
Executive Summary
This article describes how to set up and write programs using .NET for Apache Spark (Microsoft.Spark) – the .NET driver that allowed C# and F# developers to use Apache Spark for distributed data processing. Note: this project was archived in 2024 and the instructions below reflect its original state. Apache Spark itself remains actively maintained and widely used – this article provides conceptual background on how .NET interfaced with Spark’s JVM-based execution model, how Spark’s DataFrame API works, and what kinds of big data processing Spark is suited for. That conceptual knowledge transfers to any Spark environment.
Apache Spark is a fast, scalable data processing engine for big data analytics. In some cases, it can be 100x faster than Hadoop. Ease of use is one of the primary benefits, and Spark lets you write queries in Java, Scala, Python, R, SQL, and now .NET. The execution engine doesn’t care which language you write in, so you can use a mixture of languages or SQL to query data sets.
The goal of .NET for Apache Spark is to make Spark accessible from C# or F#. You can bring Spark functionality into your apps using the skills you already have.
The .NET implementation provides a full set of API’s that mirror the actual Spark API so that, excluding a few areas still under development, the complete set of Spark functionality is available from .NET.
Setting up Apache Spark on Windows
The .NET implementation still uses the Java VM, and so it isn’t a separate implementation of Spark that replaces Spark but sits on top of the Java runtime and interacts with it. You still need to have Java installed.
Spark is written in Scala and runs on a Java virtual machine so it can run on any platform including Windows. However, Windows does not have production support. The current version of Java that it supports is 1.8 (version 8).
Oracle has recently changed the way that they support their JDK in that you need to pay a license fee to run it in production. Oracle also released a version called OpenJDK that doesn’t have a license fee to pay when running in production. Spark can only run on Java 8 today and to run in a development environment doesn’t cost anything so you can use the Oracle JRE 8 for this article, if you will be using Spark in production then it is something you should investigate.
.NET for Apache Spark was released in April 2019 and is available as a download on NuGet, or you can build and run the source from GitHub.
Install a Java 8 Runtime
You can download the JRE from the Oracle site. You will need to create a free Oracle account to download.
I would strongly suggest getting the 64 bit JRE because the 32-bit version is going to be very limited for Spark. The specific download is jre-8u212-windows-x64.exe, although this will change when there are any more releases.
Install Java, my installation of Java was in C:\Program Files\Java\jre1.8.0_212 but take note of where your version is because you will need it later.
Download and Extract a Version of Spark
You can download Spark here. There are currently two versions of Spark that you can download, 2.3 or 2.4. The current .NET implementation supports both versions, but you do need to know which version you will be using. I would suggest downloading 2.4 at this point. The README for .NET spark shows which versions of Spark are supported, currently any 2.3.* version is supported or and of 2.4.0, 2.4.1, 2.4.3 but note that 2.4.2 is not supported so stay clear of that version.
At the time of this writing, the version of Spark supported by the current Microsoft.Spark is this version.
Once you have chosen the Spark version, you can select the package type, unless you want to compile Spark from source or use your own Hadoop implementation, then select the Pre-built for Apache Hadoop 2.7 and later and then download the tgz. Today, that is spark-2.4.3-bin-hadoop2.7.tgz.
Once it has downloaded, use 7-zip to extract the folder to a known location, c:\spark-2.4.3-bin-hadoop2.7, for example. Again, take note of where you extracted the Spark folder. My Spark folder looks like:
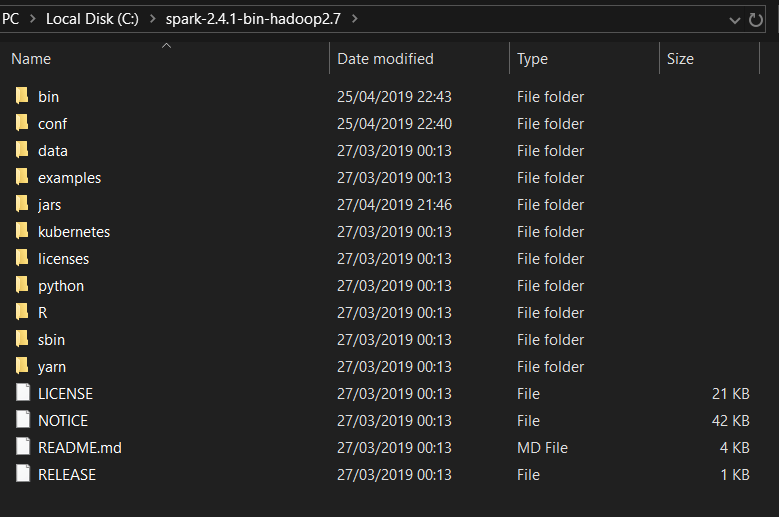
If you have something that looks like this, then you should be in good shape.
Download the Hadoop winutils.exe.
The last step is to download winutils, which is a helper for Hadoop on windows. You can download it from GitHub.
When you have downloaded winutils.exe, you need to put it in a folder called bin inside another folder. I use c:\Hadoop\bin, but as long as winutils.exe is in a folder called bin, you can put it anywhere.
Configure Environment Variables
The final step in configuring Spark is to create some environment variables. I have a script I run from a cmd prompt when I want to use them but can also set system environment variables if you wish. My script looks like this:
|
1 2 3 4 |
SET SPARK_HOME=c:\spark-2.4.1-bin-hadoop2.7 SET HADOOP_HOME=c:\Hadoop SET JAVA_HOME=C:\Program Files\Java\jre1.8.0_212 SET PATH=%SPARK_HOME%\bin;%HADOOP_HOME%\bin;%JAVA_HOME%\bin;%PATH% |
What this script does is set SPARK_HOME to the location of the extracted Spark directory, set JAVA_HOME to the location of the JRE installation, set HADOOP_HOME to the name of the folder that contains the bin directory that winutils.exe is put in. Once the environment variables have been set, I add the bin folder from each to the PATH environment variable.
Testing Apache Spark on Windows
To check everything is set up correctly, check that the JRE is available and the correct version:
In a command window, run Java -version then spark-shell. If you have set up all the environment variables correctly you should see the Spark-shell start. The Spark-shell is a repl that lets you run scala commands to use Spark. Using the repl is a great way to experiment with data as you can read, examine, and process files:
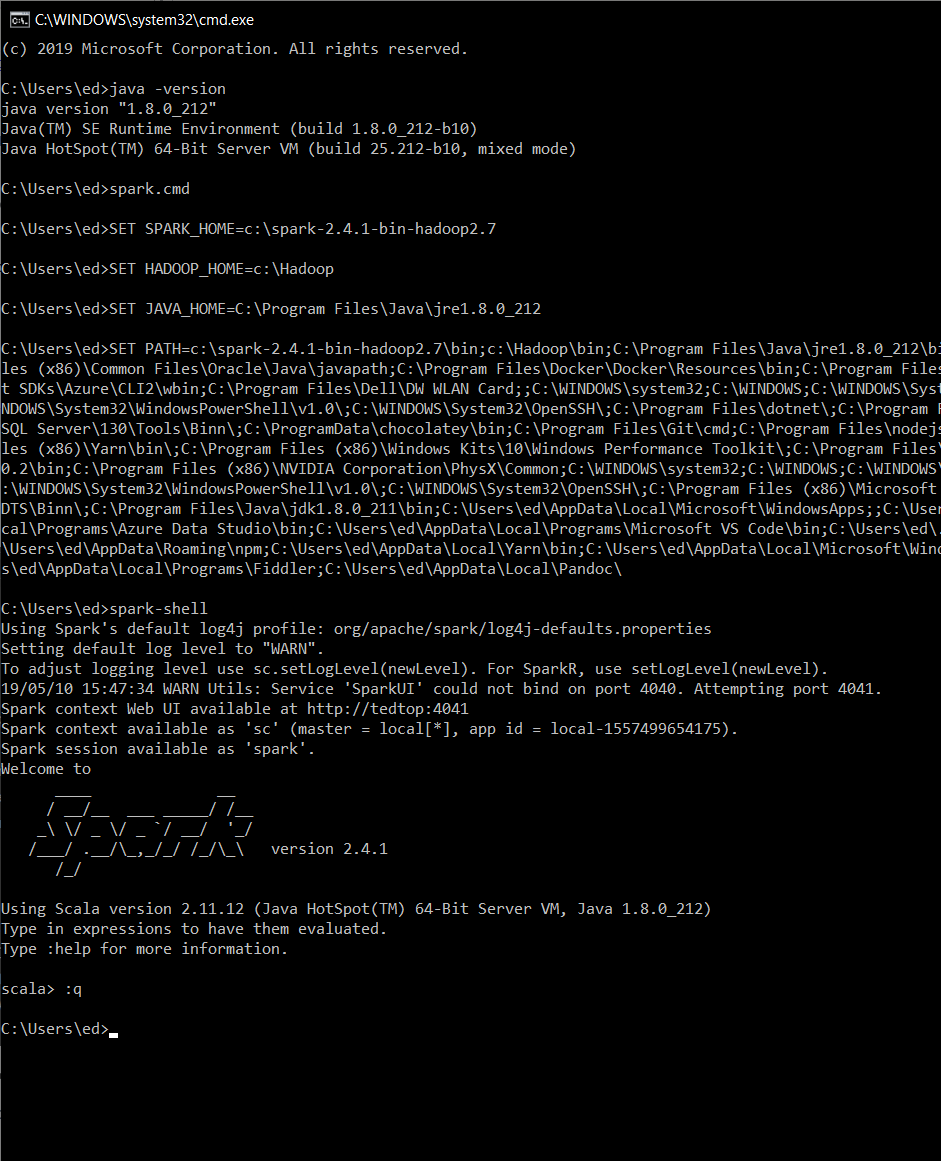
When you are ready to continue, exit Spark-shell by typing :q. You use the spark-shell to check that Spark is working. To run a job later, you use something called spark-submit.
If you can start the Spark-shell, get a prompt and the cool Spark logo, then you should be ready to write a .NET application to use Spark.
Note, you may see a warning that says
NativeCodeLoader: Unable to load native-Hadoop library for your platform… using builtin-java classes where available
It is safe to ignore this; it means that you don’t have Hadoop running on your system. If this is a Windows machine, then that is highly likely.
The .NET Driver
The .NET driver is made up of two parts, and the first part is a Java JAR file which is loaded by Spark and then runs the .NET application. The second part of the .NET driver runs in the process and acts as a proxy between the .NET code and .NET Java classes (from the JAR file) which then translate the requests into Java requests in the Java VM which hosts Spark.
The .NET driver is added to a .NET program using NuGet and ships both the .NET library as well as two Java jars. One jar is for Spark 2.3 and one for Spark 2.4, and you do need to use the correct one on your installed version of Scala.
There was a breaking change to version 0.4 of the .NET driver, so when you use the driver, if you are using version 0.4 or higher then you need to use the package name org.apache.spark.deploy.dotnet and if you are on version 0.3 or less you should use org.apache.spark.deploy, note the extra dotnet at the end.
Your First Apache Spark Program
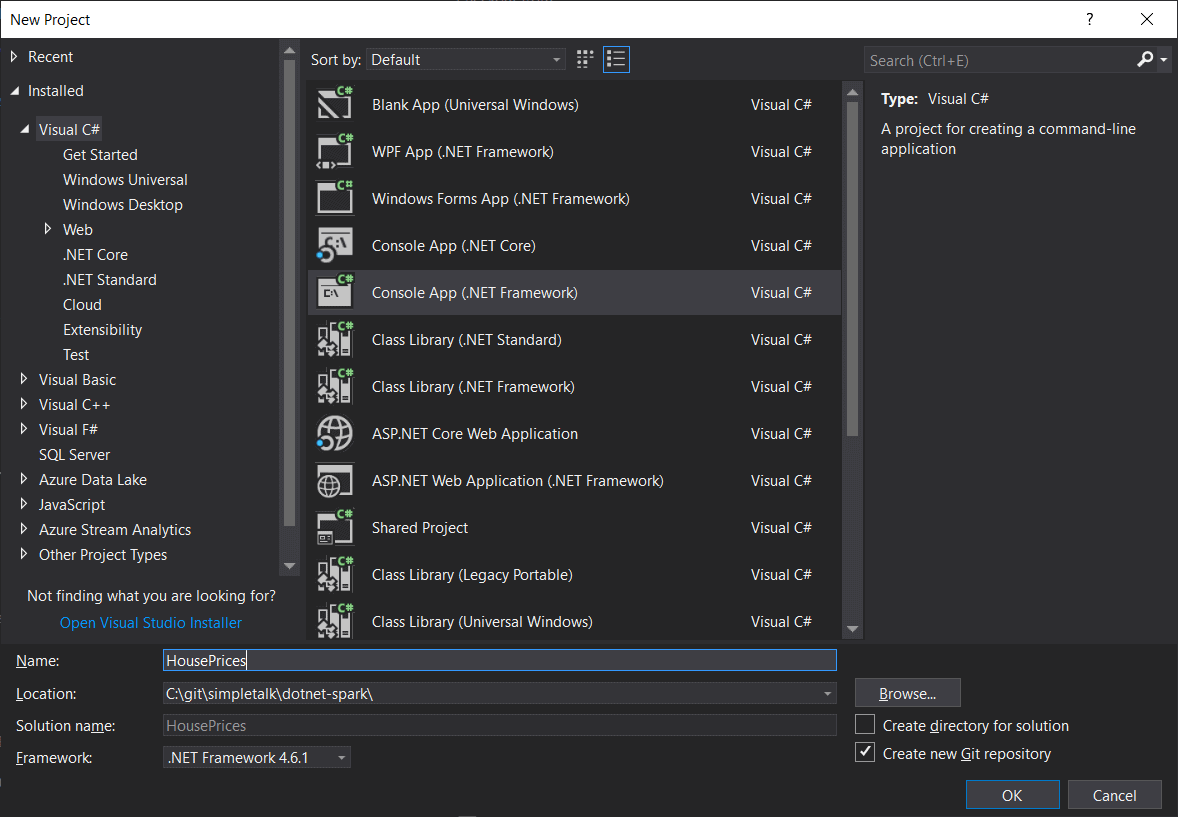
The .NET driver is compiled as .NET standard so you can use either the Windows .NET runtime or .NET core to create a Spark program. In this example, you will create a new .NET runtime (4.6) console application:
You will then add the .NET Spark driver from NuGet:
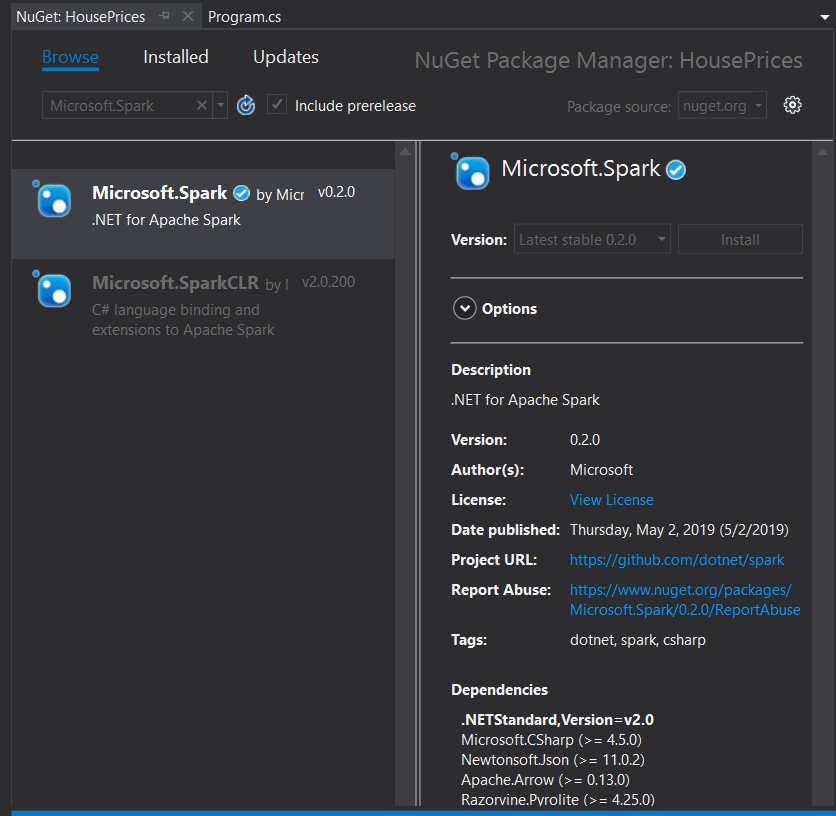
Select Microsoft.Spark. There was also an older implementation from Microsoft called Microsoft.SparkCLR but that has been superseded, so make sure you use the correct one. For this example, use Spark version 2.4.1 and the 0.2.0 NuGet package – these have been tested and work together.
When you add the NuGet package to the project, you should see in the packages folder the two Java jar’s which you will need later:
Execute Your First Program
For the first program, you will download a CSV from the UK government website which has all of the prices for houses sold in the last year. If the file URL has changed, then you can get to it from here after and searching “current month as CSV file”.
The program will read this file, sum the total cost of houses sold this month, and then display the results:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
using System; using System.Linq; using Microsoft.Spark.Sql; namespace HousePrices { class Program { static void Main(string[] args) { var Spark = SparkSession .Builder() .GetOrCreate(); var dataFrame = Spark.Read().Csv(args[0]); dataFrame.PrintSchema(); dataFrame.Show(); var sumDataFrame = dataFrame.Select(Functions.Sum(dataFrame.Col("_c1"))); var sum = sumDataFrame.Collect().FirstOrDefault().GetAs<Double>(0); Console.WriteLine($"SUM: {sum}"); } } } |
The first thing to do is to either use the sample project and build the project or create your own project and build it so you get an executable that you can call from Spark.
First, take a look at this code:
|
1 2 3 |
var Spark = SparkSession .Builder() .GetOrCreate(); |
Here you create the Spark session. The Spark session enables communication back with the .NET java code and through to Spark.
Next review:
|
1 2 3 |
var dataFrame = Spark.Read().Csv(args[0]); dataFrame.PrintSchema(); dataFrame.Show(); |
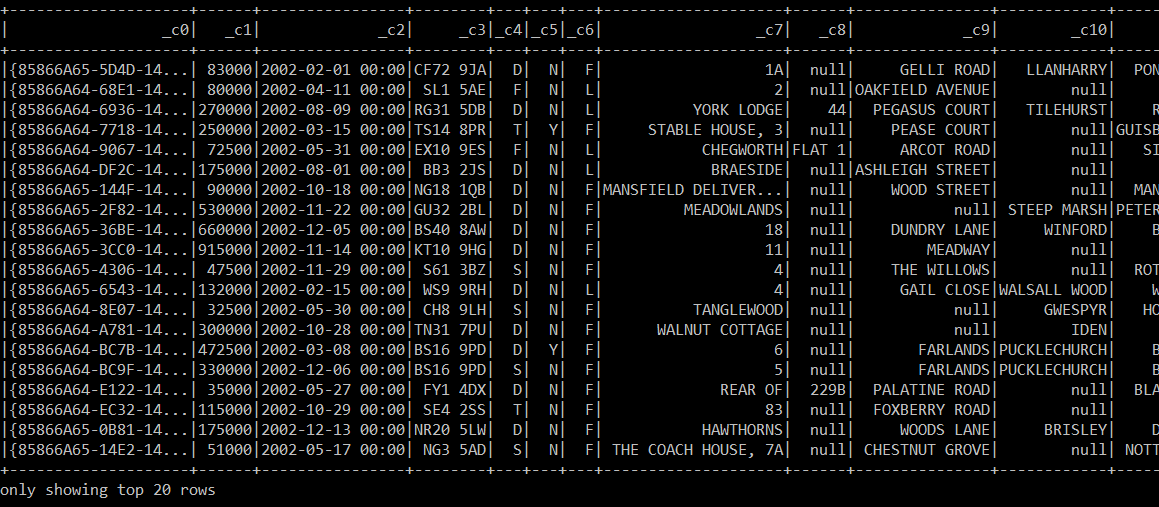
Here the Spark session created above reads from a CSV file. Pass in the path to the CSV on the command line (args[0]). (I realise that you should validate if it exists.) Once the file has been read, the code will print out the schema and show the first 20 records.
Finally look at this code::
|
1 2 3 |
var sumDataFrame = dataFrame.Select(Functions.Sum(dataFrame.Col("_c1"))); var sum = sumDataFrame.Collect().FirstOrDefault().GetAs<Double>(0); Console.WriteLine($"SUM: {sum}"); |
This will use the Sum function against the _c1 column (the price column), it will then select it into a new DataFrame (sumDataFrame) and then it iterates through the rows of the DataFrame. It selects the first row and then retrieves the value of the 0’th column and prints out the results.
To run this, instead of just pushing F5 in Visual Studio, you need to first run Spark and tell it to load the .NET driver and pass onto the .NET driver the name of the program to execute.
You will need these details to run the .NET app:
| Type | Name | Value |
| Environment Variable | JAVA_HOME | Path to JRE install such as C:\Program Files\Java\jre1.8.0_212 |
| Environment Variable | HADOOP_HOME | Path to the folder that contains a bin folder with winutils.exe inside such as c:\Hadoop |
| Environment Variable | SPARK_HOME | The folder you extracted the contents of the downloaded spark (note that the file downloaded is a tar then gzipped file, so you need to un-gzip then un-tar the file) |
| The driver package name | For 0.3 and less the driver package is org.apache.spark.deploy and for 0.4 and greater it is org.apache.spark.deploy.dotnet | |
| The full path to the built .net executable | I created my project in c:\git\simpletalk\dotnet\HousePrices so my full path is c:\git\simpletalk\dotet-spark\HousePrices\HousePrices\bin\Debug\HousePrices.exe | |
| The full path to the jars that are included in the Microsoft.Spark NuGet package | Because I created my solution in c:\git\simpletalk\dotnet, my path is C:\git\simpletalk\dotet-spark\HousePrices\packages\Microsoft.Spark.0.2.0\jars\Microsoft-spark-2.4.x-0.2.0.jar (Note it is the full path including the name of the jar, not the path to where the jars are located) If your NuGet package is version 0.0.3 or something else then the name of the jar will be more like: packages\Microsoft.Spark.0.3.0\jars\Microsoft-spark-2.4.x-0.3.0.jar – every change to the NuGet package will cause this version to change. |
|
| The full path to the downloaded house prices csv | In my example it is c:\users\ed\Downloads\pp-monthly-update-new-version.csv |
In a command prompt that has these environment variables set, run the next command. (If you still have the spark-shell session open in your command prompt, close it using :q).
|
1 |
spark-submit --class org.apache.spark.deploy.DotnetRunner --master local "C:\git\simpletalk\dotet-spark\HousePrices\packages\Microsoft.Spark.0.2.0\jars\Microsoft-spark-2.4.x-0.2.0.jar" "c:\git\simpletalk\dotet-spark\HousePrices\HousePrices\bin\Debug\HousePrices.exe" "c:\users\ed\Downloads\pp-monthly-update-new-version.csv" |
If your executable isn’t called HousePrices.exe, then replace that with the name of your program. When you build in Visual Studio, the output window should show the full path to your built executable. If you aren’t called “ed” then change the path to the CSV file, and if you decided to use Spark 2.3 rather than Spark 2.4, then change the version of the jar.
The Scala code looks in the current working directory and any child directories underneath it to find HousePrices.exe. To see how it does that, you can look at the function resolveDotnetExecutable. You can change the directory in your command prompt to your Visual Studio output directory and run it from there or be more specific in your command line.
Note also that the version of the jar increases with each version of Spark, and because the version is part of the filename, I used 0.3.0 for this article, but new versions are released quite regularly:
|
1 |
Spark-submit –class org.apache.spark.deploy.DotnetRunner --master local PathToMicrosoftSparkJar PathToYourProgram.exe PathToYourCsvFile.CSV |
If you run the command line successfully you should see:
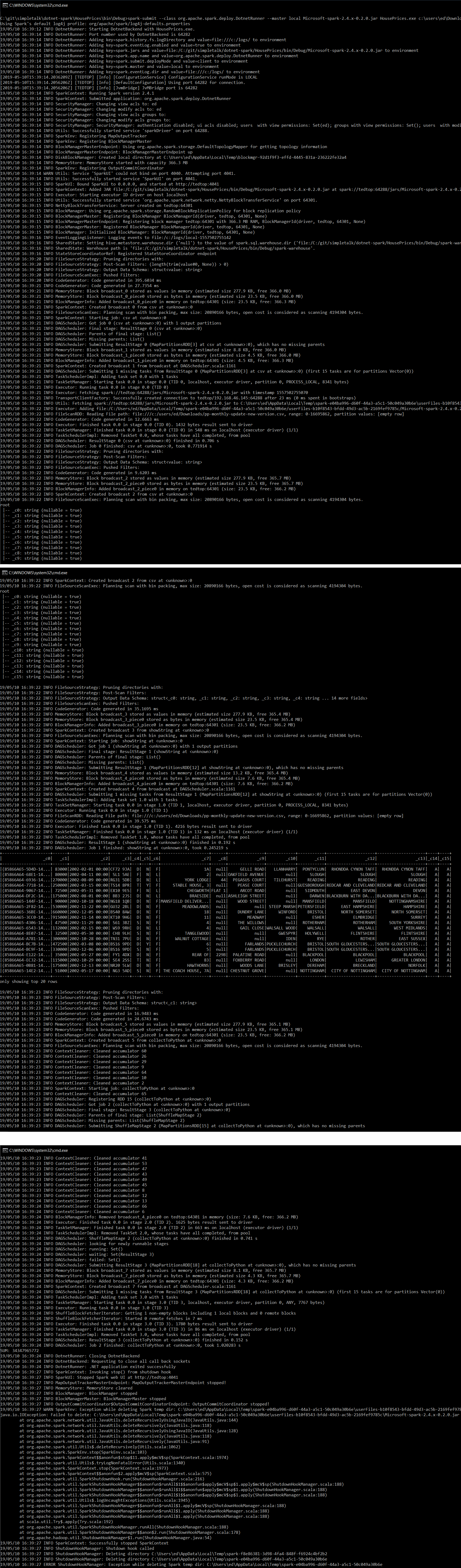
The interesting parts are the schema from dataFrame.PrintSchema():
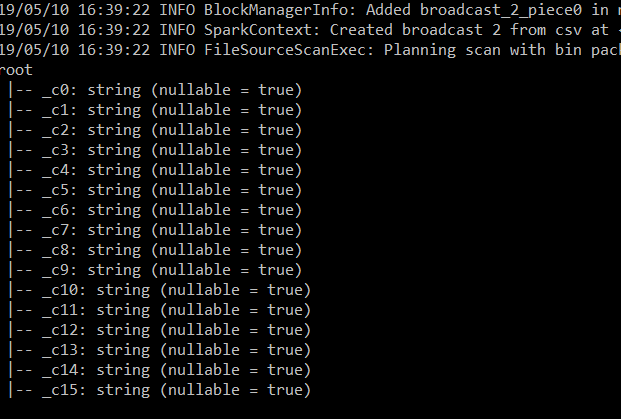
The first twenty rows from dataFrame.Show():
Finally, the results of the Sum:
![]()
You may get a lot of Java IO exceptions such as:
To stop these, in your Spark folder there is a conf directory. In the conf directory, you will have a log4j.properties file add these lines to the end of the file:
|
1 2 |
log4j.logger.org.apache.spark.util.ShutdownHookManager=OFF log4j.logger.org.apache.spark.SparkEnv=ERROR |
If you don’t have a log4j.properties you should have a log4j.properties.template, copy it to log4j.properties.
A Larger Example
The first example was very basic, and the file doesn’t contain column header, so they are set to _c0, _c1 etc. which isn’t ideal. Also, the output from PrintSchema shows that every column is a string.
The first this to do is to get Spark to infer the schema from the csv file, which you do by adding the option inferSchema when reading the csv. Change the line (line 15 in my program):
|
1 |
var dataFrame = Spark.Read().Csv(args[0]); |
into:
|
1 |
var dataFrame = Spark.Read().Option("inferSchema", true).Csv(args[0]); |
Build your .net application and re-run the spark-submit command line which now causes PrintSchema() to show the actual data types:
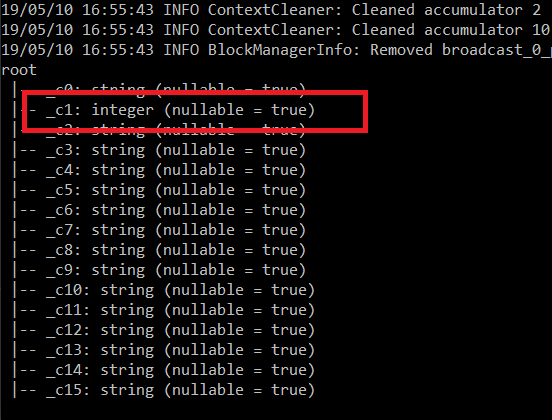
Because you now know the data types, it goes on to break the GetAs<Double>(0) with an Unhandled Exception: System.InvalidCastExceptionL Specified cast is not valid so you also need to change the GetAs<double> to GetAs<long>, from:
|
1 |
var sum = sumDataFrame.Collect().FirstOrDefault().GetAs<Double>(0); |
into:
|
1 |
var sum = sumDataFrame.Collect().FirstOrDefault().GetAs<long>(0); |
You can test that the program now completes by building in Visual Studio and re-running the spark-submit command line.
It would be good to have the correct column headers rather than _c0, to do this, read the data frame and then re-read the data frame passing in the headers – this doesn’t cause the data to be re-read or re-processed, so it is efficient. If you use this program which reads the data frame, prints the schema and then converts the data frame to a data frame with headers and re-prints the schema, you should see the original _c* column names and the corrected column names:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
using System; using System.Linq; using Microsoft.Spark.Sql; namespace HousePrices { class Program { static void Main(string[] args) { var Spark = SparkSession .Builder() .GetOrCreate(); var dataFrame = Spark.Read().Option("inferSchema", true).Csv(args[0]); dataFrame.PrintSchema(); dataFrame.Show(); dataFrame = dataFrame.ToDF("file_guid", "price", "date_str", "post_code", "property_type", "old_new", "duration", "paon", "saon", "street", "locality", "town", "district", "county", "ppd_Category_type", "record_type"); dataFrame.PrintSchema(); } } } |
Build your .net application and then re-run your spark-submit command line and you should see the correct column names:
Going further, you can use the column names to filter the data. KENSINGTON AND CHELSEA is a beautiful part of London, see how much houses in that area cost to buy:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
using System; using Microsoft.Spark.Sql; namespace HousePrices { class Program { static void Main(string[] args) { var Spark = SparkSession .Builder() .GetOrCreate(); var dataFrame = Spark.Read().Option("inferSchema", true).Csv(args[0]); dataFrame = dataFrame.ToDF("file_guid", "price", "date_str", "post_code", "property_type", "old_new", "duration", "paon", "saon", "street", "locality", "town", "district", "county", "ppd_Category_type", "record_type"); dataFrame = dataFrame.Where("district = 'KENSINGTON AND CHELSEA'"); Console.WriteLine($"There are {dataFrame.Count()} properties in KENSINGTON AND CHELSEA"); dataFrame.Show(); } } } |
Build the .net application and run the spark-submit command line and you should see something like:

In case you are struggling with the amount of output, you can hide the Info messages by going back to the log4j.properties file located in the extracted spark directory and the conf folder inside that. Change the line:
|
1 |
log4j.rootCategory=INFO, console |
into:
|
1 |
log4j.rootCategory=WARN, console |
You will see warnings and output but not all the info messages. I would say it is generally better to leave the info messages on, so you get used to what is normal and learn some of the terminology that spark uses.
This new program runs quickly, but Spark is great for processing large files. It’s time to do something a little bit more complicated. First, download the entire history of the price paid data. Download the Single File or the complete Price Paid Transaction Data as a CSV file, currently here.
You can then change the program, so instead of just filtering, it filters and then groups by year and gets a count of how many properties sold per year and the average selling price. One of the features of Spark is that you can use the methods found in Scala, Python, R, or .NET or you can write SQL.
The date must be an actual date, but even with the inferSchema option set to true, it’s still a string rather than an exact date. To correct this, add an extra column to the data set which is the date cast to an actual date:
|
1 |
dataFrame = dataFrame.WithColumn("date", dataFrame.Col("date_str").Cast("date")); |
If you build this and then run the spark-submit command line, you should see the extra column:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
using System; using Microsoft.Spark.Sql; namespace HousePrices { class Program { static void Main(string[] args) { var Spark = SparkSession .Builder() .GetOrCreate(); var dataFrame = Spark.Read().Option("inferSchema", true).Csv(args[0]); dataFrame = dataFrame.ToDF("file_guid", "price", "date_str", "post_code", "property_type", "old_new", "duration", "paon", "saon", "street", "locality", "town", "district", "county", "ppd_Category_type", "record_type"); dataFrame = dataFrame.WithColumn("date", dataFrame.Col("date_str").Cast("date")); dataFrame.Show(); } } } |
To query the data using SQL syntax rather than just using .Net methods as shown up to until now, you can save the DataFrame as a view. This makes it available to be queried:
|
1 |
dataFrame.CreateTempView("ppd"); |
You can then query the view from SQL:
|
1 |
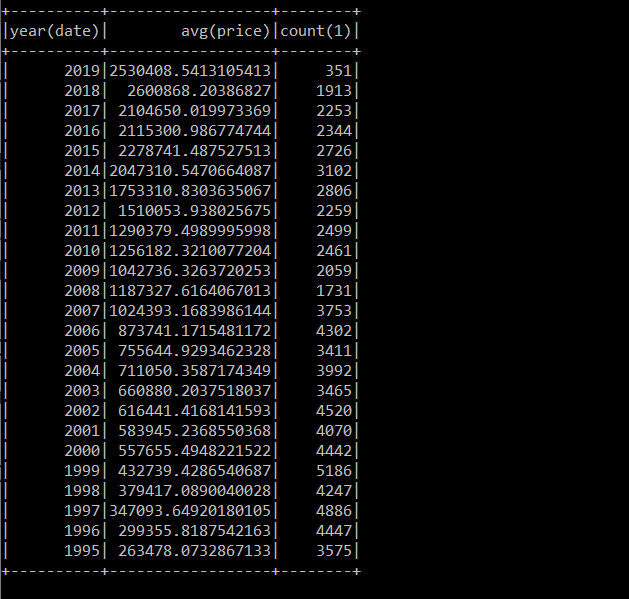
Spark.Sql("select year(date), avg(price), count(*) from ppd group by year(date)").OrderBy(Functions.Year(dataFrame.Col("date")).Desc()).Show(100); |
This runs the SQL query
|
1 |
select year(date), avg(price), count(*) from ppd group by year(date) |
It then orders the results by date descending and shows the last 100 years (the data only goes back to 1995 so you won’t see 100 years of data).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
using System; using Microsoft.Spark.Sql; namespace HousePrices { class Program { static void Main(string[] args) { var Spark = SparkSession .Builder() .GetOrCreate(); var dataFrame = Spark.Read().Option("inferSchema", true).Csv(args[0]); dataFrame = dataFrame.ToDF("file_guid", "price", "date_str", "post_code", "property_type", "old_new", "duration", "paon", "saon", "street", "locality", "town", "district", "county", "ppd_Category_type", "record_type"); dataFrame = dataFrame.WithColumn("date", dataFrame.Col("date_str").Cast("date")); dataFrame.CreateTempView("ppd"); var result = Spark.Sql("select year(date), avg(price), count(*) from ppd group by year(date)").OrderBy(Functions.Year(dataFrame.Col("date")).Desc()); result.Show(100); } } } |
You can then run this against the full dataset:
|
1 |
spark-submit --class org.apache.spark.deploy.DotnetRunner --master local[8] Microsoft-spark-2.4.x-0.2.0.jar HousePrices.exe c:\users\ed\Downloads\pp-complete.csv |
You can also change how many cores the processing takes. Instead of --master local which uses one single core by itself, use --master local[8] or whatever number of cores you have on a machine. If you have lots of cores, use them.
When I ran this on my laptop with eight cores, it took 1 minute 45 seconds to complete, and the average house price in that area is about 2.5 million pounds:
Conclusion
Using .NET for Apache Spark brings the full power of Spark to .NET developers who are more comfortable writing C# or F# than Scala, Python, R or Java. It also doesn’t matter whether you are running Linux or Windows for your development.
Source Code
I have included a working copy of the final version of the application on GitHub. In the git repo, there are .NET Framework and core versions of the solution. If you use the .NET core version, then executing the program is the same except instead of HousePrices.exe, you need to have dotnet HousePrices-core.dll before the path to the CSV file:
|
1 |
spark-submit --class org.apache.spark.deploy.DotnetRunner --master local PathTo\Microsoft-spark-2.4.x-0.2.0.jar dotnet PathTo\HousePrices-Core.dll c:\users\ed\Downloads\pp-monthly-update-new-version.csv |
References
https://github.com/dotnet/spark
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments