
A subquery in SQL is a SELECT statement embedded inside another SQL statement – typically within a WHERE, FROM, or SELECT clause. SQL Server supports two types: basic (standalone) subqueries that execute independently, and correlated subqueries that reference columns from the outer query.
Use subqueries in WHERE with comparison operators or IN/EXISTS for filtering, in FROM as derived tables for intermediate result sets, or in SELECT for computed column values. This guide covers both types with working examples against the AdventureWorks database.
Did you know you can include a SELECT statement within another SELECT statement? When a SELECT statement is embedded within another statement it is known as a subquery. There are two types of subqueries: basic subquery and correlated subquery.
In this article I will be discussing both types of subqueries and will be providing examples of how to use a subquery in different places within in a SELECT statement.
Difference between a basic subquery and a correlated subquery
A basic subquery is a “stand alone” SELECT statement that is embedded inside another SQL statement. By “stand alone”, I mean the SELECT statement that is embedded in another statement can be run independently from the statement in which it is embedded. A correlated subquery on the other hand is also a SELECT statement embedded within another query that has a dependence on the statement in which it is embedded. The correlated subquery cannot be run independently from the statement it is embedded because of the dependency.
A subquery and correlated subquery can be used anywhere in a SQL command that an expression can be used. Both types of subqueries are also known as an “inner query” or “inner select”. Whereas the SQL statement that contains the embedded subquery is known as the outer query. Subqueries are easy to spot because they are contained within a set of parentheses.
Depending on how the inner query is used in relationship to the outer query, will determine how many columns and values a subquery can return. For example, when a subquery is used in a WHERE cause that contains a comparison operator (=, !=, <, >, or >=) the subquery needs to return a single column value.
If the subquery is used with a comparison operator that supports multiple values, like an IN expression, then the subquery can return multiple values. A subquery can also return multiple columns when used in an EXISTS expression or when used in a derived table in the FROM clause.
To better understand how to use these two different types of subqueries in a SELECT statement let me go through a few subquery examples in the following sections.
Read also:
Gaps and islands analysis in SQL
CHOOSE function in SQL Server
Test data
All the examples in this article will run against that AdventureWorks2019 OLTP sample database. If you want to follow along and run the examples in this article you will need to download and restore the backup file for AdventureWorks2019 databases. The download link for this backup can be found on this web page, or by downloading using this link.
Ways to use subqueries
In the following sections, I will demonstrate several ways to use a subquery to create richer queries that I have demonstrated before. Subqueries let you have dynamic, data-driven queries where instead of a literal value (or list of values), you can dynamically get a value or list of values from a query.
Using a subquery in a column list
Both types of subqueries can be used in a column list. When a basic or correlated subquery is used in a column list it can only return a single value. The value returned will be incorporated into the result set as a column value in the outer query. To see basic subquery in a column list in action consider the code in Listing 1.
|
1 2 |
SELECT TerritoryID FROM Sales.Customer WHERE CustomerID = 29974; |
Listing 1: Code to return a TerritoryID
The code in Listing 1 will return a TerritoryID for CustomerID = 29964. This query will be used as a subquery in Listing 2.
|
1 2 3 4 5 6 7 8 9 10 |
USE AdventureWorks2019; GO SELECT CustomerID, DueDate, TotalDue, (SELECT TerritoryID FROM Sales.Customer WHERE CustomerID = 29974) AS TerritoryID FROM Sales.SalesOrderHeader WHERE CustomerID = 29974; |
Listing 2: Using a subquery in a column list
By Reviewing the code in Listing 2 you can see the code from Listing 1 is embedded in the column list. In Listing 2 the first three column values CustomerID, DueDate and TotalDue are returned from the Sales.SalesOrderHeader table. But the 4th column returned is from the results of the subquery. Or in this case the TerritoryID from the Sales.Customer table.
When the code in Listing 2 is executed the results in Report 1 are produced.
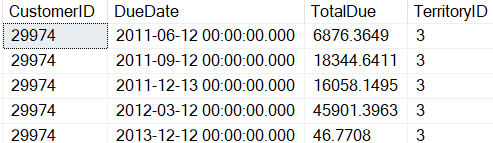
Report 1: Results when Listing 2 is run
The subquery that returns the TerritoryID column value is only evaluated one time, and the values returned from the subquery are then placed on every row returned from the outer query. Additionally worth mentioning is the basic subquery code can be run independently of the code in which it is embedded. Since this code can be run independently it make this embedded SELECT statement a basic subquery, and not a correlated subquery.
A correlated subquery can also be included in a column list. To demonstrate this, refer to Listing 3.
|
1 2 3 4 5 6 7 |
USE AdventureWorks2019; GO SELECT TOP 5 C.CustomerID, (SELECT SUM(TotalDue) FROM Sales.SalesOrderHeader H WHERE H.CustomerID = C.CustomerID) AS TotalDue FROM Sales.Customer C ORDER BY TotalDue DESC; |
Listing 3: Correlated subquery in selection list
When the code is Listing 3 is executed the results in Report 2 is displayed.
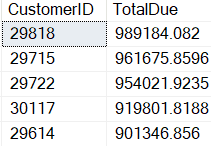
Report 2: Results when Listing 3 is run
The difference between a basic subquery and a correlated subquery is the correlate subquery references columns from the outer query. In Listing 3 the correlated subquery referenced the column C.CustomerID. The correlated subquery is run once for every row returned from the outer query. The correlated subquery calculates the total amount due for each customer selected. Another difference between a basic query and a correlated subquery is the correlated subquery cannot be run independently of the outer query without getting an error.
When a subquery or correlated subquery is used in the column list the embedded code can only bring back a single column and a single column value. If you try to return multiple columns, or multiple values an error will occur.
To show what will happen when multiple columns are requested in a subquery within a column list, I will run the code in Listing 4.
|
1 2 3 4 5 6 7 8 9 |
USE AdventureWorks2019; GO SELECT CustomerID, DueDate, TotalDue, (SELECT TerritoryID, StoreID FROM Sales.Customer WHERE CustomerID = 29974) AS TerritoryID FROM Sales.SalesOrderHeader WHERE CustomerID = 29974; |
Listing 4: Trying to bring back multiple column values in subquery code
In the subquery in Listing 4, the StoreID column was added to the subquery. When this code is executed the error in Report 3 is produced.
Msg 116, Level 16, State 1, Line 7Only one expression can be specified in the select list when the subquery is not introduced with EXISTS.
Report 3: Error when more than one column is identified in a column list subquery.
In order to bring back the StoreID value a second subquery can be added to the original code, as was done in Listing 5.
|
1 2 3 4 5 6 7 8 9 10 11 |
USE AdventureWorks2019; GO SELECT CustomerID, DueDate, TotalDue, (SELECT TerritoryID FROM Sales.Customer WHERE CustomerID = 29974) AS TerritoryID, (SELECT StoreID FROM Sales.Customer WHERE CustomerID = 29974) AS StoreID FROM Sales.SalesOrderHeader WHERE CustomerID = 29974; |
Listing 5: Having multiple subqueries in a column list.
I’ll leave it up to you to verify that both the TerritoryID and StoreID values are returned using the two different subqueries in Listing 5.
Using a Subquery in a WHERE clause
A basic and correlated subquery can also be used in a WHERE statement. Depending on the operators used in the WHERE constraint will determine the number of values a subquery can return. If the subquery uses one of these operators: “=, !=, <, >, or >=" then only a single value can be returned from the subquery in the WHERE constraint. To show an example of using a basic subquery in the WHERE constraint that uses one of these operators review the code in Listing 6.
|
1 2 3 4 5 6 7 |
USE AdventureWorks2019; GO SELECT TOP 5 CustomerID, TerritoryID, TotalDue FROM Sales.SalesOrderHeader WHERE TerritoryID = (SELECT TerritoryID FROM Sales.SalesTerritory WHERE Name = 'Northeast'); |
Listing 6: Using a subquery in the WHERE constraint.
In Listing 6 the subquery code is associated with the WHERE constraint. In this case the subquery returns the TerritoryID for the “Northeast” region. The TerritoryID returned is then used in conjunction the equals (“=”) operator. When the code in Listing 6 is executed, it produces the output in Report 4.
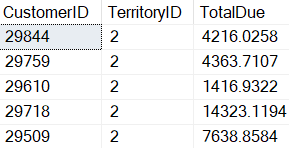
Report 4: Output when Listing 5 is executed.
The operator used in the WHERE constraint in the prior example can return a single value because the operator “=” was used. But when an operator used in conjunction with the subquery can handle multiple values, then a subquery can bring back more than a single value. To show how multiple values can be used in a correlated subquery the “IN” operator will be used in the subquery in Listing 6.
|
1 2 3 4 5 6 7 |
USE AdventureWorks2019; GO SELECT TOP 5 CustomerID, TerritoryID, TotalDue FROM Sales.SalesOrderHeader WHERE TerritoryID IN (SELECT TerritoryID FROM Sales.SalesTerritory WHERE Name Like '%east'); |
Listing 6: Using a correlated subquery with the IN operator
The subquery in listing 6 returns multiple TerritoryID values. Multiple values can be returned because the IN operator supports multiple values. When the code in Listing 6 is executed the results in Report 4 is produced.
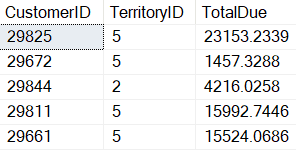
Report 4: Output produced when the in operator is used.
Here you can see TerritoryID values of 2 and 5 were returned from the subquery, but since it is not a correlated subquery, you can also simply execute the code in the IN expression, something I frequently do by just highlighting the code in SSMS:

The output of this code will be the TerritoryID values, which are, as expected, 2 and 5.
Using a Subquery in a FROM clause
A subquery can also be used in a FROM clause. When a subquery is used in a FROM clause the set created by the subquery is commonly called a derived table, which is stored in memory. In Listing 7 I have used a subquery to return a subset of the SalesOrderHeader rows for a specific date. The derived table is then joined with the SalesOrderDetail, and the Production.Product table to build the final result set.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
USE AdventureWorks2019; GO SELECT Header.SalesOrderID, Header.OrderDate, Name, StandardCost FROM (SELECT SalesOrderID, OrderDate FROM Sales.SalesOrderHeader WHERE OrderDate = '2012-08-21 00:00:00.000') AS Header JOIN Sales.SalesOrderDetail AS Detail ON Header.SalesOrderID = Detail.SalesOrderID JOIN Production.Product AS Product ON Detail.ProductID = Product.ProductID; |
Listing 7: Subquery in the FROM clause
When the SELECT statement in Listing 7 is execute the results in Report 5 are produced.
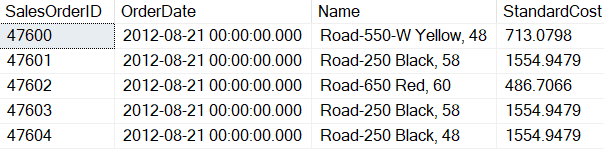
Report 5: Results when Listing 7 is executed.
The SalesOrderID and OrderDate are the columns that came from the subquery. Writing a subquery that is used in a FROM clause should be avoid if there is another way to write the query. This is because there are no indexes on a derived table so performance might suffer.
A correlated subquery cannot be used in a FROM clause. The reason is because the correlated subquery cannot be evaluated for every row of the outer query.
Using a Subquery in a HAVING clause
A subquery can also be used in a HAVING clause. To show how a subquery can be used in a HAVING clause let’s first consider the SELECT statement in Listing 8.
|
1 2 3 4 5 |
USE AdventureWorks2019; GO SELECT COUNT(*) AS NumOfOrders FROM [Sales].[SalesOrderHeader] WHERE OrderDate = '2014-05-01 00:00:00.000'; |
Listing 8: Number of orders created for a specific date
The SELECT statement in Listing 8 identifies the orders that were created on May 1, 2014, which in this case where 227 orders created on that date. Suppose now you want to identify which OrderDates have more orders than the number of orders created on May 1, 2014 (which is 227). To do that you could take the query in Listing 8 and place it in the HAVING clause as a subquery, as I have done in Listing 9.
|
1 2 3 4 5 6 7 8 9 10 |
USE AdventureWorks2019; GO SELECT COUNT(*) AS NumOfOrders, OrderDate FROM [Sales].[SalesOrderHeader] GROUP BY OrderDate HAVING COUNT(*) > (SELECT COUNT(*) AS NumOfOrders FROM [Sales].[SalesOrderHeader] WHERE OrderDate = '2014-05-01 00:00:00.000') ORDER BY OrderDate; |
Listing 9: Using a subquery in a HAVING clause
When Listing 9 is run the results are shown in Report 6
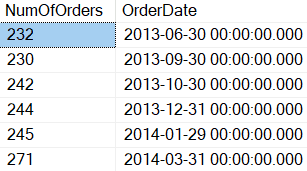
Report 6: Results when Listing 9 is executed.
By reviewing Report 6 you can see that there are 6 OrderDate values that have processed more orders than on May 1, 2014.
A correlated subquery can also be used in a HAVING clause. To demonstrate this, suppose you want to return the SalesOrderID values in the Sales.SalesOrderHeader table that have more than 70 detailed records. The code in Listing 10 accomplishes this by using a correlated subquery in the HAVING clause.
|
1 2 3 4 5 6 7 8 9 |
USE AdventureWorks2019 GO SELECT H.SalesOrderID FROM Sales.SalesOrderHeader AS H GROUP BY SalesOrderID -- Having more that 70 detail rows HAVING (SELECT COUNT(*) FROM Sales.SalesOrderDetail AS D WHERE H.SalesOrderID = D.SalesOrderID) > 70; |
Listing 10: Correlated subquery in HAVING clause.
When the code in Listing 10 is run the four rows in Report 7 were found.
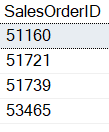
Report 7: The results when the code in Listing 10 is executed.
Using a subquery in a Function call
A subquery can also be used as a parameter of a function call. The code in Listing 11 shows how a subquery can be used as a parameter to the DATEDIFF function.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
USE AdventureWorks2019; GO SELECT TOP 3 SalesOrderID, CustomerID, OrderDate, DATEDIFF (dd, OrderDate, (SELECT Max(OrderDate) FROM Sales.SalesOrderHeader WHERE CustomerID = 29610) ) NumOfDays FROM Sales.SalesOrderHeader WHERE CustomerID = 29610; |
Listing 11: Using a subquery in a function call
In Listing 11 the subquery determines the maximum order date for CustomerID = 29610. Which in this case is 2013-02-08. The DATEDIFF function then determines the number of days between that date and other orders for CustomerID 29610, and only returns the TOP three orders. When the code in Listing 11 is executed, the results are shown in Report 8.

Report 8: Results when Listing 10 is executed
Which in this case are the oldest three orders for CustomerID 29610.
Performance Considerations for Basic Subqueries
In the Microsoft documentation about subqueries found here, the following statement regarding performance is mentioned:
In Transact-SQL, there’s usually no performance difference between a statement that includes a subquery and a semantically equivalent version that doesn’t.
To validate that a subquery performs the same as an equivalent version that doesn’t use a subquery let’s review the code in Listing 12.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
USE AdventureWorks2019; GO -- Subqeury SELECT OD.* FROM Sales.SalesOrderDetail AS OD WHERE ProductID = (SELECT ProductID FROM Production.Product WHERE Name = 'AWC Logo Cap'); GO -- Join query SELECT OD.* FROM Sales.SalesOrderDetail AS OD INNER JOIN Production.Product AS P ON OD.ProductID = P.ProductID WHERE P.Name = 'AWC Logo Cap'; GO |
Listing 12: Two different but similar SELECT queries
In Listing 12 there are two different SELECT statements. The first SELECT statement uses a subquery to identify which Sales.SalesOrderDetail records to return. The second SELECT query returns uses a JOIN to identify the same set of Sales.SalesOrderDetail records. Both queries are equivalent. Meaning they have the same execution plan and return the same set of records.
Figure 1 show the actual execution plan for the first query, the SELECT statement with the subquery. Whereas Figure 2 shows the execution plan for the SELECT statement that uses the JOIN logic.

Figure 1: Actual execution plan for SELECT statement that contains the subquery

Figure 2: Actual execution plan for the SELECT statement
By reviewing both execution plans you can see that other than the text of the query, the plans are both exactly the same. It should be noted that as your queries grow more and more complex there is a breaking point where it is too costly to find the perfect plan.
Performance Issues when using correlated subqueries
When using a correlated subquery you need to worry about the number of rows in the outer query. When the outer query contains a small number of rows a correlated subquery doesn’t perform too bad. But as volume of rows in the outer query gets larger you will find a correlated subquery start to have performance issues.
This is because the inner query (correlated subquery) has to be evaluated for every row in the outer query. Keep this scale issue in mind when you are testing out correlated subqueries. Make sure you test your code against production size tables prior to promoting a code with a correlated subquery to into your production environment.
Keep in mind that as rowcounts increase, complexity can be a concern as well. For example, you can next subqueries many levels deeps such as:
|
1 2 3 4 5 6 7 8 9 10 |
SELECT <Columns> FROM Table1 WHERE ColumnName IN (SELECT ColumnName FROM Table2 WHERE EXISTS (SELECT * FROM Table3 WHERE Name IN ( SELECT Name FROM Table4… |
This may be necessary to answer a question your users have, but at a certain point a query with too many subqueries can become complex to optimize and execute reasonably. In some cases, it may be useful to break your queries up and use temporary tables to capture rows to eliminate some subqueries.
Using a subquery in a SELECT statement
A subquery is a SELECT statement that is embedded in another SQL statement. A subquery can be a stand-alone SELECT statement (meaning it can be run independently of the outer query) or it can be a correlated SELECT statement (meaning it cannot be run independently of the outer query).
Depending on the operator in which a subquery or correlated subquery is used with, the subquery might only be allowed to return a single value or more than one value, and/or column. Subquery performance is typically the same as an equivalent query that uses a JOIN. In this article I only showed how to use subqueries in a SELECT statement. but subqueries can also be used in other statements like INSERT, UPDATE and DELETE.
Fast, reliable and consistent SQL Server development…
FAQs: How to use a subquery in a SELECT statement in SQL Server
1. What is the difference between a subquery and a correlated subquery?
A basic subquery is a standalone SELECT that can execute independently of the outer query. A correlated subquery references one or more columns from the outer query, so it executes once for each row processed by the outer statement. Correlated subqueries are more flexible but can be slower on large datasets because of the row-by-row execution pattern.
2. Can you use a subquery in a SELECT clause in SQL Server?
Yes. A scalar subquery in the SELECT clause returns a single value for each row of the outer query. For example, SELECT ProductName, (SELECT AVG(Price) FROM Products) AS AvgPrice FROM Products computes the average alongside each row. The subquery must return exactly one column and one value, or SQL Server raises an error.
3. When should you use EXISTS vs. IN with a subquery?
Use EXISTS when you only need to check whether matching rows exist – it stops processing as soon as it finds the first match, making it faster for large datasets. Use IN when the subquery returns a small, distinct set of values to compare against. EXISTS handles NULLs more predictably than IN, which can produce unexpected results when the subquery contains NULL values.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments