
Our interviewee stood at the whiteboard with his back facing us. Behind him were the indecipherable dry erase markings indicative of a problem that had spiraled far out of his control. Occasionally he had brushes of insight, but they were quickly abandoned for approaches that could only be deemed developmentally psychotic. “Maybe if I passed a delegate into the method…” he pondered aloud. It might have been amusing to see where that would have led, but he was having so much trouble trying to write a simple recursive algorithm that any thought of complicating matters by throwing delegates into the mix made me cringe. I gently advised him to avoid delegates, partly because I hoped it would steer him in the right direction, but mostly for my own sanity. I was spared a few minutes later when threw up his hands in defeat.
Recursion is a classic computer science concept that seems to throw developers off balance. On an academic level, it is a simple concept to understand. On a practical level, however, it can be difficult to put to use, especially when you are put on the spot. It takes a bit of brain power to solve a problem using recursion, and that’s why recursive programming problems make great interview questions. You can sit and watch someone work through a recursive problem and get a great deal of insight about how they think. It becomes easy to identify developers whose minds gravitate towards incoherently complex solutions. It is easy to identify people who can reason through the situation. And it’s even easier to identify someone who knows about recursion because they nail the question in under a minute.
What is an Algorithm?
An algorithm is defined as a finite series of instructions for solving a given problem. Therefore, every method that you write in your code should be an algorithm. If not, it means that you’ve successfully written an endless loop or you’ve neglected to actually solve a problem, neither of which is really productive. Take, for example, the following statement from my high school computer science teacher, about shampoo instructions:
Lather. Rinse. Repeat.
Is that an algorithm? It definitely solves a problem, especially if your problem is grimy hair. But it’s technically not an algorithm because it never ends. If you were following the instructions to the letter then you would be stuck in an infinite loop lathering and rinsing, and lathering and rinsing, and lathering and rinsing forever. Assuming, of course, that you had an infinite amount of shampoo. And you were a complete idiot. A more algorithmically correct set of instructions would be something like:
Lather. Rinse. Repeat if needed.
Now it qualifies as an algorithm because it solves a problem and provides an exit condition that makes it a finite process (thanks Mr. Doderer).
What is a Recursive Algorithm?
A recursive algorithm is a special type of algorithm in which a method calls itself over and over again to solve a problem. Each successive call reduces the complexity of the problem and moves closer and closer to a solution until finally a solution is reached, the recursion stops, and the method can exit. Recursive algorithms are fairly easy to identify, because the method name appears in the method body. Here is a quick example that demonstrates a recursive method displaying a countdown:
Listing 1
|
1 2 3 4 5 6 7 8 9 10 11 12 |
1 public void CountDown(uint number) 2 { 3 Console.WriteLine(number); 4 if(number==0) 5 { 6 return; 7 } 8 else 9 { 10 CountDown(number-1); 11 } 12 } |
The method begins by writing out the number passed into the method. Then it checks to see if the number is zero, which would denote that we have reached the end of the countdown. If so, the method exits and the countdown stops. Otherwise, the method calls itself recursively and passes in the current number minus one. As such, the countdown continues to display until it reaches zero.
Parts of a Recursive Algorithm
When you think of a recursive algorithm, it helps to think of it as having three parts: base cases, recursion, and work. Remember, recursive algorithms are about breaking complex problems down into smaller more manageable problems. As such, you can think of the base case for a recursive algorithm as the point at which the problem is solvable and need not be broken down any further, or rather a path in the algorithm that does not lead to additional recursion. Without a base case, a recursive function would have no way to exit, so it would, in theory, simply run forever. As such, recursive algorithms must have at least one base case, though they can have several base cases if needed. A base case normally consists of two parts: a condition to check if the problem is small enough to solve, and a path of execution that does not lead to additional recursion.
Recursion is pretty easy to spot in a recursive algorithm because it’s the part of the method body that contains a call to the method name. Locating the recursive portion of the method is really as simple as searching for the method name and seeing where it appears in the method body. Remember, the objective of a recursive algorithm is to break a complex problem into a smaller more manageable problem. As such, each successive recursive call should be breaking the problem down into a smaller problem in an effort to reach a solvable base case. Failing to reach a base case is just as bad as not having one in the first place, and would result in an equally endless situation.
Work is the last part of the algorithm, and consists of everything that is not recursion or a base case. If you want to get really persnickety, base cases and recursion are technically part of the “work” in a recursive algorithm, but it helps to give “the other stuff” in the algorithm a name nonetheless. Figure A visually depicts the various parts of a recursive algorithm.
Figure A
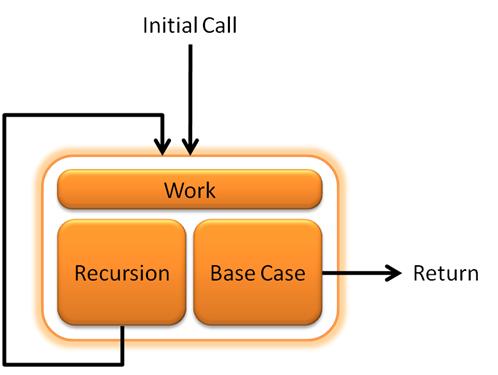
Let’s take a look back at Listing 1 and identify the various parts of the recursive algorithm. Since the method name is CountDown, and the CountDown method is called on Line 10 in the method body, we can easily identify that as the recursive part of the algorithm. When identifying the base case you have to ask, what condition allows the method to complete without any recursion? The answer to that question resides on line 4. When if(number==0) evaluates to true there is no recursion. So we say that the base case occurs when the number parameter is zero. When this condition is met, it allows the explicit return call on line 6 to execute and the method to exit without any additional recursion. The work is found on lines 3 with the Console.WriteLine statement.
Now take a look at Listing 2, which contains a modified version of the code from Listing 1
Listing 2
|
1 2 3 4 5 6 7 8 |
1 public void CountDown(uint number) 2 { 3 Console.WriteLine(number); 4 if(number>0) 5 { 6 CountDown(number-1); 7 } 8 } |
Identifying the recursion and the work in Listing 2 is still pretty easy, but the base case is a bit more difficult to nail down because it’s implicitly defined instead of explicitly defined. When if(number>0) evaluates to true, then recursion occurs. So you have to do some thinking to arrive at the fact that the base case is really the SAME as it was in Listing 1. We can still stay, the base case occurs when the number parameter is zero. Also notice that instead of executing an explicit return call, the method simply skips over the recursive section of code when the number parameter is zero, allowing the method to complete and exit without a recursive call.
Winding and Unwinding
When you deal with recursion, you may encounter the terms Winding and Unwinding. Winding is simply the work that occurs before a recursive call, and unwinding is the work that occurs after the recursive call. Take another look at the code from Listing 2. Notice that the Console.WriteLine call occurs before the recursive call. This means the number is printed, and then the recursive call occurs. As such, a call to CountDown(5) results in the following output:
5
4
3
2
1
0
Here’s a more detailed look at the chain of execution:
Listing 3
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
Call to CountDown(5) Call to Console.WriteLine(5) Base case not reached -- Call to CountDown (4) Call to Console.WriteLine(4) Base case not reached -- Call to CountDown (3) Call to Console.WriteLine(3) Base case not reached -- Call to CountDown (2) Call to Console.WriteLine(2) Base case not reached -- Call to CountDown (1) Call to Console.WriteLine(1) Base case not reached -- Call to CountDown (0) Call to Console.WriteLine(0) Base case reached (no more recursion) |
When you accomplish work before a recursive call, the work does not have to wait for the recursive call to finish before it can complete. You can, however, also complete work after the recursive call:
Listing 4
|
1 2 3 4 5 6 7 8 |
1 public void CountUp(uint number) 2 { 5 if(number>0) 6 { 7 CountUp(number-1); 8 } 9 Console.WriteLine(number); 10 } |
In this scenario, a call to CountUp(5) results in the following output:
0
1
2
3
4
5
Notice that this is output is the reverse of the previous output. Here’s a more detailed look at this chain of execution:
Listing 5
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
Call to CountUp(5) Base case not reached -- Call to CountUp(4) Base case not reached -- Call to CountUp(3) Base case not reached -- Call to CountUp(2) Base case not reached -- Call to CountUp(1) Base case not reached -- Call to CountUp(0) Base case reached (no more recursion) Call to Console.WriteLine(0) Call to Console.WriteLine(1) Call to Console.WriteLine(2) Call to Console.WriteLine(3) Call to Console.WriteLine(4) Call to Console.WriteLine(5) |
Work that occurs after a recursive call has to wait on the recursive call to finish. In turn, that recursive call may need to wait on a subsequent recursive call. And in turn, that recursive call may need to wait on a subsequent recursive call. Hopefully you can see where this is going. Basically, no work is completed until a base case is reached and the execution chain can “unwind” as recursive calls exit and allow their callers to finish executing. So remember, the location of “the work” in a recursive algorithm can affect the timing of when it is executed.
Recursive Algorithm Types
Placement of the recursive calls in a recursive algorithm determines the “type” of the recursive algorithm. Following is a brief list of the various types of recursive algorithms that you will run across:
Linear Recursion
Linear recursion is the simplest and most common form of recursion. In fact, all of the methods shown thus far are examples of linear recursion. For a recursive method to exhibit linear recursion, it must call itself, and it can only call itself recursively once per call. This results in a linear chain of calls that looks similar to the following:

Tail Recursion
Tail recursion is a special form of linear recursion. A recursive method is considered to be tail recursion if nothing has to be done after the recursive call before the method exists. Listing 2 is an example of a tail recursion- notice that after the method calls Shampoo() on line 5 nothing else occurs before the method exits. Now, you may think to yourself that an algorithm is tail recursive if the recursion appears on the last line, but remember, physical placement has nothing to do with it. If the recursion occurs, then the method exits without doing anything else, then it is tail recursive. Take the following for example:
Listing 6
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
1 public void Shampoo() 2 { 3 Lather(); 4 Rinse(); 5 if(!HairIsClean) 6 { 7 Shampoo(); 8 } 9 else 10 { 11 Say("Sweet, my hair is clean!"); 12 } 13 } |
Even though the recursive call occurs in the middle of the method, it is still tail recursive because the method exists right after the call. Another situation where people get hung up on is when the recursive call looks like it’s the last thing that happens, but isn’t:
Listing 7
|
1 2 3 4 5 |
public int Foo(int x) { ... code ... return 10 * Foo(x-1); } |
At first glance, this looks like a tail recursive function because the recursive call is the very last thing you see in code. In reality, however, the call to Foo(x-1) returns a result, and then that result is multiplied by 10. So the very last thing that actually occurs is a multiplication operation, which means that this method does NOT represent tail recursion. One of the biggest things to remember about Tail Recursion is that it can normally be solved fairly easily using an iterative approach instead of a recursive approach.
Middle Recursion
In a middle recursion scenario, there is code both before and after the recursive call. Thus, the recursion occurs in the middle of the method.
Head Recursion
In my meanderings I’ve found a limited number of references to head recursion. People say that a recursive method is head recursive when the recursive call is the first call in the method. When you stop and think about it, however, the very first call cannot really be a recursive call because there would be no way for the method to ever hit a base case. So head recursion may be referring to “middle recursion” where there really isn’t much “work” before the recursive call (only a base case check).
Binary Recursion
In binary recursion, a recursive algorithm calls itself recursively twice per call. It is a bit more complex than linear recursion because it branches out and creates various non-linear paths of execution. A recursive method employing binary recursion must wait for BOTH recusive calls to finish before it can complete. Subsequently, those recursive calls must wait for BOTH of their recursive calls to complete before they can return. So, the path of execution works its way down one branch of the tree, then back up, then back down, until all of the recusive calls that need to occur have occurred. In the diagram below, you can see an example of binary recursion. The green bubbles identify the order in which the items begin executing, and the red bubbles identify the order in which the items complete execution.
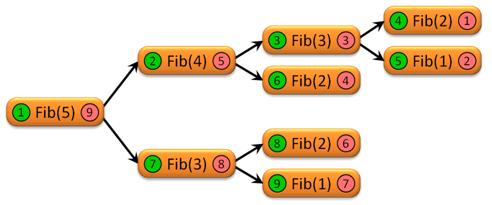
One of the interseting things about binary recursion is that some of the recursive calls complete before other recusive calls even begin. For example, the call to Fib(2) and Fib(1) that are the 4th and 5th calls to be executed (respectively) are finished executing before the call to Fib(2) which is the 6th call is ever even started. In practical terms, this means that alothough there may be a number of recusive calls that need to occur, not all of them are being actively executing at the same time.
Mutual Recursion
Mutual recursion occurs when two algorithms are defined in terms of one another. Having never seen this approach used in production system, I am lead to believe it does not occur that often in the real world. I must concede, however, that there may be some business rules or scenarios that are defined in such a manner, in which case this type of recursion may be encountered. With that in mind, only example I have ever found is a horrible implementation of Odd and Even functions. And here they are…
Listing 8
|
1 2 3 4 5 6 7 8 9 10 11 |
public bool Even (int x) { if(x==0) return true; return !Odd(x-1); } public bool Odd(int x) { if(x==0) return false; return !Even(x-1); } |
Executing a mutual recursive set of methods results in a recursive back and forth between the two methods until a solution is achieved, as shown in the image below.

Obviously, there is a far more efficient way to determine if a number is odd or even (hint: it involves division) than using mutual recursion, but hopefully it gets the point across.
Nested Recursion
In an attempt to be as thorough as possible, I will include a brief overview of nested recursion. As far as I can tell, nested recursion exists to give mathematicians and computer scientist something to talk about at social gatherings because you rarely see it used outside of academia. In nested recursion, the parameter for a recursive call is a recursive call itself. The most notable trait of nested recursion is that it is so complex that it cannot be solved iteratively, whereas other forms of recursion can be put in iterative form with a little bit of work. One of the most famous examples of nested recursion is the Ackermann function, which, from what I gather, is an algorithm that was made to prove that you could in fact have an algorithm so complicated that it could not be solved iteratively. Here’s what it looks like:
Listing 9
|
1 2 3 4 5 6 7 8 9 10 11 12 |
1 public int Ackermann(int m, int n) 2 { 3 if(m==0) return n + 1; 4 if(m > 0 && n == 0) 5 { 6 return Ackermann(m-1, 1); 7 } 8 else 9 { 10 return Ackermann(m-1, Ackermann(m, n-1)); //Take note of this nasty looking line 11 } 12 } |
Don’t worry about what this method does, because it basically produces really big numbers and solves no real world problem. The main thing to notice is on line 10. See how the recursive call contains a parameter that is another recursive call? That’s what nested recursion is all about.
Six Steps to Writing a Recursive Algorithm
In attempt to make writing recusive algorithms a bit more approachable, I’ve broken the process down into the following six steps:
- Define the Inputs
You have to start somewhere, and when it comes to methods a good place to start is the method signature. So the first thing you need to do is determine the inputs with which you need to work because these will become your method parameters. Once you know that, you can pick a good name for the method write your method signature.
- Define the Base Cases
The FIRST thing you should do after defining your method signature is to identify the base cases for your recursive algorithm and get them into your code. The BIGGEST problem I see when people are trying to solve a problem with recursion is that they start on the recursive part. Base cases are simple. Start by getting the simple part out of the way.
- Think Backwards from the Base Case
Some solutions for recursive problems will come to you naturally. Some will stump you. If you find yourself stumped, start from the base case and work backwards. Recursion is a very nebulous thing, so if you start thinking about the recursion then you’re mind is going to explode. A base case is a very well-defined and concrete concept. If you start with the base cases and work backwards, then you are starting from a concrete concept and it’s easier to think though. Most of the people I see having major problems with seemingly simple recursive problems are starting at the wrong end of the problem.
- Define the Recursion
If you are writing a recursive function then you are going to need to recurse at some point, so you need to identify how a recursive call plays into the solution. You also need to identify how the inputs to the recursive method calls need to change to ensure you are moving towards a base case.
- Do the Work
Remember, recursion is about working towards a base case, so the method needs to continually move in that direction with the work it does. You may also need to complete other operations along the way that are part of the solution but have absolutely nothing to do with moving towards a base case.
- Don’t get complicated
Recursive algorithms tend to be elegantly simple, so if you find yourself doing crazy stuff to get a recursive algorithm to work then you’re probably doing something horribly wrong; especially in an interview. If you find yourself needing a bunch of variables to store stuff, or you suddenly get the urge to introduce a delegate or anonymous function into the mix, then you probably need to backtrack.
A Quick Dive into the Recursive Factorial Function
Computer science has a few “classic” recursive functions, one of which is the Factorial function. I can attest that these have been a part of almost every interview that I have taken or given, so they are an important concept to learn for interviewing. If you think back really hard to high school math, you may remember the concept of factorials, which Wikipedia defines as follows:
“In mathematics, the factorial of a non-negative integer n, denoted by n!, is the product of all positive integers less than or equal to n.” (see Wikipedia entry)
Although it’s a concise definition, it leaves out one very important and key detail: the factorial of zero is equal to one. You cannot calculate 0! so it comes pre-defined as having a value of 1. Following is a listing of the few factorials:
Listing 10
|
1 2 3 4 5 6 |
0! = 1 1! = 1 * 1 2! = 2 * 1 3! = 3 * 2 * 1 4! = 4 * 3 * 2 * 1 5! = 5 * 4 * 3 * 2 * 1 |
You can also re-write this more succinctly as:
Listing 11
|
1 2 3 4 5 6 |
0! = 1 1! = 1 * 0! 2! = 2 * 1! 3! = 3 * 2! 4! = 4 * 3! 5! = 5 * 4! |
And you can break that down even further by defining a factorial as:
Listing 12
|
1 2 |
0! = 1 n! = n * (n-1)! |
Now let’s start looking at how to make a recursive method out of this. First, we know that we are dealing with an operation known as a factorial, so the name Factorial sounds like a great name for the method. Second, we know that the factorial function accepts a single integer as an input, and returns and integer value. As such, let’s go ahead and create the following method signature:
Listing 13
|
1 2 3 |
public int Factorial(int n) { } |
Next, we need to incorporate the base case into the method. Look back at the mathematical definition for factorials found in Listing 12. There are two definitions. One uses recursion. One does not. Guess which one is the base case? If you guessed the first one, then you are right.
Listing 14
|
1 2 3 4 |
public int Factorial(int n) { if(n==0) return 1; } |
If you take another look at Listing 12, you will see that the recursive part of the algorithm has been laid out for us fairly well. It’s simply a matter of getting the equation translated into code.
Listing 15
|
1 2 3 4 5 |
01 public int Factorial(int n) 02 { 03 if(n==0) return 1; 04 return n * Factorial(n-1); 05 } |
Now we have a functioning, recursive Factorial function. Notice that the mathematical definition in Listing 12 and the code are eerily similar. This is certainly not by chance. Whenever you have a recurrence relation, it should be fairly simple process to transpose it over into code. Fortunately, most interview questions involving recursion center on mathematical concepts like Factorials and Fibonacci numbers.
Writing the Factorial Function to Show Off for an Interview
Mike Frizzell stood at the whiteboard with his back facing us, presented with the same task as the interviewee from the beginning of this story: writing a recursive factorial function. He had paused at the whiteboard long enough that we were concerned we were about to have to endure another torturously unpleasant whiteboard session, so we prodded him by saying “Feel free to walk us through what you are thinking” to keep the interview from stalling out completely. That’s when he shrugged and said, “Oh, I’m trying to see if I can fit it all on one line…” which was definitely the answer for which we were looking. If you are writing the Factorial function as part of an interview then there are a few steps you can take to stand out a bit from the crowd. Listing 16 has the code:
Listing 16
|
1 2 3 4 |
01 public UInt64 Factorial(byte n) 02 { 03 return n==0 ? 1 : n * Factorial(n-1); 04 } |
This version of the Factorial function has a few key differences: the body is on a single line, it makes use of the conditional operator instead of an if statement, it uses an unsigned long integer as the return value and a byte as the input parameter instead of integers. Putting all the code in a single line is symbolic of being a bad ass because it tells the interviewers that it cannot get any more concise and to the point than what you have. If you are using the conditional operator, it means that you know about some of the more obscure parts of the .NET Framework. Finally, the Factorial function produces some large numbers. If you use an int as the return value, the method will crap out at Factorial(17) because the result is larger than an integer. A long value gets you all the way to Factorial(20). And the Uint64 allows you to go all the way up to Factorial(65) before you encounter issues. Since the method quits working when you pass in 65, an int value is overkill. A short value is overkill too. So you use a byte.
If you can remember all of that, then you’ll really come across as knowing your stuff if you encounter the factorial question in an interview. Be forewarned, however, that you should take the time to understand recursion as a whole, not just memorize how to answer the factorial question. If I have a candidate nail the factorial function question in an interview, I always have a backup one ready to make sure they really know what they’re talking about and not just regurgitating a prepackaged answer.
Recursion vs. Iteration
Most recursive algorithms can be implemented using an iterative approach, so the question that naturally arises is “what are the differences between the two approaches and when do you use one over the other?” To answer that question we need to talk about the call stack. As the name implies, the call stack is a stack based data structure that maintains information about which methods your application is actively executing. When your application calls a method, that method is pushed onto the top of the stack and begins executing. When a method completes and exits, that method is popped off the stack and execution returns to the previous method in the stack. Every method on the stack has a memory footprint. Depending on the number of parameters being passed into the method and the number of local variables inside the method, the footprint may be large or small, but it always requires a bit of memory to store information about an executing method. Likewise, each time a new method is called it takes a bit of processor power to create the method and place it on the call stack. So spinning up a new method incurs a minor penalty in terms of both processor time and memory.
Recursion is all about calling a method over and over again to arrive at a solution, so recursion has a built-in performance penalty due to the overhead associated with all of those methods being added and removed from the call stack. As such, the rule of thumb is to use an iterative approach if you have an option between the two. However, there are some problems that lend themselves to a recursive solution. Recursion often results in elegantly simple code because it leverages the call stack to store “state” information behind the scenes. An iterative approach to the same problem may not be as straightforward, requiring additional state storage variables and complex looping instructions which can reduce clarity and maintainability. So you have at trade off. If performance is a chief concern, you may want to opt for an iterative approach to squeeze every last bit of performance out of the method. If keeping things simple and maintainable is a concern, then you may opt for the recursive approach to avoid the headache of having to figure out an iterative solution.
Another limitation of which you should be aware is that the call stack has a finite amount of memory with which to work. Although you can encounter an infinite loop, you cannot really encounter infinite recursion because you eventually run out of stack space. And by eventually I mean dang near instantly. It can take less than a second to use up all the memory in the stack. So it is possible to encounter a situation where the recursion runs too deep and the stack simply isn’t big enough to accommodate all of the concurrent calls required to solve a problem. All you have to do to see this in action is to take a look at the Odd and Even functions in the Mutual Recursion section. A call to Even(50000) requires 50,001 recursive calls to solve, which is about 34,000 calls too many (at least on my system), and results in a StackOverflowException. The total number of recursive calls the stack can support for a given method is dictated by how much space the method takes up on the stack. Methods with a lot of local variables and parameters take up more stack space, so the stack cannot accommodate nearly as many of these as compared to methods with fewer local variables and parameters. Also understand that only concurrently executing recursive calls take up space in the stack. Recursive calls that have completed do not take up any space. If you look back to the Binary Recursion section, you can see that there are a total of nine recursive calls, but only four of those calls are executing (and therefore taking up stack space) at any given point in time.
In a discussion about recursion vs. iteration, you may also hear about tail-recursion optimization. Tail recursion optimization is a compiler optimization routine that converts tail recursive methods into an iterative form to avoid the overhead associated with recursion. You may think it’s kind of like the best of both worlds because you get the simplicity of recursive code and the performance of an iterative approach, but it only works with tail recursive methods and only on compilers that support the optimization. At the time of this writing, some of the .NET compilers do support tail recursion if your code meets certain criteria. You can check out David Broman’s blog post on Tail Call JIT Conditions if you want to wade through the list of requirements. However, I would not rely on nor get too excited about the compiler making your code super-fast.
Real World Recursion
Most of the examples we’ve looked at are fairly simple academic examples, but what do real world solutions that use recursion look like? Recursive solutions are normally used for problems where the branching logic is complex, so you tend to see them used to process tree-based structures like file systems, XML documents, and hierarchies of data. Tree-based structures have a variety of branching paths, and the nature of recursion makes the code for traversing those various paths simpler than an iterative approach. You may also see recursion used in situations requiring combinations or permutations, such as “what if” scenarios that need to incorporate an assortment of input variables.
Common Recursive Algorithms
If you want to explore recursive algorithms in more detail, or just prepare for an interview, then you should find the following list fairly helpful. If contains links to some of the most common recursive algorithms that you will encounter.
Conclusion
Taking a moment to brush up on recursion is definitely worth the time, especially if you plan on interviewing any time soon. Recursion is a topic that interviewers like to throw out to people because it really does separate those who know their stuff from those who are just picking up concepts as they go. Besides possibly landing you a job, recursion is also a good concept to know because it could really head off a problem that you encounter in your daily life. At least if you’re a developer. Or maybe a shampoo instruction copy editor.
Load comments