
In the first article of this series, we looked at some of the common ways that beginners to SQL mistakenly apply some of the techniques that served them well with a procedural language. About once a month, there is a request posted to a newsgroup or forum asking how to pass a CSV (comma separated values) list in a string as a parameter to a store procedure. They miss their arrays and other variable-sized data structure and want to mimic them in SQL. They also have no idea what First Normal Form (1NF) and the Information Principle are and why they are the foundations of RDBMS.
Every time, those of us who give advice on newsgroups and forums see this type of question we refer to the definitive articles at Erland Sommarskog’s website:
http://www.sommarskog.se/arrays-in-sql-2005.html#manyparameters
http://www.sommarskog.se/arrays-in-sql-2008.html
The approaches to this problem can be classified as (1) Iterative algorithms in T-SQL (2) Auxiliary series table to replace looping (3) Non-SQL tools, such as XML and CLR routines, (4) long parameter list and recently (5) table valued parameters, or TVPs.
The iterative, XML and CLR solutions are purely procedural and are not really SQL. Aside from the religious grounds about declarative programming, the practical grounds of increased maintenance costs and a lack of optimization make them look ugly. And I am too old to learn CLR languages.
The use of the series table in a single query and the table-valued parameter are declarative SQL. Of those two approaches, the table-valued parameters are the best. But both of them are extra work.
As an aside, when Erlang tested the long parameter list, he got a 19ms in execution time for 2000 elements which was better than any other method that he tested. But when he ran the procedure from PHP, the total time jumped to over 550ms, which was horrible. I have no idea what PHP is doing and have had no problems with other host languages.
All but the table-valued parameter approach require that you scrub the input string, if you want data integrity. If the data is already in a table, then you know it is good to go.
Data scrubbing is hard enough in T-SQL, but when you have to worry about external language syntax differences, it is a serious problem. Quickly, which languages accept ‘1E2’ versus ‘1.0E2’ versus ‘E2.0’ for floating point notation? Which ones cast a string like ‘123abc’ to integer 123 and which blow up?
The simplest answer is to use a long parameter list to construct lists and derived tables inside the procedure body. SQL server can handle up to 2100 parameters, which should be more than enough for practical purposes. SQL Server is actually a wimp in this regard; DB2 can pass 32K parameters. and Oracle can have 64K parameters. In practice, I have seen a list of 64 (Chessboard), 81 (Sudoku solver) and 361 (Go board) simple parameters. Most of the time, 100 parameters is a very safe upper limit.
Part I of this series listed the main advantages of the long parameter lists. These are:
- The code is highly portable to any Standard SQL. It can take advantage of any improvements in the basic SQL engine.
- The optimizer will treat the members of the long parameter list like any other parameter. They can be sniffed. You can use a RECOMPILE option and get the best performance possible each time the procedure runs.
This point gets lost on people. It means that I get the same error messages, testing and logic as any other parameter. When I use a home-made or external parser, I do not. Frankly, I have never seen anyone who used one of the other techniques write RAISERROR() calls to return the same error messages as the compiler.
The example in my first article was a procedure to create a basic Order header and its details in one procedure call. A skeleton for this insertion will use the price list and join it to the SKU codes on the order form. Here is the skeleton.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
CREATE PROCEDURE OrderAndDetails (@in_order_nbr CHAR(10), .. @in_sku_1 CHAR(15), @in_qty_1 INTEGER, @in_sku_2 CHAR(15), @in_qty_2 INTEGER, ..) AS BEGIN /* order header skeleton */ INSERT INTO Orders (order_nbr, ..) VALUES (@in_order_nbr, ..); /* order details with price extension */ INSERT INTO OrderDetails SELECT @in_order_nbr, OrderForm.sku, OrderForm.order_qty, P.list_price FROM (VALUES (@in_sku_1, @in_qty_1), (@in_sku_2, @in_qty_2), ..) AS OrderForm(sku, order_qty), PriceList AS P WHERE OrderForm.sku = P.sku; END; |
Do you see the idea? An entire program is being built from the long parameter list in a single declarative statement that uses no special features. I have used this same pattern to create routines for adding subordinates to a nested set tree given the root of the new subtree. Other options are use “COALESCE (@in_qty_x, 1)” on each row on the assumption they wanted at least one if they typed in a SKU, or to remove the SKUs that are NULL before the JOIN to the price list.
|
1 2 3 4 5 6 7 |
(SELECT sku, order_qty FROM (VALUES (@in_sku_1, COALESCE(@in_qty_1, 1)), (@in_sku_2, COALESCE(@in_qty_2, 1)), ..) AS X(OrderForm(sku, order_qty) WHERE sku IS NOT NULL) AS OrderForm(sku, order_qty) |
But the real differ between the long parameter list and a home-made parser is in the exception handling. Here is a table of various inputs and what happens to them.
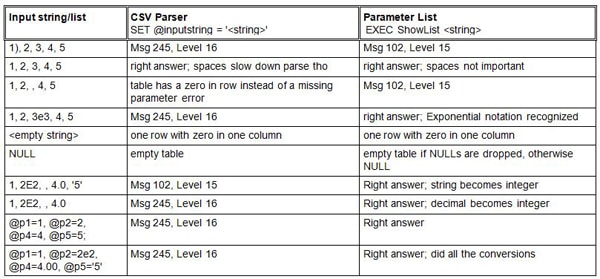
Legend:
- Msg 245, Level 16, State 1, Line x: Conversion failed when converting the varchar value <<string>> to data type int
- Msg 102, Level 15, State 1, Line x: Incorrect syntax near <<token>>
Notes:
- The CSV parser gives more serious errors, but the difference between level 15 and 16 is not much.
- CSV fails to do some valid conversions.
- Date testing has its own problems in CSV. The ISDATE() and the CAST() do not work the same way, so you need extra code in the CSV parser that does not depend on that function. Microsoft expects an ISO-8601 date in the string for the CAST(), but not for their proprietary ISDATE().
12345SELECT ISDATE ('2010-01-01'); -- TRUESELECT CAST ('2010-01-01' AS DATE); -- no problemSELECT ISDATE ('010-01-01')-- TRUESELECT CAST ('010-01-01' AS DATE); -- Msg 241, Level 16, State 1, Line 1Conversion failed when converting date and/or time from character string.
- OUTPUT parameters are impossible with the CSV parser:
1234567CREATE PROCEDURE ShowList(@p1 INTEGER = NULL,@p2 INTEGER = NULL,@p3 INTEGER = NULL,@p4 INTEGER = NULL,@p5 INTEGER = NULL OUTPUT)AS ..;
- The NULL should produce an empty table only if we prune out NULLs, as it does. But the empty string should not become a zero. This is a string conversion error as far as I can tell; at least it is consistent, though.
- You can pass local variables with the long parameter list, but not with CSV:
1234567DECLARE @local_int_1 INTEGER;DECLARE @local_int_2 INTEGER;SET @local_int_1 = 42;SET @local_int_2 = POWER (@local_int_1 , 2);EXEC ShowList @local_int_1, @local_int_2;
A handy example of the technique is to insert a st of children under a parent in a Nested Set model. Let’s assume we have a basic Nested Set tree table:
|
1 2 3 4 5 |
CREATE TABLE Tree (node_name VARCHAR(15) NOT NULL, lft INTEGER NOT NULL CHECK (lft > 0) UNIQUE, rgt INTEGER NOT NULL CHECK (rgt > 0) UNIQUE, CHECK (lft < rgt)); |
Now add the root node to get things started:
|
1 |
INSERT INTO Tree VALUES ('Global', 1, 2); |
The procedure shown here only does 10 children, but it can be easily extended to 100 or 1000 if needed.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
CREATE PROCEDURE InsertChildrenIntoTree (@in_root_node VARCHAR(15) = NULL, @in_child_01 VARCHAR(15) = NULL, @in_child_02 VARCHAR(15) = NULL, @in_child_03 VARCHAR(15) = NULL, @in_child_04 VARCHAR(15) = NULL, @in_child_05 VARCHAR(15) = NULL, @in_child_06 VARCHAR(15) = NULL, @in_child_07 VARCHAR(15) = NULL, @in_child_08 VARCHAR(15) = NULL, @in_child_09 VARCHAR(15) = NULL, @in_child_10 VARCHAR(15) = NULL) AS BEGIN |
— Find the parent node of the new subtree
|
1 2 3 4 5 |
DECLARE @local_parent_rgt INTEGER; SET @local_parent_rgt = (SELECT rgt FROM Tree WHERE node_name = @in_root_node); |
Put the children into kindergarten; I just had to be cute.
Notice that we can build complete rows with the VALUES() clause immediately without looping or other procedural code.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
SELECT node_name, (lft + @local_parent_rgt -1) AS lft, (rgt + @local_parent_rgt -1) AS rgt INTO #local_kindergarten FROM (VALUES (@in_child_01, 1, 2), (@in_child_02, 3, 4), (@in_child_03, 5, 6), (@in_child_04, 7, 8), (@in_child_05, 9, 10), (@in_child_06, 11, 12), (@in_child_07, 13, 14), (@in_child_08, 15, 16), (@in_child_09, 17, 18), (@in_child_10, 19, 20)) AS Kids (node_name, lft, rgt) WHERE node_name IS NOT NULL; |
Use the size of the kindergarten to make a gap in the Tree
|
1 2 3 4 5 6 7 8 9 10 |
UPDATE Tree SET lft = CASE WHEN lft > @local_parent_rgt THEN lft + (2 * (SELECT COUNT(*) FROM #local_kindergarten)) ELSE lft END, rgt = CASE WHEN rgt >= @local_parent_rgt THEN rgt + (2 * (SELECT COUNT(*) FROM #local_kindergarten)) ELSE lft END WHERE lft > @local_parent_rgt OR rgt >= @local_parent_rgt; |
Insert kindergarten all at once as a set
|
1 2 3 4 5 6 7 8 |
INSERT INTO Tree (node_name, lft, rgt) SELECT node_name, lft, rgt FROM #local_kindergarten; /* check you work if you wish SELECT node_name, lft, rgt FROM Tree; */ END; |
Here are some tests you can run to see that it works. The sibling order is the same as the parameter list order. You could also add text edits and other validation and verification code to the statement that built Kindergarten.
|
1 2 3 |
EXEC InsertChildrenIntoTree 'Global', 'USA', 'Canada', 'Europe', 'Asia'; EXEC InsertChildrenIntoTree 'USA', 'Texas', 'Georgia', 'Utah', 'New York', 'Maine', 'Alabama'; |
Could I have done this with a table-valued parameter? Sure. But there are down sides to that method. The code would not port because T-SQL does not agree with other vendors. The Microsoft model is that this is a type and not a structure. That is an important difference.
I have to declare the table as a type outside the procedure. In other SQL products I would declare it in the parameter list, so I can see the structure. I then have to load it outside the procedure body, then pass it to a local table inside the procedure body with the same structure.
The skeleton for this pattern is:
Create the data type
|
1 2 |
CREATE TYPE dbo.My_Table_Type AS TABLE ( .. ); |
Create a table using the type
|
1 |
DECLARE @in_my_table_parm My_Table_Type; |
Load the table
|
1 2 |
INSERT INTO @in_my_table_parm(...) VALUES (..),(..), .. (..); |
Pass the table to the procedure, finally
|
1 |
EXEC SomeProc @my_table_parm = @in_my_table_parm, ..; |
Remember that the parameter has to be READ-ONLY to prevent changing the rows of @in_my_table_parm in the procedure. You can get a quick introduction to the technique at http://www.sqlteam.com/article/sql-server-2008-table-valued-parameters.
One advantage of the table-valued parameter is that it is a full table, with constriants for keys and so forth. You check the data before it goes to the procedure in a separate step, while the long parameter list checks the data after it goes to the procedure in the EXEC statement.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved






Load comments