
Being a database administrator means you have taken up a career as a DBA, and not necessarily a vendor-specific DBA. If a challenge that arises which requires your services as a DBA, it may not necessarily be your favourite flavour of RDBMS that is the best solution for your employer, or client. Specialists sometimes maintain that you cannot be a Master/Mistress of more than one database management system. However, I’d like to argue that DBAs should diversify as a way to improve their marketable skills or competitiveness, broaden their knowledge and innovative thinking.
Surely, any Database Administrator who really understands databases and SQL standards could work quite well with any of the leading Relational Database Management Systems (RDBMS). If you want to become what I describe as a polyglot of databases, equally confident in a range of RDBMSs, you must first have an excellent grasp of the fundamentals of RDBMSs, such as normalisation and indexing, and understand the importance of certification and practice.
In the same way that knowing several languages can help you to know your own language better, I believe that taking the deep dive into another RDBMS can also broaden your approach to resolving problems in your ‘native’ RDBMS. Being multilingual myself, I was briefly tempted to give this article the long-winded title “Applying the Principles of a Polyglot to Database Management: How Shrewd DBAs Benefit from MySQL and Oracle, Over and Above SQL Server”.
Oracle 11g R2 and Developer 2.1 – The Latest Toys from the Oracle World
It can be quite an initial shock to move from one RDBMS to another. If you come from a predominantly Oracle background, then you will be interested in a fine series on Crossing the Great Divide from Oracle to SQL Server by Jonathan Lewis. My shock was in the other direction. Although I originally trained on Oracle 8 in 1998 at Oracle Montreal’s offices, I’ve predominately worked with SQL Server thereafter. I’ve recently spent over a year of working once again with Oracle 11gR2 and its solid architecture. The hardest part initially was re-learning the complete set of Acronyms related to Oracle’s architecture, such as SMON, PMON, P/SGA, DBWn, RECO, XDB, ARCn et al. It was worth the struggle, though, and I’m impressed with it. When tackling a different RDBMS, one soon notices features that are done particularly well: I especially appreciate the database-recovery approach that Oracle takes, especially the redo/undo log files and using the SCN (system change number, defined during a checkpoint) for bombproof recovery. With MSSQL, it is possible to lose your backup recovery chain (i.e. be unable to match LSN numbers) with mixed Tape/Disk backups. Helpfully, with Oracle’s use of the SCN, this is not such an issue, since control files won’t even start up the database without the correct SCNs.
More examples of this solid architecture can be seen during the mount process: During this, there is a fail-safe check for the control file(s) to permit the instance to start, or to avoid Startup Open because one might want to benefit from the way that Startup Restrict can allow easy maintenance operations. After starting a database instance, the Oracle software will then associate the instance with a specific database. This is called ‘mounting the database’. I have created the diagram below as an expansion from a rudimentary diagram from the Official course materials, so as to help you understand why I admire the way in which an Oracle database is opened.
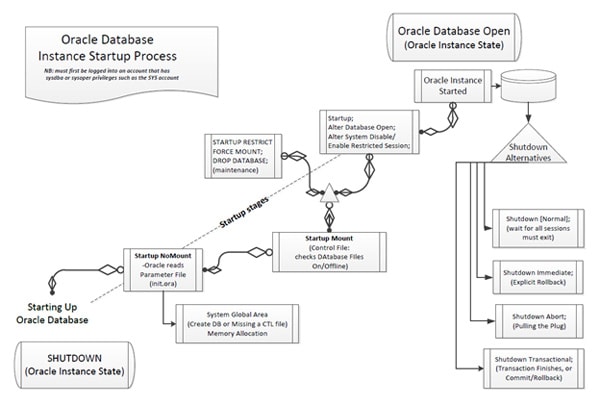
Figure 1. The Oracle Database Start-up Process
Oracle Developer 3.0 early adopter version, as seen below, is a cool management tool which also comes with a user-friendly ability to export result sets to XLS/CSV/TXT, although I personally prefer SQL Server Management Studio (having been made SQL Server MVP, I can hardly avoid a natural bias). Many SQL Plus commands are supported within Developer 3.0, which also now let’s you handle the DBMS job scheduler, as well as how many times a job is executed. Also not to be ignored in the Oracle world is the excellent web-based Enterprise Manager 11g from Oracle, also known as Grid Control, though it takes a while to work out how you find your way around. However, once you’re familiar with it, you’ll discover that this tool is rich in features. It is useful for monitoring health, availability and performance, as well as performing virtually all of your normal administrative tasks.
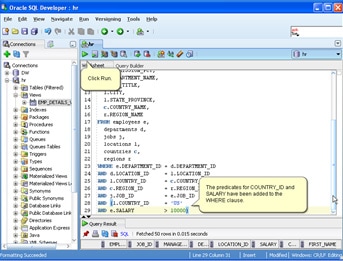
Figure 2. Screenshot of Oracle Developer 3.0, taken from a presentation demonstrating the Query Builder
Seasoned Oracle DBAs have mentioned the lack of spooling in Oracle Developer as a pain-point: Spool actually works fine in Oracle Developer 2.1/3.0, although I’ll admit that it works better in SQL Plus. Settings like Timing, Echo, Feedback, Show User, and Show Errors make it much easier to discover, in both tools, what went wrong and where in your code, so take advantage of these features.
Oracle Developer and SQL Server Management Studio always have the code and results split up into separate windows: This not always make it easy to associate the error with the section of code you are working on, unless you click on the error in SSMS’ report pane (as a side note, see my auditing preference for SSMS). Setting the Spool on and off after working on production provides comprehensive evidence for auditing operations on your production databases or for results during testing and development.
Moving Forward with Oracle Certification, Albeit Slowly.
If you want to be proficient with Oracle, then it makes sense to get yourself some training and certification. You can make some progress with a bit of self-learning, but if you really want to get the most out of a new database ‘language’, then you’re doing yourself a disservice if you don’t do your best to tool up. If this is something you’re exploring, then remember that you have to make time to prepare for exams, and while there is always too much work to do (e.g. e-mail deluge), allocating a few hours a week to training makes all the difference. Even so, trying to get through the over-one-thousand pages of official Oracle course material has been very hard, but YouTube training videos from community colleges in the U.S. make great background noise while trudging through monotonous tasks! Hopefully I will not be shown the door by Microsoft as an MVP for preaching heterodoxy (bearing in mind that my main reason for diversifying is that my employer has asked for it, and the benefits are a welcome by-product).
I will not spend any more time describing what might entice one to use Oracle as a SQL Server DBA, because Jonathan Lewis has written substantially and thoughtfully on comparing Oracle with SQL Server, even exploring how the two platforms compare in their handling of heaps, and indexes. For the purposes of this article, my goal with the above is open the door to the understanding of Oracle’s solid architecture.
MySQL 5.x and Workbench 5.2
Pre-requisite: To follow some of what I’ll be covering next, you need to have a copy of MySQL Workbench 5.2. It’s a great tool, was released July 1st, 2010, and has – thus far – been updated every month with point releases. You can download the latest version of the Workbench tool for all common operating systems from the MySQL.com site.
As part of a group of DBAs asked to handle a large group of MySQL Instances (once you include all the test, development and production environments too) the most useful software we found was this great administrative tool, MySQL Workbench.
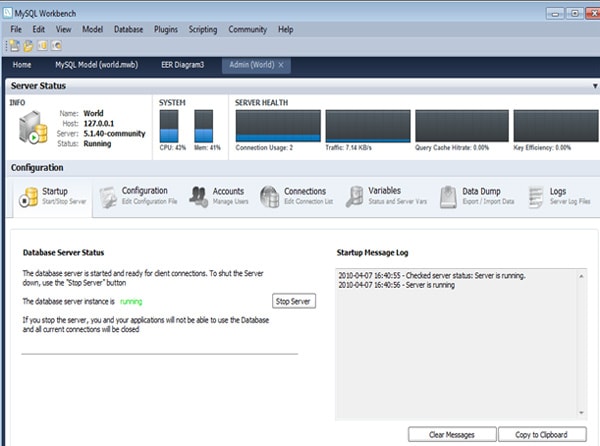
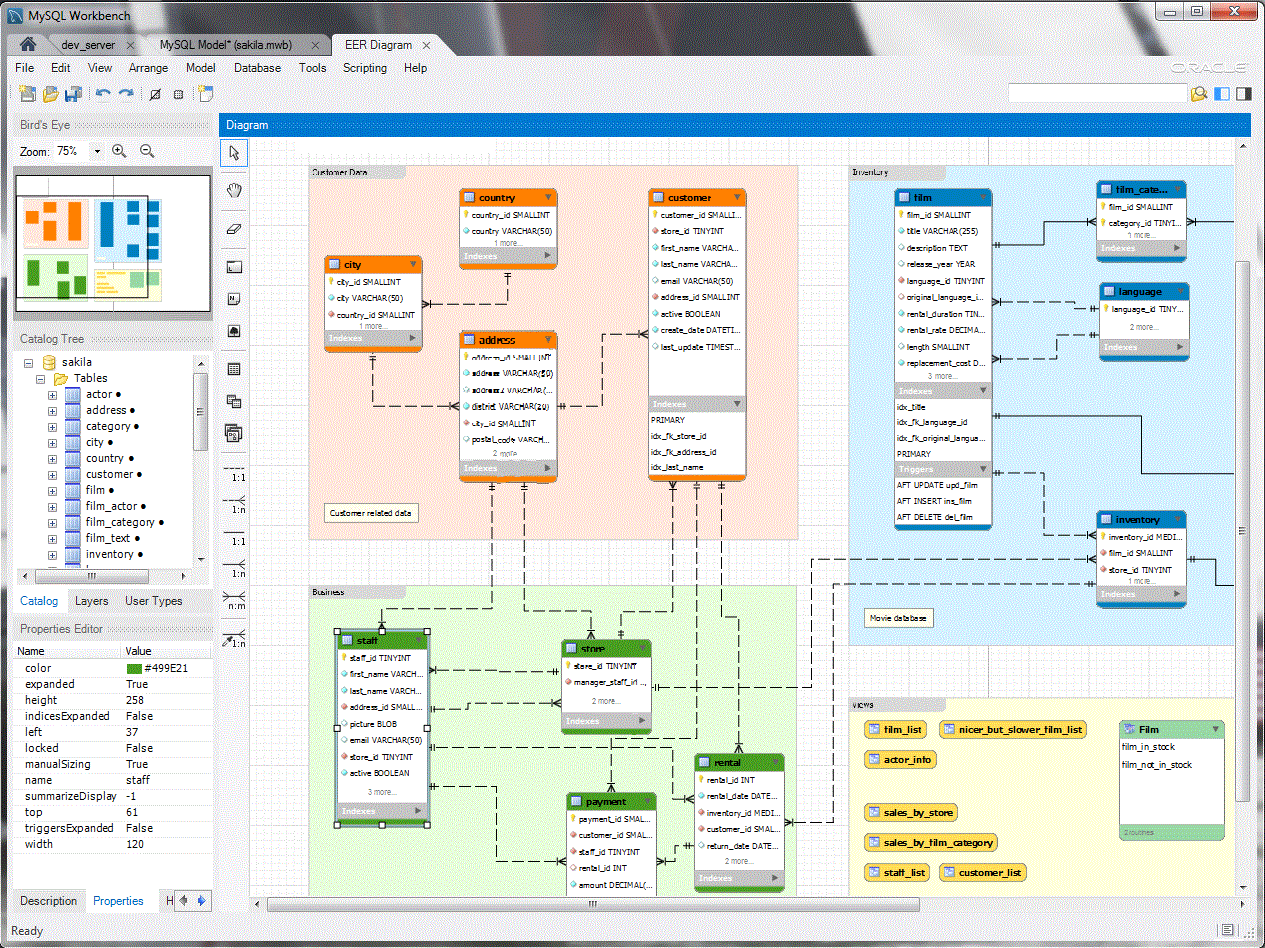
Figure 3. The main dashboard of MySQL Workbench 5.2
We were pleasantly surprised to discover that the tool is pretty well fleshed-out, in terms of what your average DBA might expect. Not only did it have the typical SQL Editor Query window, a connection manager that supports SSH connections to instances, but it also has a humble entity relationship diagram tool called Data Modelling built in, just like all the larger vendors do.
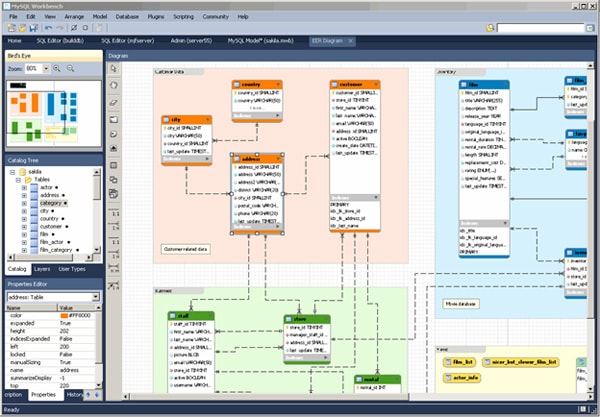
Figure 4. MySQL Workbench 5.2’s Data Modelling tool, as seen on the MySQL.com site.
{kind=link}
MySQL’s InnoDB Engine Should Be Handled Carefully
Before you think that I have nothing but praise for MySQL, I do have some nightmarish anecdotes of InnoDB log issues which some colleagues have hit up against. In short, I recommend that you be very careful with the InnoDB log_file_size setting, since the entire database engine itself can be disabled silently, as David Pashley describes. What makes the problems which we encountered more painful is that they would have been easily avoided in another RDBMS , and that is not very impressive when you are regularly working between environments.
Rather than dive into the details, I will say that the safest thing that you can ultimately do when dealing with an InnoDB issue is to simply remove the offending data folders between restarts of the instance. This will allow the system to rebuild the InnoDB as if it were a cousin of the TempDB in SQL Server (which flushes itself out, without intervention). Incidentally, Log issues aside, the InnoDB will be your preferred Database Engine for large databases, as opposed to the rudimentary MyISAM database engine.
Finally, before we take a look at how you might use MySQL, it’s worth noting that detractors of MySQL can also (rightly) criticise this RDBMS for its preference of a very fast responding database over proper transaction handling or ACID compliance (especially with the MyISAM default engine type, which is the actual internal DB engine). Assuming that you have swallowed these bitter pills, let’s take a look at how a DBA will use MySQL.
Typical MySQL Operations to Whet the Appetite
The following should give you a decent overview of the typical operations you would go through in a day of managing your MySQL instances. Starting with User creation:
|
1 2 3 4 |
CREATE USER 'UserName'@'ServerAddressOrIPSource%' IDENTIFIED BY 'Password'; grant SELECT on DBname.* to 'UserName'@'ServerAddressOrIPSource%'; grant ALL PRIVILEGES on AnotherDBname.* to 'UserName'@'ServerDNShostAddressOrIPSource%'; flush privileges; |
Nothing much different from standard SQL syntax, and the flush privileges command is to make sure that privileges are reloaded to the instance, otherwise they are not active. For most admins from other RDBMS, this post User Grant & Create statement is strange and tiresome, depending on your mood, and I am sure that this flushing command will be weeded out of future versions. Here are a few more typical actions:
Login session:
|
1 2 |
mysql -u root -p enter password |
See what is happening (global variables, privileges, connections, data) on the Instance:
|
1 2 3 4 5 |
show processlist; show databases; show variables; show grants; .... |
Stopping and Starting a MySQL Instance CMD Line:
(Do you have the rights to perform a stop and start? if not contact your Unix Admin)
|
1 2 3 4 5 |
$ sudo -l // check if processes are running before stopping/restarting $ ps -fu mysql $ sudo /etc/init.d/mysqld stop $ sudo /etc/init.d/mysqld start |
A backup (otherwise known as a Data Dump):
|
1 2 3 4 |
mysqldump -u root -p --databases DBName --opt| gzip > MySQLdumpFileName.sql.gz //Loading a dump copy: simply logon to your other DB instance, and load the backup to a Source MySQLdumpFileName.sql //then all your data will begin to load. Or you can rename the database name in the dump file so //you can a the line: Drop database DBName; |
On Windows Servers this is done from the Administration of Services Management Console. I’ve mentioned the above details regarding how to operate MySQL via command line because the Windows users will find the equivalent easier.
Auditing MySQL Operations with Tee Logs:
(the MySQL equivalent of auditing)
|
1 |
tee log Logfile.log |
…which is terminated by:
|
1 |
no tee |
Typical MY.CNF file for a Website with Respectable Traffic (recommended settings):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 |
[client] port = 3306 # this is the port MySQL uses #socket = /var/run/mysqld/mysqld.sock socket = /var/lib/mysql/mysql.sock [mysqld_safe] #socket = /var/run/mysqld/mysqld.sock socket = /var/lib/mysql/mysql.sock nice = 0 [mysqld] user = mysql pid-file = /var/run/mysqld/mysqld.pid #socket = /var/run/mysqld/mysqld.sock socket = /var/lib/mysql/mysql.sock port = 3306 basedir = /usr datadir = /data/mysql # where the data folders live tmpdir = /data/mysqltmp language = /usr/share/mysql/english skip-external-locking #skip-name-resolve # this will disable DNS resolution, thus # if you want your server to run by IP only, users have to be IP based too # # * Fine Tuning # key_buffer = 16M max_allowed_packet = 16M thread_stack = 128K thread_cache_size = 8 max_connections = 4000 table_cache = 2048 # should be well above your Opened_tables variable value #* Query Cache Configuration tmp_table_size = 128M # this is the maximum size for temp table space query_cache_limit = 16M # way too small normally, push this since MEM is cheap query_cache_size = 256M # loads to MEM for faster access, stores result set rows #(adjust according to your respective runtime status information, i.e. if Qcache_lowmem_prunes is RED) max_heap_table_size = 128M # typically too small # # INNODB CONFIG (any changes require resetting files, a DB server restart will fail otherwise) # innodb_thread_concurrency = 16 #8 - eight is default, but too small innodb_buffer_pool_size = 18G #3500M #2048M - Iargest impact on space # the innodb Buffer Pool Size should be at least 50% of the physical ram # to be available for high volume DBs innodb_additional_mem_pool_size = 20M innodb_flush_log_at_trx_commit = 2 innodb_lock_wait_timeout = 50 innodb_log_buffer_size = 4M innodb_log_file_size = 256M #by default much smaller log = /data/mysql/mysql.log log-queries-not-using-indexes long_query_time = 3 #seconds before logging bad queries log-slow-queries = /data/log/mysql/slow-queries.log expire_logs_days = 5 max_binlog_size = 100M skip-bdb [mysqldump] quick quote-names max_allowed_packet = 16M [mysql] #---- prompt will display user host and database in mysql command line prompt=(\u@\h) [\d]> #no-auto-rehash # faster start of mysql but no tab competition [isamchk] key_buffer = 16M |
Performance Monitoring: Free Tools
When it comes to monitoring the performance of your MySQL installation, there are a few free tools which you can consider. Chances are that you’re using MySQL because you don’t want to be locked into an expensive vendor upsell cycle, so free tools are probably the order of the day. To start with, there are the Perl MySQLTuner.pl scripts, which will produce a result set that looks something like this:
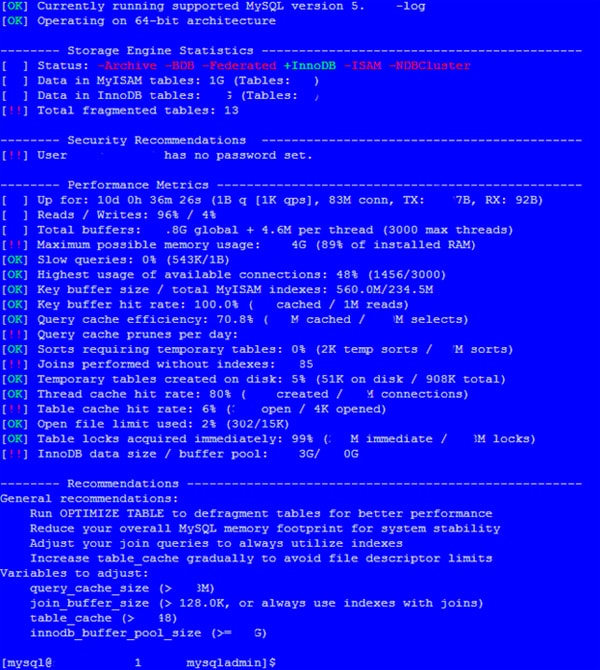
Figure 5. A normal result set from the MySQLTuner.pl scripts. A fuller version can be downloaded from the top of this article.
Alternatively, If you don’t want to run Perl scripts, then you can also try the Maatkit open-source performance monitoring tools, with my personal preference being the Query Digest Analysis of the Slow Queries Log file (mk-query-digest command), which is particularly useful once you have had a decent amount of traffic on your database, hopefully before reaching production. As a comparison of the tools, the recommendations from MySQLTuner are, as you can see above, very simple. On the other hand, Maatkit’s Query Digest will provide a detailed report for every poor performing query that shows up in your Slow Query file, starting with the worst by group. If you want to use the Maatkit tool, then take a look at the above sample MY.CNF file to see how to set the timing threshold for Slow Queries (the setting is in the last quarter of the file).
If you’re performing query tuning with MySQL, than, as with all DB systems, do not make a whole bunch of changes at once; perform one at a time, and compare your results against benchmarks and palpable real-time monitoring. For more on performance, please see this great Webinar on Performance Tuning Best Practices for MySQL, with credit going to Google’s Tech Talk series. If you want to know more about the Query Cache, which is something else you can tinker with via the MY.CNF file, see Ian Gilfillan’s great article on MySQL Query Cache for the best explanation.
If you’ve hit the ceiling with MySQL Community Edition, described above, and require an RDBMS at the level of Oracle and SQL Server, the logical step is to invest in MySQL Enterprise.
Conclusion
As with anything, all it takes is practise, practice and more pratique before you can feel truly free to wander between the heterogeneous relational database worlds. As well as maintaining the Gold Standard of tools for comparing databases or schemas in SQL, Red Gate will eventually be releasing MySQL Compare (and have already released Schema and Data comparison tools for Oracle). Even if you don’t like these brilliant tools, you can always try BeyondCompare, a favourite for the Oracle/Peoplesoft Development world.
Counter to the naysayers who warn against the perils of playing with multiple RDBMS, I have encountered only benefits since taking up Oracle again alongside sporadic MySQL administration. One develops a deeper understanding of each with repetitive use, rather than a diffusion of the mastery of one. Indeed, thanks to the connectivity of the SQuirrel SQL Universal SQL Client V3.1, it is remarkably easy to move from one environment to another, and progressively learn more and developer your skills. And finally, you will be considered a greater asset to potential employers because you have the experience in multiple domains.

Therefore, I invite you all cross the bridge to the other side, where you can enjoy other database systems, without compromising your knowledge of your favourite one, because in a nutshell, obtaining more skills, leads to more problem-solving, leading to transcend logical and sequential thinking (cognitive skills), and hopefully more innovation. This is not an argument to say you are more intelligent to by mastering more than one database system, but it will simply allow the acquisition of specific types of expertise that help attend to critical tasks and ignore irrelevant information. These critical tasks, and unresolved problems create dysfunctional relationships in the workplace ultimately, they become impediments to flexibility and in dealing with strategic change in an open-ended and creative way.
The more you develop skills across domains, the more apt you are to benefit from the stimuli to the cognitive and practical with respect to their relationship with resolving complex problems (what DBAs see very often), and thus leads to greater innovation. Knowledge dispels the inevitable fear of human nature’s knee-jerk reaction to reject change, by encouraging skills development in this way, brings database administrators much closer to the point of providing innovate solutions.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments