Repeatedly on the SQL Server forums, I see people struggling to solve common, complex business problems in T-SQL. More to the point, I see them struggling to solve them in a way that performs well and scales gracefully to large numbers of rows. My systematic approach to writing ‘difficult’ T-SQL is always the same:
- Examine the data set carefully, and note down any particular characteristics, especially appearance of
NULLvalues, use of dates, and so on. - Make sure I fully understand the expected results and validate them, manually.
- Break the problem down into a series of simple steps, write the T-SQL, view the results, adjust if necessary, and move on to the next step.
The key at each step is to understand and accept that the first, most intuitive solution is unlikely to be the fastest or most scalable. As I explained in my previous series, Writing Efficient SQL, we need to look for opportunities to use set-based techniques that will help avoid non-scalable row-by-row processing, work with the smallest data set for any expensive calculations, scan the data as few times as possible, and so on. If my solution still fails to meet my expectations for performance, I try to “pair” with a co-worker, or ask advice from a T-SQL guru in the community, to help me find a better solution.
I recently helped solve a business problem that illustrates this process, and these ideas, perfectly. Based on data from a time clock, the challenge was to calculate based on a series of entry and exit times for employees, the amount of time between each entry and exit recorded, for each person. I present first a solution that will work on SQL Server 2008 and SQL Server 2008 R2, but has to scan the data a number of times to arrive at the result. Since that solution was not acceptable, I enlisted the help of a T-SQL guru, Peter Larsson (known as “SwePeso” or “Peso” on the various community forums) who changed the approach to the problem, and found a better solution.
Finally, I’ll demonstrate how new analytic functions in SQL Server 2012, LAG and LEAD, make it possible to find a solution that performs just as well, and requires a little less lateral thinking.
Understanding the Business Requirements and Data
Listing 1 provides the code to create the StaffHours table and populate it with data that represents fairly the time clock data set with which I worked. It uses row constructors, introduced with SQL Server 2008, and so the code will not run in any earlier versions (see the code download for the 2005 version).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
--2008 & 2012 version IF EXISTS ( SELECT * FROM sys.tables WHERE name = 'StaffHours' ) DROP TABLE StaffHours; CREATE TABLE StaffHours ( StaffMember CHAR(1) , EventDate DATE , EventTime TIME , EventType VARCHAR(5) ); INSERT INTO StaffHours ( StaffMember, EventDate, EventTime, EventType ) VALUES ( 'A', '2013-01-07', '08:00', 'Enter' ), ( 'B', '2013-01-07', '08:10', 'Enter' ), ( 'A', '2013-01-07', '11:30', 'Exit' ), ( 'A', '2013-01-07', '11:35', 'Exit' ), ( 'A', '2013-01-07', '12:45', 'Enter' ), ( 'B', '2013-01-07', '16:45', 'Exit' ) ( 'A', '2013-01-07', '17:30', 'Exit' ) ( 'A', '2013-01-07', '1:00', 'Exit' ) ( 'C', '2013-01-07', '08:33', 'Enter' ), ( 'C', '2013-01-07', '17:33', 'Exit' ), ( 'C', '2013-01-07', '17:35', 'Exit' ); |
Listing 1: Creating and Populating the StaffHours table
Figure 1 shows the “time clock” data set, essentially a series of entry and exit times from each member of staff.
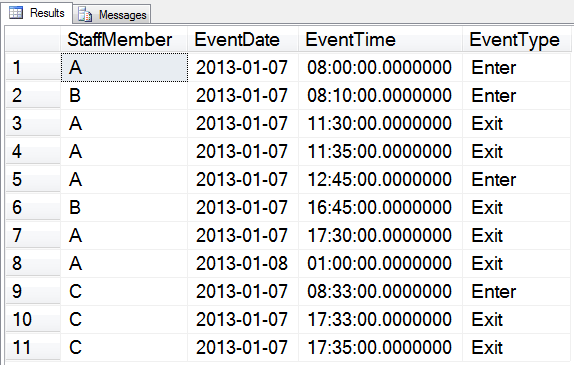
Figure 1: The original time clock data set
The requirement is to calculate the amount of time in hours, minutes and seconds between each Enter and Exit, for each staff member. The first point to note is that while there is usually a matching Exit row for each Enter, sometimes there is an Enter with no Exit or an Exit with no Enter. Here are the business rules:
- If there are consecutive Enter rows, use the first one.
- If there are consecutive Exit rows, use the last one.
- Ignore any Exit rows with no matching Enter row (i.e. if the first row for an employee is an Exit, then ignore it).
- Ignore any Enter rows with no matching Exit row (i.e. if the last row for an employee is an Enter, then ignore it).
- The Exit for an Enter could be a subsequent day.
We can validate our expected results, manually. Employee A starts a work session at 08:00 on Jan 7. There follows two Exit times and, according to our business rules, we use the last one (11:35), for a work session duration of 3 hours 35 minutes. Employee A enters again at 12:45 on the same day and again we have two Exit entries, the latter falling on the next day, to give 12:15:00 duration. In a similar fashion, we can hand-calculate the full result set, as shown in Figure 2.
|
StaffMember |
EnterDateTime |
ExitDateTime |
WorkTime |
|
A |
2013-01-07 08:00:00 |
2013-01-07 11:35:00
|
03:35:00 |
|
A |
2013-01-07 12:45:00 |
2013-01-08 01:00:00 |
12:15:00 |
|
B |
2013-01-07 08:10:00 |
2013-01-07 16:45:00 |
08:35:00 |
|
C |
2013-01-07 08:33:00 |
2013-01-07 17:35:00 |
09:02:00 |
Figure 2: Expected results
A Pre-SQL Server 2012 Solution: pairing events using row numbers
Listing 2 shows my first solution, which uses row numbersand self-joins on matching rows, based on the row numbers. It takes a very systematic approach, using five levels of CTEs, as follows:
Level1– partition the data byStaffMemberand applyROW_NUMBERLevel2– perform two self-joins to find, for each row, the value of theEventTypefor the previous and then the subsequent rows, in each partitionLevel3– filter out unneeded rows and reapply row numbersLevel4– perform another self-join to pair upENTERandEXITrowsLevel5– useDATEDIFFto calculate work session durations for each employee
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 |
--SET STATISTICS IO ON;; WITH Level1 AS (-- apply row numbers SELECT StaffMember , CAST(EventDate AS DATETIME) + CAST(EventTime AS DATETIME) AS EventDateTime , EventType , ROW_NUMBER() OVER ( PARTITION BY StaffMember ORDER BY EventDate, EventTime ) AS RowNum FROM StaffHours ), LEVEL2 AS (-- find the last and next event type for each row SELECT A.StaffMember , A.EventDateTime , A.EventType , COALESCE(LastVal.EventType, 'N/A') AS LastEvent , COALESCE(NextVal.EventType, 'N/A') AS NextEvent FROM Level1 A LEFT JOIN Level1 LastVal ON A.StaffMember = LastVal.StaffMember AND A.RowNum - 1 = LastVal.RowNum LEFT JOIN Level1 NextVal ON A.StaffMember = NextVal.StaffMember AND A.RowNum + 1 = NextVal.RowNum ), Level3 AS (-- reapply row numbers to row-eliminated set SELECT StaffMember , EventDateTime , EventType , LastEvent , NextEvent , ROW_NUMBER() OVER ( PARTITION BY StaffMember ORDER BY EventDateTime ) AS RowNBr FROM Level2 WHERE NOT ( EventType = 'Enter' AND LastEvent = 'Enter' ) AND NOT ( EventType = 'Exit' AND NextEvent = 'Exit' ) AND NOT ( EventType = 'Enter' AND NextEvent = 'N/A' ) AND NOT ( EventType = 'Exit' AND LastEvent = 'N/A' ) ), Level4 AS (-- pair enter and exit rows. SELECT A.StaffMember , A.EventDateTime , B.EventDateTime AS ExitDateTime FROM Level3 A JOIN Level3 B ON A.StaffMember = B.StaffMember AND A.RowNBr + 1 = B.RowNBr WHERE A.EventType = 'Enter' AND B.EventType = 'Exit' ), LEVEL5 AS (--Calculate the work session duration SELECT StaffMember , DATEDIFF(second, EventDateTime, ExitDateTime) AS Seconds , EventDateTime , ExitDateTime FROM Level4 ) SELECT StaffMember , EventDateTime , ExitDateTime , seconds , RIGHT('0' + CAST(Seconds / 3600 AS VARCHAR(2)), 2) + ':' + RIGHT('0' + CAST(Seconds % 3600 / 60 AS VARCHAR(2)), 2) + ':' + RIGHT('0' + CAST(Seconds % 3600 % 60 AS VARCHAR(2)), 2) AS WorkTime FROM Level5; |
Listing 2: Calculating work session duration using row numbers, CTEs and self-joins
I spent quite a bit of time working on this query, taking it a step at a time, checking the results and moving on to the next level. However, as soon as I saw the STATISTICS IO information, I knew there was a problem.
|
1 2 3 |
(4 row(s) affected) ... Table 'StaffHours'. Scan count 6, logical reads 6, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. |
The query scanned the table six times! Of course, with a small amount of data, this was not a problem, but the solution will never scale. Figure 3 visualizes the problem
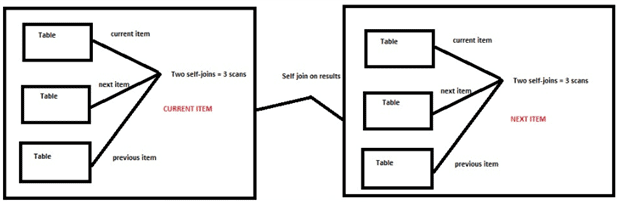
Figure 3: Why we need six scans to arrive at the result
While my solution is intuitive, I’d fallen into the trap of thinking about what I needed to do with each row, instead of considering what I could do by looking at the data as a set. This skill does not come easily to most of us, especially those with a background in programming that teaches an iterative approach.
A Better Pre-SQL Server 2012 Approach: Islands and Gaps
When I wrote a series of articles on the SQL Server Speed Phreak competitions (see https://www.simple-talk.com/author/kathi-kellenberger/), I discussed the compromise between solutions that were simple to understand, and “fast enough”, and the absolute fastest solutions possible. I spent time trying to explain how the latter worked, for the benefit of those with only medium-sized SQL brains.
On several occasions, when dissecting the fastest solution, the author was Peter Larsson. I turned to him for help on this problem, and he devised a very elegant solution that returns the answer in just one table scan instead of six. However, even Peter didn’t conjure his best solution straight off the bat. His first attempt, show in in Listing 3, reduces the scan count from six to three.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
; WITH cteSource ( StaffMember, EventDateTime, EventType, rn ) AS ( SELECT StaffMember , CAST(EventDate AS DATETIME) + CAST(EventTime AS DATETIME) AS EventDateTime , EventType , ROW_NUMBER() OVER ( PARTITION BY StaffMember ORDER BY EventDate, EventTime ) AS rn FROM dbo.StaffHours ), cteGrouped ( StaffMember, EventDateTime, grp ) AS ( SELECT c.StaffMember , c.EventDateTime , ROW_NUMBER() OVER ( PARTITION BY c.StaffMember ORDER BY c.EventDateTime ) - 1 AS grp FROM cteSource AS c LEFT JOIN cteSource AS p ON p.StaffMember = c.StaffMember AND p.rn = c.rn - 1 LEFT JOIN cteSource AS n ON n.StaffMember = c.StaffMember AND n.rn = c.rn + 1 WHERE ( COALESCE(p.EventType, 'Exit') = 'Exit' AND c.EventType = 'Enter' ) OR ( c.EventType = 'Exit' AND COALESCE(n.EventType, 'Enter') = 'Enter' ) ) SELECT StaffMember , MIN(EventDateTime) AS EventDateTime , MAX(EventDateTime) AS ExitDateTime , DATEDIFF(SECOND, MIN(EventDateTime), MAX(EventDateTime)) AS Seconds , CONVERT(CHAR(8), DATEADD(SECOND, DATEDIFF(SECOND, MIN(EventDateTime), MAX(EventDateTime)), '00:00:00'), 8) AS WorkTime FROM cteGrouped GROUP BY StaffMember , grp / 2 HAVING COUNT(*) = 2; |
Listing 3: Peter’s First Solution Eliminates One Self-Join
Peter’s initial solution contains the two self-joins to determine the previous and next event types just as my solution does, but he manages to eliminate the final self-join (level 4 in my solution), and with it half the scans.
He achieved this by creating groups of rows representing each Enter and Exit pair, using row numbers generated in the cteGrouped level. At this level, he also used a simplified WHERE clause to eliminate most of the invalid rows, keeping every Enter row that had a previous Exit row and every Exit row with a subsequent Enter row. Figure 4 shows how the data looks at the cteGrouped stage.
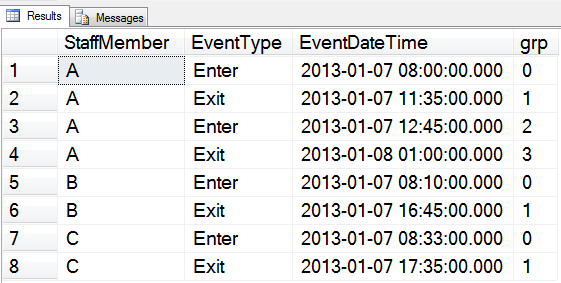
Figure 4: The values from cteGrouped
Notice that the value of grp for all of the remaining Enter rows are even, and the remaining Exit rows are odd. Integer division throws away remainders, so when the grp values are divided by two we end up with group 0 for the first enter/exit pair, group 1 for the second enter/exit pair and so on. This observation is important because it means we can now find each enter/exit pair using that grouping, in the final step. Use of Having COUNT(*) = 2 ensures that we are working with pairs of rows and not any orphaned Exit events at the beginning, or Enter events at the end.
The other point to remember, at this stage, is that the Enter date and time is the MINIMUM for the group, and the Exit date and time is the MAXIMUM for the group. Peter takes advantage of this in the final step to match up the Enter and Exit times without doing another self-join. Remember that the final self-join, if performed, doubles the work with six scans of the data.
In the final step, the query performs the grouping as well as the calculations. Peter uses an interesting technique to do the calculation.
|
1 2 3 4 5 |
... CONVERT(CHAR(8), DATEADD(SECOND, DATEDIFF(SECOND, MIN(EventDateTime), MAX(EventDateTime)), '00:00:00'), 8) AS WorkTime ... |
The DATEDIFF calculates the seconds between the MIN(EventDateTime), or ENTER time, and the MAX(EventDateTime), or Exit. He then adds those seconds back to time zero (00:00:00). He uses the style 8 (hh:mm:ss) to format the value returned. Often, people use the CAST function in preference to the CONVERT function, but the benefit of the latter is that you can specify a style that formats the date.
However, not happy with three scans of the table, Peter tried again to improve the performance and arrived at a masterful “Islands and Gaps” solution that eliminated the initial self-joins, thus reducing the table scans to just one!
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
; WITH cteIslands ( StaffMember, EventType, EventDateTime, grp ) AS ( SELECT StaffMember , EventType , CAST(EventDate AS DATETIME) + CAST(EventTime AS DATETIME) AS EventDateTime , ROW_NUMBER() OVER ( ORDER BY StaffMember, EventDate, EventTime ) - ROW_NUMBER() OVER ( ORDER BY EventType, StaffMember, EventDate, EventTime ) AS grp FROM dbo.StaffHours ), cteGrouped ( StaffMember, EventType, EventDateTime ) AS ( SELECT StaffMember , MIN(EventType) , CASE WHEN MIN(EventType) = 'Enter' THEN MIN(EventDateTime) ELSE MAX(EventDateTime) END AS EventDateTime FROM cteIslands GROUP BY StaffMember , grp ), cteResult ( StaffMember, EventType, EventDateTime, grp ) AS ( SELECT StaffMember , EventType , EventDateTime , ROW_NUMBER() OVER ( PARTITION BY StaffMember ORDER BY EventDateTime ) - 1 AS grp FROM cteGrouped ) SELECT StaffMember , MIN(EventDateTime) AS EventDateTime , MAX(EventDateTime) AS ExitDateTime , DATEDIFF(SECOND, MIN(EventDateTime), MAX(EventDateTime)) AS Seconds , CONVERT(CHAR(8), DATEADD(SECOND, DATEDIFF(SECOND, MIN(EventDateTime), MAX(EventDateTime)), '00:00:00'), 8) AS WorkTime FROM cteResult GROUP BY StaffMember , ( grp - CASE WHEN EventType = 'Exit' AND Grp = 0 THEN NULL ELSE 0 END ) / 2 HAVING COUNT(*) = 2 |
Listing 4: The Islands and Gaps Pre-2012 Solution
The first CTE, cteIslands, applies row numbers to the data sorted in two different ways and subtracts the two values. In order to see what is going on more easily, let’s extract and execute the query from cteIslands and look at the results it returns.
|
1 2 3 4 5 6 7 8 |
SELECT StaffMember , EventType , CAST(EventDate AS DATETIME) + CAST(EventTime AS DATETIME) AS EventDateTime , ROW_NUMBER() OVER ( ORDER BY StaffMember, EventDate, EventTime ) AS ByTime , ROW_NUMBER() OVER ( ORDER BY EventType, StaffMember, EventDate, EventTime ) AS ByType , ROW_NUMBER() OVER ( ORDER BY StaffMember, EventDate, EventTime ) - ROW_NUMBER() OVER ( ORDER BY EventType, StaffMember, EventDate, EventTime) AS grp FROM dbo.StaffHours; |
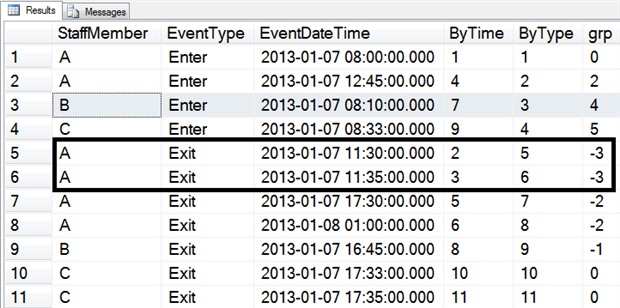
Listing 5: Viewing the Islands
Listing 5 applies the ByTime row numbers in order of StaffMember, and then EventDateTime. It applies the ByType row numbers in order of EventType, StaffMember and then EventDateTime. If an Exit event follows another Exit event, they will end up in the same GRP (ByTime - ByType). The same goes for Enter events.
If the data were perfect, an Exit event would follow every Enter event. If that had been the case, all the ByTime values would have odd numbers for the Enter rows, and even numbers for the Exit rows and so the difference between the ByTime and ByType values would have increased by one for each Enter row, and increased by one for each Exit row, thus giving us no duplicate GRP numbers. Figure 6 shows how the results of Listing 5 would look assuming ideal data.
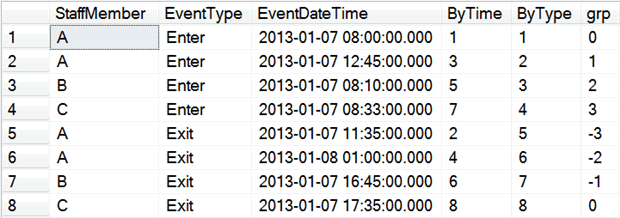
Figure 6: Results of Listing 5, if the data were perfect
In our imperfect data, because two adjacent Exit events will increase both ByTime and ByType by one (Figure 5), the difference between ByTime and ByType for the two rows are equivalent, and those two adjacent rows become a group (an “island”). This enables us to use MIN for Enter rows and MAX for Exit rows to find the valid row for each GRP.
The remainder of this solution uses the same techniques as Listing 3 to pair Enter and Exit rows, and to calculate the difference in time.
Note that Peter submitted a further iteration to his solution, which uses the same basic algorithm but with refinements, including small bug fixes for two edge conditions. It is available as part of the code download at the bottom of the article.
SQL Server 2012-only Solution: New Analytic Functions
While this solution performs far better than my original attempt and will perform well on all SQL Server versions, up to and including SQL Server 2012, a solution that is easier to develop, and has equal performance, takes advantage of some new functions available in SQL Server 2012.
SQL Server 2012 brings us several new functions, three of which will be very helpful here: LAG, LEAD, and TIMEFROMPARTS. LAG and LEAD are two new analytic window functions. TIMEFROMPARTS is one of several new functions used to build a particular date and time with the parts.
In our previous solution, we created partition “windows” based on StaffMember, and used the ROW_NUMBER function to number sequentially each row in each partition (Listing 2). However, we then had to perform two extra table scans to get the event type values for the previous and next rows. The new LAG and LEAD functions allow us to retrieve these event type values from each “window” without needing to apply row numbers first. The LAG function returns the previous value from a particular column without rescanning the table. With LEAD, we can find the next value. Instead of rescanning, SQL Server performs the operation on data already in memory. This means fewer scans of the data and fewer logical reads.
The LAG and LEAD functions each accept three parameters. The first parameter specifies the column for the value we wish to retrieve. The second parameter is optional and is the number of rows to go back or forward with the default of one. The third parameter, also optional, defines a default value in case a NULL is returned.
Listing 6 shows the code using these functions to return the previous and next values of the event type. Notice that we also return N/A instead of NULL and so render redundant the COALESCE logic we previously added for this task.
|
1 2 3 4 5 6 7 |
SELECT StaffMember , EventType , CAST(EventDate AS DATETIME) + CAST(EventTime AS DATETIME) AS EventDateTime , LAG(EventType, 1, 'N/A') OVER ( PARTITION BY StaffMember ORDER BY EventDate, EventTime ) AS LastEvent , LEAD(EventType, 1, 'N/A') OVER ( PARTITION BY StaffMember ORDER BY EventDate, EventTime ) AS NextEvent FROM StaffHours; GO |
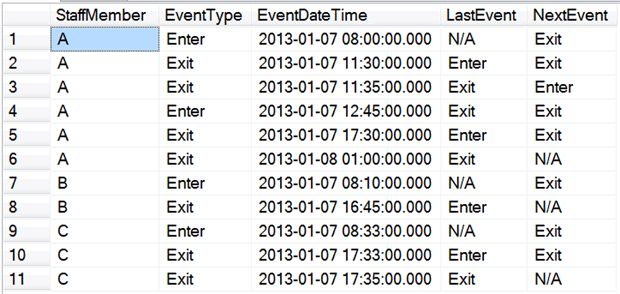
Listing 6: Using LAG and LEAD to find the previous and next event type values
Critically, we’ve achieved this with only one scan of the table, instead of three. The next step is to filter out the unneeded rows. SQL Server processes the WHERE clause before the LAG and LEAD functions are processed, so we’ll have to use the CTE strategy again. Listing 7 shows the query for this step.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
; WITH Level1 AS ( -- Use LAG and LEAD to find the previous and next event type -- values (Listing 6) ) SELECT StaffMember , EventType , EventDateTime , LastEvent , NextEvent FROM Level1 WHERE NOT ( EventType = 'Enter' AND LastEvent = 'Enter' ) AND NOT ( EventType = 'Exit' AND NextEvent = 'Exit' ) AND NOT ( EventType = 'Enter' AND NextEvent = 'N/A' ) AND NOT ( EventType = 'Exit' AND LastEvent = 'N/A' ); GO |
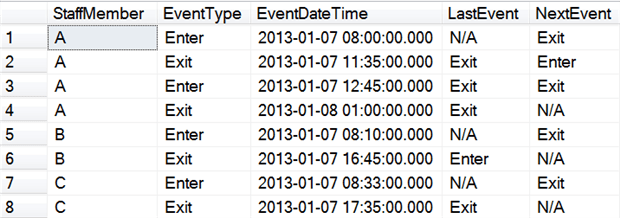
Listing 7: Filter out unneeded rows
Crucially, we are still at one table scan. We now have the rows we need, but we can’t do the time calculations because the EventDateTime values are on different rows. We can use the LEAD function again to access the EventDateTime value on the next row. Because we can nest functions, we can use the results of the LEAD function inside the DATEDIFF function to calculate seconds. Listing 8 shows the additional code for this step.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
; WITH Level1 AS ( -- Using LAG and LEAD to find the previous and next event type -- values (Listing 6) ), Level2 AS ( -- Filter out unneeded rows (Listing 7) ) SELECT StaffMember , EventType , EventDateTime , DATEDIFF(second, EventDateTime, LEAD(EventDateTime) OVER ( PARTITION BY StaffMember ORDER BY EventDateTime )) AS Seconds FROM Level2; GO |
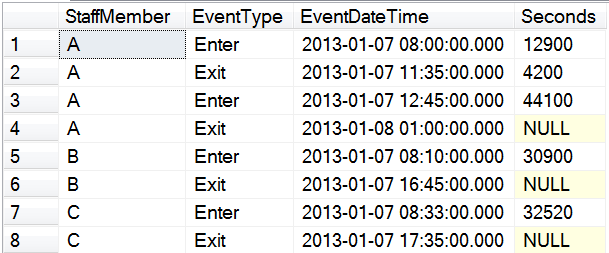
Listing 8: Calculate work session duration in seconds
The final step is to turn Seconds into hours, minutes, and seconds. We can use the new TIMEFROMPARTS functions to simplify the formula. Each date or time data type in SQL Server 2012 has a corresponding *FROMPARTS function. These allow us to build a date from its component parts. There is no casting or appending. Finally, we filter to return just the Enter rows. Listing 9 shows the final 2012-only code.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 |
; WITH Level1 AS ( SELECT StaffMember , EventType , CAST(EventDate AS DATETIME) + CAST(EventTime AS DATETIME) AS EventDateTime , LAG(EventType, 1, 'N/A') OVER ( PARTITION BY StaffMember ORDER BY EventDAGate, EventTime ) AS LastEvent , LEAD(EventType, 1, 'N/A') OVER ( PARTITION BY StaffMember ORDER BY EventDate, EventTime ) AS NextEvent FROM StaffHours ), Level2 AS ( SELECT StaffMember , EventType , EventDateTime , LastEvent , NextEvent FROM Level1 WHERE NOT ( EventType = 'Enter' AND LastEvent = 'Enter' ) AND NOT ( EventType = 'Exit' AND NextEvent = 'Exit' ) AND NOT ( EventType = 'Enter' AND NextEvent = 'N/A' ) AND NOT ( EventType = 'Exit' AND LastEvent = 'N/A' ) ), Level3 AS ( SELECT StaffMember , EventType , EventDateTime , DATEDIFF(second, EventDateTime, LEAD(EventDateTime) OVER ( PARTITION BY StaffMember ORDER BY EventDateTime )) AS Seconds FROM Level2 ) SELECT StaffMember , EventDateTime , TIMEFROMPARTS(Seconds / 3600, Seconds % 3600 / 60, Seconds % 3600 % 60, 0, 0) AS WorkTime FROM Level3 WHERE EventType = 'Enter'; |

Listing 9: The final SQL 2012-only code
Here are the results, just as expected. Thanks to the new functions in SQL Server 2012, the query is simpler and easier to write and is much more efficient, scanning the data just one time. If you are working with SQL Server 2012, keep the new functions in mind to help you solve those tricky queries. If you’re interested in seeing Peter’s SQL 2012-only solution, which is similar to mine but with some refinements, it’s available in the code download file.
Summary
Writing T-SQL queries to solve complex problems is often difficult. Frequently, I will assist others, either on forums or by direct request, in solving those problems. My methodology involves breaking the problem down and solving it systematically. At each step, I examine the results, adjust if necessary, and move on to the next step. I don’t expect to get the right answer right off the bat; writing a complex query takes time. I hope that the individual asking for help will not just take the answer, but will learn something and be better able to handle the next challenging query that comes along. The same applies to me, of course. Peter managed to find a more efficient pre-2012 solution and I can take what I learned from that and apply to future problems.
Luckily for SQL Server developers, T-SQL functionality has improved immensely starting with the introduction of the ranking functions and the OVER clause in 2005, and continuing with the introduction of very useful analytic functions, such as LAG and LEAD, in SQL Server 2012. If you haven’t kept up with these improvements, you owe it to yourself to spend some time learning about them. I found that once I started working with such functions, and Common Table Expressions, I relied on them more and more.
In particular, if you are fortunate enough to run SQL Server 2012, be sure to learn about the new analytic and other functions. The improved performance in many queries may be the tipping point to get your organization to upgrade!
Load comments