

Code refactoring is a common process when developing in procedural languages – and essential to developing high-quality code – yet somehow often gets overlooked in SQL. In this article, we’ll explain what refactoring is, how it helps, and give concrete examples on how it can make your code more readable, reliable, and maintainable.
What is Refactoring?
Over time the term “refactoring” has expanded and is sometimes used to mean code quality improvement in general, but here we are using it with its original meaning: condensing and eliminating redundant segments of code. Like factoring a number in math, we break the code into smaller blocks, identify any repeated elements, then replace them with a single reference. The graphic below illustrates the basic concept of what refactoring tries to accomplish:
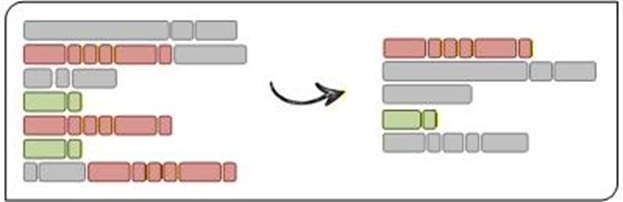
Refactoring can be considered a case of the DRY (Don’t Repeat Yourself) principle of software development. Redundant code is harder to read, more prone to bugs, and significantly more expensive to maintain.
Usually, refactoring doesn’t help performance; it just improves the code quality. But on shorter queries where parsing is a substantial portion of the total execution time, refactoring can improve performance too.
We’ll start with some tips on refactoring single queries, then move on to strategies for refactoring across your entire code base. We’ll demonstrate using short examples, but real-world queries can benefit even more. One of the most extreme cases I encountered, refactoring reduced a 1,200 line query down to just 90 lines – without, of course, altering the results at all.
1. Use a Derived Table
Even novice SQL developers are usually adept at using subqueries in a WHERE clause or as a column in a SELECT. But a subquery that returns a table-valued object can also be the target of the FROM clause, meaning we can use the result just as we would a base table. Such derived tables are ideal for creating intermediate values for further processing. The basic syntax looks like this:
|
1 2 3 4 |
SELECT (use derived columns here) FROM ( SELECT (create derived columns here) FROM (base table) ) AS (table alias) |
Let’s turn these words into an actual example. Imagine a company that awards a pay modifier of 1% for every month an employee has worked beyond their first twelve months. Our task is a query that calculates for each employee the value of this modifier, along with modified values for their base and bonus pay. Note: we’re using MS SQL Server date functions. The syntax for PostgreSQL or MySQL is slightly different.
Our employee table contains the following columns:
|
1 2 3 4 5 6 |
CREATE TABLE employees ( emp_id INT NOT NULL, hire_date DATE NOT NULL, base_pay NUMERIC(9,2) NOT NULL, bonus_pay NUMERIC(9,2) NOT NULL, … ); |
The query to calculate the pay values is straightforward, though very redundant – we have to repeat the date arithmetic three times:
|
1 2 3 4 5 6 |
SELECT emp_id, (GREATEST(DATEDIFF(month, hire_date, GETDATE())-12,0) * .01 + 1), (GREATEST(DATEDIFF(month, hire_date, GETDATE())-12,0) * .01 + 1) * base_pay, (GREATEST(DATEDIFF(month, hire_date, GETDATE())-12,0) * .01 + 1) * bonus_pay FROM employees; |
But if we move that date arithmetic into a subquery, the redundancy vanishes:
|
1 2 3 4 5 6 7 |
SELECT emp_id, pay_mod, pay_mod * base_pay, pay_mod * bonus_pay FROM (SELECT GREATEST(DATEDIFF(month, hire_date, GETDATE())-12,0) * .01 + 1 AS pay_mod, * FROM employees) AS sub |
Note: a version of this with PostgreSQL-format date arithmetic is in Appendix I.
Remember that a derived table is a table – we can join other tables to it directly, just as if it was a base table. So we can use this technique to simplify much larger, more complex queries than this example.
2. Lateral Join
A lateral join is similar to a correlated subquery: both are evaluated once for every row in the main query. But where a subquery can only return a single value, a lateral join can return an entire row of values, or even multiple rows. This makes it an obvious choice for refactoring queries that contain multiple identical or similar subqueries. Again, let’s illustrate this with a concrete example.
Using our employees table from above, let’s write a query to pair each employee with the name and date of the first company “team building” event occurring after they were hired. We have a new table of team events:
|
1 2 3 |
CREATE TABLE team_events ( event_name VARCHAR(128) NOT NULL, event_date DATE NOT NULL ); |
Matching the right team event to each employee is easy enough: find event dates greater than the employee hire date, order by event_date, then use TOP 1 (or LIMIT 1, for MySQL/PostgreSQL) to match a single row. The problem is we can’t use a normal join because of that pesky one-row limit. So you might be tempted to use subqueries:
|
1 2 3 4 5 6 7 |
SELECT e.emp_id, ( SELECT event_date FROM team_events te WHERE te.event_date > e.hire_date ORDER BY event_date LIMIT 1) ( SELECT event_name FROM team_events te WHERE te.event_date > e.hire_date ORDER BY event_date LIMIT 1) FROM employees e |
If you had to select three or more columns in such a manner, you can see this quickly becomes a mess. But a lateral join handily removes the redundancy:
|
1 2 3 4 5 6 7 |
SELECT e.emp_id, te.event_date, te.event_name FROM employees e LEFT JOIN LATERAL ( SELECT * FROM team_events te WHERE te.event_date > e.hire_date ORDER BY event_date LIMIT 1 ) te ON true |
(Note: SQL Server uses the ‘APPLY’ keyword for lateral joins; see Appendix I)
A Left Join is used to ensure all employees are listed, even if no matching event exists. Notice that our join condition is just the “true” flag. This is because we encapsulate the join condition within the lateral subquery.
3. Common Table Expression (CTE)
The word “common” in ‘Common Table Expression’ is a hint on how useful these can be for removing redundancy in queries. Our first two tips are limited on where the refactored code can be used. But CTEs are much more flexible: define it at the start of your query and use it anywhere you like, as often as you like. That makes CTEs the ‘Swiss army knife’ of SQL code refactoring.
To illustrate, let’s expand our last example of team building events. These events hold a competition that matches each employee to everyone else present, and we want a query to reflect this. To generate this “round robin” result, we use the query from above to match employees to events, then, using the same query, self-join the result table to itself. The resulting query is confusing and hard to read – the redundant blocks are highlighted to identify them:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
SELECT e1.emp_id, e2.emp_id, te1.event_name, te1.event_date FROM employees e1 LEFT JOIN LATERAL ( SELECT * FROM team_events te WHERE te.event_date > e1.hire_date ORDER BY event_date LIMIT 1 ) te1 ON true INNER JOIN employees e2 ON e1.emp_id < e2.emp_id LEFT JOIN LATERAL ( SELECT * FROM team_events te WHERE te.event_date > e2.hire_date ORDER BY event_date LIMIT 1 ) te2 ON true WHERE te1.event_name = te2.event_name; |
Using a CTE, we can condense the two redundant blocks into one, making the code shorter and much easier to understand:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
WITH emp_event AS ( SELECT * FROM employees e LEFT JOIN LATERAL ( SELECT * FROM team_events te WHERE te.event_date > e.hire_date ORDER BY event_date LIMIT 1 ) te ON true) SELECT ee1.emp_id, ee2.emp_id, ee1.event_name, ee1.event_date FROM emp_event ee1 INNER JOIN emp_event ee2 ON ee1.event_name = ee2.event_name AND ee1.emp_id < ee2.emp_id; |
Here we name our CTE “emp_event” to indicate its joining employees to events. While we use the CTE twice here, a CTE can be used three, four, or more times in a single query. Even if you use it just once, a CTE can still be useful. It doesn’t shorten the query, but separating out a block of code and naming it to indicate purpose can help organize a large query.
10 tools for every stage of SQL Server development
4. Defining a View
All our examples so far have involved a single query. Let’s look more globally: refactoring across an entire database. Often a code pattern – especially those involving table joins – appears throughout a system over and over again. One of the easiest ways to eliminate this redundancy is by defining a view.
For our example, imagine a database tracking security alerts. The alert description is based on its type, and comes from one lookup table, while the alert priority is based on its source, and comes from another lookup table. So, whenever we access an alert, we must join the same three tables in the same manner:
|
1 2 3 4 |
SELECT a.*, at.description, ap.priority FROM Alerts a LEFT OUTER JOIN AlertTypes at ON a.type = at.type LEFT OUTER JOIN AlertPriorities ap ON a.source = ap.source |
The details of this query aren’t terribly important. The point is that it’s a block of code that’s likely to be repeated throughout an application, whenever an alert is accessed. On production systems, it’s common to see such join patterns – by themselves or as blocks in larger queries – repeated dozens or even hundreds of times.
Defining a view allows us to remove the redundancy, centralizing the business logic within the view, and allowing us to treat these three tables as if they were a single unit. This is as simple as prefacing the code in question with a CREATE VIEW statement:
|
1 2 3 4 5 |
CREATE VIEW VwAlert AS SELECT a.*, at.description, ap.priority FROM Alerts a LEFT OUTER JOIN AlertTypes at ON a.alert_type = at.alert_type LEFT OUTER JOIN AlertPriority ap ON a.alert_source = ap.alert_source |
We can of course query this view directly. But we can also treat it as a table, including it as part of a larger query, for example:
|
1 2 |
SELECT * FROM devices d INNER JOIN VwAlerts va d.device_id = va.device_id |
or:
|
1 2 |
SELECT * FROM USERS u INNER JOIN VwAlerts va ON u.user_id = va.user_id |
If our business logic involving alert definition changes, we update one view, rather than performing edits scattered across multiple queries.
5. Generated Columns
Generated columns (known as computed columns in SQL Server) allow us to define a repetitive calculation inside a table definition, to be done automatically whenever any query or application accesses the table. This not only eliminates redundancy, but it centralizes business logic at the DDL (data definition layer) – preventing any query or application from overriding or altering it.
In our employee table, let’s add a column with a code to indicate employee type: ‘P’ for permanent, ‘S’ for temporary seasonal help, and ‘I’ for interns. To determine how many days per year of paid time off they’re eligible for, the following rule is used:
- Permanent employees receive 10 days.
- Interns receive 0 days.
- Seasonal help hired in December receive 1 day, otherwise they receive 3.
Calculating this value can be done with a single CASE statement, but a large system might use that value in dozens of forms, screens and queries across multiple applications. Repeating the code to calculate it is wasteful and prone to error and, if the code ever changes, updating can be a nightmare. A generated (computed) column is a better approach.
In SQL Server, the code is straightforward (only our two new columns are included here):
|
1 2 3 4 5 6 7 8 9 10 |
CREATE TABLE employees ( … emp_code CHAR(1) NOT NULL DEFAULT 'P', pto_days AS (CASE WHEN emp_code='P' THEN 10 WHEN emp_code='I' THEN 0 WHEN emp_code = 'S' AND MONTH(hire_date)=12 THEN 1 WHEN emp_code = 'S' AND MONTH(hire_date)<>12 THEN 3 ELSE NULL END) ); |
In MySQL, the code is similar, except it requires us to explicitly state the column’s data type:
|
1 2 3 4 5 6 7 8 9 10 |
CREATE TABLE employees ( … emp_code CHAR(1) NOT NULL DEFAULT 'P', pto_days INTEGER GENERATED ALWAYS AS (CASE WHEN emp_code='P' THEN 10 WHEN emp_code='I' THEN 0 WHEN emp_code = 'S' AND MONTH(hire_date)=12 THEN 1 WHEN emp_code = 'S' AND MONTH(hire_date)<>12 THEN 3 ELSE NULL END) VIRTUAL ); |
In both cases, we’ve defined the column as virtual: it’s calculated on the fly when we query its value. Both SQL Server and MySQL have a second option, which physically stores the calculated value in the table itself. One benefit of storing the generated column is that it allows you to index on it. When a query needs to order by or quickly search for the results of a calculation, this is a very handy feature.
Note: At the time of writing, PostgreSQL didn’t support virtual generated columns – the only option was store the value – but as of PostgreSQL 18 (released in September), this functionality was added.
Final Thoughts & Next Steps
Like any other programming language, SQL benefits from the compact, readable, and well-structured code that refactoring creates. These five techniques aren’t the only ways to get there, but they’re all useful and should be part of your daily toolkit.
Please scroll to the bottom of the article for the full sample code.
Update 12/12/2025: SQL Server Central Editor Steve Jones has been thinking about refactoring SQL code and shared his thoughts in this article. What do you think? Whether you comment here on Simple Talk or over on SSC, we’d love to hear your views.
FAQs: Refactoring SQL Code
1. What is SQL code refactoring?
Refactoring SQL code means improving the structure, readability and maintainability of SQL queries and database objects without altering their external behavior.
2. Why refactor SQL code?
Over time, SQL scripts can accumulate technical debt – making them harder to read, brittle to schema changes and expensive to maintain. Refactoring improves clarity and lowers risk.
3. When should you refactor SQL code?
Consider refactoring when you see messy formatting, SELECT * wildcards, dynamic SQL constructs, duplicated logic, or frequent schema changes breaking queries.
4. What are key strategies for refactoring SQL code?
- Apply consistent formatting and naming conventions.
- Replace wildcards (
SELECT *) with explicit column lists. - Replace dynamic filters and dynamic
ORDER BYwith static SQL when possible. - Decompose complex logic into variables or simpler statements.
- Rename stored procedures, functions and objects to meaningful names.
5. What risks should be managed during SQL refactoring?
Changing code structure may affect performance, break dependencies, or introduce bugs if tests aren’t in place. Ensure you have good regression tests.
6. How should you approach SQL refactoring in practice?
Start small, refactor incrementally, test thoroughly before and after each change, and use tools where available. Keep old and new code supported when transitioning.
7. What benefits result from well-executed SQL refactoring?
You’ll get cleaner, more maintainable code, better resilience to schema changes, faster onboarding for new developers, and lower long-term maintenance costs.
Appendix I: Sample Code
Part 1: Create tables and load test data
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
CREATE TABLE employees ( emp_id INT NOT NULL, name VARCHAR(64), hire_date DATE NOT NULL, base_pay NUMERIC(9,2) NOT NULL, bonus_pay NUMERIC(9,2) NOT NULL ); CREATE TABLE team_events ( event_name VARCHAR(128) NOT NULL, event_date DATE NOT NULL ); INSERT INTO employees values (101,'Joe','11-01-2023', 72400, 7250), (102,'Alice','08-15-2024', 67000, 6700), (103,'Keith','11-02-2024', 98250, 0), (104,'Toby','10-21-2025', 59500, 5950), (105,'Marge','04-30-2025', 48000, 1000), (106,'Olaf','07-31-2025', 46500, 1000), (107,'Amar','10-03-2022', 95000, 0); INSERT INTO team_events values ('Downtown Scavenger Hunt','12-02-2022'), ('Lakefront Luau','12-10-2023'), ('Air Guitar Competition', '12-09-2024'), ('Rocket Go Karts', '12-11-2025'); |
Part 2: Examples 1-3 in PostgreSQL format
Example 1, unfactored
|
1 2 3 4 5 6 7 8 9 10 11 12 |
SELECT emp_id, (GREATEST((EXTRACT(YEAR from AGE(now(), hire_date))-1) * 12 + EXTRACT(MONTH from AGE(now(), hire_date)),0) * .01 + 1), (GREATEST((EXTRACT(YEAR from AGE(now(), hire_date))-1) * 12 + EXTRACT(MONTH from AGE(now(), hire_date)),0) * .01 + 1) * base_pay, (GREATEST((EXTRACT(YEAR from AGE(now(), hire_date))-1) * 12 + EXTRACT(MONTH from AGE(now(), hire_date)),0) * .01 + 1) * bonus_pay FROM employees; -- Example 1, factored SELECT emp_id, pay_mod, pay_mod * base_pay, pay_mod * bonus_pay FROM (SELECT GREATEST((EXTRACT(YEAR from AGE(now(), hire_date))-1) * 12 + EXTRACT(MONTH from AGE(now(), hire_date)),0) * .01 + 1 AS pay_mod, * FROM employees) AS sub |
Example 1, factored
|
1 2 3 4 |
SELECT emp_id, pay_mod, pay_mod * base_pay, pay_mod * bonus_pay FROM (SELECT GREATEST((EXTRACT(YEAR from AGE(now(), hire_date))-1) * 12 + EXTRACT(MONTH from AGE(now(), hire_date)),0) * .01 + 1 AS pay_mod, * FROM employees) AS sub |
Example 2, unfactored
|
1 2 3 4 5 6 |
SELECT e.emp_id, ( SELECT event_date FROM team_events te WHERE te.event_date > e.hire_date ORDER BY event_date LIMIT 1), ( SELECT event_name FROM team_events te WHERE te.event_date > e.hire_date ORDER BY event_date LIMIT 1) FROM employees e |
Example 2, factored
|
1 2 3 4 5 6 7 |
SELECT e.emp_id, te.event_date, te.event_name FROM employees e LEFT JOIN LATERAL ( SELECT * FROM team_events te WHERE te.event_date > e.hire_date ORDER BY event_date LIMIT 1 ) te ON true |
Example 3, unfactored
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
SELECT e1.emp_id, e2.emp_id, te1.event_name, te1.event_date FROM employees e1 LEFT JOIN LATERAL ( SELECT * FROM team_events te WHERE te.event_date > e1.hire_date ORDER BY event_date LIMIT 1 ) te1 ON true INNER JOIN employees e2 ON e1.emp_id < e2.emp_id LEFT JOIN LATERAL ( SELECT * FROM team_events te WHERE te.event_date > e2.hire_date ORDER BY event_date LIMIT 1 ) te2 ON true WHERE te1.event_name = te2.event_name; |
Example 3, factored
|
1 2 3 4 5 6 7 8 9 10 |
WITH emp_event AS ( SELECT * FROM employees e LEFT JOIN LATERAL ( SELECT * FROM team_events te WHERE te.event_date > e.hire_date ORDER BY event_date LIMIT 1 ) te ON true) SELECT ee1.emp_id, ee2.emp_id, ee1.event_name, ee1.event_date FROM emp_event ee1 INNER JOIN emp_event ee2 ON ee1.event_name = ee2.event_name AND ee1.emp_id < ee2.emp_id; |
Part 3: Examples in SQL Server format
Example 1, unfactored
|
1 2 3 4 5 6 |
SELECT emp_id, (GREATEST(DATEDIFF(month, hire_date, GETDATE())-12,0) * .01 + 1), (GREATEST(DATEDIFF(month, hire_date, GETDATE())-12,0) * .01 + 1) * base_pay, (GREATEST(DATEDIFF(month, hire_date, GETDATE())-12,0) * .01 + 1) * bonus_pay FROM employees; |
Example 1, factored
|
1 2 3 4 |
SELECT emp_id, pay_mod, pay_mod * base_pay, pay_mod * bonus_pay FROM (SELECT GREATEST(DATEDIFF(month, hire_date, GETDATE())-12,0) * .01 + 1 AS pay_mod, * FROM employees) AS sub |
Example 2, unfactored
|
1 2 3 4 5 6 |
SELECT e.emp_id, (SELECT TOP 1 event_date FROM team_events te WHERE te.event_date > e.hire_date ORDER BY event_date), (SELECT TOP 1 event_name FROM team_events te WHERE te.event_date > e.hire_date ORDER BY event_date) FROM employees e |
Example 2, factored
|
1 2 3 4 5 6 |
SELECT e.emp_id, te.event_date, te.event_name FROM employees e OUTER APPLY ( SELECT TOP 1 * FROM team_events te WHERE te.event_date > e.hire_date ORDER BY event_date ) te |
Example 3, unfactored
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
SELECT e1.emp_id, e2.emp_id, te1.event_name, te1.event_date FROM employees e1 OUTER APPLY ( SELECT TOP 1 * FROM team_events te WHERE te.event_date > e1.hire_date ORDER BY event_date ) te1 INNER JOIN employees e2 ON e1.emp_id < e2.emp_id OUTER APPLY ( SELECT TOP 1 * FROM team_events te WHERE te.event_date > e2.hire_date ORDER BY event_date ) te2 WHERE te1.event_name = te2.event_name; |
Example 3, factored
|
1 2 3 4 5 6 7 8 9 10 |
WITH emp_event AS ( SELECT * FROM employees e OUTER APPLY ( SELECT TOP 1 * FROM team_events te WHERE te.event_date > e.hire_date ORDER BY event_date ) te ) SELECT ee1.emp_id, ee2.emp_id, ee1.event_name, ee1.event_date FROM emp_event ee1 INNER JOIN emp_event ee2 ON ee1.event_name = ee2.event_name AND ee1.emp_id < ee2.emp_id; |
Subscribe to the Simple Talk newsletter
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved






Load comments