IAsyncEnumerable is a powerful interface introduced in C# 8.0 that allows you to work with sequences of data asynchronously. It is a great fit for building ETLs that asynchronously stream data to get it ready for transfer. You can think of IAsyncEnumerable as the asynchronous counterpart of IEnumerable because both interfaces allow you to easily iterate through elements in a collection.
Since the early days of .NET, the IEnumerable interface has been fundamental for many programs. The IEnumerable interface provided a way to retrieve elements from a collection one at a time, and the IEnumerable<T> interface extended this functionality to generic types. However, the IEnumerable interface is synchronous, which means that it is not suitable for working with asynchronous data sources.
Later, the Task and Task<T> classes were introduced to simplify asynchronous programming with the async and await keywords. However, the Task and Task<T> classes are not suitable for working with sequences of data because they represent a single operation that returns a result or an exception.
The IAsyncEnumerable interface was introduced to address the limitations of the IEnumerable interface and the Task class. This way, you can stream asynchronous data and process it efficiently as soon as it becomes available.
In this take, you will learn how to work with IAsyncEnumerable to asynchronously stream a big table and extract the data in a ETL process. You will also learn the difference between IAsyncEnumerable and IEnumerable and how to use IAsyncEnumerable in your everyday work. Then, you will look at comparisons between the two different approaches and why one is better than the other in certain scenarios.
The table used for this ETL will be the SalesOrderDetail table from the AdventureWorks database. This is the biggest table in the AdventureWorks database, and it contains 121,317 rows. Don’t worry, you will not need to install SQL Server and set up this whole database. There is a nice CSV file in the GitHub repository you can download and unzip.
The SalesOrderDetail table is by far not the biggest table I have ever encountered but it is good enough for illustration purposes. In a real-world scenario, you might need to process a table with millions of rows or perhaps even billions of rows so imagine how this might scale. In such cases, you will need to use IAsyncEnumerable to stream the data and process it efficiently.
At the end of this exercise, you will have a GZIP file with the data extracted from the SalesOrderDetail table. Because the load and transform steps are not the focus of this take, you will only extract the data from the table and save it to a GZIP file. You can use the extracted data to load it into a data warehouse, a data lake, or any other data storage system.
What you will need to get started.
I will assume that you have a good understanding of C# 12 and .NET 8.0. I will also assume that you have the latest version of .NET 8.0 installed on your machine. To make this accessible to everyone, I will use the .NET 8.0 SDK and the .NET 8.0 CLI. If you are using Visual Studio, you can follow along by creating a new .NET 8.0 console application.
Note, in this process, you will also be using Dapper and SQLite. The Dapper package is a high-performance micro-ORM that allows you to work with SQL databases in a more efficient way. The System.Data.SQLite package is a lightweight ADO.NET provider for SQLite databases.
Getting Started with the ETL
The first step is to create a new .NET 8.0 console application. You can do this by running the following command in your terminal:
|
1 2 3 4 5 |
mkdir async-enumerable-etl cd async-enumerable-etl dotnet new console -n AsyncEnumerableEtl dotnet new sln -n AsyncEnumerableEtl dotnet sln add AsyncEnumerableEtl.csproj |
The CLI command tool is a bit silly, and it will create a new folder with the same name as the project. You can delete the folder and move the project file to the root of the repository. You can also delete the obj and bin folders.
The repository should look like this:
Figure 1. Folder structure
The next step is to download the SalesOrderDetail.csv.zip file from the GitHub repository and place it in the root of the repository. You can download the file by clicking here.
Then install two NuGet packages: Dapper and System.Data.SQLite. You will use these packages to read the SalesOrderDetail table in a SQLite database. You can do this by running the following command in your terminal:
|
1 2 |
dotnet add package Dapper dotnet add package System.Data.SQLite |
Open the Program.cs file and add the following code:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
using System.Data; using Dapper; using System.Data.SQLite; using System.IO.Compression; var mode = args.Length > 0 ? args[0] : "IEnumerable"; switch (mode) { case "IEnumerable": await WriteToCsvFileWithIEnumerable(); break; case "IAsyncEnumerable": await WriteToCsvFileWithIAsyncEnumerable(); break; default: Console.WriteLine("Invalid mode"); break; } return; static async Task WriteToCsvFileWithIEnumerable() { throw new NotImplementedException(); } static async Task WriteToCsvFileWithIAsyncEnumerable() { throw new NotImplementedException(); } |
You can now run the build command to make sure everything is working:
|
1 |
dotnet build |
Setting Up the SQLite Database
Expand the SalesOrderDetail.csv.zip file and place the SalesOrderDetail.csv file in the root of the repository. You can do this by running the following commands in your terminal:
|
1 |
Expand-Archive -Path .\SalesOrderDetail.csv.zip -DestinationPath .\ |
Create a SQL script to install the AdventureWorks database in a SQLite database. You can do this by creating a new file called `installadventureworks.sql` in the root of the repository and adding the following code:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
CREATE TABLE [SalesOrderDetail] ( [SalesOrderID] INTEGER NOT NULL, [SalesOrderDetailID] INTEGER IDENTITY (1, 1) NOT NULL, [CarrierTrackingNumber] TEXT, [OrderQty] INTEGER NOT NULL, [ProductID] INTEGER NOT NULL, [SpecialOfferId] INTEGER NOT NULL, [UnitPrice] INTEGER NOT NULL, [UnitPriceDiscount] INTEGER NOT NULL, [LineTotal] INTEGER NOT NULL, [rowguid] TEXT UNIQUE NOT NULL, [ModifiedDate] DATETIME NOT NULL, PRIMARY KEY ([SalesOrderID], [SalesOrderDetailID]) ); .separator , .import SalesOrderDetail.csv SalesOrderDetail VACUUM; |
Download the SQLite command line tools from the SQLite website and add the sqlite3 command to your PATH. You can download the SQLite command line tools by clicking here.
Create a new SQLite database by running the following command in your terminal:
|
1 |
sqlite3 AdventureWorks.db < installadventureworks.sql |
You can now run the following command to make sure the SalesOrderDetail table was created:
|
1 2 |
sqlite3 AdventureWorks.db "SELECT COUNT(*) FROM SalesOrderDetail" |
Now that the SQL table is ready, you can start preparing the ETL process.
Add Guid Types to the SalesOrderDetail Table
The SalesOrderDetail table in the AdventureWorks database has a column called rowguid that is of type uniqueidentifier. The uniqueidentifier type in SQL Server is equivalent to the Guid type in C#. You will need to add a GuidTypeHandler to the Dapper library to handle the Guid type in SQLite.
Open the Program.cs file and add the following code:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
SqlMapper.AddTypeHandler(new GuidTypeHandler()); SqlMapper.RemoveTypeMap(typeof(Guid)); SqlMapper.RemoveTypeMap(typeof(Guid?)); // after the return statement public class GuidTypeHandler : SqlMapper.TypeHandler<Guid> { public override void SetValue(IDbDataParameter parameter, Guid guid) { parameter.Value = guid.ToString(); } public override Guid Parse(object value) { return new Guid((string)value); } } |
With this type handler in place, you can now declare the SalesOrderDetail class.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
public class SalesOrderDetail { public required int SalesOrderId { get; init; } public required int SalesOrderDetailId { get; init; } public string? CarrierTrackingNumber { get; init; } public required short OrderQty { get; init; } public required int ProductId { get; init; } public required int SpecialOfferId { get; init; } public required decimal UnitPrice { get; init; } public required decimal UnitPriceDiscount { get; init; } public required decimal LineTotal { get; init; } public required Guid RowGuid { get; init; } public required DateTime ModifiedDate { get; init; } } |
To turn a single row of the SalesOrderDetail table into a CSV row, you can add the following method to the Program.cs file:
|
1 2 3 4 5 |
static string GetSalesOrderDetailRow(SalesOrderDetail detail) => $"{detail.SalesOrderId},{detail.SalesOrderDetailId},{detail.CarrierTrackingNumber}, {detail.OrderQty},{detail.ProductId},{detail.SpecialOfferId}, {detail.UnitPrice:F2},{detail.UnitPriceDiscount:F2},{detail.LineTotal:F2}, {detail.RowGuid},{detail.ModifiedDate.ToUniversalTime():o}\r\n"; |
Writing the ETL Process with IEnumerable
The first step is to write the ETL process using the IEnumerable interface. This is the traditional way of working with collections in C#. You can do this by adding the following code to the WriteToCsvFileWithIEnumerable method:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
static async Task WriteToCsvFileWithIEnumerable() { await using var fileStream = File.Create("etl-salesorderdetail.csv.gz"); await using var compressionStream = new GZipStream(fileStream, CompressionLevel.Optimal); await using var writer = new StreamWriter(compressionStream); foreach (var detail in await GetSalesOrderDetailsWithIEnumerable()) { await writer.WriteAsync(GetSalesOrderDetailRow(detail)); } } static async Task<IEnumerable<SalesOrderDetail>> GetSalesOrderDetailsWithIEnumerable() { const string sql = """ SELECT SalesOrderId, SalesOrderDetailId, CarrierTrackingNumber, OrderQty, ProductId, SpecialOfferId, UnitPrice, UnitPriceDiscount, LineTotal, RowGuid, ModifiedDate FROM SalesOrderDetail """; await using var connection = new SQLiteConnection("Data Source=AdventureWorks.db"); return await connection.QueryAsync<SalesOrderDetail>(sql); } |
The WriteToCsvFileWithIEnumerable method creates a new GZIP file called etl-salesorderdetail.csv.gz and writes the SalesOrderDetail table to it. The GetSalesOrderDetailsWithIEnumerable method reads the SalesOrderDetail table from the SQLite database and returns it as an IEnumerable<SalesOrderDetail>. If you are not familiar with the Dapper library, the QueryAsync method is an extension method that allows you to execute a SQL query and map the results to a collection of objects.
You can now run the following command to make sure the etl-salesorderdetail.csv.gz file was created:
|
1 |
dotnet run IEnumerable |
This is the synchronous way of writing the ETL process in C#. Returning an IEnumerable from the GetSalesOrderDetailsWithIEnumerable method will dump the entire SalesOrderDetail table into memory before returning it. This is not ideal for large tables, as it can use a lot of memory.
Writing the ETL Process with IAsyncEnumerable
The next step is to write the ETL process using the IAsyncEnumerable interface. This is the asynchronous way of working with collections in C#. You can do this by adding the following code to the WriteToCsvFileWithIAsyncEnumerable method:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
static async Task WriteToCsvFileWithIAsyncEnumerable() { await using var fileStream = File.Create("etl-salesorderdetail.csv.gz"); await using var compressionStream = new GZipStream(fileStream, CompressionLevel.Optimal); await using var writer = new StreamWriter(compressionStream); await using var extract = GetSalesOrderDetailsWithIAsyncEnumerable(); await foreach (var detail in extract.Data) { await writer.WriteAsync(GetSalesOrderDetailRow(detail)); } } static StreamedQuery<SalesOrderDetail> GetSalesOrderDetailsWithIAsyncEnumerable() { const string sql = """ SELECT SalesOrderId, SalesOrderDetailId, CarrierTrackingNumber, OrderQty, ProductId, SpecialOfferId, UnitPrice, UnitPriceDiscount, LineTotal, RowGuid, ModifiedDate FROM SalesOrderDetail """; var connection = new SQLiteConnection("Data Source=AdventureWorks.db"); return new StreamedQuery<SalesOrderDetail>( connection, connection.QueryUnbufferedAsync<SalesOrderDetail>(sql)); } public class StreamedQuery<T>( IAsyncDisposable connection, IAsyncEnumerable<T> data) : IAsyncDisposable { public IAsyncEnumerable<T> Data { get; } = data; public ValueTask DisposeAsync() => connection.DisposeAsync(); } |
The StreamedQuery class is a simple wrapper around the IAsyncEnumerable interface. Notice that the connection is not disposed in the GetSalesOrderDetailsWithIAsyncEnumerable method. This is because the StreamedQuery class is responsible for disposing the connection. The extension method QueryUnbufferedAsync is used to execute a SQL query and map the results to an IAsyncEnumerable<T>. This method is part of the `Dapper` library and is used to stream the results from the database to the application. The `await foreach` statement is used to iterate over the data asynchronously.
When you stream data from the database to the application, it is important to leave the connection open until you are done with it. If you close the connection prematurely, you will get an error. This is why the StreamedQuery class is responsible for disposing the connection.
If you examine the code, you will notice that the connection declaration lacks a using statement. This statement is now in the consuming method where the stream is being used.
This technique is ideal for large tables, as it does not load the entire table into memory. You can now run the following command to make sure the etl-salesorderdetail.csv.gz file was created:
|
1 |
dotnet run IAsyncEnumerable |
Comparing the Performance of IEnumerable and IAsyncEnumerable
The memory consumption between the two approaches is the big concern. The IAsyncEnumerable will stream the table and load only one row at a time. The IEnumerable will load the entire table into memory before returning it.
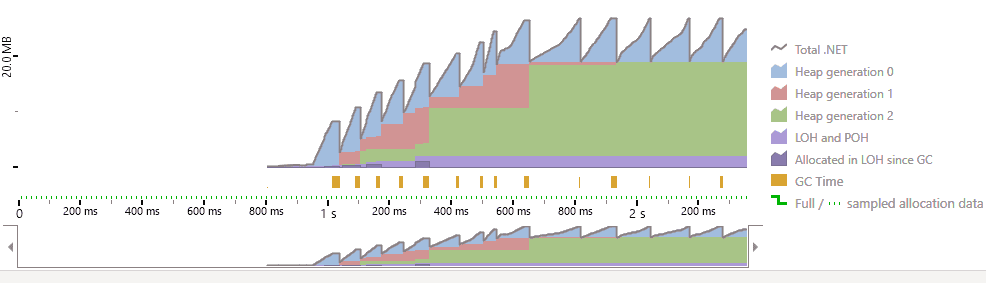
This is what memory consumption looks like when using IEnumerable:
This is what memory consumption looks like when using IAsyncEnumerable:
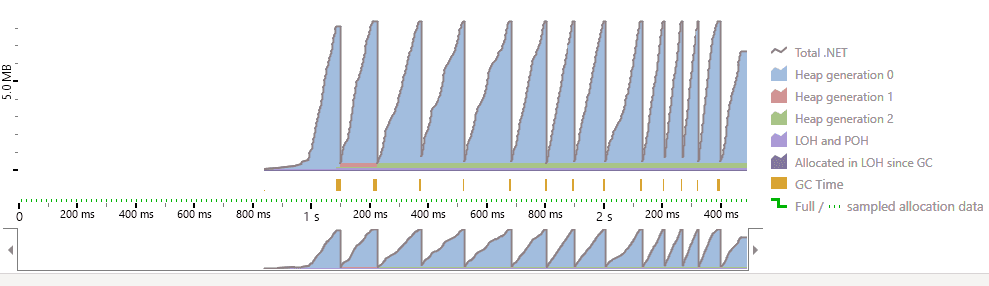
As you can see, the memory consumption in IEnumerable is much higher at 25MB. Because it must load the entire table and more data ends up in heap generation 2. This puts more pressure on the garbage collector, which can lead to performance issues. The memory consumption in IAsyncEnumerable is much lower at 8MB, and memory consumption remains relatively flat because most objects die young, which is ideal for performance.
Depending on the size of the table, the IEnumerable approach can cause memory and performance issues. Ideally, you should only use IEnumerable for small tables that can easily fit into memory. For large tables, you should use IAsyncEnumerable to asynchronously stream the data from the database to the application.
Conclusion
In this article, you learned how to write an ETL process using the IEnumerable and IAsyncEnumerable interfaces. You also learned how to compare the performance of the two approaches. Each approach can work depending on the size of the table. By using the right approach, you can avoid memory and performance issues in your ETL process.
Load comments