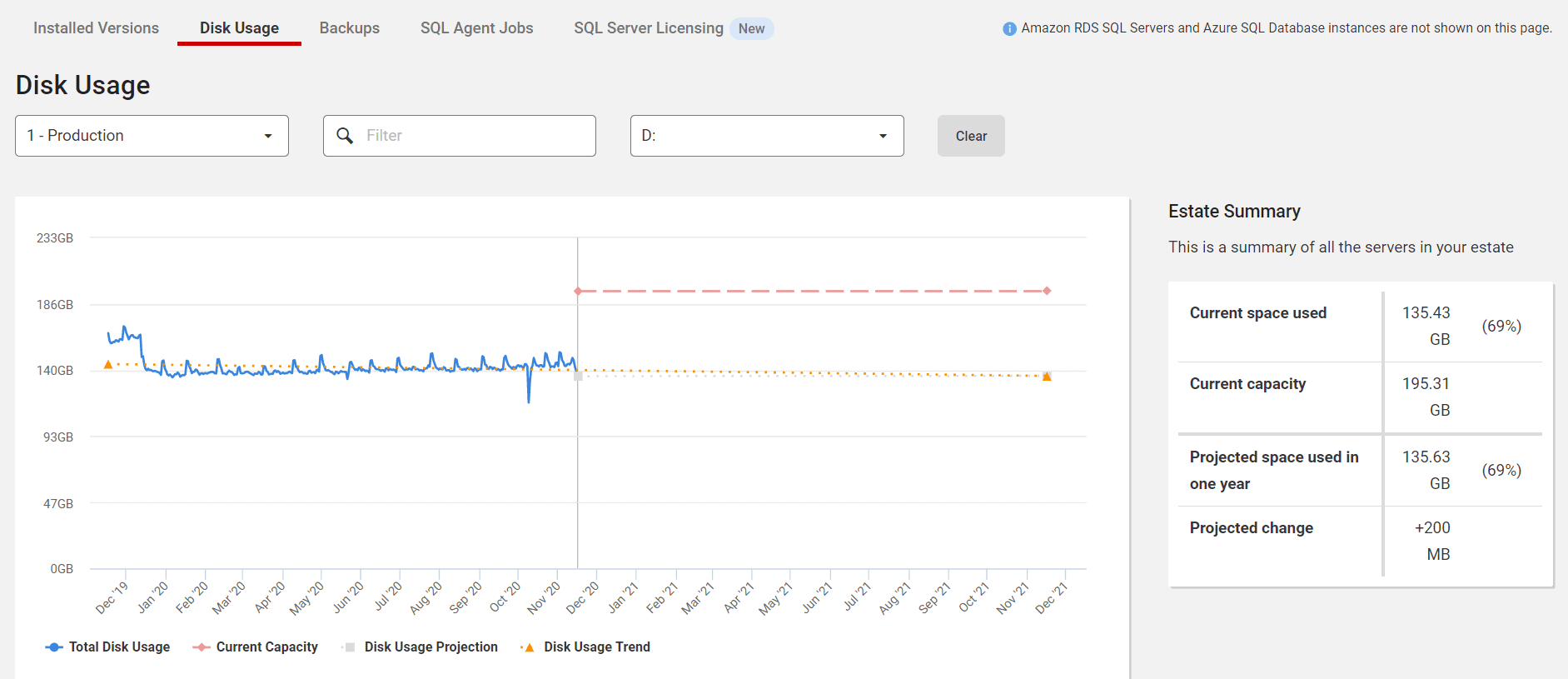
Know Your Resource Limits
You should now have some sort of idea of idea of how much space you currently have and how quickly your databases are consuming it. Time to look to resource consumption. There are a host of metrics that assess your server’s resource consumption – some more useful than others. For the purposes of this discussion, it will be limited to the basics – latency, CPU, and memory.
Latency
Latency means delay. There are two types of latency: Read latency and write latency. They tend to be lumped together under the term I/O latency (or just latency).
What is a normal number for latency, and what is bad? Paul Randal defines bad latency as starting at 20 ms, but after you assess your environment and tune it as far as you can, you may realize that 20 ms is your normal, at least for some of your servers. The point is that you know what and where your latencies are, and you work toward getting that number as low as you possibly can.
Well, that sounds right, you are probably thinking. How do you do that? You begin by baselining – collecting data on your server performance and maintaining it over time, so that you can see what is normal. Baselining is very similar to a doctor keeping track of your vital signs and labs. It’s common knowledge that 98.6 F is a baseline “normal” temperature, for instance, but normal for you may be 97.8 F instead. A “normal” blood pressure may be 120/80, but for you, 140/90 is as good as it gets, even on medication. Your doctor knows this because they have asked you to modify your diet, exercise and take blood pressure medication, and it is not going down any more than that. Therefore, 140/90 is a normal blood pressure for you. Alternatively, maybe you modified your diet as much as you are willing to, but are faithful to take your medications, and you exercise when you think about it. In that case, your blood pressure could still go down some, but for now, 140/90 is your normal.
The same is true for your servers. Maybe one of your newer servers is on the small side. It does not have a lot of activity yet, but historical data is in the process of back loading into one of the databases for future use. It has 5 ms of read latency and 10 ms of write latency as its normal.
Contrast that with another server in your environment, which gets bulk loaded with huge amounts of data daily. The server is seven years old and stores data from the dawn of time. The data is used for reports that issue a few times a day. It has 5 ms of read latency, but 30 ms of write latency. You know that there are some queries that are candidates for tuning, but other priorities are preventing that from happening. You also realize that this is an older server approaching end of life, but there is no more budget this year for better hardware, so 30 ms of write latency is normal – at least for now. It is not optimal, but you are doing what you can to stay on top of it. The idea is to be as proactive as possible and to spare yourself any nasty surprises.
To understand your baselines, you must collect your data points on a continuous basis. If you are new and no one is screaming about slowness yet, you might have the luxury of a month to begin your determination of what is normal for your environment. You may not. Nevertheless, start collecting it now, and do not stop. The longer you collect information on your I/O latency (and the other points discussed in this article), the clearer the picture becomes. Moreover, you can measurably demonstrate the improvements you made!
If you find that your latency is in the problem zone, the article I referred to before has some great places to begin troubleshooting. Try to be a good citizen first and look at all the alternatives Paul suggests before throwing hardware at the problem. Many times, you are in a position to help. I once had a situation where we were implementing some software, and a developer wrote a “one ring to rule them all” view that wound up crashing the dev server – twice. By simply getting rid of unnecessary columns in the SELECT statement, we reduced the reads in the query from over 217 million to about 344,000. CPU reduced from over 129,000 to 1. If we could have implemented indexing, we could have lowered the reads to 71. On those days, you feel like a hero, and if your server could speak, you would hear the sigh of relief from taking the weight off its shoulders.
Other query issues can also lead to unnecessary latency. One place to check is your tempdb. Here, you want to look for queries inappropriately using temporary structures. You may find, for instance, that temp tables are loaded with thousands of rows of data that are not required, or they are filtered after the temp table is already populated. By filtering the table on the insert, you will save reads – sometimes, a lot of them! You could find a table variable that would perform better as an indexed temp table. Another place to look is at indexing. Duplicate indexes can cause latency issues, as well as bad indexing, which causes SQL Server to throw up its hands and decide that it would be easier to read the entire table rather than to try to use the index you gave it.
CPU
Think of CPU as a measure of how hard your queries are making SQL Server think. Since SQL Server is licensed by logical core, that may lead you to wonder what the problem is with using your CPU. The answer is, nothing – as long as it is normal CPU usage.
So, what is “normal”? Again, baselining will tell you (or your server monitoring software will). Look for sustained spikes of high CPU activity rather than short spurts. Needless to say, if your CPU is pegged at 100% for 20 minutes, that is a problem! On the other hand, if you see 90% CPU usage for short spurts of time, that may be okay. If you do find a server with CPU issues, sp_BlitzCache is helpful to track down possible problem queries. You can, sort by reads or CPU. Even better, you will get concrete suggestions to help.
If you have SQL Monitor, you can also sort the top queries by CPU time to find queries taking the most CPU time.
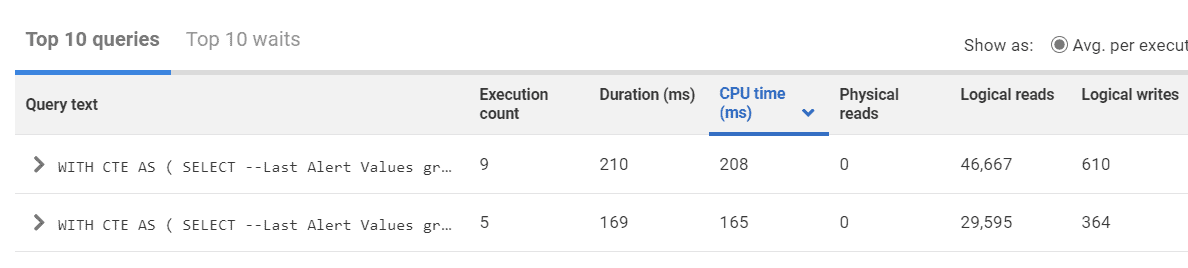
One of the most insidious consumers of CPU are implicit conversions. Implicit conversions occur when SQL Server must compare two different data types, usually on a JOIN or an equal operator. SQL Server will try to figure out the “apples to oranges” comparison for you using something called data type precedence, but you will pay in CPU for SQL Server to figure this out – for every agonizing row.
Implicit conversions are not easy to see. Sometimes, the two columns in the implicit conversion have the same name, but under the covers have two different data types. Or it can be more subtle – for instance, an NVARCHAR value without the “N’” used. Worse, you won’t even always see them on execution plans unless you go through the XML, so without monitoring for them, you may never know that you have an issue with them. Yet these invisible performance killers can peg your CPU. Running sp_BlitzCache on your servers will find these and help you with them.
High numbers of recompiles can also cause CPU issues. You might encounter these when code contains the WITH RECOMPILE hint to avoid parameter sniffing issues. If you have stored procedures using WITH RECOMPILE at the top of the procedure, one thing you can try is to see if you have any other alternatives. Maybe only part of the sproc needs the recompile hint instead of the whole thing. It is possible to use the recompile hint at the statement level instead of for the entire stored procedure. On the other hand, maybe a rewrite is in order. BlitzCache will catch stored procedures with RECOMPILE and bring them to your attention.
Memory
When discussing memory issues in SQL Server, a good percentage of DBAs will immediately think of the Page Life Expectancy (PLE) metric. Page life expectancy is a measure of how long a data page stays in memory before it if flushed from the buffer pool. However, PLE can be a faulty indicator of memory performance. For one thing, PLE is skewed by bad execution plans where excessive memory grants are given but not used. In this case, you have a query problem rather than a true memory pressure issue. For another, many people still go by the dated value of 300 seconds as the low limit of PLE, which was an arbitrary measure when first introduced over twenty years ago – it should actually be much higher. How much? It depends on your baseline. If you really love PLE and rely on it as an indicator anyway, look for sustained dips over long periods, then drill down to find out their causes. Chances are that it will still be some bad queries, but the upside is that you may be able to help with that.
What other things might be causing memory pressure? Bad table architecture can be the culprit. Wide tables with fixed rows that waste space still have to be loaded (with the wasted space!) and can quickly become a problem. The fewer data pages that can be loaded at a time, the less churn you will see in your cache. If possible, try to address these issues.
While you are at it, check your max memory setting. If it is set to 2147483647, that means that SQL Server can use all the memory on the OS. Make sure to give the OS some headspace, and do not allow any occasion for SQL Server to use all the memory.
If you are using in-memory OLTP, there are additional things for you to consider. This site will help you with monitoring memory usage for those tables.
Bad indexing can be another possible issue. Here, look for page splits and fragmentation, or missing indexes. If SQL Server can use a smaller copy of the table (a nonclustered index) rather than loading the entire table into memory, the benefits become obvious!
If none of these issues apply to you (or if you find that you just do not have enough memory), you may need to throw some hardware at it. There is nothing wrong with the need for hardware, if it is the proven, best solution.
Summary
Before you can tell if your SQL Server is not performing as well as expected, you need to know what normal performance is for that server. This article covered the three main resources, disk latency, CPU, and memory that you should baseline.
Simple Talk is brought to you by Redgate Software
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments