

DevOps, Continuous Delivery & Database Lifecycle Management
Version Control
With this article, we begin our exploration of the processes, tools and practices that are required in order to allow a team of developers, or even several teams of developers, to work together to deliver to production, successfully and smoothly, an application and its database.
The purpose of change management is to protect the integrity of the database design throughout the development process, to identify what changes have been made, when, and by whom and, where necessary, undo individual modifications. A source control system is typically the critical application around which a change management regime is structured and is a requirement for any team development project.
In this article, we will explore:
- Development environments that are necessary as an application and its database make their way from initial development through to production
- Overview of source control for databases, including coverage of source control models and systems, and the challenges of managing database objects in source control
- How to get you database objects into source control, via scripting or by using Redgate SQL Source Control.
- Managing data in source control, and how to synchronize the data needed for the application to run (lookup tables, metadata, and so on)
With all this in place, in the ‘Redgate Guide to SQL Server Team-based Development’ we move on, to see how to automate deployment of database, including necessary data, from one environment to another.
The challenges of team-based development
The journey of a team-developed application and its database, from initial development to successful deployment to production, involves many stages, including but not limited to the following:
- Initial development and unit testing of code on local sandbox servers
- Strict use of source control to store and version control individual code modules
- Use of Continuous Integration to perform regular builds in a test environment, to find out how the small units work when put together
- A way to automate the build and deployment process, including a reliable way to push schema and data changes, from one environment to the next, for testing, staging and so on.
All of this requires mechanisms for establishing multiple development platforms, sandboxes, integration environments, local servers and more. Each of these can then lead to multiple testing servers, performance testing, Quality Assurance, financial test, user acceptance test. Ultimately, it all comes together to go out to a production server.
Regardless of the specific development methodology employed (ITIL, Scrum etc.), it is vital that a process is put in place to manage all these people, their code and the environments. In support of this process, tools will be needed in order to automate builds and deployments because, with this many people and this many environments, attempting to deploy manually would be a time-consuming, error-prone exercise in frustration. The goal of the process is to enable large teams of developers to work on the same project, at the same time, without stepping on each other’s toes.
If all this isn’t enough, the very purpose of having a database, keeping data, storing it, retrieving it, presenting it to the user, means that you can’t just throw away yesterday’s database. It has data. That data is kept for a reason. It may be vital financial information or it may be very simple lookup data that helps you maintain consistency. Regardless, it needs to be kept around and that makes the job of building databases even harder. You have to be able to retain data even as you make changes to the underlying structure. You may need to move data with the deployment of new versions of the database. You’ll probably need a mechanism to make one database look like another without performing a backup and restore, but instead performing a deployment of code, structure and data. You’re going to want to automate all this as well.
Thankfully, there are a number of tools available that can help you manage your code and deploy multiple versions of the database to any number of systems, with varying degrees of automation. There are tools and methods for putting database code, objects and data into source control so that these database specific objects can be managed just like the developers manage their application source code. Best of all, many of these tools work together and can be automated such that you arrive at a place where you automatically deploy different versions of your database to different servers in a timely manner, freeing you up to work on performance tuning.
The key to achieving successful team and cross-team development is to implement a process and to follow that process with a great deal of discipline. The military has a saying, “Slow is smooth, and smooth is fast.” No one wants a slow development process, but a rough and tumble development process with lots of errors, a great deal of friction and rework, one that is not smooth, will not be fast. Better to concentrate on making your process smooth, and fast will follow.
Environments
In very small shops, it’s possible to develop directly against your production server. It’s not smart, but it’s possible. However, as the importance of your production data to the company grows, and the number of people and number of steps within your development process expands, you’ll find it increasingly important to have multiple layers of servers between your production and development systems. Not all of these environments are required for every development process. Further, some environments can serve multiple purposes depending on the stringency of your process, the number of teams involved and the business requirements you’re striving to meet. With this many servers, the migration problem becomes clear: you need a lot of change scripts, and hence the need for automation.
In order to support team development in any application that persists information to a relational database system, you will need somewhere to host the database server. SQL Server can be run on systems large and small and within virtual environments. I’m not going to spend time specifying when, or if, you need a physical or virtual server for these environments or what size of environment you’ll need. That’s going to vary widely depending on the applications you’re developing, the processes you implement, the amount of money you’re willing to spend and any number of other variables. Instead, I’ll focus here on the purposes to which a given server may be dedicated in order to achieve a goal, within the process of developing your application. Just remember, once you define the needs and purposes of the servers within your process, use them in a disciplined manner in order to ensure the smoothness of your development process.
For most development, in order to provide a mechanism for testing prior to deployment, you should have at least three basic environments:
- a development environment where you can make mistakes without hurting your production system.
- a testing environment to ensure that anything you’re releasing into the wild of production will work correctly.
- a production system where the data that supports your company will live.
Development Environments
There are two common models for organizing database development:
- Dedicated, where each developer has their own local copy of the database
- Shared, where each developer works on the same, central copy of the database
With a local server, a developer has a lot more flexibility, and can try things out without affecting the rest of the team. However, integration can be problematic. In a shared server environment, integration becomes more fluid, but changes by any individual developer or development team can seriously impact others. I’m going to assume a situation where both models are in use, in order to maximize flexibility without compromising the importance of integration.
Sandbox (local server)
The first place that most development will occur is on a sandbox server. This is usually, but doesn’t have to be, a full instance of a database server running locally on the developer’s machine or, possibly, in a private server environment. The sandbox server is meant to be a playground, a place where developers and designers can try things out, break things even. It’s the one place where just about anything goes. However, all the fun and games in the sandbox server should remain there. No code and no structures should be moved off a sandbox server unless they’ve gone through some type of local testing, frequently referred to as a unit test. Once a piece of code has passed a unit test it can be moved into whatever type of source control is being used.
Security on the sandbox should allow the developer at least database owner (dbo) access to the databases on which they’re working. If the sandbox is located locally, you can probably go ahead and let them have system administrator (sa) privileges.
Common Server
When working with a team of developers it’s usually necessary to have, in addition to the sandbox server, a common, shared work space for database work. That way, the new column you’ve added or the new procedure your co-worker has built will be immediately available to other developers in the team. If you’re using Redgate SQL Source Control (covered later), the need for a common server is greatly diminished; since the tool integrates the source control system directly into SSMS, each team member can simply get the latest changes from the “Get Latest” tab.
I’ve known cases where multiple teams develop against a single common server, but this only really works if there are few, if any, dependencies between the code bases. Otherwise, as changes get made by one team, they’ll break the code of the next team, which can lead to a lot of frustration and, even worse, slow down development.
Direct development against the common server should be expected and planned for. As with the sandbox, no code should be moved off the common server until it has passed a unit test, and if necessary a more extended test between multiple teams, if there are dependencies (integration testing will be covered shortly).
In terms of security, an individual or team should only have access to the database or schema for which they’re responsible. If certain developers are responsible for the whole database, then they will probably require dbo privileges. However, where possible you should control access at a more granular, object level. If a developer is responsible only for creating stored procedures, then his or her privileges should be limited to just those objects, and the right to, for example, create tables, should be denied.
Testing, Staging and Production environments
At various stages during development, the application and database code must be subject to rigorous testing, not only to make sure that it is functionally correctly, but also that the database conforms to user and business requirements, deploys smoothly, and so on. This requires multiple environments to be created, including integration, testing and staging.
Integration Server
When multiple developers, or teams, are working on various different parts of an application, and there is a great deal of dependency between these parts, then it’s a good idea to build an integration server.
The integration server presents a controlled environment where code that has already gone through initial testing can be combined with other, tested, parts of the application under development. Integration testing is a means to ensure that tightly coupled applications are validated prior to being sent to a Quality Assurance team.
No direct development should be allowed on the integration server. You should only allow a deployment directly from source control so that the server is always in a known state. This will enable your development teams to establish the fact their application, or part of the application, works with a specific version of any number of other applications and components. It provides a foundation for further development. Deployments to this server could be performed on-demand, or according to an agreed schedule.
Security should be fairly clamped down, only allowing developers read access or access through an application’s limited-privilege role. Developers should not be allowed to modify structures directly, on this server as this can and will lead to inconsistent test results, which will cause rework and friction between the teams, and will slow down development.
Continuous Integration Server
When there are a lot of dependencies between teams or applications, it might be a good idea to check those dependencies a lot more frequently, maybe even constantly. This is the purpose of a continuous integration (CI) server. With a CI server, you’ll want to either automate a build based on code being checked into source control or automate a build based on a regular, but frequent schedule. The key word to associate with a CI server is ‘automation.’ You need to set up automatic deployment and automatic testing so that you can validate the build and deployment without involving a single human being. This provides a solid early warning system for integration issues. The CI process is discussed in more detail in Chapter 5 of the ‘Redgate Guide to SQL Server Team-based Development’.
Security shouldn’t be a problem on a CI server because no one from a development team should be allowed access to the server.
Quality Assurance
Quality Assurance (QA) is a standard practice whereby the general quality of the code being deployed is repeatedly validated, as each new build is deployed, through a combination of automated and manual testing. Usually, the QA process includes verifying that the code meets the documented business requirements and Service Level Agreements (SLAs). Deployments to a QA server are either done on an ad-hoc basis, as milestones within the code are met, or on a scheduled basis, so that QA is constantly checking the status of the code.
Deployments are based on a known version of the code and can take the form of differential builds, also known as incremental builds, or full builds. In a differential build, only the code or structures that have changed are deployed; in a full build, all of the code, including the database, is completely replaced each time.
The importance of repeatable tests in a QA environment suggests the need for realistic test data, as supplied by data generation tools such as the Data Generator in Visual Studio Team System Database Edition or SQL Data Generator from Redgate.
Security in a QA system should be more stringent than in most development systems. In order to ensure that the tests are valid, changes can’t be introduced. This means that developers and QA operators should not have the ability to manipulate objects. You may want to allow them to manipulate data.
Performance Testing
The performance testing environment is sometimes combined with QA, but this is generally inadvisable. Separating performance testing from the more general business testing of QA allows for more flexibility in both testing processes.
The idea of a performance test is not to carefully simulate a production load, although that is a part of the process. Instead, you want to measure performance under an ever increasing load, as measured in transactions per second, user connections, data volume and other metrics. You not only want to see how the application behaves under load, you want to see where and how it breaks. This can be a time consuming process, when done properly, and is one of the main reasons why it needs to be separated from the standard QA Process. In order to provide a reliable set of test results, deployments should be from a version or label within source control (discussed in more detail in the later Source Control section).
Security on the performance testing server can be somewhat flexible, but again, once testing starts, you don’t want changes introduced. It’s probably better to treat it like a QA system and not allow data definition language (DDL) operations against the databases on the server.
User Acceptance Testing
User Acceptance Testing (UAT) is a lot like QA testing, but whereas QA is focused on careful verification of the quality of code, UAT involves business operators and end-users manually testing the system to ensure it performs in ways they anticipated.
The UAT process can be combined with QA, but sometimes QA is on a faster schedule and UAT can take a long time, so having a separate environment is useful. Security should be clamped down on a scale similar to your production system. No direct access to manipulate the data outside of what is provided through application, and certainly no DDL, should be allowed.
Staging
On the staging server, we perform a final check for our application’s deployment process, to ensure that it will run successfully in production. As such, the staging server should be a mirror of the production environment. This doesn’t mean it has to be the same size machine, with as much memory and CPU horsepower. However, it does mean that the staging server must host an exact copy of the production database, and must exactly mimic the production server configuration and environmental settings. If the production server is configured as a linked server, for example, this configuration must be replicated on the staging server; all ANSI settings, which may affect the way your code is deployed, must be identical.
You need to treat any errors occurring during a deployment on a staging system as a failure of the entire deployment. Do not simply try to fix the error in-situ and proceed with the deployment. Instead, reset the server so that it is once more a copy of your production system (e.g. using a backup and restore, or by using Redgate SQL Compare and Data Compare), fix the error in the deployment, and retry the entire process from scratch.
Once a successful deployment, from a known state in source control, is completed, no other changes to code should be allowed prior to running the deployment on production. Security should be as tight as a production system. No direct DML and no DDL.
Production
The production system represents the culmination of all your application’s hopes and dreams. Deployment should be from the same source that was just successfully deployed to Staging.
Security should be clamped down in order to protect the integrity of the company’s data.
Source Control
A database application development project depends on the successful coordination of the application and database development efforts. It is essential to be able to keep the scripts together so that any working build can be reproduced and to do this, we need to be able to tie database changes to the code changes to which they relate. The way to do this is to check them into source control as a part of the same changeset transaction. This makes it far easier to make consistent builds and deployments.
As discussed earlier, there are several points in the development lifecycle, such as for integration testing, QA testing and so on, where a consistent working build must be readily available. For databases, there must be a correct version of the build script, not just for the database structure and routines, but also for key ‘static’ data, and configuration information. Everything that goes towards the build must be in source control, including configuration files, and it should be possible to build the entire application from these scripts.
Use of a Source Control system has long been an established part of the development process for application code but not, sadly, for database code. Largely, this is because, unlike application code, database code is all about persistence. You can’t simply recompile the database into a new form. You must take into account the data and structures that already exist. Mechanisms for automating the process of getting a database into source control, and deploying it from that location, have either been manual or home-grown. In either case, database source control processes have, traditionally, been problematic and difficult to maintain.
Recently, a number of tools, such as Redgate’s SQL Source Control (and SQL Compare) and Microsoft’s Visual Studio Database Projects have sought to make it much easier to manage database code in a Source Control system, and to automate the deployment of databases out of source control. This means that checking your database into a source control system can, and should, be a fundamental part of your processes.
Source Control Features
Source control provides several important solutions to almost all development processes, including:
- ability to share code, allowing multiple people/teams to access pieces of code, or a database, at the same time
- a way to manage and protect the code generated
- a way to version each piece of code, so that a history of changes can be kept
- a way to version, or label, whole sets of code, so that you can deploy from a known state, or revert to a previously known state
- facilitation of change management, so that new software or new functionality is carefully tracked and approved
As this suggests, every Source Control system will provide a means by which a developer can retrieve a particular version of a given piece of code and a way to put the changed code back into the system, thereby creating a new version of the code. When a developer accesses a piece of code, he or she will, depending on the source control system used, get either shared access to the code, which is common in Source Control systems that employ an “optimistic” approach to concurrent access, such as Subversion, or exclusive access to the code, which is the “pessimistic” approach used, for example, by Microsoft’s Visual SourceSafe.
A good source control system should have a mechanism in place for merging multiple changes to the same code. In other words, if more than one developer worked on the same procedure, a mechanism must exist for reconciling their individual changes. Furthermore, in order to support multiple development streams, for example one stream writing service patches for code already in production and another stream creating all new functionality for the system, the source control system should allow developers to create branches of the codebase for testing or for releases. The alterations in the branches can then be merged back into the main trunk of development, although this is sometimes a difficult process that requires careful planning.
Versioning databases
The location of the database within source control is important. If you create your own, separate storage location, then the vital coordination between the database and the application is either lost or left to the mercy of manual processes. Instead, the database should be made an integral part of the larger project, or solution, in which the application is stored. This ensures that when a label or branch is created in the application, the database is labeled or branched in exactly the same way.
While code frequently has versioning built into the executables, databases don’t automatically receive a versioning system, as they are created or updated. A method of labeling the database itself should be incorporated into the source management process.
