
Recently someone posted a question where they couldn’t quite figure out how to construct a predicate based on a bit parameter. They tried to write a procedure like this, which wouldn’t parse, of course:
|
1 2 3 4 5 6 7 8 9 10 11 |
CREATE PROCEDURE dbo.whatever @flag bit = 0 AS SELECT * FROM dbo.tablename WHERE IF @flag = 1 flag_column = 1 IF @flag <> 1 flag_column = 0; |
I explained that you can’t have control-of-flow inside a SQL statement like that, at least not in T-SQL. And that the way you should do it is as follows, if the table is sensible and the bit column doesn’t allow NULL:
|
1 2 3 4 |
... FROM dbo.tablename WHERE flag_column = @flag; |
And then – because the user didn’t include the table definition – I added that if the column does allow NULL, one way would be:
|
1 2 3 4 |
... FROM dbo.tablename WHERE COALESCE(flag_column, 0) = @flag; |
Someone immediately mentioned that the latter option was not sargable. Yes, that’s absolutely true. For bit columns, I generally assume there isn’t an index. But on the other hand, I have always been an advocate for writing queries as if a supporting index were there; even though it might not exist yet, someone could create it tomorrow.
An example
Let’s consider a table like this, with 10 rows where flag_column = 1, 85 rows where it is 0, and 5 rows where it is NULL:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
CREATE TABLE dbo.tablename ( id int IDENTITY, flag_column bit, filler char(4000) NOT NULL DEFAULT '', CONSTRAINT PK_tn PRIMARY KEY(id) ); INSERT dbo.tablename(flag_column) SELECT TOP (10) 1 FROM sys.all_columns UNION ALL SELECT TOP (85) 0 FROM sys.all_columns UNION ALL SELECT TOP (5) NULL FROM sys.all_columns; |
The plan for the query with COALESCE looks like this (@flag = 0 on the left, @flag = 1 on the right):

In the unlikely event you have an index that leads on flag_column:
|
1 2 3 |
CREATE INDEX IX_flag ON dbo.tablename(flag_column); |
The optimizer might still ignore the index and still use a clustered index scan, depending on what parameter value was passed in on first compile. So, it may be beneficial to write the query this way (assuming that NULL and 0 are equivalent):
|
1 2 3 4 5 6 |
... FROM dbo.tablename WHERE flag_column = @flag OR (@flag = 0 AND flag_column IS NULL) OPTION (RECOMPILE); |
Now, not everyone likes query hints, but in this case we get a much more favorable plan – however, only for the @flag = 1 case. With @flag = 0, we still get a clustered index scan:
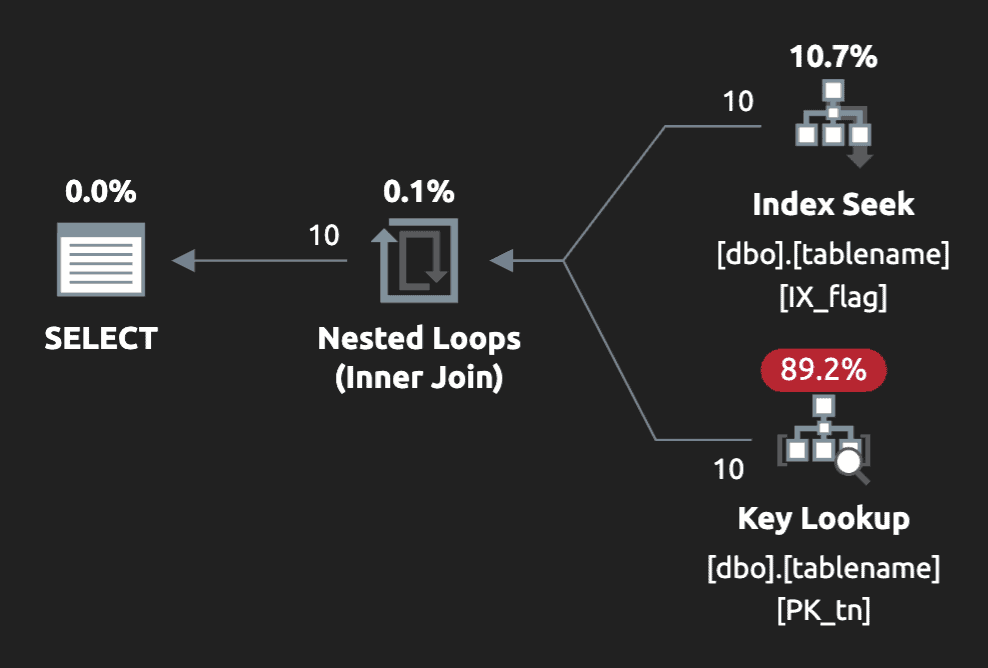
And depending on several other factors, this plan would only be chosen when scanning the narrow index and looking up the additional data nets less work than just scanning the whole table.
And again, even if that index doesn’t exist yet, having the query formulated as if it were there, since it can do no worse than the COALESCE approach, is safer and more forward-compatible.
So then I started thinking…
This sent me in a spiral thinking about how we rarely create indexes where the key leads with a bit column, and why that is.
Let’s recap: sargability is only a concern in this case if there is a valid index to use (and one that has a chance at covering the rest of the query) and that the index is useful enough to be considered even for a scan, never mind a seek, depending on how much of the table matches the (probably sniffed and cached) parameter value and how well the index covers the query. Given SELECT *, not very likely, unless this was a very narrow table.
Rarely is a bit column a good candidate for a leading index key because the selectivity just isn’t there. If SQL Server is going to have to scan an estimated 50% of the index anyway, and then perform lookups for every row for all the non-covered columns, it’s just not going to pick the index. The exception is when the data is skewed much more heavily toward 0 or 1.
And in that case, a filtered index is potentially better. But a filtered index wouldn’t be considered using the above query because the plan generated for the parameterized query has to be able to satisfy parameter values of both 0 and 1. It’s not necessarily beneficial to create both filtered indexes, because only one of them will be desirable depending on data skew, and they won’t be useful unless you also use OPTION (RECOMPILE). I’m not afraid of that hint but, in situations like this where we want the filtered index to be chosen, but we don’t want to add query hints, we’ve resorted to interpolating the parameter value into the query text (either in the application code, or using dynamic SQL) or using branching.
…let’s try a filtered index
Let’s drop the original index, and create a new filtered index catering to the case where we know it will be most useful (@flag = 1):
|
1 2 3 4 5 6 |
DROP INDEX IX_Flag ON dbo.tablename; CREATE INDEX IX_Flag_1 ON dbo.tablename(flag_column) WHERE flag_column = 1; |
If we run the two original queries again (WHERE flag_column = @flag; and WHERE COALESCE(flag_column, 0) = @flag;), at least without OPTION (RECOMPILE), we get a clustered index scan; neither query considers the filtered index. To do that without the query hint, you’d need to build the query text without parameters in the application, or use one of the following constructs inside the procedure:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
IF @flag = 1 BEGIN SELECT * FROM dbo.tablename WHERE flag_column = 1; END ELSE BEGIN SELECT * FROM dbo.tablename WHERE flag_column = 0 OR flag_column IS NULL; END /* or - sql injection jokes aside please */ DECLARE @sql nvarchar(max) = N'SELECT * FROM dbo.tablename WHERE flag_column = ' + CASE @flag WHEN 1 THEN N'1;' ELSE N'0 OR flag_column IS NULL;' END; EXEC sys.sp_executesql @sql; |
For the @flag = 0 case, we still get a clustered index scan, as expected. For the @flag = 1 case, we get a slightly more pleasing seek on the filtered index, accompanied by a key lookup to get the remainder of the data:

(The warning on the left is a misguided missing index recommendation for a non-filtered index; on the right, we have a benign unmatched index warning, which you can read more about here.)
But I don’t like key lookups, either…
That key lookup will be less and less attractive to the optimizer the more the table grows and the wider that lookup becomes. At a certain point, SQL Server will deem it too expensive, and go back to a scan. If we want to try to eliminate the lookup, we can stop using SELECT * and only select covered columns, or we can re-create the index with the additional column(s) in the INCLUDE:
|
1 2 3 4 5 6 |
CREATE INDEX IX_Flag_1 ON dbo.tablename(flag_column) INCLUDE(filler) WHERE flag_column = 1 WITH (DROP_EXISTING = ON); |
Now the execution plan for the @flag = 1 case looks like this (still with the benign unmatched index warning):
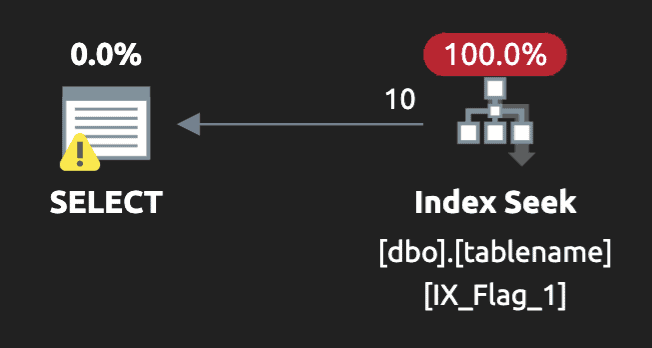
Final thoughts
None of these approaches is wrong; index tuning is always a balance of art and science and often involves subjective trade-offs. This just highlights that we need to be careful about using bit columns that are going to be involved in a significant portion of our workload, particularly if the distribution is not even.
For bit columns specifically, think about whether the column should allow NULL, and why. The query above would be a lot simpler to optimize if it could only be 0 or 1.
You should also consider that in cases where you use a filtered index but the key involves other columns, you can really help the optimizer out by adding the filtering column(s) to the end of the key list (this is mentioned in the documentation). Without it, it can be harder to use tricks to persuade the optimizer to choose your filtered index, something I’ll address in a future post.
Oh, and we never use SELECT * in production code, right?
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved





Load comments