
The problem
The Cloud, and Azure in particular, has opened up a wide range of possibilities for application developers because it is now so easy to have SQL Server on the internet. For example, they can now get databases up and running in Azure and have requests either coming from inside Azure, another cloud provider or on the customer’s site.
Good old TDS is still used to connect to Sql Azure over the internet, but TDS is now in a very different world to the one it was designed for. This can cause problems. Connections can be slow to create, they can be insecure, and they can break. To explain more about these problems, and how to avoid them with connection pooling, it is important to understand what is involved in using TDS over the internet.
A little on TCP and the internet
The latency on a LAN is small; so small, in fact, that ping on Windows does not even bother telling you how much time it took to send a packet and get a response back, because it is typically less than a millisecond. Even when you are sending a few packets backwards and forwards, the cost of the network transport is generally hidden. if is it noticeable on a LAN, then there is something seriously wrong.
Connection Latency
The latency further afield over a WAN or the Internet is, slow; very slow. The problem with going across the internet is that unless you are using dedicated lines with a high quality of service, the latency is variable and, the further you go, the more variability you get. It isn’t just distance but the time of day too: services such as netflix and iplayer use a lot of additional bandwidth at particular times of day. All these factors will lead to internet users experiencing a slower, more variable and less reliable TCP connection than on a LAN.
A networked connection to Microsoft Sql Server from a .Net application involves a TCP connection, a TDS connection over the TCP connection and a set of objects in Sql Server and .Net such as a SqlConnection and everything that this requires. The connection can be used to send queries and receive the response to those queries from a Microsoft Sql Server database.
Without any connection pooling, when Open is called, there is quite a lot of things to do and a number of interactions between the client and server.
First a TCP connection is created to the server and this involves:
- The client taking the name of the server in the connection string or alias and getting the IP address some how (dns lookup, netbios lookup etc).
- The client sends a TCP packet with the SYN flag set to 1 to the servers IP address.
- The server responds to the TCP SYN with its own SYN and an acknowledgement that it received the client’s SYN.
-
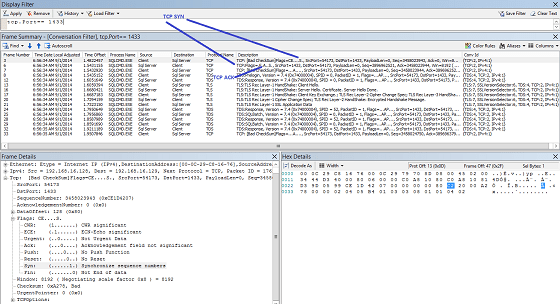 The packets involved in setting up a TCP connection.
The packets involved in setting up a TCP connection. - The client then in the background responds that it has received the server’s SYN, while it is doing that it tells the calling application that the connection is ready.
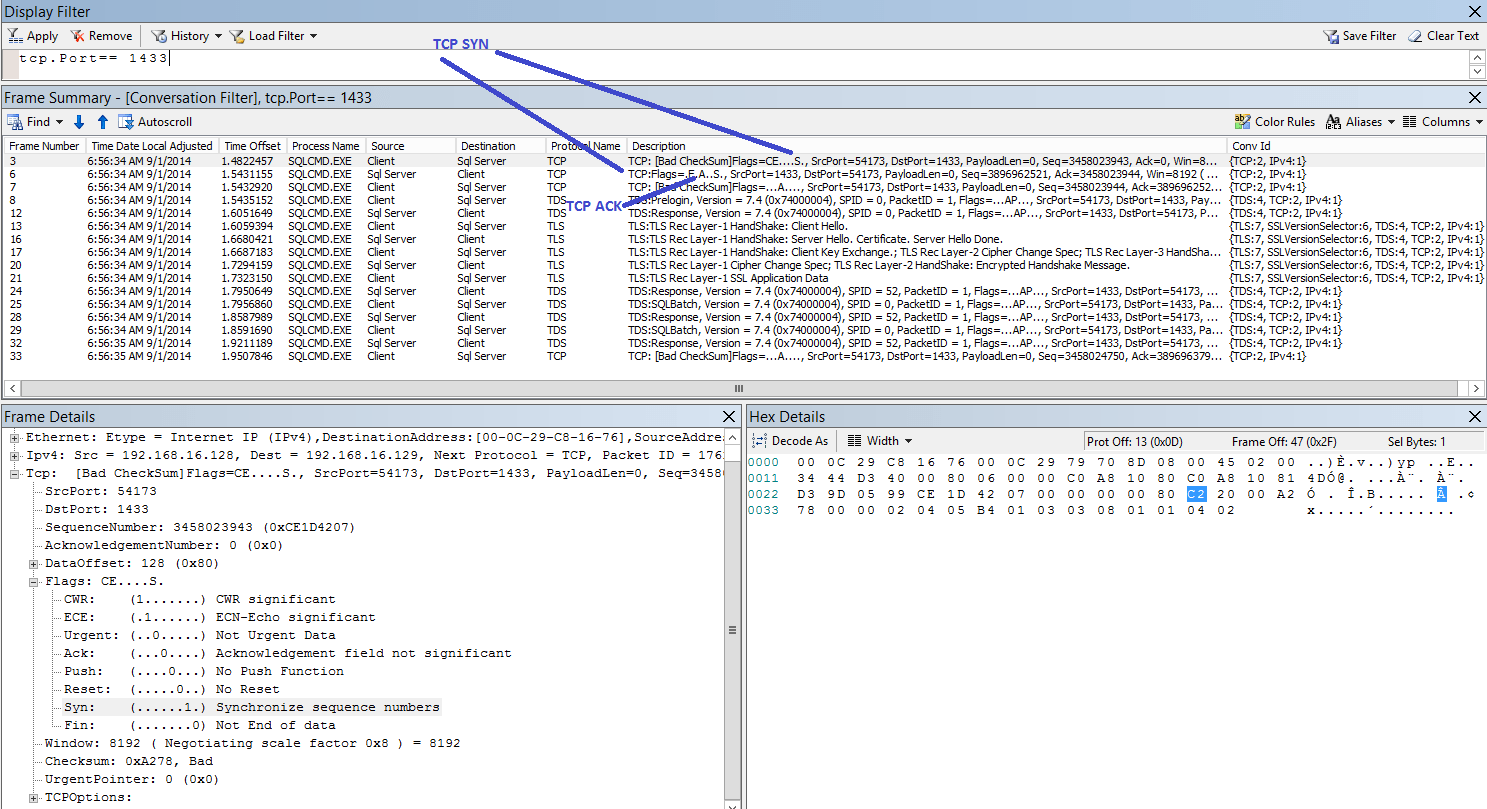
Secondly the client then sets up a TDS connection which involves (deep breath):
The client sends the server a pre-login packet:
- The pre-login packet enables the client and server to establish and share some information such as whether MARS will be used and if the connection will be encrypted. The pre-login packet also carries out a TLS exchange and then any encrypted payload that is required to logon. The TLS exchange happens both for encrypted and unencrypted connections as unless the client has explicitly disabled encryption the login information is encrypted.
- Once the pre-login packets and responses have given the client enough data to actually logon to the server it sends a TLS encrypted LOGIN7 packet and then a number SSPI messages if windows authentication is being used. The number of SSPI messages you get depends on the SSPI implementation, NTLM uses a challenge response model so you will a few packets going back and forth.
- When the server is happy you are who you say you are and you are allowed access to the server, you get a standard TDS response with, at a minimum, the Login Acknowledgement token which confirms that you are logged in. You are now ready to send your actual request.
On my test virtual machine, connecting locally the whole process takes around 40 milliseconds which is pretty fast, but because each TDS packet requires the last one before it can be generated and sent, any latency you add will increase this by the amount of latency multiplied by the number of packets so if we add 10 ms latency the connection suddenly takes around 400 milliseconds. To put this into a meaningful context, the latency between my machine in London to the Azure data centre in Amsterdam is about 30 milliseconds and a login takes 16 TCP packets in each direction, excluding TCP ACK’s which can be sent in the background so 16 * 30 = 480 ms so about a third of a second just to transfer the data required to create the connection. This is pretty slow and very noticeable when connection pooling has been disabled and there are a lot of connections, especially using the standard c# pattern of open, use and then close.
To put this into pictures, this is a netmon trace taken with a network profile of 2mb/s (in this example, as there is nothing else running other than a single SQL connection this limit will never be reached) 30 milliseconds latency with a 0% error rate:
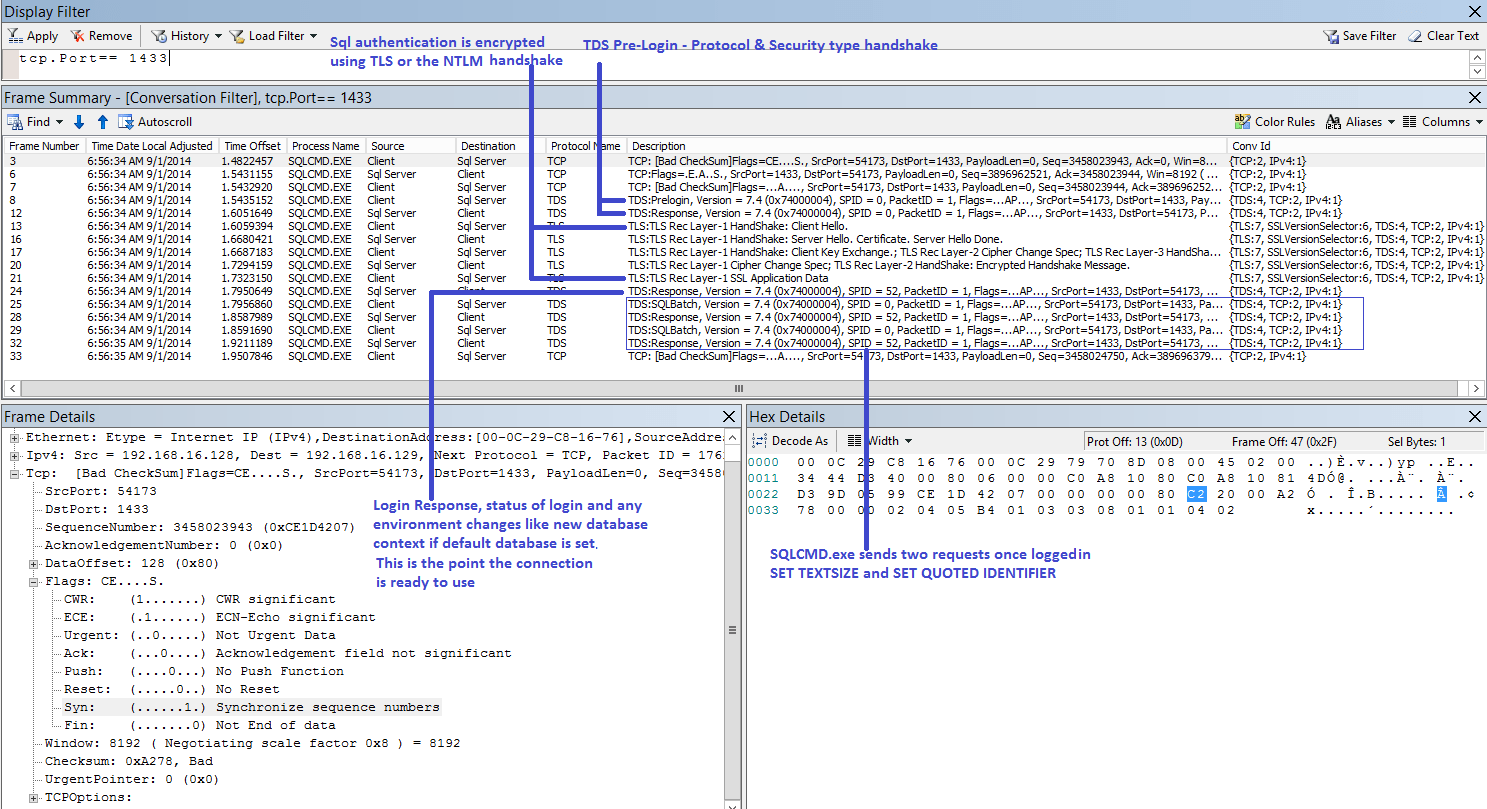
The sharp-eyed amongst you will see that the time offsets between sending and receiving a response are not 30 milliseconds, sometimes they are very small and sometimes over 60 milliseconds. This is because I am taking the network trace on the client so the responses to the server include the latency in both directions and the server processing time. The last packet arrives at the server 60 milliseconds after the last packet is sent in this trace. If I had taken the trace from the server, the first packet would have been sent 30 milliseconds before the trace began.
Connection pooling
A connection pool aims to pre-create connections so that when one is requested, it has already gone through the process of creating a connection. It is a time saver and in the .Net System.Data.SqlClient both free, simple and helpful.
What is a pool?
A pool is a group of connections that are created and re-used, because there is a much higher overhead associated with creating a new connection compared to re-using an existing one, it is much more effective to have a set of connections ready to use and re-use.
The typical pattern for using System.Data.SqlClient is:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
using(var con = new SqlConnection(_connectionString) { con.Open(); //<<---- At this point create a TCP connection and then use that to make a TDS connection using(var cmd = con.CreateCommand()) { cmd.CommandText = "stored_procedure_call"; cmd.CommandType = CommandType.StoredProcedure; using(var reader = cmd.ExecuteReader()) { while(sdr.Read()) { //do something here } } } } |
Ok, I want one, how do I get one?
In .Net you don’t need to do anything, when you call .Open, the call makes its way to DbConnectionInternal (thanks Roslyn) which gets the connection from the pool if it can.
What happens is that every time you pass in a new connection string to SqlConnection or you use a different windows identity you get a whole new pool and you take the first connection out of it, rather than you having to create a pool and a connection separately and then having to add your connection to the pool. Keep this in mind for later on as although the process of using a connection pool is really simple, it can cause an abundance of connection pools in certain scenarios which can be bad.
Ok then how do I stop using the pool if I don’t want one?
The simplest way is to add “Pooling=false” to the connection string, although I have seen (ahem, implemented, ahem) other more exotic ways such as passing in a unique connection string to each call to new SqlConnection by using something like using a guid as the app name.
Isn’t re-using connections a bad idea?
If you implemented your own connection pool and just ran queries one after the other, you would need to ensure you cleared everything up – including transactions and locks which have been left open after queries have finished. This might seem like a simple thing to do but if you consider that it is possible for queries to end in all manner of interesting states such as with transactions open and save points active either because of some poor code or an unexpected error, it is not straight forward.
To simulate the behaviour of getting a clean connection in the same known state as when you create a new connection, TDS and Sql Server include the ability to reset the state of a connection to that of an, almost, new connection.
The way this functionality works is that TDS has a standard header across all packets that looks something like:
- Type – 1 byte
- Status – 1 byte
- Length – 2 bytes
- Spid – 2 bytes
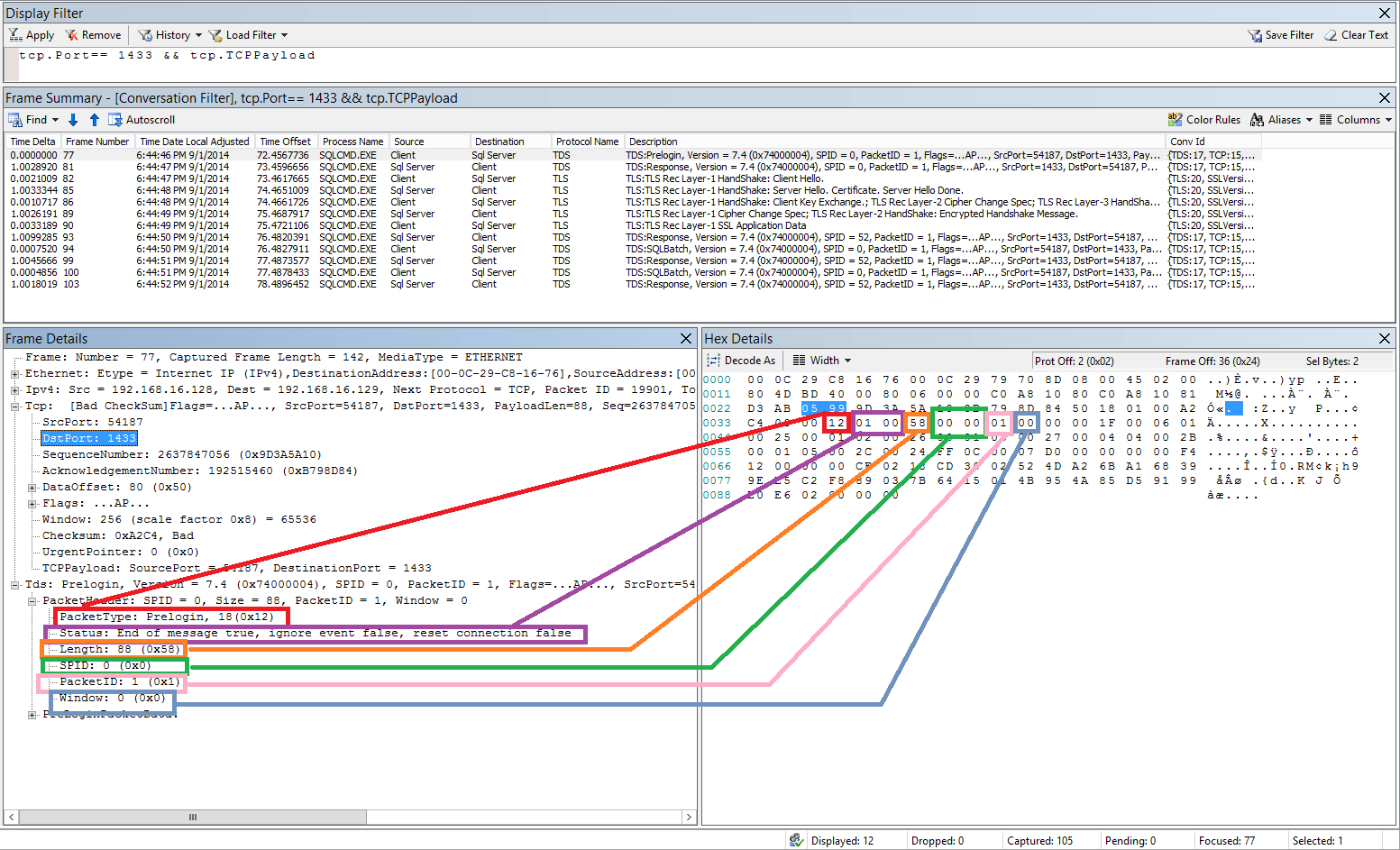
For specific packet types, SqlBatch, RPC and DTC transactions you can set the status to include the bit 0x08 RESETCONNECTION or 0x10 RESETCONNECTIONSKIPTRAN.
The RESETCONNECTION bit clears up the connection as per the [MS-TDS] open protocol specification:
“This signals the server to clean up the environment state of the connection back to the default environment setting, effectively simulating a logout and a subsequent login, and provides server support for connection pooling.”
When you run profiler, what you see is a call to sp_reset_connection and a logout and login event.
The RESETCONNECTIONSKIPTRAN pretty much does what it says, it resets the state but leaves transactions. This strikes me as being a dangerous thing to do. Looking at the reference source, it is possible to get this by using System.Transactions transactions, either implicit transactions using TransactionScope or explicit transactions and by calling EnlistTransaction on the SqlConnection. Personally, if I needed to use a distributed transaction with multiple calls to the same server, I would tend to take a connection from a pool and hand it back once I have finished and closed the connection but it is certainly important to be aware that if you use these type of transactions then the behaviour of the connection pool changes.
So that is what sp_reset_connection is?
Yes, pre Sql Server 2000 / TDS 7.1 sp_reset_connection was an actual stored procedure that was executed; but from Sql Server 2000 onwards it has been a part of the TDS protocol and the stored procedure doesn’t actually exist.
Does sp_reset_connection simulate a completely new connection?
No. Everything is reset except for the transaction isolation level which could potentially lead to issues. To avoid any issues, the general recommendation is to always include the required transaction isolation level in the stored procedure call. If you are not using stored procedures then a) why? b) seriously why? and c) you really should.
This behaviour of not resetting the transaction isolation level is not specifically documented in the TDS specification or books online, however there is a connect item which discusses it:
Pool fragmentation
There are potential problems with connection pooling. One of these is pool fragmentation. This is when you end up creating lots and lots of connection pools because you have a large number of connection strings or use different windows identities to create SqlConnections.
The connection string has to be entirely unique so changing anything at all will create a new pool.
This is typically an issue in web sites that use windows authentication to impersonate the end users. If this is the case then the only recommendation from Microsoft is to disable pooling. To be fair to Microsoft, if you do have a web site impersonating end users, the web servers and Sql servers are probably within the same domain and unlikely to have a high amount of uncontrollable latency between them so a decision of whether to use better security over slightly slower performance is a trade-off that can be made on an application-by-application basis.
How do I know if I have pool fragmentation?
The easiest way is to check the performance monitor counters:
- “.Net CLR Data\SqlClient: Current # connection pools”
- “.Net CLR Data\SqlClient: Current # pooled and nonpooled connections”
- “.Net CLR Data\SqlClient: Current # pooled connections”
Just the first counter, “Current # connection pools” tells you whether you have 1 or a lot. Then the other two counters give you some further information on whether you are using connection pooling for all of your SqlConnections.
TCP connections can and do end even when the client doesn’t ask them to end
A TCP connection basically goes like this:
- Hi someone else, are you in room 1433? You are, good well I am in room 58987 let’s connect? or, I want to connect to port 1433, my port is 58987, here is my synchronization number
- Hi, yes I am in room 1433, you phoned me so you must know that. Anyway, you are in room 58987, great I would love to talk or, I have a socket listening on 1433 and can send back to 58987 and here is my synchronization number
- Great, here have some data, have some more data, have some more
- Cool, here I acknowledge that data and here, have some of my own
This carries on until the connection is closed either nicely or abruptly:
The nice way is that one application at either end says to the other end that they want to close and so they send a TCP FIN and stops sending in their direction after sending the FIN. When you receive a FIN you know you aren’t going to get any more data from the client so normally you would send any data you have ready to send and then close the connection. If you receive a FIN and don’t then send a FIN of your own to close the channel in both directions it is like hosting a party and your guests wanting to leave but you keep them there by holding their hand and shaking it as they are walking backwards out of the door.
Eventually you must close your end of the channel because the other end holds a trump card and can use the abrupt method of ending a connection. At any time anyone involved in the connection can send a reset or TCP RST, this is where the connection is closed, all data in any buffers is discarded and everyone leaves with a feeling of being slightly short changed.
There is also another option, it is possible for the route between the two hosts to disappear or for a router to stop routing and stop forwarding packets so you keep on sending data but it never gets there. This can happen in both directions and I get the image in my head of a prison where a visitor can’t speak to a prisoner because of a sheet of glass and they must use a phone but in this case the phone isn’t plugged in – I am not sure if this is worrying or not, I don’t think so.
TCP connections don’t just go from one machine magically to another, they move over other devices. On a LAN this may be a switch or two but over the internet this will likely involve quite a few different pieces of equipment owned by many different people and any of the them can decide to FIN, Reset or just plain drop your TCP packets, however mean it might be – just get used to it.
What happens when the connection is killed and why are you telling us about this?
It helps to explain an issue with connection pooling, it is important!
If you receive a FIN or a RST then the machine knows that the connection has ended, if the client has posted any Receives, i.e. they have said to Windows, I am waiting for some data then windows can alert those people that the connection is down.
If the connection has died because a router has decided that it no longer wants to forward your packets and no other routers like you either then there is no way to know this unless you try to send some data and don’t get a response.
If you create a connection and a connection pool is created and connections are put into the pool and not used, the longer they are in there, the bigger the chance of something bad happening to it.
When you go to use a connection there is nothing to warn you that a router has stopped forwarding your packets until you go to use it; so until you use it, you do not know that there is a problem.
This was an issue with connection pooling that was fixed in the first .Net 4 reliability update (see issue 14 which vaguely describes this) with a feature called “Connection Pool Resiliency”. The update meant that when a connection is about to be taken from the pool, it is checked for TCP validity and only returned if it is in a good state.
Idle connection resiliency
If the connection is in the pool, this takes care of making sure that the clients get a valid connection; but if the connection is out of the pool then the TCP connection can still go down because those pesky routers between you and your destination really don’t care what you are doing or not doing.
To help cases where the connection is torn down when the connection is being used, Sql Server 2014 and Sql Azure include a feature called connection resiliency. This feature gives the client the opportunity to re-connect to an existing session in certain circumstances. What happens is that the clients asks to use session recovery by asking really nicely with a FEATUREEXTACK_TOKEN with a FeatureId of 1, the server then responds with a series of SESSIONRECOVERY tokens which tell the client whether the connection is currently recoverable or not. If the connection is killed and it had previously been in a recoverable state, it is recovered for the user without you having to do anything.
The white-paper that describes the resiliency is a great read and I recommend it highly. The authors include a slightly more lively perspective on how useful it is, based on a user hibernating their laptop or going into a lift and losing their WIFI signal and then re-connecting seamlessly.
To be clear, this is a very good thing and a major step forward for using Sql / TDS connections over a network that is less reliable than a LAN, and to help support the way people use their computing devices today.
When can a connection be recovered?
First of all the connection needs to be idle to be recoverable. If you are in the middle of a request then it cannot be recovered. Even if the connection is idle, certain states stop the connection being recoverable, the states are generally things that take resources on the server and could block other users. These states mean that no recovery is possible because they were cleared up when the connection died in order that a broken session doesn’t affect other users.
The white-paper lists some common causes of the connection being non-recoverable but it may not be an exhaustive list:
- Temporary tables
- Cursors (why are you using these anyway?)
- Open transaction
- Application locks
- Execute As / Revert
- sp_OACreate handles
- Orphan LOB handles
- sp_xml_preparedocument handles
What happens if a connection can’t be recovered?
If the connection can’t be recovered then you will get an exception, if you are using SqlConnections over the internet then you are guaranteed to have transient connection errors and you will need to handle this in your code. The transient fault handling application block is part of the enterprise library and gives a Microsoft-supported way to handle SqlConnections over the internet and TCP. If you don’t use the Microsoft application block then implementing your own retry logic should be pretty straight-forward.
Testing connections
TCP connections over the internet are relatively slow, sometimes unreliable, and with variable bandwidth and latency. Testing Sql connections or any protocol over the internet is difficult as the variability makes it hard to get repeatable tests. If you use a LAN connection, you will not have the same issues as over the real internet. If you use the real internet, you may have a much better or much worse connection than your users. To help test in a reliable fashion there are a number of WAN emulators which let you add a specific amount of latency including a variability factor, specific error rate and bandwidth. My personal favourite is the WANatronic 10001 which is documented: WANatronic 10001: An extremely simple WAN emulator.
The WANatronic works by receiving packets and sending them back to the sender on the same port, so if you are on the machine with SQL server listening on TCP port 1433, put the IP address of the WANatronic and it should connect (check firewall and the Sql port etc if you get issues connecting).
Summary
The internet is a scary place for Sql Server TDS connections. They were designed and implemented when all connections were local and reliable, very different to what we find on the internet. By using a combination of the new features like connection pools and idle connection resiliency, Sql Server and the .Net client can really help to make applications faster and more reliable. The features are available for free, often without you having to do anything: That is a great step and so if you are disabling connection pooling then you should definitely make sure that the reasons why this was done are still valid and that they still hold. A reason of something along the lines of ‘it was causing lots of extra sp_reset_connection requests’ is about the most common of these outdated reasons that I hear.
A plea to writers of applications using Sql Connections over the internet
Sql Connections over the internet can be unreliable, so build in retry logic so that your application remains usable over the internet.
The performance of database requests is variable, in the office it might be fine, on my train journey home going through tunnels it sometimes is and sometimes isn’t. To cater for this please use the UI thread for displaying the UI and maybe a cancel button. It pays to carry out your processing in the background so that, when the internet is a little choppy, the users of your application can do something about it.
Load comments