One popular, although rather messy, solution is to insert rows into a version table, but this requires maintaining data, not simply working with code. A better approach is to use Extended Properties within SQL Server. Extended Properties can be applied to most objects within the database and by applying and updating these property values, as appropriate, it is possible to either version the database as a whole, or version each of the individual objects. Best of all, this can be automated as part of the build and deploy process, so that the source control versions or labels are automatically applied to the values on the Extended Property.
Optimistic versus pessimistic source control
There are a couple of prevailing models for managing code within source control. The older method, used by tools such as Microsoft VSS, is a pessimistic process wherein the developer takes an exclusive lock on the code in question through a process known as a check-out. While a piece of code is checked out, other developers can read the code, but they cannot edit it themselves. When the original developer is done, the code is checked back in to VSS and is now available for other developers to use.
Most developers prefer a more flexible, optimistic approach to Source Control, as offered by modern source control systems, such as Subversion or Microsoft’s Team Foundation Server. Instead of an exclusive lock, a developer just retrieves a copy of the code and begins to edit. Other developers are free to also start working with the same code. When any developer is done with the work, the code is merged back into source control and committed. This allows for more than one developer to work on any given piece of code, but still manage the changes so that no one’s work is inadvertently overwritten and lost.
Source Control Systems
There are source control systems available from a large number of vendors, as well as several open source options. The source control systems currently supported by Redgate SQL Source Control are Team Foundation Server, Subversion, Git, Vault, Mercurial and Perforce. Microsoft still has available Visual SourceSafe (VSS) but that is actively being retired and will no longer be supported.
While TFS and SVN work in similar ways, there are distinct differences and you may find one or the other is much better suited to your system. Table 3.1 outlines some of the fundamental differences between the two products.
|
Feature |
TFS |
SVN |
|
Branching |
Strong support for creating branches and merging them back together |
Strong support for creating branches and merging them back together |
|
Labeling |
Fundamental behavior allows for multiple labels of individual files or entire projects |
Fundamental behavior allows for labels of individual files or entire projects |
|
Merge |
Works in either traditional VSS mode of exclusive check outs or within the Edit/Merge methods of modern source control systems |
Works within Edit/Merge method of modern source control systems. Some weakness in tracking merge history. |
|
Offline Editing |
TFS does not work well in an offline state. |
SVN can work in an offline state, with the ability to retrieve a set of code, disconnect from the server to work and then reconnect later to merge the changes. |
|
Multi-Platform Support |
This is available through third party plug-ins at additional cost |
Multi-platform support is the fundamental foundation of SVN. Clients can be in any OS connected to a server in any OS. |
|
Work Integration |
TFS is intended as an enterprise development management tool, of which source control is just one aspect. It exposes multiple tools and processes for managing development teams, projects, problem tracking and integration. |
SVN is a source control system and does not provide this type of processing |
|
Integration with SQL Server |
SQL Server is a fundamental piece of TFS, so the software available for SQL Server management such as Reporting Services or Integration Services are available for working with TFS |
SVN manages data in a proprietary (open source) format. Tools are available, but a learning curve will be associated with each one |
Table 3.1: A comparison of the SVN and TFS source control systems
While SVN does offer support for working offline, some of the newer “distributed” source control systems, such as Git and Mercurial, aim to make this much easier.
Git, in particular, has been gaining traction. Whereas traditional source control systems, such as SVN and TFS, stores data as a series of files and change sets, Git uses the concept of snapshots. At each commit, Git takes a snapshot of the state of all of the files in the project, and stores a reference to this snapshot. The entire project history is stored on a developer’s local database and so virtually all operations can be performed locally, and offline. The idea behind Git is that it is built “from the ground up” to handle branching and merging. An excellent resource for learning more about Git is Scott Chacon’s online book, Pro Git.
Ultimately, the source control system you use isn’t nearly as important as the fact that you do need to start managing your databases through source control.
Database Objects in Source Control
Changes made to an application during development result, directly, in a change to the underlying code file. These source files can be kept in source control so that each revision to a file is retained. This process does not interrupt or modify the developer’s “interactive” development model, whereby a developer works directly with his or her code, within Visual Studio, with direct access to syntax checking, debugging tools and so on.
Ideally one would like to extend the “interactive” or “online” development model to databases, allowing developers to work directly with the databases, in SSMS, while still maintaining a history of changes in the source control system, there are complicating factors. The most obvious difficulty is that DML and DDL queries modify the current state of a database, so there are no files being changed and, essentially, no source code to control.
Developers can periodically script out the database objects they have changed but, in the absence of third-party tools, it is very hard to maintain a proper incremental history of changes, packaging up a specific database version becomes difficult, and discrepancies are common between the “working” database and what’s in source control.
This is the reason why most home-grown solutions for source controlling databases have, by necessity, adopted an “offline” development model, whereby rather than working directly with the database, you work directly with the scripts, in source control, which are then applied to a database. As long as all developers rigorously adopt the approach of never editing a database object directly within SSMS, and instead updating a script in source control, then maintaining change history is easier, and one can be confident that what’s in source control should accurately represent the “truth” regarding the current state of the database.
Nevertheless, there are many drawbacks to the offline model. It is disruptive, and the biggest obvious disadvantage is that, in working with scripts rather than a database, you lose the benefits of immediate syntax checking. If you are just working with a script, completely independent of the database, it is possible, even likely, that you will introduce syntax errors. To check the syntax of an offline script, it must be run against a database to make sure that the latest version of the scripts, in source control, will build a functional database. Additional processes must be in place to ensure that objects are scripted in dependency order and referential integrity is maintained, and that changes made by teams of developers can successfully be merged.
The tools available to help manage databases in source control, adopt different models. Visual Studio Team System uses the offline model and builds in features to help overcome the discussed issues. Conversely, Redgate’s SQL Source Control integrates your source control system directly with SSMS and so has the considerable advantage of allowing developers to continue using the interactive development model, working with an “online” database. It automates the source control of object creation scripts, alerting users to differences between the database and source control versions, and making it simpler to commit changes to source control.
The model and tools you choose may vary depending on the skill set and preferences of your team. Most DBAs I know are very comfortable within SSMS and are much less so in other development environments, such as Visual Studio. However, for many of the developers I know, the opposite is true, and these developers can take advantage of the enhanced text editing offered by tools like Visual Studio. Likewise, if you’ve come to rely on luxuries such as intellisense and syntax checking when writing database code, then the online model will be very attractive. However, if you have learned how to work with T-SQL such that you’re able to write scripts to create database objects much faster than is possible through a GUI, then the offline model may work better.
Whether your use an online or offline development method with your database, the key point is that you need to deploy databases out of source control. You need to establish this as a discipline in order to be able to automate your processes. You’ll find that only will deploying from source control not slow down development, but it will speed it up because you’ll be dealing with fewer errors in deployment.
Getting your database objects into source control
If following the offline model, or if using the online model but without full integration between SSMS and your source control system, then the first step is to add the database objects to the source control system; in other words, the most basic building blocks of the database objects, the T-SQL scripts, need to be checked into whatever source control system is being used, individually. With those individual scripts, the database T-SQL code can be managed through the source control processes. To manage a database in a team environment properly, you’ll need to break down the scripts into the smallest possible component parts, preferably one script per database object, and then store these scripts in your source control system, usually with separate folders for each type of object, for various types of reference data, and so on.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
SVN MyProject Databases MyDatabase Database Tables Procs Functions Data Procs Tables TestData ReleaseScripts ...<etc.>... |
Listing 1: Database file layout in source control
You will need to take into account that the objects you’re creating either won’t exist in your database, or, they will exist and you’re making changes to them. Usually, I find the best way to solve this, if you’re not using a tool to perform the integration with Source Control for you, is to use scripts that DROP and then CREATE the objects. In this manner, you can always be sure the objects will be built. If you just use ALTER commands in your scripts, you may not get all the objects into the database.
If you use Redgate’s SQL Source Control tool then the need to script out your objects, as a separate step, is removed. Over the coming sections, we’ll take a look at a few ways to generate scripts separately, either via a command line or GUI, and then at how it working using SQL Source Control.
Scripting a database using PowerShell / SMO
Getting your scripts output from the database can be a tedious task. The best way to script out your database objects is through automation. Listing 2 is an example of an SMO / PowerShell script. The full script is available with the code download for this article, but Listing 2 shows the basic details. It takes three parameters, the instance name for the server to which you want to connect, the name of the database that is going to be scripted out, and the base directory for the location of the script files. It will create a directory there with the name of the target database, and then script the objects within, with a separate folder for each type of object.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 |
#DBscripting.ps1 #Script all the objects in the specified database # Backs up user databases # Get the SQL Server instance name, database and base directory from the command line param( [string]$inst=$null, [string]$dtbase=$null, [string]$base=$null ) # Load SMO assembly, and if we're running SQL 2008 DLLs load the SMOExtended and SQLWMIManagement libraries $v = [System.Reflection.Assembly]::LoadWithPartialName( 'Microsoft.SqlServer.SMO') if ((($v.FullName.Split(','))[1].Split('='))[1].Split('.')[0] -ne '9') { [System.Reflection.Assembly]::LoadWithPartialName('Microsoft.SqlServer.SMOExtended') | out-null [System.Reflection.Assembly]::LoadWithPartialName('Microsoft.SqlServer.SQLWMIManagement') | out-null } # Handle any errors that occur Function Error_Handler { Write-Host "Error Category: " + $error[0].CategoryInfo.Category Write-Host " Error Object: " + $error[0].TargetObject Write-Host " Error Message: " + $error[0].Exception.Message Write-Host " Error Message: " + $error[0].FullyQualifiedErrorId } Trap { # Handle the error Error_Handler; # End the script. break } # Connect to the specified instance $s = new-object ('Microsoft.SqlServer.Management.Smo.Server') $inst # Connect to the specified database $db = $s.Databases[$dtbase] $dbname = $db.Name # Create the Database root directory if it doesn't exist if (!(Test-Path -path "$base\$dbname\")) { New-Item "$base\$dbname\" -type directory | out-null } $homedir = "$base\$dbname\" # Instantiate the Scripter object and set the base properties $scrp = new-object ('Microsoft.SqlServer.Management.Smo.Scripter') ($s) $scrp.Options.ScriptDrops = $False $scrp.Options.WithDependencies = $False $scrp.Options.IncludeHeaders = $True $scrp.Options.AppendToFile = $False $scrp.Options.ToFileOnly = $True $scrp.Options.ClusteredIndexes = $True $scrp.Options.DriAll = $True $scrp.Options.Indexes = $True $scrp.Options.Triggers = $True # Script any DDL triggers in the database $db.Triggers | foreach-object { if($_.IsSystemObject -eq $False) { $trg = $_ if (!(Test-Path -path "$homedir\DatabaseTriggers\")) { New-Item "$homedir\DatabaseTriggers\" -type directory | out-null } $trgname = $trg.Name $scrp.Options.FileName = "$homedir\DatabaseTriggers\$trgname.sql" $scrp.Script($trg) } } # Script the tables in the database $db.Tables | foreach-object { if($_.IsSystemObject -eq $False) { $tbl = $_ if (!(Test-Path -path "$homedir\Tables\")) { New-Item "$homedir\Tables\" -type directory | out-null } $tblname = $tbl.Name $scrp.Options.FileName = "$homedir\Tables\$tblname.sql" $scrp.Script($tbl) } } # Script the Functions in the database <....SNIP....> |
Listing 2: Scripting out database objects using PowerShell
With the DBScripting.ps1 script, you can very quickly generate a set of scripts for your database. Further, with this type of automation, you can adjust the mechanism to better fit your needs to ensure that all your databases are scripted in the same way.
Redgate SQL Source Control
SQL Source Control integrates directly into SSMS and is specifically designed to synchronize databases and source control. This tool essentially “removes” the need to generate a set of files on the file system as a part of moving the database objects into source control. Of course, this step still happens but the tool does it automatically behind the scenes.
SQL Source Control uses SSMS as a front-end that directly links a database, and its objects, into files within source control. In database terms, this is online database development, meaning changes to structures or SQL code are done directly in a live database, rather than to scripts.
In this example, we will place the AdventureWorks database into source control so developers can begin working on it. This example uses:
- The Subversion source control system
- The Tortoise SVN client for Subversion
- SQL Source Control
There are two stages to source controlling a database with SQL Source Control. First, we need to link the database to source control, and then commit the database objects.
Linking associates the database with a location in source control. That location must be an existing, empty folder. We can create a folder in SVN, and link the database to that location as follows:
- In a Windows Explorer window, right-click, and from TortoiseSVN select Repo-browser:
The URL dialog box is displayed. - In the URL textbox that appears, type or paste the URL for your repository, and click OK
- The Repository Browser is displayed:
In the Repository Browser, in the left pane, select the folder in the repository where you want to source control the database. Then right-click and select Create folder. - In the Create Folder dialog box, specify a name for the folder, and click OK.
- Right-click the new folder, and select Copy URL to clipboard
One member of the team, with SQL Source Control running within SSMS, can now simply select a database that is not yet under source control, click on Link to my source control system, select the source control system (SVN in this case), click Next and enter the repository URL defining where within that system the database will be created. Once the Link button is pressed, all the objects are marked as changed and are then ready to be checked into a structure within source control. In SQL Source Control you can click on the Commit changes tab. It will then display the objects that SQL Source Control is capturing, ready for moving into source control. You can add comments and click on the Commit button, shown in Figure 1. That will then move all the objects into source control.
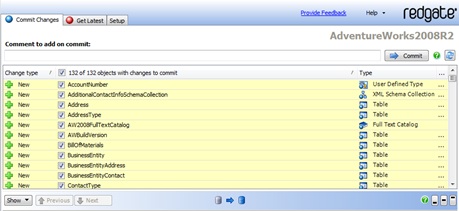
Figure 1: Committing database objects to source control with SQL Source Control
Subsequently, other members of the team can link their own local copy of the database to the source controlled database to get all of the latest objects.
Redgate SQL Compare
If you are not using the SQL Source Control tool, then an alternative to scripting out the database is using Redgate’s SQL Compare tool. At its most basic, SQL Compare is a utility for directly comparing the structure of one database against another and then generating a script that reflects the difference between the databases, in order to make one database look like another.
Building straight from one database to another doesn’t allow for source control or a lot of process automation, but SQL Compare also allows you to create a script folder, in which it can generate the scripts needed to recreate the database and its objects. These scripts can then be put into source control and SQL Compare can compare the scripts to a live database, and create a synchronization script to update that database. The basic steps for the initial generation of the scripts are:
- Select Script Folder as the Source, on the “New Project” screen
- Click on the short cut Create Schema Scripts….
- Connect to the database; and choose a name and location for the scripts.
- Click the Create Scripts Folder button
It will use the database that you defined as the source and will reverse engineer each of the objects out to a file. The files, unlike the output from SSMS, will be categorized and placed into a nice neat set of folders as shown in Figure 2.
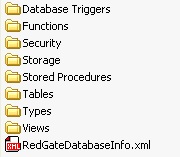
Figure 2: Script folder output from SQL Compare
With the database objects separated into scripts and the scripts neatly categorized, you can check these objects into the source control program of your choice to begin managing the deployments.
Visual Studio Team System Database Edition
In Visual Studio 2010 Team System, with a developer’s license comes the ability to create SQL Server Database Projects (previously, an add-on to Visual Studio). The Database Project represents a complete suite of tools for database development and deployment. It is designed to allow you to manage database code in source control in the same way as any other code, and with a familiar set of Visual Studio-style tools. It uses the offline model so developers must work with scripts, rather than a live database.
It is configured to layout the database as a discrete set of scripts, integrates directly with source control, and has a mechanism for building databases. To get started breaking your database down into scripts, you first have to create a database project. You can either begin creating objects or you can reverse engineer an existing database, basically the same thing as we did with Redgate SQL Compare. If you right-click on the database project in the project explorer window, you can use the Import Database Wizard. It really only requires a connection to the database you want to import, to get started.
There’s very little available from the wizard in terms of controlling how the database is imported. Everything is captured except the options you define such as extended properties, permissions or database file sizes. Click the Start button and the import will complete. Once it’s finished, you’ll have a full set of directories and files available to check into source control. VSTS:DB breaks down the database objects in a very granular manner such that, like SQL Compare, there is a folder for objects such as Table, but that is further broken down to include Constraint, Indexes, and Keys. This allows version control and source management at a very low level within your database. Figure 3 shows the folders and the levels of detail that they represent within the file system.
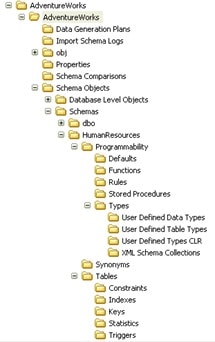
Figure 3: Part of the folder structure created by VSTS:DB
Using one of these methods, you convert your database into a set of scripts. Once you have a set of scripts, you need to add them to a source control system in order to manage sharing the database objects between multiple developers and DBAs.
SSMS
In the absence of any third party tools, and if PowerShell scripting is not an option, then basic scripting functionality is available in SSMS. Just right-click on your database and select Tasks | Generate Scripts… and you’ll enter the “Generate SQL Server Scripts” Wizard.
There are a whole series of options that allow you to control the objects that get scripted and the scripting options used for each object, or you can simply shortcut the whole process and script out every object in the database. On the “Output Options” screen, you should elect to Script to file, select the File per object radio button, determine the output path for the scripts and then click on the Finish button to generate the scripts.
You’ll end up with a rather-disorganized folder full of scripts that you can check into your source control system. The only problem is that there’s no easy way get these scripts back together to build your database. It’s possible to run the scripts, but they won’t run in the correct order, so you’ll end up with lots of dependency errors.
You’d need to build some mechanism for taking all the individual scripts, determine what has been changed and then generate a synchronization script, a script that reflects only the changed objects, to deploy to each environment.
Managing Data in Source Control
Getting control of the code, the object definitions, is only part of what makes up a database; there is also the data that is a part of any database. I’m not talking about the standard business data generated by users interacting with the application, but the metadata needed for the application to run. This data includes things like lookup tables, metadata, data that defines behavior, and so on. This data also has to be managed as part of any deployment. It can be maintained manually through scripts or by storing in a database, but there are also tools for managing data, similar to those tools used to manage code.
Authoritative Source Database
Data can’t really be checked into a source control system unless you export it as scripts, but then, depending on how much data you have, you could overwhelm your source control system. If you have a small set of data, you can script out the insert statements, or use sqlcmd to export the data to a set of files and check these into source control. However, if you have large sets of data, this might not be a viable option. Instead, a good method is to create an authoritative source database; a database you would treat like a production system, where you maintain what your source data should look like. You can add effective dates, expiration dates and flags to determine if a piece of data is ready for a production rollout. A basic lookup table, consisting of an ID/Value pair, would look something like as shown in Listing 3.
|
1 2 3 4 5 6 7 8 9 10 11 |
CREATE TABLE dbo.IvLookup ( ID INT NOT NULL IDENTITY(1,1) , IvValue NVARCHAR(50) NOT NULL , EffDate DATETIME NOT NULL , ExpDate DATETIME NULL , ProductionReady BIT NOT NULL , IsDeleted BIT NOT NULL , AppLabel NVARCHAR(30) NOT NULL , PRIMARY KEY CLUSTERED ( ID ) ); |
Listing 3: A lookup table in the authoritative source database
The data stored in a table, following this approach, allows for a number of control points to help dictate which data is ready for use in various environments. The ID and IVvalue columns for the lookup information are the easiest to describe. These would be artificial keys and associated values that provide the lookup information. The effective and expiration dates, EffDate and ExpDate, can be used to return only data that is active within a given time period. The bit fields ProductionRead and IsDeleted can be used to mark a value as either being ready for release to production, or as being logically deleted. Logical deleting is the best way to maintain data integrity and yet remove lookup values from active lists within the application. By labeling the software version that last updated the value, AppLabel, the data can be associated with a particular rollout, especially when the deployments are incremental, meaning that we are only deploying changes rather than performing a complete redeployment of a database.
To access this data from the authoritative source, a view would be necessary, which might look similar to that shown in Listing 4.
|
1 2 3 4 5 6 7 8 9 10 |
CREATE VIEW MySchema.IvLookup AS SELECT i.ID ,i.IvValue ,i.EffDate ,i.ExpDate ,i.IsDeleted FROM dbo.IvLookup i WHERE i.ProductionReady = 1 AND AppLabel = 'QA1301' |
Listing 4: A view to access the authoritative source data
The purpose of the view is to enable applications to determine, through their own rules, which values may or may not be included. A given application may only want the latest data, with no need to maintain data that has been logically deleted. Another application may need to deal with lots of legacy data and will need to maintain even the deleted data. Either application can create a view within a schema defined for that application. With this view, each application can create its own set of data, out of the authoritative source database, and eliminate the data definition and housekeeping columns such as isDeleted or ExpDate, if they are not needed in the application.
The rules to define which data belongs in production and will be part of any given rollout may vary, but the process for getting the data moved needs automation in the same fashion as the rest of the deployment. Luckily, like the rest of the deployment, there are tools and methods that can help move the correct data into place.
Data Movement Tools
There are a variety of data movement tools, available from a number of vendors including Embarcadero, Idera, Redgate and others. Most of them provide a common set of functions, including the ability to automatically identify data differences, map tables or views to each other, selectively or programmatically determine which data to move, and finally generate the script to migrate the required data. I’ll focus on the tools with which I’m most familiar: Redgate’s SQL Source Control and SQL Data Compare, and the Data Compare utility within Visual Studio.
Redgate SQL Source Control: Managing Static Data
SQL Source Control lets you track any changes to, and migrate, any static (lookup/reference) data on which an application may depend. This static data is typically non-transactional and updated infrequently (a table of US states would be one example).
Managing a table of static data from within SQL Source Control works pretty much the same as source controlling schema objects. The only difference is an additional selection step whereby you locate the table in the SSMS Object explorer, right-click and select Other SQL Source Control Tasks, and then click Link/Unlink Static Data.
Redgate SQL Data Compare
SQL Data Compare allows you to manage data for deployments and can be run from a GUI or through a command line interface. In order to show how to set up basic comparisons and definitions, I’ll use the GUI in the following examples, but in a real automated deployment situation, you would want to use the command line for most operations. In chapter 4 of ‘The Redgate Guide to SQL Server Team-based Development”, I’ll use the command line utilities as a part of a fully automated deployment.
If you adopt the scheme I’ve suggested, using the authoritative source database, then you can perform comparisons between that authoritative source and another database in order to generate scripts that reflect the data that must be installed. However, SQL Data Compare also allows for the use of data scripts as the authoritative source, so if your data size is not so large that is overwhelms your source control system, you can use files to maintain your data. Assuming the former, the steps to migrate/synchronize data between environments are:
- Start a new SQL Data Compare project, comparing two databases
- Connect to your authoritative source, as the source database, and the appropriate target database
- Define the SQL Server instance, the appropriate security criteria and each of the database to which you want to connect
- Click on the Options tab and enable “Include views” (so that the application-specific view is included as part of the comparison)
- Move to the Tables & Views tab. If the schema names are the same in each database and the objects in each database match up then you can begin the comparison. If not, then either:
- use the Object Mapping tab to manually map each object in the source to the appropriate object in the target, or
- use the Owner Mapping tab to map the two schemas
- In the scheme suggested, the objects identified in the source are views and so do not have primary keys and can’t be compared. For any such objects, the term “Not Set” will appear in the Comparison Key column on the Tables & Views tab. Click on each “Not set” entry to choose the correct mapping key from the options that SQL Data Compare has indentified.
- Run the data comparison for the selected objects.
For the purposes of this article, the results of the comparison don’t really matter. What does matter is the creation of the comparison project that is the result of the above process. The options settings, object mappings, the selection of custom comparison keys, and the results of all these processes, can be saved as a project. Once the project is saved it can be reused, not simply in the GUI but also from a command line. The command line allows for automation of the deployment process. In addition to the command line, a full software development kit is also available to allow for integration into home-grown applications. Automation of deployments is one the key ingredients for team development. Taking into account the ability to map mismatched objects, it is possible to support multiple teams and multiple projects from a single authoritative source and automate those deployments.
Visual Studio Data Comparison
The Database Development tool within Visual Studio also provides a data comparison utility, although with radically fewer options available to it than Redgate’s SQL Compare. It can’t compare a database to a file and more importantly, it can’t map between disparate objects. In order to use this tool the objects need to match up, in both schema and name. This prevents the type of mapping that would allow multiple applications to easily consume the data fed to them from an authoritative source. However, a single database can still be used, just not with the flexibility of the other software.
It is possible to still use views, but they need to be indexed views created using schema binding, so to support comparing the data tables between a target database and the AuthoritativeSource database, a set of indexed, schema bound, views must be created inside a schema named the same as in the target database.
Like Redgate Data Compare, the Data Comparison utility in Visual Studio requires an initial setup before it will be available for automated deployments:
- Open the Data Compare utility, through the Data menu in Visual Studio.
- Open a New Data Comparison
- Supply two database connections, a Source and a Target.
- Define what sort of records you want to compare in the data Compare Options box (generally all types of records will be compared)
- Click the Next button and define which tables, views and columns are to be moved.
Like with the Redgate SQL Data compare, the final results are not important. What is important is that once the comparison has been configured, it can be saved and called up at will as part of an automated deployment.
Summary
Change management in development can be very difficult and in database development can be extremely hard, especially when multiple teams are involved.
Having the right processes in place, and sufficient environments to support those processes, is a large step towards taming team-based database development. Once you’ve established these processes and moved your code into source control, you now need to work on automating as many of the deployments to all these new environments as you can, in order to make the processes repeatable and easy to maintain.

DevOps, Continuous Delivery & Database Lifecycle Management
Go to the Simple Talk library to find more articles, or visit www.red-gate.com/solutions for more information on the benefits of extending DevOps practices to SQL Server databases.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved





Load comments