
This article was updated on the 2nd of November 2011 to reflect changes in the most recent version of SQL Storage Compress.
Introduction
In the database world there is one thing you can always count on, and that is the fact that more and more data is being created and stored every day. This means more SQL Server instances, more databases, and larger databases. In fact, it is estimated worldwide, that there is over 1 zettabyte (one trillion gigabytes) of data currently being stored or managed by databases.
While disk storage has come down in price substantially over the years, it still isn’t cheap, at least for server-class computers. The cost of high speed, high capacity SAS drives in a local server or attached DAS can add up fast, especially if you are using RAID 1 or RAID 10, where you have to purchase twice the number of drives for the same amount of available space. If you have a SAN, the cost per gigabyte is even greater. As data volumes continue to grow, more and more disk space is needed, which means that more and more money has to be invested in purchasing, maintaining, and administrating all of that storage.
Is there any way to reduce the requirement for additional high-end data storage? SQL Storage Compress, from Red Gate Software, may be able to help.
In essence, SQL Storage Compress takes your live database files and compresses them on disk, saving as much as 90% of the original size of MDF and NDF files. A database compressed with SQL Storage Compress behaves exactly like any normal SQL Server database, but if used appropriately, SQL Storage Compress can significantly reduce your SQL Server database disk storage needs, so helping you to reduce your storage costs.
SQL Storage Compress can compress MDF, NDF, and LDF files, but for optimum performance, it is recommended that only MDF and NDF files are compressed, and this will be the assumption I will be making throughout this article.
Note that you don’t have to compress all MDF and NDF files when you use SQL Storage Compress. You might not want to compress all the data files, as, for example, in situations where some data files are very active and other data files are mostly read-only. Thorough testing would be needed to determine whether you can boost the overall performance of the database by not compressing some of a database’s data files.
In this article I’m going to Explain in detail what SQL Storage Compress really does, and how it works. I’ll also cover how to install and implement SQL Storage Compress. Then I’ll discuss some tests that compare the difference in performance between using uncompressed SQL Server database files, SQL Storage Compress compressed database files, and SQL Server database files that use SQL Server 2008’s Enterprise Edition page compression. I’ll finish with some recommendations on when and where to use SQL Storage Compress in your organization to save on storage costs.
SQL Storage Compress is powered by Red Gate Software’s HyperBac technology, which is also used in Red Gate Software’s SQL Virtual Restore and SQL HyperBac tools. Click on these links to read my guides to using both of these tools.
So what exactly does SQL Storage Compress do?
The best way to explain what SQL Storage Compress does is to look at an example. Let’s assume you currently have a database that has a single MDF file of 500 GB. The 500 GB of file space will most likely include both full and empty data pages, especially if you intentionally pre-size your MDF file for future growth, as recommended by best practices. For the sake of this example, let’s assume that of the 500 GB MDF file size, that 400 GB actually contains data, with the remaining 100 GB of space reserved for future growth.
Now let’s add SQL Storage Compress to our example. When it is implemented, it automatically compresses the data stored in the MDF file (I’ll talk about how this works in the next section). Depending on how much empty space you have in your database, plus how compressible your data is, SQL Storage Compress can reduce MDF and NDF file sizes by up to 90%, although 60-80% compression is more typical. For the sake of this example, let’s assume that the compression rate is 80%. So this means that the 500 GB database shrinks to 100 GB, resulting in a significant saving of storage space.
That’s what SQL Storage Compress does; it just compresses data on the fly so that the disk space used by a database is substantially smaller than native SQL Server MDF and NDF files. All of this is done behind the scenes and, in fact, SQL Server doesn’t even know what is happening. SQL Server works just as it did before you began using SQL Storage Compress, retaining all the ACID properties you expect of SQL Server.
SQL Storage Compress can do more than just compress your database; it can optionally encrypt it as well, offering the same benefits as SQL Server 2008 Enterprise Edition Transparent Data Encryption (TDE), but without the requirement to purchase an Enterprise Edition license.
So what’s the catch? SQL Storage Compress can’t work miracles, right? As with any data compression tool (including SQL Server 2008 native page and row compression) it takes additional CPU power to perform the on-the-fly compression, and we’ll look at this in more detail when I discuss the performance tests later in this article.
How does SQL Storage Compress work under the covers?
So how does SQL Storage Compress perform its magic? How is it able to compress MDF and NDF files so that SQL Server can read and write to them like any other SQL Server database files? Before we can understand how SQL Storage Compress works, we first need to take a high-level look at how SQL Server interacts with the Windows OS (operating system).
While SQL Server performs many of its own tasks internally using the SQLOS (SQL Server Operating System), one of the things it doesn’t handle is the reading and writing of data directly to disk. Whenever SQL Server needs to read or write to a MDF or NDF file, it passes the I/O request to the Windows I/O Manager, which is a part of the OS’s kernel. At that point, the Window’s I/O Manager passes the I/O request to a device driver, and eventually the data is read from, or written to, disk.
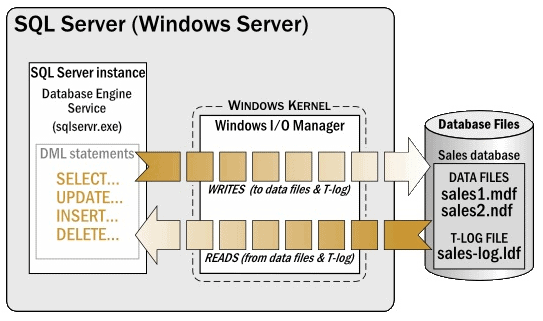
Figure 1: A high-level overview of how SQL Server interacts with the OS
For example, in Figure 1, any SELECT or DML statements (reads or writes) executed within the database engine that require data to be moved to or from the SQL Server data cache to disk are passed through the Windows I/O Manager to the MDF and NDF as appropriate.
Now that we know a little about how SQL Server works with the Windows I/O Manager, let’s find out how SQL Storage Compress is able to compress MDF and NDF files on the fly, without SQL Server even knowing that it is happening.
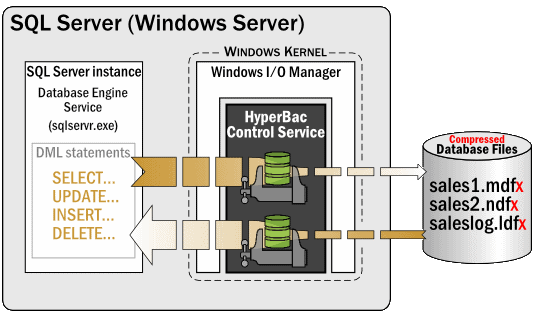
Figure 2: SQL Storage Compress uses the HyperBac Control Service to compress database data on the fly
When SQL Storage Compress is set up, it installs and starts what is called the HyperBac Control Service. This service is like any other OS service and runs under the LocalSystem security account. Its job, in cooperation with the Windows I/O Manager, is to intercept the read and write requests from SQL Server, compressing or decompressing them as necessary. SQL Server doesn’t even know that the HyperBac Control Service exists- the database engine just passes its I/O requests to the Windows I/O Manager. And since SQL Storage Compress works within the context of the Windows I/O Manager, SQL Server is none the wiser. The SQL Server instance remains unaware that the database files are being compressed and decompressed, and works just as any database files do, reading and writing data to the MDF and NDF files.
Now that we know a little about how SQL Storage Compress works under the covers, we’ll move on to how to use it. For a detailed look at installation, and how to initiate MDF and NDF compression in your own databases, please download this PDF.
Using the SQL Storage Compress GUI
As we have seen, all you need to do to create or convert an existing database using SQL Storage Compress is to use native Transact-SQL commands. However, in response to requests from some customers of previous versions of SQL Storage Compress, a simple GUI has been added to the latest version that not only provides a graphical view of which databases are and are not being compressed by SQL Storage Compress, but it also can be used to restore a backup to a compressed SQL Storage Compress database without having to write any Transact-SQL code.
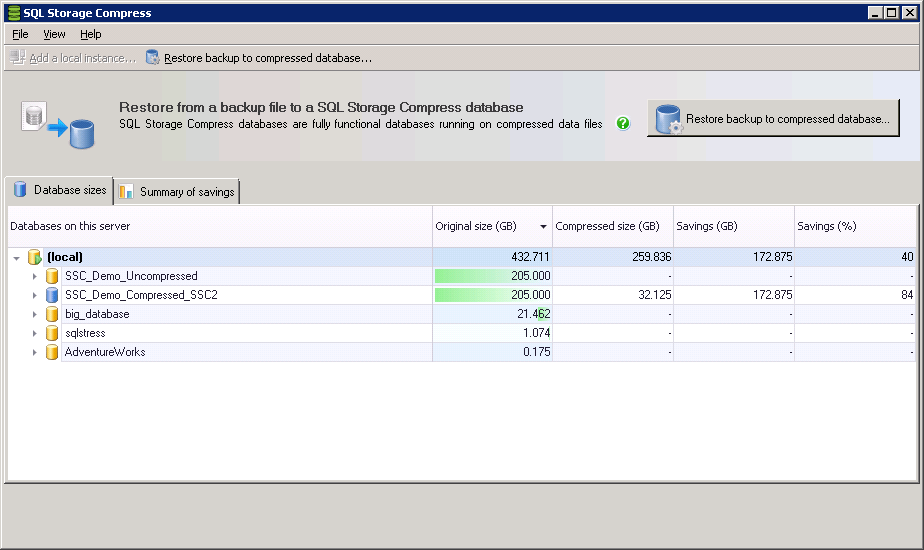
Figure 5: The new SQL Storage Compress GUI showing the “Database sizes” tab.
In Figure 5, you see the “Database sizes” tab. This tab has several purposes.
First, it lists both uncompressed and compressed databases stored on this instance. (Normally, once a database has been compressed with SQL Storage Compress, the old, non-compressed database would be deleted. For the purposes of explanation, I have not deleted the non-compressed version of the database in this example.)
The uncompressed databases sizes under Original size (GB) can be used to see which databases are the largest, and therefore might reap the greatest benefit from using SQL Storage Compress. This is because the larger the database the greater the compression is likely to be.
The remaining three columns are designed to be used after you have compressed one or more databases using SQL Storage Compress, and they show the compressed size and the space savings in GB and as a percentage. This feature was added to remind DBAs that the database sizes they see in SSMS are what SQL Server thinks it sees, not the actual compressed database sizes on disk after SQL Storage Compress has worked in the background to perform its compression magic.
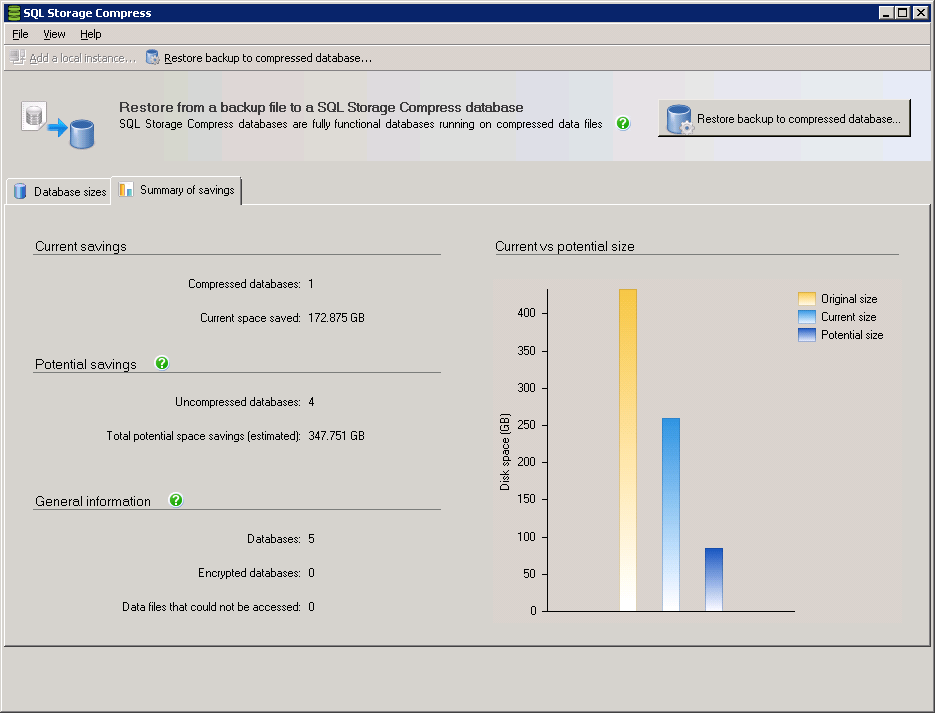
Figure 6: The “Summary of savings” tab
Like the first tab, the “Summary of savings” tab provides some data that is useful before any databases are compressed using SQL Storage Compress, such as the estimated amount of space that could be saved if all of the databases were compressed using SQL Storage Compress. Once one or more databases have been compressed using SQL Storage Compress, additional compression-related information is provided, such as the actual space savings. In Figure 6, I have one compressed database and have saved about 172.9 GB. On the other hand, additional savings of 337.8 GB could be had if other databases were also compressed.
One last feature of the GUI is the “Restore backup to compressed database” button. It can be used to restore a backup as a compressed database instead of using the Transact-SQL code.
Putting SQL Storage Compress to the test
I am sure that most of you will be interested in the performance of SQL Storage Compress. In this section, my goal is to provide you with the results of some tests I performed, so you can get a better understanding of what the performance hit is. Before you read this next session, I want you to keep in mind that the testing I did was specific to a single test database under ideal conditions, using my test hardware. If you were to try and replicate my tests, you could very well get different results. This is because there are many variables that affect the performance of a database, whether or not it is compressed, such as:
- The hardware used for the testing: This not only includes the type and configuration of the hardware, it also includes how busy the hardware is. Is the hardware bottleneck free, or does it have some bottlenecks?
- The compressibility of the data stored in the database.
- How busy the server is when you perform the testing: Are there many active, simultaneous users, and are they performing a lot of activity? Is the activity mostly OLTP, OLAP, or some mixture of the two?
- How well the database schema is designed: Some schema designs lend themselves better to compression than others.
- How well tuned an application’s queries are, and how well the indexes on the tables have been tuned.
- What kind of database activity you are performing, and at what ratio: For example, is your database 100% read-only? Is it 70% SELECTS, 20% INSERTS, 5% UPDATES and 5% DELETES? In other words, the type of activity you perform directly affects the performance of a compressed database, whether the database is compressed by SQL Server Compress or using SQL Server 2008 Enterprise Edition page compression.
As you can see, there are a lot of variables that can affect performance. Some variables help boost the performance of a compressed database, others hurt it, and others don’t affect it at all. In other words, the only way to know for sure if any database compression will meet your needs, whether using SQL Storage Compress or SQL Server 2008 Enterprise Edition page compression, is to perform your own testing, using your hardware, using your own data, and testing under realistic production conditions.
My test setup
All my testing was done using the following:
- Two identical Dell T610 Towers, each with a single, 6-core CPU (Intel Xeon X5670, 2.93 Ghz, 12M Cache, HT, 1333 MHz FSB); 32 GB 1333 MHz RAM; a PERC H700 RAID controller; two 146 GB 15K SAS Drives; one HBA (to connect to the DAS); and a 1 GB network card. Hyperthreading was turned on, so SQL Server saw 12 logical CPUs. One server was used for SQL Server; the other was used to run the tests. The two servers were connected via a 1 GB network card and switch.
- The test SQL Server was attached to a PowerVault MD3000 DAS with two, dual-port controllers, and 15 146 GB 15K SAS drives. MDF files were stored on a RAID 10 array with 10 drives, and the LDF files were stored on a RAID 10 array with 4 drives.
- SQL Server 2008 R2 Enterprise Edition and Windows 2008 R2 Enterprise (with all the latest updates as of August 2011) were used for all testing.
- The test database had a 200 GB MDF file and a 5 GB LDF file. The MDF and LDF files were located on separate RAID 10 arrays. The MDF file was compressed while the LDF file was left uncompressed.
- The database had a single table that included data similar to what you might find in a customer table, with a variety of different fixed length and variable length data types. It had a clustered index on an identify column, and a non-clustered index on the Last_Name column with an included column on First_Name, and had 150 million rows. The MDF file stored 114.8 GB of data, with the remaining space unused. The test data used in the tables was created using SQL Data Generator. Obviously this is not representative of most databases, but it provides a baseline for which I can perform a variety of consistent tests.
Test scenarios
I tested three different scenarios on the exact same database:
- Native SQL Server MDF files (no compression).
- SQL Server page compression. (I did not test row compression, which is a subset of page compression, and produces less compression than page compression.)
- SQL Storage Compress database compression.
I then compared the results for each scenario.
Tests Performed
In order to minimize any variations in my testing, I kept the tests simple. Because of this, the following results aren’t entirely realistic, but at least they allow me to compare one test scenario to another in an apples-to-apples comparison. The tests for each scenario comprised:
- SELECT 5 million rows from a table.
- INSERT 5 million rows into a table.
- UPDATE 5 million rows into a table. This test updated only one column, and did not change the length of the row, so there would be no issues with potential page splits. (Page splits only complicate the testing, so I intentionally avoided them by keeping the UPDATE statement as simple as possible.)
- DELETE 5 million rows from a table.
You may be wondering why I choose to work with 5 million rows. I did this because when I tried testing with more “typically-sized” queries, the performance difference was so small that I couldn’t distinguish one result from another. For example, if I only tried 100 rows for each of the above tests, the difference between them were in the thousandths of a second, which is too small a number to get accurate measurements. So I went to the extreme in order to push the software and to better differentiate the results.
For all the tests, the buffer cache was full, which means the data being tested was already in the data cache. This was intentional, because disk I/O is complicated to test, and disk I/O performance varies so much between different SQL Server hardware. (However, note that the INSERT, UPDATE, and DELETE tests, of course, had to log their activity to the transaction log during each test, which means that disk I/O did inevitably play a part in the rest results.)
Each of the tests were run multiple times, taking a total of about 20 hours to perform. In most cases, each separate run of a test produced a similar result, although there was the occasional anomaly, such as a checkpoint running during the middle of a test. I threw out anomalous results and used the average of all the remaining test runs in the results.
As you review the results, keep in mind that some of the differences are relatively very small, even though I used 5 million records for each test, and because of this, don’t have a lot of meaning. For example, if one test took 110 seconds under one scenario, but 115 in another scenario, even though 110 is faster than 115, it’s not much faster, and the difference is insignificant.
Testing standard SQL Server MDF files (no compression)
This first test acted as my baseline, as the database was not compressed. When you look at the Disk Usage Report, you will see how the data is allocated in the database.
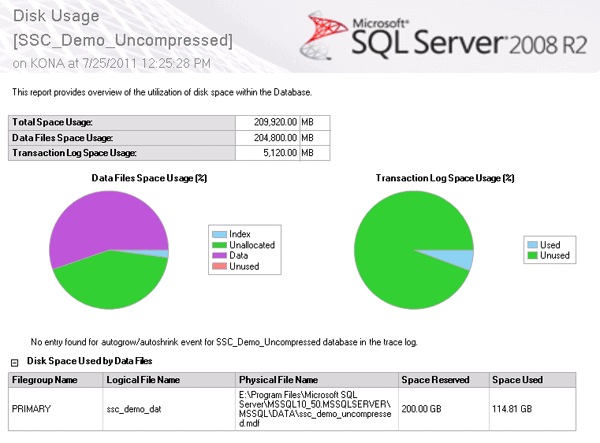
Figure 7 – Each test used in all three scenarios used this same database
The results for the tests on the uncompressed database are shown in Figure 8.
| File Sizes | Standard SQL Server MDF and LDF Files |
| MDF (KB) | 209,715,200 |
| Test Results | |
| SELECT 5 million rows (sec) | 120 |
| INSERT 5 million rows (sec) | 243 |
| UPDATE 5 million rows (sec) | 7 |
| DELETE 5 million rows (sec) | 102 |
The test results speak for themselves, and will be our baseline for the next two scenarios.
Testing SQL Server page compression
SQL Server 2008 and SQL Server 2008 R2 (Enterprise Edition only) offer two different types of data compression: row and page compression. To learn more about them, see An Introduction to Data Compression in SQL Server 2008 (http://www.bradmcgehee.com/2010/03/an-introduction-to-data-compression-in-sql-server-2008/).
To keep my test scenarios as “apples-to-apples” as I could, I used page compression on all the indexes (clustered and non-clustered) in the sample database, because SQL Storage Compress compresses all objects in a database. I used page compression over row compression because it provides the greatest amount of data compression offered by the product. The results are shown in Figure 9, with the results from the baseline test included for reference.
| File Sizes | Compression | |
| No Compression | SLQ Server Native Page | |
| MDF (KB) before compression | 209,715,200 | 209,715,200 |
| MDF (KB) after compression | – | 235,553,792 |
| Percent compression | – | -12% |
| Test Results | ||
| SELECT 5 million rows (sec) | 120 | 120 |
| INSERT 5 million rows (sec) | 243 | 275 |
| UPDATE 5 million rows (sec) | 7 | 9 |
| DELETE 5 million rows (sec) | 102 | 107 |
Figure 9: Comparing ‘no compression’ with SQL Server page compression
Let’s compare the results of using SQL Server page compression to not using page compression.
The MDF size starts out identical, which is to be expected, as the same copy of the database was used for testing.
But when you compare the size of the MDF files after page compression has been turned on, the MDF file size is 12% larger, not smaller! So what happened to the compression? Shouldn’t the page-compressed files be smaller? Have you guessed the answer yet? What happened was that during the page compression process, additional space was needed in the MDF file to create the newly compressed indexes, so the MDF file actually had to grow in order to make room. Then, the old, uncompressed indexes were deleted, leaving additional unallocated space.
So what does this all mean? The first question you must ask is whether the data in the database actually shrank, and the answer is yes, although this information is not shown in the results table. To see the data shrinkage, it is necessary to look at the Disk Usage by Top Tables Report included within SSMS. Before the compression, the table size looked as in Figure 11:

Figure 10: Table sizes before page compression was turned on
Adding up the size of the data and the indexes, we can calculate that Table_1 took up 120,363,264 KB of disk space before page compression was turned on. After page compression was turned on, the table is now smaller, as you can see in Figure 11:

Figure 11: Tables sizes after page compression was turned on
After page compression, Table_1 takes up 117,734,208 KB, a reduction of about 2.2%-not a very large amount for this particular table and its data. Of course, a different set of test data could potentially be compressed much more, depending on the nature of the data.
While the data did shrink, the MDF file grew in size. At this point, you have the option of leaving the MDF at its current size, or shrinking it back to its original size, or reducing it to an even smaller size. You could shrink the page-compressed database to fit only the size of the data to reduce storage space, but this is not a “best practice”. Ideally, you should leave free space in your databases for future growth, and not depend on autogrowth to manage the size of your databases.
While this is good advice for SQL Server uncompressed and page-compressed databases, this is not the case with SQL Storage Compress. SQL Storage Compress doesn’t have a need to maintain empty space, growing only as needed, and doing so in a way different from the way autogrowth does, rendering it unnecessary to maintain empty space in the first place. This is one of the ways that SQL Storage Compress keeps database sizes to a minimum.
Now let’s take a look at the differences in performance. SELECT performance was identical in both databases, at 120 seconds to SELECT 5 million rows from a table with a clustered index. This was most likely because all of the data was already in the data cache, and the server did not have any memory pressure. If the server had been very active and under heavy memory pressure, I would expect the SELECT performance of the page-compressed database to outperform the uncompressed database. This is because page compression works, not only on disk, but also in the data cache, which means that page compression allows more rows to be stored in the data cache, which could, depending on the circumstances, reduce the disk I/O needs of the server. I did not test under a heavy load with memory pressure because it proved to be too hard to keep this consistent from one test to another.
INSERT performance suffered more under data compression than under no compression, although not by a lot. It took 243 seconds to INSERT 5 million rows into a table with a monotonically increasing clustered index key with no compression, but 275 seconds under page compression. This is as expected because the inserted data has to be compressed, which takes additional time.
The UPDATE test showed similar results. It took 7 seconds for the uncompressed database and 9 seconds for the SQL Server native page compressed database. This test was much faster than the INSERT and DELETE tests because only one column was updated. The difference between 7 and 9 seconds is not much and probably would not be significant in most databases.
In the DELETE test, the uncompressed database took 102 seconds verses 127 seconds for the SQL Server native page compressed database. This difference was comparable to the INSERT test, where the uncompressed database performed noticeably faster than the compressed database.
While the SELECT tests between the non-compressed database the SQL Server native page compression performed identically, all of the data modification tests performed more slowly, which can be attributed largely to do the overhead of the extra CPU required to perform the compression.
Unfortunately, if, like many DBAs, you don’t use the Enterprise edition of SQL Server 2008 or SQL Server 2008 R2, you won’t be able to use row or page compression. Therefore, if live, on-the-fly data compression is important to you to reduce the overall storage footprint of a database, SQL Storage Compress is your only option.
Testing SQL Storage Compress
As I have already discussed, SQL Storage Compress compresses the entire database, including any MDF and NDF files you specify that you want compressed. And, unlike SQL Server native page compression, SQL Storage Compress performs all of its work outside of the SQL Server engine. Now let’s see how SQL Storage Compress fared in the testing.
In this section, I compare SQL Storage Compress to both an uncompressed database and the SQL Server native page compressed database. So please be patient as I compare all of the tests. The results of the previous two tests are also shown in Figure 12 for reference.
| File Sizes | Compression | ||
| No Compression | SQL Server Native Page | SQL Storage Compress | |
| MDF (KB) before compression | 209,715,200 | 209,715,200 | 209,715,200 |
| MDF (KB) after compression | – | 235,553,792 | 28,439,168 |
| Percent compression | – | -12% | 86% |
| Test Results | |||
| SELECT 5 million rows (sec) | 120 | 120 | 120 |
| INSERT 5 million rows (sec) | 243 | 275 | 245 |
| UPDATE 5 million rows (sec) | 7 | 9 | 7 |
| DELETE 5 million rows (sec) | 102 | 127 | 109 |
Figure 12: The test results for SQL Storage Compress (compared with the previous tests for reference)
The first thing I want to look at is the amount of space used by the MDF file as compared to the uncompressed and page compressed databases.
As you can see from Figure 14, after SQL Storage Compress has compressed the database MDF file, the file is now only 28,439,168 KB, which is a reduction of about 86% over the original MDF file size, and over the SQL Storage native page compression assuming that you shrink it back to its original size. This is where the real benefit of using SQL Storage Compress comes into play-freeing up large amounts of storage space, and substantially reducing the costs of storage.
Now let’s take a look at the differences in performance between SQL Storage Compress compression, SQL Server native page compression, and no compression.
It took the SQL Storage Compress compressed database 120 seconds to SELECT 5 million records, the same time as it took to perform the same test in the other two database scenarios. This is to be expected, as all of the data that was selected was already in the data cache. But, you may be asking, is this a fair test, as in the real world, this would not always be the case? And that’s a fair question as, on a server, some queries would find the data all in the data cache, and other queries would require pages to be moved into the data cache from disk. You can never be sure where the data will be (data cache or disk); because of this, I decided to only test SELECT performance when the data is available from the data cache, as this is easily repeatable.
On the other hand, there is something that is not obvious about this SELECT test that you need to be aware of when using SQL Storage Compress. For example, let’s say that you want to perform a SELECT on 5 million rows, but none of the rows are in the data cache, only on disk. This means that, in the worst case, SQL Server will have to read the 5 million rows from disk into the buffer cache. When the SELECT statement is issued, SQL Server will pass the read request on to the I/O Manager and the HyperBac service. SQL Server will then be able to read the 5 million rows from disk using far fewer physical reads than if the data was uncompressed or page compressed. Why? Because the physical MDF file for the SQL Storage Compress compressed database is much smaller. In other words, SQL Storage Compress can store more rows per KB on disk than either an uncompressed or page compressed disk file.
This means that, if disk I/O is required to move data pages from disk to the data cache, the SELECT will incur far fewer I/O reads, as each I/O read will be able to read more rows than from an uncompressed database or a SQL Server native page compressed database. However, it will require additional CPU cycles to perform the decompression. In other words, you have to make a trade-off: more CPU cycles for less disk I/O. Given that most SQL Servers tend to be more I/O bound than CPU bound, this is often a good trade-off. In fact, if your current system is I/O bound, and if, by using SQL Storage Compress you eliminate the I/O bottleneck, the overall performance of the database could potentially improve.
The next test was the INSERT test. As with the page compression database, inserting 5 million rows of data into a table takes longer than with an uncompressed database. It took 245 seconds for SQL Storage Compress, which was 30 seconds faster than the 275 seconds it took under SQL Server native page compression. As you can see, both were slower than the 243 seconds it took for the uncompressed database but, as I mentioned before, this is because the data has to be compressed before it is inserted, which takes a little extra time.
The UPDATE test only took the SQL Storage Compress database 7 seconds, which was 2 seconds faster than the 9 seconds required by the SQL Server native compression database, and the same amount of time as the uncompressed database.
The DELETE test only took the SQL Storage Compress database 109 seconds, which was 18 seconds faster than the 127 seconds required by the SQL Server native page compression database, and only 7 seconds longer than the non-compressed database.
When should SQL Storage Compress be used?
Just as with SQL Server 2008’s Enterprise Edition data compression, SQL Storage Compress may not always be the right solution for every database. For the most part, SQL Storage Compress works well in the situations below:
- For large databases.
While SQL Storage Compress will work on databases of virtually any size, the larger the database, the more disk space you will save. In turn, the higher your storage costs, the faster the return on investment you will receive using SQL Storage Compress. - For databases running on servers that have extra CPU power that is not being used.
If your SQL Server total CPU utilization exceeds 70% on a regular basis, SQL Storage Compress is probably not a good option. This is because data compression uses CPU resources, whether it is SQL Storage Compress or SQL Server 2008 Enterprise Edition data compression. In many cases, by taking advantage of wasted CPU cycles, SQL Storage Compress can reduce disk I/O, helping to reduce or eliminate bottlenecks.
Test SQL Storage Compress for yourself
As we have seen, SQL Storage Compress has the ability to significantly reduce the size of your databases, helping to reduce your storage costs. There is some impact on CPU, but if storage costs are important to you, I strongly recommend that you download the free trial of SQL Storage Compress and try it out for yourself. Only by testing it in your own environment will you be able to determine if it meets your specific needs.
Load comments