
In this article, I’ll lay out the technical details of implementing a simple Disaster Recovery Plan (DRP) for production applications running Microsoft SQL Server. My goal is to provide you with generic documentation to use as the basis of your own production system failover strategy. You will, of course, need to alter it with your own details and keep it updated any time that changes are made to your production systems, but this should give you a good departure point from which to build your own strategy.
I’ll describe the steps to follow in the event of the failure of a database production system, and annotate the process as I go along. This is largely based on a Disaster Recovery Plan I had to design recently (all the better for you to download and personalize), so it is deliberately written in the style of a business strategy document. I’ll also explain the advantages of automatic restoration of compressed backup files from a failover server. I’ll also be the first to admit that this topic might seem a little dry, but having a DRS will make it worth the read – I promise.
Part 1 of this article will describe the basic steps necessary to set up a ‘hot’ standby server (the recovery method I used when drafting this DRP), and Part 2 is an annotated transcript of Disaster Recovery document, including steps to be taken in the event of a disaster, and information for the unfortunate DBA tasked with recovering from it. Here we go:
PART 1 – Automatic Restoration of backup files to a failover server
SQL Servers’ norecovery mode keeps the database stable and ready to accept the changes you’re progressively applying as part of the backup process. This means that it’s only necessary to apply the latest differential or log backup before the database is ready to be accessed by users and applications.
The disaster recovery method used is to have a ‘hot’ standby server (SQL2), which is already installed, stable and, most importantly, is an exact copy of the production server’s configuration. The standby server should already have the most recent operational databases fully-restored in norecovery mode.
Implementing a Hot Standby Server
After SQL Server has been installed on the failover server, you need to check that Robocopy is installed in the sysroot\windows\system32 folder. Secondly, Red Gate’s SQL Backup software must connect to the server and be configured by clicking the small grey square next to server listing in left pane – this is for instance auto-configuration, if it has not been done already.
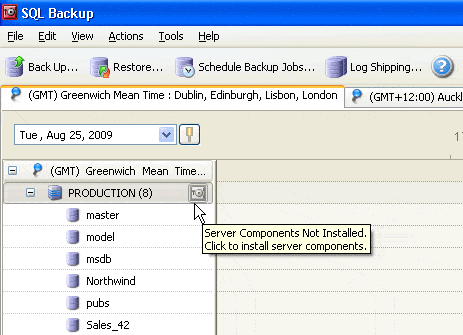
Figure 1 – SQL Backup’s auto-configuration system.
Robocopy is much better than ( the soon-to-be-discontinued) Xcopy, by the way. And since Windows Server 2003, Robocopy has been the recommended / future-proofed tool of choice. As far as I know, Xcopy will no longer be available in future versions of Windows Server.
Next, for the stored procedures that execute Robocopy (we place these procedures in a local database on each server called DBA_tools), you need to allow the advanced option xp_cmdshell to run:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
-- To allow advanced options to be changed. EXEC sp_configure 'show advanced options', 1 GO -- To update the currently configured value -- for advanced options. RECONFIGURE GO -- To enable the feature. EXEC sp_configure 'xp_cmdshell', 1 GO -- To update the currently configured value for this feature. RECONFIGURE GO |
In order to copy the backup files, each database on the standby server needs a database-specific SQL Server Agent job running Robocopy at the required interval to copy full and differential backups from the production server to the standby server. These jobs can be run at whatever frequency needed, be it daily, hourly or even more often if your operations require it.
Robocopy is the first step in all automated restore jobs, unless you want to add validation steps prior to the backup file copy. The following example copies all differential database backups from a production server to a DRP server:
|
1 2 3 4 |
EXEC dbo.usp_RoboCopy '\\PRODserver\drive$\ProdServerBackupShare\Diff', '\\DRPserver\Drive$\ProdServerDbBackupFolder\Diff', 'database1_* database2_*' -- This case just handles the differential folder, so we're assuming you'll also have -- a Tlog and Full folder. |
A database-specific SQL Server Job will restore these backups daily to the hot standby server (DRP) using stored procedures specifically created for this setup, such as:
usp_DB_Restore_Master or usp_DB_Restore_Master_Multiusp_DB_Restoreusp_DB_Restore_NoRecoveryusp_DB_Restore_differentialusp_DB_Restore_Log
A consideration for the DBA regarding the level of database recovery
If you are currently in Simple Recovery mode, and provided there are regular Transaction Log and differential backups (as in, several times a day), you can switch your recovery model over to Bulk-Logged in production to restore up to a specific point in time. This will naturally minimize the amount of data lost from the work session prior to any downtime.
Full Recovery mode is recommended for critical databases that require auditing compliance.
In the event of failure, the most recent log or differential backup is ready to be applied to the standby database sitting in norecovery mode, and you’re up and running quickly with minimal down-time.
An alternative method for a much smaller database, where the total restore time is below five minutes, is to apply the complete restore every hour to the failover server, in which case you don’t need to worry about norecovery mode.
PART 2 – Instructions to follow in the event of a disaster to the production system
- If you haven’t heard from them directly already, please contact FIRST LINE DBA SUPPORT at [INSERT NUMBER] or SECONDARY DBA at [INSERT NUMBER]
- After the production/original data publisher server failure (SQL1), the restore / backup-subscriber server (SQL2) will be used as the primary database server (a.k.a. DRP server). Inform everyone in the department by E-mail (It’s also worth thinking about who will inform internal/external clients).
- Once the switch occurs to the DRP server and the downtime of SQL1 actually happens, all application connection strings need to be changed to access SQL2. The CGI should handle this step automatically.
- Disable Automatic Restore SQL Agents on SQL2.
- Disable all SQL Agent jobs on failed server SQL1 if possible.
- Enable all maintenance and backup jobs on newly active server SQL2
Please note that restoring a log backup is not possible if the production database recovery model is set to Simple. For fine-grained restoration, the database needs to have been using the Full recovery model – Thankfully, the default setting is the Full Recovery model. If point in time recoveries are requested by management on a regular basis, then we can also change the database recovery level to Bulk-Logged, if space is an issue, and Full otherwise – Perhaps with deserved hesitation from the side of the Database Administrators, as Bulk-logged recovery is much more space efficient.
How the automation of the restore from compressed backup is benefitial to your production environment. Ideally you should keep two full backups, one on the Test server and one on the DRP server. Having this second copy of the production databases will allow you to do some useful and intensive work which you don’t want to have to run on live databases, such as a full DBCC CheckDB – console commands that can check the integrity of your exact database restore copy.
A log of what has been restored shall be placed in the following directory:
\\DatabaseServerName\drive$\prodBackupDir\DBlog\
As soon as a restore is completed, we should have an automatic purge of old backups – done perhaps every week (maximum 14 days manually, or automatically in a SQL Server Maintenance Plan), and which can be automated using a batch file or PowerShell Script.
To ensure a smooth restore process, we should read the restore parameters directly from the backup log system tables – such as BackupHistory, BackupSet, BackupFile or
Backuplog – unless a backuplog table is explicitly created in a local database or exists in msdb. This is to ensure that the essential restore parameters (such as the backup file name and position) are immediately available.
As I often set them, the SQL Agent Restore jobs have their parameters manually set during testing and are usually left that way – but of course it’s best to pull the meta-data directly from the system in case you move files around and forget to update the restore scripts.
SQL1 & SQL2 (Prod. & DRP) Server Hardware Configuration
This is the configuration for the servers this document was originally written for (I don’t remember the System Models for that setup, but that’s not to say you shouldn’t record yours) Update the following with your own server properties.
SQL1 (production instance)
|
1.1 |
Server Type |
Windows 2008 (standard x64 edition) |
|
1.2 |
System Model |
[Server Model Number, Product Type] |
|
1.3 |
RAM Memory |
8 Gig |
|
1.4 |
No. of CPU’s |
2 |
|
1.5 |
CPU & Speed |
AMD (x64) |
|
Drives |
Hard Disk Space |
C(#G);D(#G) |
SQL2 (storage replication partner / hot standby restore-subscriber)
|
1.1 |
Server Type |
Windows 2008 ( standard x64 edition ) |
|
1.2 |
System Model |
[Server Model Number, Product Type] – Same as SQL1 |
|
1.3 |
RAM Memory |
9 Gig |
|
1.4 |
No. of CPU’s |
2 |
|
1.5 |
CPU & Speed |
AMD (x64) Opteron Processor 280 |
|
Drives |
Hard Disk Space |
C(#G); D(#G); F(2TB); G(250GB); H (1.5TB); Z(20GB) This server should have terabytes and terabytes of space, depending on your archiving needs. |
SQL Server Configuration
For a previous client our production build of SQL Server was 9.0.3152, so naturally the DRP server had to be the exact same build – both systems must be as identical as possible.
Our servers are using 64-bit versions of the SQL Database Engine 2005/8, with at least service pack 2 (2005), cu3 (2008) installed, and the collation type is Latin1_General_CI_AS (accent sensitive is recommended). It is preferable to have at least Cumulative Rollup package 8 or SP3 for SQL Server 2005, and it’s important to do an update to production build levels of SQL on a regular basis.
Detailed information for the server and databases is included in the compiled help file located on both servers SQL1 and SQL2
D:\DRP\ServerName.chm (i.e. make it very easy to find DRP info)
Critical SQL Server User Database Details
1. List of databases
Database1
Database2
…
NB: We will not be doing master, msdb, model or temp – these are backed up on a regular basis and will be copied by Robocopy although not restored onto the database restore replication subscriber directly.
2. Database Maintenance Plan and Auto-Restore.
In general, our database restore plan will reflect exactly the backup schedule and wait for backups to finish by querying the metadata from the production server. The restore jobs will check to see if the days’ full backup has completed (or daily diff.) using the backupset.backup_finish_date column. Once we see that Full backup has been completed on the production server, we copy the backupfile over to the hot standby server. In the second step of the job, we continue to execute the code from the appropriate usp_DB_restore combined with the metadata extraction from the system tables.
3. Database Backup schedule in production
|
Maintenance Job Name |
Maintenance Job Description |
Freq |
Time to Run |
|
BackupFull_Database1 |
Full Database backup Database1 |
W |
Sunday 6:00 |
|
BackupFull_Database2 |
Full Database backup Database2 |
W |
Sunday 6:30 |
|
… |
… |
… |
… |
4. Restore jobs on DRP server
|
Maintenance Job Name |
Maintenance Job Description |
Freq |
Time to Run |
|
BackupFull_Database1 |
Full Database backup Database1 |
W |
Sunday 6:00 |
|
BackupFull_Database2 |
Full Database backup Database2 |
W |
Sunday 6:30 |
|
… |
… |
… |
… |
Critical Scripts, Procedures and Programs related to disaster recovery
Following is a list of all the code used for the DRP process from SQL1 to SQL2:
usp_DB_Restore_Master
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 |
CREATE PROC usp_DB_Restore_MasterRecovery -- Add the database name and input variables, instead of setting them on lines 40-23. AS DECLARE @filename VARCHAR(255) , @cmd VARCHAR(500) , @cmd2 VARCHAR(500) , @dbNameSource sysname -- This is an input parameter, unless you are testing. ,@dbNameTarget sysname -- This is an input parameter, unless you are testing. ,@FullRestoreFolder NVARCHAR(MAX)-- This is an input parameter, unless you -- are testing. ,@dbNameStatement NVARCHAR(MAX) , @dbNameStatementDiff NVARCHAR(MAX) , @LogicalName VARCHAR(255) , @PhysicalName VARCHAR(255) , @Type VARCHAR(20)-- Useful if reading the backup headers, no? -- As part of the validation perhaps. ,@FileGroupName VARCHAR(255) , @Size VARCHAR(20) , @MaxSize VARCHAR(20) -- Check what I do above and use what's below -- if relevant. ,@filelistStatmt1 VARCHAR(MAX) , @filelistStatmtDiff VARCHAR(MAX) /* The following variables are set up for testing and may be taken off when sp is used afterwards (if we cannot get them reliably from sys databases automatically). */ ,@backupFile sysname -- will grab from local test .sqb files first. ,@logicalDataFile sysname /* I am developing this code first assuming that we will only have one data file and logical file for each database. Later we'll add support for multiple logical and physical files (there may be, in Database1's case, more than one row for dbo.sysfiles where fileid=1 and groupid=1). */ ,@logicalDataStmt1 NVARCHAR(MAX) , @logicalDataStmt2 NVARCHAR(MAX) , @logicalDataStmt3 NVARCHAR(MAX) , @logicalLogFile sysname -- Returned and verified. ,@logicalLogStmt1 NVARCHAR(MAX) -- So many annoying variables. If I could just ,@logicalLogStmt2 NVARCHAR(MAX) -- read the header it'd be easier in the future. ,@logicalLogStmt3 NVARCHAR(MAX) , @physicalDataFile sysname -- Easy to grab since it was in master. ,@physicalLogFile sysname -- Need two variables. ,@physicalLogFileStmt1 NVARCHAR(MAX) , @physicalLogFileStmt2 NVARCHAR(MAX) , @physicalLogFileStmt3 NVARCHAR(MAX) SET NOCOUNT ON -- Following best practices, although we're not throwing around big -- counts anyway. -- Parameters and variables set by Hugo for testing. SET @FullRestoreFolder='\\testServer\Drive$\ProdServerBackupFolder\full\' SET @dbNameSource ='Database1' SET @dbNameTarget ='Database1' -- Sometimes we want to over-write another database -- (e.g. in the case of importpdm_tst). SET @physicalDatafile=( SELECT filename FROM MASTER.dbo.sysdatabases WHERE NAME=@dbnameTarget) PRINT 'The physical data FILE TO RESTORE IS '+@physicalDatafile SET @logicalDataStmt1='select top 1 name from [' SET @logicalDataStmt2='].dbo.sysfiles where fileid=1 and groupid=1' SET @logicalDataStmt3 = (@logicalDataStmt1+@dbNameTarget+@logicalDataStmt2) /* I wanted to do an execute at this line but I kept thinking that if it was within a single statement, my set statement @logicalDataFile would take the result of the query (select top 1 name from PROD_PASRAA.dbo.sysfiles where fileid)=1 and groupid=1. */ CREATE TABLE #logicalDataFile -- Drop table #logicaldatafile. ( logicalDataFile sysname ) INSERT INTO [#logicalDataFile] ( logicalDataFile ) EXEC (@logicalDataStmt3) -- Now set the variable from the temp finally. SET @logicalDataFile=( SELECT * FROM #logicalDataFile) -- Check out a temp table method...need the result set from. PRINT 'the logical data file is '+@logicalDataFile SET @logicalLogStmt1='select top 1 name from [' SET @logicalLogStmt2='].dbo.sysfiles where fileid=2 and groupid=0' -- Put the statement together. SET @logicalLogStmt3 = (@logicalLogStmt1+@dbNameTarget+@logicalLogStmt2) CREATE TABLE #logicalLogfile -- Drop table #logicalLogfile. ( logicalLogFile sysname ) INSERT INTO [#logicalLogFile] ( logicallogFile ) EXEC (@logicallogStmt3) -- Now set the variable from the temp finally. SET @logicalLogFile=( SELECT * FROM #logicalLogFile) PRINT 'the logical log file is '+@logicalLogFile -- Has the right value -- grab the last db file related variable from sysfiles. SET @physicalLogFileStmt1='select filename from [' SET @physicalLogFileStmt2='].dbo.sysfiles where fileid=2 and groupid=0' SET @physicalLogFileStmt3 = (@physicalLogFileStmt1+@dbNameTarget+@physicalLogFileStmt2) CREATE TABLE #physicalLogFile -- Drop table #physicalLogFilefile. ( physicalLogFile sysname ) INSERT INTO [#physicalLogFile] ( physicalLogFile ) EXEC (@physicalLogFileStmt3) -- Now set the variable from the temp finally. SET @physicalLogFile=( SELECT * FROM #physicalLogFile) PRINT 'the physical log file is '+@physicalLogFile /* All verified up to here, and we're ready for some backup logic.Grab the corresponding file for the restore folder, and according to following inputs full restore file. */ CREATE TABLE #dirList (filename NVARCHAR(MAX)) CREATE TABLE #filelist ( LogicalName NVARCHAR(MAX) , PhysicalName NVARCHAR(MAX) , [Type] VARCHAR(20) , FileGroupName VARCHAR(50) , Size VARCHAR(20) , MaxSize VARCHAR(20) ) -- Get the list of database backups that are in the restoreFromDir directory. IF @dbNameSource IS NULL -- If @OneDBName is null. -- For our purposes we are only using one database name for this. SELECT @cmd = 'dir /b /on "' +@FullRestoreFolder+ '"' -- Select @cmd = 'dir /b /on ' -- +@restoreFromDir+ ELSE SELECT @cmd = 'dir /b /o-d /o-g "' +@FullRestoreFolder+ '"' INSERT #dirList EXEC master..xp_cmdshell @cmd -- Select filename from #dirlist whose list of files is good. SELECT @dbNameStatement= 'full%_'+@dbnameSource+'_200%_%.sqb' - SQB IS FOR SQLBACKUP SET @filelistStatmt1=( SELECT TOP 1 filename FROM #dirList WHERE filename LIKE @dbNameStatement) PRINT 'This is the full backup file to be restored '+@filelistStatmt1 SET @backupfile=(@FullRestoreFolder)+(@filelistStatmt1) PRINT 'this is the full path to the full restore file that will be restored ' + @backupfile EXEC DBA_Tools.dbo.[usp_DB_Restore] @backupfile, @dbnameTarget, @logicalDataFile, @logicalLogFile, @physicalDataFile, @physicalLogFile |
usp_DB_Backup & usp_DB_Restore
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 |
-- ============================================= -- Description: Restore Database -- Parameter1: Restore File Name -- Parameter2: Full path of file location i.e. 'DriveName:\BackupShare\' -- Parameter3: RestoreType -- FDN=full or differential no recovery, FDR = full or differential with recovery, -- LN=log no recovery, LR=log with recovery -- File Extensions: Full = *.bak , Differential= *.dif, T- Log= *.trn , *.sqb -- (SQLBackup) -- ============================================= CREATE PROCEDURE [dbo].[usp_DB_restore] @RestoreFileName SYSNAME, @LogicalNameData SYSNAME, @LogicalNameLog SYSNAME, @RestorePathData SYSNAME, @RestorePathLog SYSNAME, @ResoreType CHAR(1) AS BEGIN SET NOCOUNT ON ; DECLARE @SqlCmd NVARCHAR(2000) DECLARE @DateTime SYSNAME DECLARE @BakupFile NVARCHAR(1400), @DiffFile NVARCHAR(1400), @LogFile NVARCHAR(1400) IF @ResoreType = 'FDN' SET @SqlCmd = 'RESTORE DATABASE ' + QUOTENAME(@DBName) + ' TO DISK = ' + @Bakupfile + 'WITH INIT' IF @ResoreType = 'FDR' SET @SqlCmd = 'RESTORE DATABASE ' + QUOTENAME(@DBName) + ' TO DISK = ' + @Bakupfile + 'WITH INIT' IF @ResoreType = 'LN' SET @SqlCmd = 'RESTORE LOG ' + QUOTENAME(@DBName) + ' TO DISK = ' + @LogFile + IF @ResoreType = 'LR' SET @SqlCmd = 'RESTORE LOG ' + QUOTENAME(@DBName) + ' TO DISK = ' + @LogFile + PRINT @SqlCmd EXECUTE sp_executesql @SqlCmd END |
usp_DB_Restore_NoRecovery
Same as above, but for databases that need to be left in no recovery mode (e.g. waiting for a log backup to be applied or differential)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 |
CREATE PROC [dbo].[usp_DB_Restore_NoRecovery] -- input variables when it all works below @backupfile SYSNAME, @dbName SYSNAME, @logicalDataFile SYSNAME, @logicalLogFile SYSNAME, @physicalDatafile SYSNAME, @physicalLogFile SYSNAME AS DECLARE @exitcode INT DECLARE @sqlerrorcode INT DECLARE @restoreStmt NVARCHAR(MAX) SET NOCOUNT ON -- Kill any users in the database nicely? well, not really nicely. EXEC usp_KillConnections @dbName SET @restoreStmt = N'-SQL RESTORE DATABASE ' + @dbName + ' FROM DISK = ' + @backupfile + ' WITH NORECOVERY ,MOVE ' + @logicalDataFile + ' TO ' + @physicalDatafile + ' ,MOVE ' + @logicalLogFile + ' TO ' + @physicalLogFile + ' ,REPLACE ,LOGTO = "\\ServerName\Drive$\SourceServerName\DBlog<DATABASE>_<TYPE>_ <DATETIME yyyymmddhhmss>.txt"' --PRINT @restoreStmt EXEC master..sqlbackup @restoreStmt, @exitcode OUT, @sqlerrorcode OUT IF ( @exitcode >= 500 ) OR ( @sqlerrorcode <> 0 ) BEGIN RAISERROR ( 'SQL Restore failed with exit code: %d SQL error code: %d', 16, 1, @exitcode, @sqlerrorcode ) END |
usp_DB_Restore_Differential
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 |
-- restore directly from our copy which is automatically brought local using robocopy -- EXEC [usp_DB_restore_Differential] -- '\\TestServer\Drive$\ProductionServer\Diff\ -- DIFF_ServerName_DB_20080301_210001.sqb', -- 'DBname', 'LogicalDataFileName', 'LogicalLogFileName', -- 'Drive:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\Data\Database1.mdf', -- 'Drive:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\Data\ -- Database1_log.ldf' -- drop proc [usp_DB_restore_Differential] CREATE PROC [dbo].[usp_DB_Restore_Differential] -- Input variables when it all works below. @backupfile SYSNAME, @dbName SYSNAME, @logicalDataFile SYSNAME, @logicalLogFile SYSNAME, @physicalDatafile SYSNAME, @physicalLogFile SYSNAME AS DECLARE @exitcode INT DECLARE @sqlerrorcode INT DECLARE @restoreStmt NVARCHAR(MAX) SET NOCOUNT ON EXEC usp_KillConnections @dbName -- WITH RECOVERY is used after a full restore is done already, and a final -- differential is applied to it (restore differential should be on a db in -- NORECOVERY MODE). SET @restoreStmt = N'-SQL RESTORE DATABASE ' + @dbName + ' FROM DISK = ' + @backupfile + ' WITH NORECOVERY ,MOVE ' + @logicalDataFile + ' TO ' + @physicalDatafile + ' ,MOVE ' + @logicalLogFile + ' TO ' + @physicalLogFile + ' ,REPLACE ,LOGTO = "\\DRPServerName\Drive$\ProdServerBackupFolder\DBlog\<DATABASE>_<TYPE>_ <DATETIME yyyymmddhhmss>.txt"' -- PRINT @restoreStmt EXEC master..sqlbackup @restoreStmt, @exitcode OUT, @sqlerrorcode OUT IF ( @exitcode >= 500 ) OR ( @sqlerrorcode <> 0 ) BEGIN RAISERROR ( 'SQL Restore failed with exit code: %d SQL error code: %d', 16, 1, @exitcode, @sqlerrorcode ) END |
usp_DB_Restore_Log
Should allow multiple logs to be automatically applied
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 |
SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO /* EXEC [usp_DB_restore_log] '\\ProdServer\Drive$\ProdServerDBbackups\Full\ FULL_ServerName_DatabaseName1_20080217_030000.sqb', 'LogicalFileName', 'LogicalDataFile', 'LogicalLogFileName', 'Drive:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\Data\Database1.mdf', 'Drive:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\Data\Database1_log.ldf' drop proc [usp_DB_restore_log] */ CREATE PROC [dbo].[usp_DB_restore_log] -- Input variables when it all works below. @backupfile SYSNAME, @dbName SYSNAME, @logicalDataFile SYSNAME, @logicalLogFile SYSNAME, @physicalDatafile SYSNAME, @physicalLogFile SYSNAME /* System table backupfile on production server can give us LSN (log sequence number), logical_name, physical_drive and physical_name. If not, to grab the possible backup sets that are usable, see ms-help://MS.SQLCC.v9/ MS.SQLSVR.v9.en/tsqlref9/html/f1a7fc0a-f4b4-47eb-9138-eebf930dc9ac.htm. */ AS DECLARE @exitcode INT DECLARE @sqlerrorcode INT DECLARE @restoreStmt NVARCHAR(MAX) SET NOCOUNT ON -- We will not need to kill connections, since the database is in restoring state -- already, waiting for a log. -- EXEC usp_KillConnections @dbName -- Transaction logs must be applied in sequential order. If there are multiple -- transaction logs to apply we have to leave the NORECOVERY option on. /* In most cases, under the full or bulk- logged recovery models, SQL Server 2005 requires that you back up the tail of the log before restoring a database that is currently attached on the server instance. A tail-log backup captures the log that has not yet been backed up (the tail of the log) and is the last backup of interest in a recovery plan. Restoring a database without first backing up the tail of the log results is a mistake, unless the RESTORE statement contains either the WITH REPLACE or WITH STOPAT clause. A tail-log backup can be created independently of regular log backups by using the COPY_ONLY option. A copy-only backup does not affect the backup log chain. The transaction log is not truncated by the tail-log backup, and the log captured will be included in future normal log backups. This allows tail-log backups to be taken, for instance, to prepare for an online restore without affecting normal log backup procedures. For more information, see Copy-Only Backups (Full Recovery Model). */ -- Restore log info ms-help://MS.SQLCC.v9/MS.SQLSVR.v9.en/tsqlref9/html/ 877ecd57-3f2e-4237-890a-08f16e944ef1.htm. SET @restoreStmt = N'-SQL RESTORE Log ' + @dbName + ' FROM DISK = ' + @backupfile + ' WITH RECOVERY ,MOVE ' + @logicalDataFile + ' TO ' + @physicalDatafile + ' ,MOVE ' + @logicalLogFile + ' TO ' + @physicalLogFile + ' ,REPLACE ,LOGTO = "\\TestServer\d$\TtestDB\DBLog\<DATABASE>_<TYPE>_ <DATETIME yyyymmddhhmss>.txt"' --PRINT @restoreStmt EXEC master..sqlbackup @restoreStmt, @exitcode OUT, @sqlerrorcode OUT IF ( @exitcode >= 500 ) OR ( @sqlerrorcode <> 0 ) BEGIN RAISERROR ( 'SQL Restore failed with exit code: %d SQL error code: %d', 16, 1, @exitcode, @sqlerrorcode ) END |
usp_RoboCopy
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 |
CREATE PROCEDURE [dbo].[usp_RoboCopy] ( @srcUNC SYSNAME, -- Source Server Name. @dstUNC SYSNAME, -- Destination Server Name. @filelist VARCHAR(1024) -- Space delimited list of files to be copied. ) AS /*****************************************************************/ -- Stored Procedure : usp_RoboCopy -- Creation Date : 2009-02-26 -- Written by : Stephen Mandeville, adapted by Hugo Shebbeare /*************************************************************************/ SET NOCOUNT ON DECLARE @ccmd VARCHAR(1500) DECLARE @logfile VARCHAR(25) DECLARE @retcode INT /**************************************************************************/ -- This stored procedure uses ROBOCOPY.exe, which is installed on server itself -- in the sysroot\windows\system32 folder (default on 2008). -- The Source and Destination shares must exist. /***************************************************************************/ SELECT @logfile = REPLACE(SUBSTRING(( CONVERT(VARCHAR(15), GETDATE(), 121) ), 1, 10), '-', '') + REPLACE(SUBSTRING(( CONVERT(VARCHAR(30), GETDATE(), 121) ), 12, 8), ':', '') SELECT @ccmd = 'ROBOCOPY ' + @srcUNC + ' ' + @dstUNC + ' ' + @filelist + ' /NP /LOG:' + @dstUNC + '\transfer' + '_' + @logfile + '.txt' --PRINT @ccmd EXECUTE @retcode = master..xp_cmdshell @ccmd /***************************************************************************/ -- The return code (@retcode) from Robocopy (version 1.74 and later) is a --bit map, defined as follows: -- -- Value MeaningIfSet -- 16 Serious error. Robocopy did not copy any files. This is either a -- usage error or an error due to insufficient -- access privileges on the -- source or destination directories. -- 8 Some files or directories could not be copied -- (copy errors occurred and the retry limit was -- exceeded)Check these errors further. -- 4 Some Mismatched files or directories were detected. -- Examine the output log. -- Housekeeping is probably necessary. -- 2 Some Extra files or directories were detected. -- Examine the output log. -- Some housekeeping may be needed. -- 1 One or more files were copied successfully.that is, new files -- have arrived). -- 0 No errors occurred, and no copying was done. -- The source and destination -- directory trees are completely synchronized. /**************************************************************************/ -- Raising error only upon @retcode > 7. IF @retcode > 7 BEGIN RAISERROR ( 'Error occurred while executing Robocopy', 16, 1 ) RETURN ( @retcode ) END --IF @retcode > 7 ELSE BEGIN RETURN ( @retcode ) END --ELSE |
usp_KillConnections
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 |
IF NOT EXISTS ( SELECT * FROM sys.objects WHERE OBJECT_ID = OBJECT_ID(N'[dbo].[usp_KillConnections]') AND type IN (N'P', N'PC')) BEGIN EXEC dbo.sp_executesql @statement = N' /***************************************************************** *** Procedure: usp_KillConnections *** Usage: usp_KillConnections @dbname = ''Database Name'' *** Description: Drop all connections from a specific database *** Input: @dbname - REQUIRED - Name of the database *** Output: Outputs the results of the proccess *** Revision: 1.0 *** Revision History: 1.0 First Release *** Author: Antonio Pedrosa Linares *** Date: 7/25/2007 ******************************************************************/ -- exec usp_KillConnections ''staplescpc'' create procedure [dbo].[usp_KillConnections] @dbname varchar(128) as declare @spid varchar(5) declare @loginname nvarchar(128) declare @intErrorCode int declare @intOk int declare @intError int declare @intTotal int set @intErrorCode = 0 set @intOk = 0 set @intError = 0 set @intTotal = 0 select @intTotal = count(sp.spid) FROM master..sysprocesses sp JOIN master..sysdatabases sd ON sp.dbid = sd.dbid WHERE sd.name = @dbname declare KILL_CONS cursor for SELECT cast(sp.spid as varchar(5)),rtrim(sp.loginame) FROM master..sysprocesses sp JOIN master..sysdatabases sd ON sp.dbid = sd.dbid WHERE sd.name = @dbname OPEN KILL_CONS FETCH NEXT FROM KILL_CONS INTO @spid,@loginname WHILE @@FETCH_STATUS = 0 BEGIN EXEC(''Kill ''+ @spid + '''') SELECT @intErrorCode = @@ERROR if @intErrorCode = 0 begin set @intOk = @intOk + 1 PRINT ''Process '' + @spid + '' from login '' + @loginname + '' has been ended.'' end else begin set @intError = @intError + 1 PRINT ''Process '' + @spid + '' from login '' + @loginname + '' could not be ended.'' end FETCH NEXT FROM KILL_CONS INTO @spid,@loginname END CLOSE KILL_CONS DEALLOCATE KILL_CONS PRINT ''Total number of processes from database '' + @dbname + '': '' + cast (@intTotal as varchar) PRINT ''Processes ended normally: '' + cast(@intOk as varchar) PRINT ''Processes could not be ended: '' + cast(@intError as varchar)' END |
System Database Backups
On the DRP server itself the backups of the MSDB, DBAs databases, which are critical to this whole DRP process are located here:
\\DRPServerName:\DRPbackupFolder\Full
There should always be an alternative local backup location for system databases, such as on the Test server.
All DBAs and system databases are backed up as well as on:
\\TstServerName:\TestSrvBackupFolder\Full
The following example was tested on a primary test server and exists on the restore server. The usp_DB_restoreX stored procedure takes 6 input parameters. To match up with backup log metadata, we shall match up the database name by date and then pull the relevant restore file input parameter into the appropriate usp_DB_restoreX stored procedure. The master restore procedures, divided into single file and multiple file restore procedures, use all the sub procedures to do the actual restore process.
Please note that the usp_DB_RestoreX stored procedures are dependent on usp_KillConnections which will help in the restoration process by killing the existing database users (that is, unless it’s a system user however).
e.g.
|
1 2 3 4 5 |
EXEC DBA_Tools.dbo.usp_DB_restore '\\TestServerName\Drive$\ProductionBackupFolder\ Full\FULL_ServerName_Database1_20080217_030000.sqb', 'DBlogicalName' 'DB_DataFile_Logicalname', 'DB_LogFileLogical_name', 'DriveName:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\Data\ DBphysicalDataFileName.mdf', 'DriveName:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\Data\ DBphysicalLogFileName_log.ldf' |
The stored procedure usp_DB_restore_norecovery is the same as usp_DB_restore, only for Databases that need to be left in norecovery mode (as described earlier in the article)
Please view the Activity History from Red Gate SQL Backup for reporting on what databases have been backed up, as the scope of this document covers the restoring process only. Although the backup information is extracted to prepare the automated restore scripts within the jobs, we are not going to create (at least at this stage) customised backup reporting information. However, do not forget that, since we are using these scripts within a SQL Server Agent job, we will have histories for each step and a log file written to the \DBlog\ folder local to the disaster recovery server running these SQL Agent Jobs.
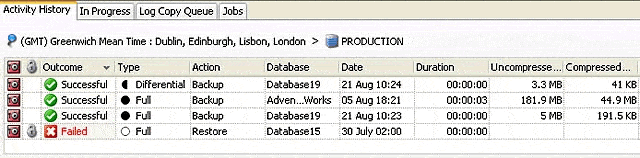
Figure 2 – SQL Backup Activity Log
Database Restore method when applying Differential Backups.
Please note that we use usp_restore_db_norecovery to load a production backup from the local copy moved over using Robocopy. Thus, if executed on the DBA database of the DRP server (SERVER NAME / INSTANCE NAME):
|
1 2 |
EXEC DBA_Tools.dbo.usp_DB_restore_norecovery \\DRPserver\InstanceName\full\FULL_ServerName_Database_20080217_030000.sqb', 'VSOT2', 'VSOT2_data', 'VSOT2_log, 'D:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\Data\VSOT2.mdf, 'D:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\Data\VSOT2_log.ldf' |
This will be the core of what runs for the second step of an automated job which leaves the database in NoRecovery mode, and thus should call the respective RestoreDiff_dbx next and, finally, apply the log files via RestoreLog_dbx.
After the restore, make sure to run several tests that ensure the integrity of the data and that typical applications can run normal operations on the database.
Summary
Is this disaster recovery method really minimizing the manual intervention after failure? Can we make it better? Yes and yes, but there’s always room to improve. More importantly, this method certainly doesn’t suit every environment. Before you take what I’ve put together here and run with it, I strongly recommend you take a look at the High Availability Options table below to get a clear picture of what methodologies might be more appropriate for you individual needs. To make an effective choice, you’re naturally going to need a detailed understanding of each clients’ needs for the restore process.
High Availability Options
|
Solution |
Cost |
Complexity |
Failover |
Failback |
|
Hardware Clustering |
High |
High |
Fast |
Fast |
|
Software Clustering |
High |
High |
Fast |
Fast |
|
Replication |
Medium |
Medium |
Medium with manual |
Slow with manual |
|
Continuous Data |
Medium |
Medium |
Medium |
Slow |
|
Log Shipping |
Low |
Low |
Medium |
Slow |
|
Backup and |
Low |
Low |
Slow |
Slow |
|
Database Mirroring |
Low |
Low |
Fast, but only at the |
Fast, but only at the |
At the time of writing, our backup-and-restore is super slow – at least 13 hours before we were live on the warm standby – but if optimization is run, we should be done in around 2 hours.
Nobody wants to go through a disaster without being properly prepared. When I was asked to prepare a plan for Canada’s largest institutional fund manager, I took it rather seriously, hence the length of this document. We ran this through a real disaster recovery test over a weekend, and it all worked out just fine. I’ve tried to share with you exactly how you can get your own disaster recovery plan in place, so that when the time comes at least the recovery step itself is not a disaster.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments