
In this article, Greg Low explains what chunking is, why it matters for embeddings, and how SQL Server 2025 enables efficient AI-powered vector search.
If you’ve started to work with vector databases and looked at using text embeddings for AI search, you might have come across the term chunking and wondered what it relates to. In this article, I’ll explain the concept in general – and then show how it works in SQL Server 2025.
What is chunking?
To generate text embeddings, you send a body of text to an AI language model that returns you a set of vectors. The number of values that come back (i.e., the dimensions of the vector) is determined by the model you’re using. That makes sense for product descriptions, categories, short summaries, etc, but as the text size increases, it gets more challenging. Additionally, the price you pay for using the model usually increases with the number of tokens you send.
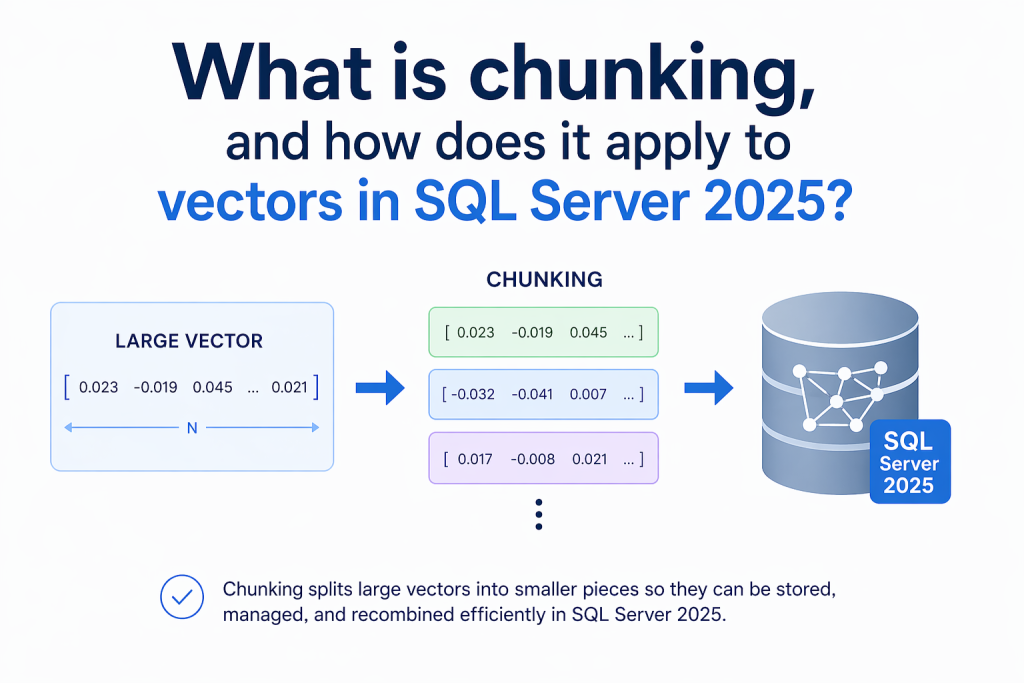
Chunking is the term used to describe breaking a larger document into smaller pieces before you generate embeddings for it. Each piece (or ‘chunk’) of text is then converted to a vector. The vector represents the semantic meaning of the text. We can then store the vectors and use them to search for other text with a similar meaning. So, the chunking determines the unit of meaning you’re going to work with, and will directly impact search quality.
When working with real documents, many are too large and too broad to embed as a single block. Think policy documents, a technical guide, contracts, a long article, transcripts…these often contain many topics and subtopics. A vector that represents the meaning of the large document ends up like some sort of average representation of what it contains. That’s not often useful unless you’re just looking for vague similarity. What you generally want is the part of the document that’s relevant to the search.
Issues with retrieval-augmented generation (RAG)
Another problem arises when working with retrieval-augmented generation (RAG). Relevant chunks of information are sent as part of the context when a prompt is sent to a language model.
It’s easy for the context ‘window’ to be full of irrelevant information which makes it hard to locate the actual useful information. The size of the context window can also be a limiting factor.
Good chunking balances precision and context. As well as the issues with chunks being too large, if the chunks are too small, there might not be enough related information to allow for correct interpretation.
Chunking methods, explained
There are different ways to chunk text.
- Fixed-size chunking splits content to a predefined length. This can be measured in characters, words, or tokens. This is the easiest way to perform chunking and is easy to automate.
- Sentence-based chunking tries to determine and preserve sentence boundaries.
- Paragraph-based chunking follows paragraph boundaries and often lets you work with the document structure much more closely.
- Semantic chunking tries to locate boundaries where the topic being discussed has changed.
When you’re chunking text, you also need to consider a concept called overlap. You might determine that it’s valuable to repeat part of the previous chunk at the start of the following one. The aim is to reduce the chance of important sections of text being separated from relevant context because of where chunking boundaries have fallen.
The downside of increasing overlap is that you’re storing more text, you need to send more text to generate embeddings, and you’re more likely to get duplicated matches in query response (because they’re referencing the same text.) The amount of overlap can be an important parameter to tune when designing chunking.
There’s no single correct answer for how to determine the best chunk size. It totally depends on the source text, the model being used, and the prompts coming from the users.
Fast, reliable and consistent SQL Server development…
Chunking in SQL Server 2025, explained
SQL Server 2025 added several functions for working with text embeddings, vectors, vector-based indexing, and searches.
The CREATE EXTERNAL MODEL command allows you to configure how calls can be made to a language model that calculates text embeddings. This can be a cloud-based system like OpenAI, or a local model hosted in a tool like Ollama. Learn more about the command here.
The AI_GENERATE_EMBEDDINGS function simplifies the generation of text embeddings once the external model has been defined, and the vector data type provides a convenient storage format for the embeddings. Learn more about the function here.
AI_GENERATE_CHUNKS rounds out the capabilities by letting you chunk text before you generate embeddings for it. It’s a table-valued function that chunks supplied text. The current documentation of the syntax shows that it accepts:
- The text to be chunked (
SOURCE) - The type of chunking to use (
CHUNK_TYPE) - The size of each chunk when using
FIXEDchunking (CHUNK_SIZE) - (Optional) The amount of overlap (
OVERLAP) - (Optional) An option to generate an ID for each chunk (
ENABLE_CHUNK_SET_ID).
Note that many of these AI functions are still in preview so the syntax, and the options allowed for each parameter, may change. It’s also worth noting that vector indexing and vector search have had substantial changes recently.
CHUNK_TYPE currently only has a single accepted value of FIXED. Whenever you see a required parameter with only a single value, it’s a hint that this is not the end of the story!
CHUNK_SIZE is required for FIXED (which is the only option right now), and is a positive number.
OVERLAP is the percentage of the previous text that needs to be included in a chunk. That’s a value between 0 and 50, and the default is 0 (i.e., no overlap).
If ENABLE_CHUNK_ID is 1, then a column called chunk_set_id is returned along with the chunks.
How it looks in practice – an example query
Let’s look at an example query:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
DECLARE @TextToChunk nvarchar(max) = N'A happy day feels light from the moment it begins. The sun seems warmer, ' + N'small things go right without effort, and there is a quiet sense of ease ' + N'in everything around you. Time spent with people you enjoy, good food, ' + N'laughter, and a few simple moments of calm can make the whole day feel ' + N'bright and memorable. By the end of it, you feel content, grateful, and ' + N'a little reluctant for it to end.'; SELECT * FROM AI_GENERATE_CHUNKS ( source = @TextToChunk, chunk_type = FIXED, chunk_size = 50, enable_chunk_set_id = 1 ) AS c; |
That query returns the following data:
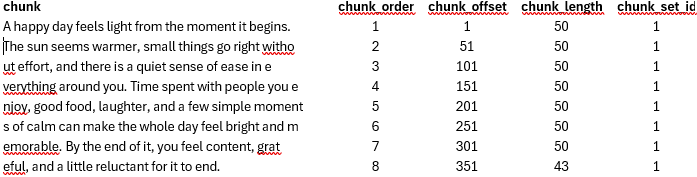
The chunk_order determines the order of the chunk in the original text. The chunk_offset determines the starting location within the original text. The chunk_length returns the final length of each chunk, and the chunk_set_id determines an ID for this set of chunks. The function is a table-valued function, generally called via CROSS APPLY or OUTER APPLY to process multiple rows, and it’s here you would see different sets.
Summary: Chunking in SQL Server 2025
These features mean that SQL Server 2025 can support a much stronger workflow for semantic retrieval. Text can be stored in tables, split into chunks with AI_GENERATE_CHUNKS, converted into embeddings with AI_GENERATE_EMBEDDINGS, stored in a vector column, and used with vector functions and vector indexes for similarity search. These capabilities greatly enhance the options available in SQL Server.
Simple Talk is brought to you by Redgate Software
FAQs: Chunking in SQL Server 2025
1. What is chunking in AI, and why is it important?
Chunking is the process of splitting large text into smaller sections before generating embeddings, helping improve search relevance and reduce processing costs.
2. How does chunking affect embedding quality?
Smaller, focused chunks produce more accurate vectors, while large chunks can dilute meaning and harm search precision.
3. What is the ideal chunk size for embeddings?
There’s no fixed answer – the best size depends on your data, model, and use case, but it should balance context with specificity.
4. What is overlap in chunking and when should you use it?
Overlap repeats part of the previous chunk to preserve context, which can improve understanding but increases storage and cost.
5. How does SQL Server 2025 support chunking?
SQL Server 2025 introduces the AI_GENERATE_CHUNKS function, allowing you to split text directly in the database before creating embeddings.
6. Can chunking improve RAG (retrieval-augmented generation)?
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved





Load comments