
SQL Server provides one built-in feature for storing documentation alongside database objects (extended properties, accessed via sp_addextendedproperty and the catalog views) and one tooling-supported pattern for keeping documentation inside build scripts (structured comment headers in YAML, JSON, or XML). Neither is sufficient on its own. Extended properties don’t support hierarchies or lists and aren’t versioned with build scripts. Structured headers in build scripts version naturally but require extraction tooling to publish.
The pragmatic approach is to use both: structured YAML headers in CREATE/ALTER scripts for object-level documentation (versioned in source control), and extended properties for the surface metadata exposed to tools and queries.
This article walks through both approaches, the format choices (YAML preferred for readability, JSON for tool-chain integration, XML for legacy compatibility), how to extract YAML from build scripts, and how to publish the extracted documentation.
‘Understanding the existing product consumes roughly 30 percent of the total maintenance time’
“Facts and Fallacies of Software Engineering” by Robert L. Glass.
Introduction
Code likes to be surrounded by explanation. I like to keep as much information as possible together with the code I write, whatever language I use. Most languages allow you to extract this information for the purposes of reporting, documentation, integrating with bug-tracking or source control, or providing tooltip help: SQL Server doesn’t. No sensible method for doing database documentation has either been provided by Microsoft, or properly supported by the software tools that are available. In the absence of an obvious way of going about the business of documenting routines or objects in databases, many techniques have been adopted, but no standard has yet emerged.
You should never believe anyone who tells you that effective database documentation can be entirely generated from a database just by turning a metaphorical handle. Automatic database generators can help, but cannot absolve the programmer from the requirement of providing enough information to make the database and all its routines intelligible and maintainable: This requires extra detail. The puzzle is in working out the most effective way of providing this detail.
Once you have an effective way of providing details about the tables, views, routines, constraints, indexes and so on in your database how do you then publish this information in a form that can be used?
In this article I’ll show how to insert structured headers into SQL code, and attach them to various database objects, and show to extract the information from the database in a form that can then be used for whatever purpose you require.
Why bother to document databases?
When you’re doing any database development work, it won’t be long before you need to seriously consider the requirement for documenting your routines and data structures. Even if you are working solo, and you operate a perfect source-control system, it is still a requirement that kicks in pretty soon, unless you have perfect recall. Many times, I’ve sat down in front of some convoluted code, asked the rhetorical question ‘God, what idiot wrote this code?’ only to find out it was I, sometime in the past. By documenting, I don’t just mean the liberal sprinkling of in-line comments to explain particular sections of code: If you are coordinating a number of programmers on a project, then it is essential to have more than this; you’ll require at least an explanation of what it does, who wrote it or changed it, and why they did so. I would never advocate presenting the hapless code-refactorer with a sea of green, but with a reasonable commentary on the code to provide enough clues for the curious. I’d also want examples of use and a series of assertion tests that I can execute to check that I haven’t broken anything. Such thing can save a great deal of time.
Where the documentation should be held?
Most database developers like to keep the documentation for a database object together with its build-script, where possible: That way, it is easy to access and never gets out of synchronization. Certain information should be held separately in source control, but only sufficient for the purposes of continuous integration and generating the correct builds for various purposes. The source code should be the canonical version of documentation where possible.
This primary source of the essential documentation should be, in effect, stored within the database, and the ideal place is, usually, within the source script. When documentation about code needs to be extracted, it is best done, where possible, by an automatic process.
You can hold the documentation separately from the code in source control, of course, but it is difficult to match the convenience of having as much information accessible within the database. The problem is in the duplication of effort if you wish to provide extra data to source control such as check-in comments.
The obvious place to hold documentation within the SQL source is in a comment block in the actual text for routines such as stored procedures, rules, triggers, views, constraints and functions.
This sort of comment block is frequently used, held in structured headers that are normally placed at the start of a routine, but acceptable anywhere within it.
Microsoft had an attempt at a standard for doing it. Some SSMS templates have headers like this …
|
1 2 3 4 5 |
-- ============================================= -- Author: <Author,,Name> -- Create date: <Create Date, ,> -- Description: <Description, ,> -- ============================================= |
… (the macros delimited by the angle-brackets are filled in by SSMS), but these headers are neither consistent not comprehensive enough for practical use. These headers would have to conform to a standard, so that routines can be listed and searched. At a minimum, there should be agreement as to the choice of headings. The system should be capable of representing lists, such as revisions, or examples of use. Many different corporate-wide standards exist but I don’t know of any common shared standard for documenting these various aspects. Many conventions for ‘structured headers’ take their inspiration from JavaDocs, or from the XML comment blocks in Visual Studio. Doxygen is probably one of the best of the documenters designed for r C-style languages like C++, C, IDL, Java, and even C# or PHP.
The major difficulty that developers face with database documentation is with tables, columns and other things that are not held in the form of scripts. These scripts cannot be reverse-engineered from the metadata with the tools that Microsoft provides, so if you wish to preserve them you can’t use the GUI to modify the tables. You cannot store documentation for these in comment blocks if you like using SSMS to modify tables and their associated objects : you have to store them in extended properties. We’ll discuss this at length later on in this article.
Wherever these headers are stored, they require special formatting because the information is really hierarchical in nature when it comes to lists of revisions, and examples of use. Microsoft use XML-formatted headers with Visual Studio. I know of people who have experimented with YAML and JSON headers with homebrew methods of extracting the information. Most of these scripts extract structured headers from T-SQL routines, automatically add information that is available within the database such as name, schema, and object type, and store them in an XML file. From there on, things get murky.
What should be in the documentation?
We probably want at least a summary of what the database object does. For routines, I suspect that you’ll also need a comprehensive list of examples of use. You may want to add a quick-check test batch that you can execute when you make a minor routine change. Even though source control will tell you who wrote and provide a history of who revised it, when, why, and what they did, it is handy to have a copy here for the even if the ‘who’ was yourself. I’ve always wanted to automatically pick up this information in source control to add to the headers but never got around to it. Headers need to support extensible lists, so you can make lists of revisions, parameters, examples of use and so on. Databases already hold a lot of information that is normally in code headers, such as when the routine was first created, when last modified, its parameters if any, what its dependencies are, and what objects it is dependent on. I generally add these if necessary when extracting the documentation.
How should the documentation be published?
There is no point in keeping all this documentation if it cannot be published in a variety of ways. There are many ways that development teams need to communicate, including intranet sites, PDF files, DDL scripts, DML scripts and Help files. This usually means extracting the contents of structured headers, along with the DDL for the routine, as an XML file and transforming that into the required form. Regrettably, because there are no current standards for structured headers, no existing SQL Documenter app is able to do this effectively. Several applications can publish prettified versions of the SQL code, but none can directly use such important fields of information as summary information or examples of use, though SQL Doc can display them. We don’t have the database equivalent of Sandcastle, which takes the XML file and generates a formatted, readable, help file. However, one can easily do an XSLT transformation on the XML output to provide HTML pages of the data, all nicely formatted, or one can do corresponding transformations into a format compatible with HELP-file documentation systems.
What standards exist?
Let’s firstly have a look at the equivalent standard for C#, VB.NET and F#. The compilers for these languages can extract strings tagged with ‘well-formed’ XML markup that are in special comment lines (/// for C# and ”’ for Visual Basic) or in a special comment block delimited as /** .... **/. The compilers can add information that it gains by parsing the source file and then placing the result into XML files called XML Documentation Comments. These are then used for Visual Studio Intellisense and the object browser, and can be imported into applications such as Doxygen or Sandcastle to convert them into help files. Of course, you can transform an ‘XML Documentation Comments’ file into anything you choose with XSL.
Microsoft’s XML documentation standard isn’t much used outside Visual Studio, and all tools seem to assume that you are writing in a .NET procedural language. The standard has not been adopted with much enthusiasm except for the three items of information (Summary, Params and Remarks) that are used by Visual studio.
The basic tags used in XMLdocs are appropriate for most purposes, but if you are doing your own processing of the results, you can add to them.
Unlike most forms of structured documentation, XML documentation is usually inserted immediately before the definition of the component that you are documenting.
The standard tags are as follows:
| Tag | Purpose |
| <c> | Set text within a paragraph in a code-like font to indicate that it is a token |
| <code> | Set one or more lines of code or output |
| <example> | An example of the routine’s use |
| <exception> | The errors or exceptions that can be thrown by the code |
| <list> | Create a list or table |
| <para> | delimits a paragraph within the text |
| <param> | Describe a parameter for a routine, procedure, method or constructor |
| <paramref> | Identify that a word is a parameter name |
| <permission> | Document the security accessibility of a routine or member |
| <remarks> | Describe a type |
| <returns> | Describe the results, variables, or return value of a routine or method |
| <see> | Specify a link, |
| <seealso> | Generate a See Also entry e.g. <seealso cref=”MyProcedure”/> |
| <summary> | Describe a member of a type |
| <typeparam> | The name of the type parameter, with the name enclosed in double quotation marks (” “). |
| <value> | Describe a property or variable |
There is, in addition, one tag that is actually a directive
| Tag | Purpose |
| <include> | Refers to another file that describes the types and members in your source code. This can include a XPath spec to explain where in the file the compiler should go to get the information |
Not all these tags require their contents to be filled in, since information such as the parameters and the permissions is easily retrieved. With the Microsoft .NET languages, the compiler will fill in the details that it can. Some of the most useful things you normally want to put into structured headers aren’t included in this list because they are made into lists, and XML isn’t as suited for lists as JSON or YAML.. The <LIST> elements are mostly used for revision/version lists but the format is no good for searching for version numbers, or the details of particular revisions of code
In order to try to persuade you that this is not a good standard to adopt, here is a very simple SQL Server Stored Procedure with the barest minimum of documentation..
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
IF OBJECT_ID(N'IsSpace') IS NOT NULL DROP FUNCTION IsSpace GO CREATE FUNCTION dbo.[IsSpace] (@string VARCHAR(MAX)) /** <summary>IsSpace string Function Returns Non-Zero if all characters in @string are whitespace characters, 0 otherwise.</summary> <example> <code>Select dbo.IsSpace('how many times must i tell you')</code> </example> <example> <code>Select dbo.IsSpace(' <>[]{}"!@#$%9 )))))))')</code> </example> <example> <code>Select dbo.IsSpace(' ????/>.<,')</code> </example> <returns>integer: 1 if whitespace, otherwise 0</returns> **/ RETURNS INT AS BEGIN RETURN CASE WHEN PATINDEX( '%[A-Za-z0-9-]%', @string COLLATE Latin1_General_CS_AI ) > 0 THEN 0 ELSE 1 END END GO |
Extracting the XML file isn’t too hard. For each routine, you’d need an XML fragment like this ..
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
<member id="span"> dbo.IsSpace(Varchar(MAX)"> <summary> IsSpace string Function Returns Non-Zero if all characters in @string are whitespace characters, 0 otherwise. </summary> <param id="String""> Parameter 1 requires a VARCHAR(MAX) argument. </param> <example> <code> Select dbo.IsSpace('how many times must i tell you')</code> </example> <example> <code> Select dbo.IsSpace(' <>[]{}"!@#$%9 )))))))')</code> </example> <example> <code> Select dbo.IsSpace(' ????/>.<,')</code> </example> <returns> integer: 1 if whitespace, otherwise 0 </returns> </member> |
Notice that you ought to escape certain characters. This makes the translation more complicated.
It isn’t hard to see from this why the ‘XML documentation comments’ convention never really caught on as a general standard, beyond using the summary tag to generate intellisense. It is awkward. It makes the code hard to read. You are liable to miss important information.
More modern approaches to structured text, such as YAML, provide a far easier and more intuitive approach, and allow for a much more versatile way of handling paragraphs of text. Here is a JSON header, which is easier to read or write than raw XML.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
/** { "returns": "1 if whitespace, otherwise 0", "example": [ { "code": "Select dbo.IsSpace('how many times must i tell you')" }, { "code": "Select dbo.IsSpace(' <>[]{}\"!@#$%9 )))))))')" }, { "code": "Select dbo.IsSpace(' ????/>.<,') " } ], "summary": "IsSpace string Function Returns Non-Zero if all characters in s are whitespace characters, 0 otherwise.\n" } */ |
If you want a human-oriented approach to headers, YAML seems a better design. Here is a YAML version of the XML header which is directly equivalent.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
IF OBJECT_ID(N'IsSpace') IS NOT NULL DROP FUNCTION IsSpace GO CREATE FUNCTION dbo.[IsSpace] (@string VARCHAR(MAX)) /** summary: > IsSpace string Function Returns Non-Zero if all characters in s are whitespace characters, 0 otherwise. example: - code: Select dbo.IsSpace('how many times must i tell you') - code: Select dbo.IsSpace(' <>[]{}"!@#$%9 )))))))') - code: Select dbo.IsSpace(' ????/>.<,') returns: 1 if whitespace, otherwise 0 **/ RETURNS INT AS BEGIN RETURN CASE WHEN PATINDEX( '%[A-Za-z0-9-]%', @string COLLATE Latin1_General_CS_AI ) > 0 THEN 0 ELSE 1 END END GO |
Here is another example of a YAML header
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
summary: > This procedure returns an object build script as a single-row, single column result. Unlike the built-in OBJECT_DEFINITION, it also does tables. It copies the SMO style where possible but it uses the more intuitive eay of representing referential constraints and includes the documentation as comments that was, for unknown reasons, left out by Microsoft. You call it with the name of the table, either as a string, a valid table name, or as a schema-qualified table name in a string. Revisions: - Author: Phil Factor Version: 1.1 Modification: dealt properly with heaps date: 20 Apr 2010 - version: 1.2 modification: Removed several bugs and got column-level constraints working date: 1 Dec 2012 - Version: 1.3 Modification: Added extended properties build date: 3 Dec 2012 example: - code: sp_ScriptFor 'production.product' - code: sp_ScriptFor 'HumanResources.vEmployee' - code: sp_Scriptfor 'person.person' - code: execute AdventureWorks..sp_ScriptFor TransactionHistory - code: sp_ScriptFor 'HumanResources.uspUpdateEmployeeHireInfo' returns: > single row, single column result Build_Script. |
YAML is far more usable, but would require processing to turn it into XML. However, other approaches can be modified with little change. JSON code can, for example, normally be digested by a YAML parser. The SSMS templates need just a slight adjustment. These are provided for you to fill with the required parameters , The content between the chevron brackets is filled in by SSMS as part of the templating process and is not part of YAML.
|
1 2 3 4 5 |
-- ============================================= -- Author: <Author,,Name> -- Create date: <Create Date, ,> -- Description: <Description, ,> -- ============================================= |
Becomes
|
1 2 3 4 5 6 7 |
/** # ============================================= Author: <Author,,Name> Create date: <Create Date, ,> Description: <Description, ,> # ============================================= **/ |
In our example, we have placed the comments in a structured header at the head of the text of the routine. Here is our next problem: Only the text for Check constraints, Defaults (constraint or stand-alone), stored procedures, scalar functions, ,Replication filter procedures , DML triggers, DDL triggers, inline table-valued functions, table-valued functions, and Views are retained: The comments for tables, indexes and columns are lost. We need a different way of doing this for database objects that don’t support headers. Whereas all .NET objects boil down to code, the same is not true of tables in SQL Server. When you script out a table in SSMS, or via SMO you’ll notice that table build-scripts have lost any comments that you put in them
This may or may not present a problem. It depends on how you develop databases, and how quickly you’d like information about an object. There are two basic ways of developing databases; one where the script is always the primary source, and the other where the database is, at times, considered to be the source. The first method of developing databases involves maintaining one or more build scripts which contain all the comment blocks and inline comments. This is used to generate the database, but the process is never reversed.
The latter happens if you use the GUI tool, usually SQL Server Management Studio (SSMS) , to create or edit a database object. When you wish to update what is in source control, you will need to script out what you’ve done, but you’ll find that tables, indexes and columns will have lost their comments
If the script is always the primary source, then you don’t have a problem; Otherwise, you will have to put your comment or structured header in an ‘extended property’ of the table.
Extended properties
There are problems in using ‘Extended Properties’ as an alternative to structured headers, because they don’t support lists or hierarchies. Even if you define extra properties to store different types of information such as ‘summary’ or ‘remark’, you still face problems with lists, such as revision lists, since one cannot have more than one instance of any particular extended property. If, therefore, you need to describe the parameters that you pass to routines, give examples of their use, give a revision history of the routine and so on, then it suddenly all gets more difficult unless you store the information in a structure and store that structure in an extended property. In other words, you can use ‘Extended Properties, but only if you use it merely to contain the structure.
SSMS allows you to create other extended properties besides MS_Documentation. Here is a shot of me editing a ‘documentation’ extended property to a PERSON table in SSMS (right click on the table whose documentation you want to alter in the object browser, and click on properties. In the left-hand side of the properties window, click on ‘extended properties’. Click on the ‘three-dots’ icon on the right hand side of the property you wish to edit, or the bottom-most one to create a new one.)
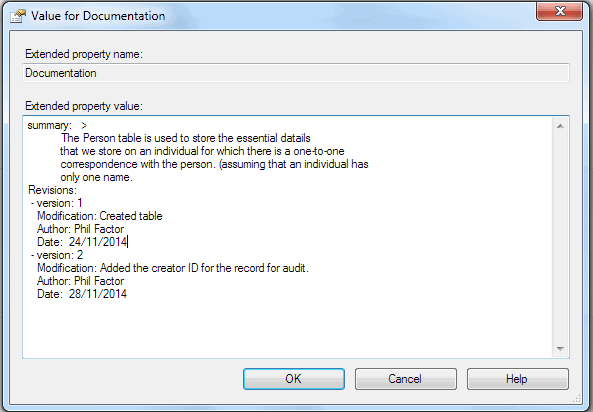
SSMS is fine for maintaining this type of extended property. SQL Doc will display this as well but cannot parse it
Here’s an example of how you might place it in a build script.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 |
CREATE TABLE [dbo].[Person]( [Person_id] [int] IDENTITY(1,1) NOT NULL, [Title] [varchar](20) NOT NULL, [FirstName] [nvarchar](50) NOT NULL, [NickName] [nvarchar](50) NOT NULL, [LastName] [nvarchar](50) NOT NULL, [DateOfBirth] [datetime] NULL, [insertiondate] [datetime] NOT NULL, [terminationdate] [datetime] NULL, [Creator_ID] [int] NOT NULL, [ CONSTRAINT [PK_dbo_Person] PRIMARY KEY CLUSTERED ( [Person_id] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] GO EXEC sys.sp_addextendedproperty @name=N'Documentation', @value=N'primary key for the table' , @level0type=N'SCHEMA',@level0name=N'dbo', @level1type=N'TABLE',@level1name=N'Person', @level2type=N'COLUMN',@level2name=N'Person_id' GO EXEC sys.sp_addextendedproperty @name=N'Documentation', @value=N'Creator of the record' , @level0type=N'SCHEMA',@level0name=N'dbo', @level1type=N'TABLE',@level1name=N'Person', @level2type=N'COLUMN',@level2name=N'LastName' GO EXEC sys.sp_addextendedproperty @name=N'Documentation', @value=N'Date the record was created (automatic)' , @level0type=N'SCHEMA',@level0name=N'dbo', @level1type=N'TABLE',@level1name=N'Person', @level2type=N'COLUMN',@level2name=N'insertiondate' GO EXEC sys.sp_addextendedproperty @name=N'Documentation', @value=N'Date for the termination of the record' , @level0type=N'SCHEMA',@level0name=N'dbo', @level1type=N'TABLE',@level1name=N'Person', @level2type=N'COLUMN',@level2name=N'terminationdate' GO EXEC sys.sp_addextendedproperty @name=N'Documentation', @value=N' summary: > The Person table is used to store the essential datails that we store on an individual for which there is a one-to-one correspondence with the person. (assuming that an individual has only one name. Revisions: - version: 1 Modification: Created table Author: Phil Factor Date: 24/11/2014 - version: 2 Modification: Added the creator ID for the record for audit. Author: Phil Factor Date: 28/11/2014 ' , @level0type=N'SCHEMA',@level0name=N'dbo', @level1type=N'TABLE',@level1name=N'Person' GO EXEC sys.sp_addextendedproperty @name=N'Documentation', @value=N'The identifier of a person' , @level0type=N'SCHEMA',@level0name=N'dbo', @level1type=N'TABLE',@level1name=N'Person' GO ALTER TABLE [dbo].[Person] ADD CONSTRAINT [DF_Person_Title] DEFAULT ('') FOR [Title] GO ALTER TABLE [dbo].[Person] ADD CONSTRAINT [DF_Person_FirstName] DEFAULT ('') FOR [FirstName] GO ALTER TABLE [dbo].[Person] ADD CONSTRAINT [DF_Person_NickName] DEFAULT ('') FOR [NickName] GO ALTER TABLE [dbo].[Person] ADD CONSTRAINT [DF_Person_creator] DEFAULT (user_name()) FOR [LastName] GO ALTER TABLE [dbo].[Person] ADD CONSTRAINT [DF_Person_insertiondate] DEFAULT (getdate()) FOR [insertiondate] GO |
Now we are able to attach documentation to all our database objects. With extended properties, you can now document almost any conceivable database object, except for Full-text objects, objects outside the database scope such as HTTP end points, unnamed objects such as partition function parameters, certificates, symmetric keys, asymmetric keys, and credentials and system-defined objects such as system tables, catalog views, and system stored procedures. That’s quite sufficient for me, anyway.
Why didn’t I use MS_Description? We need some way of distinguishing ordinary comments, and structured headers. I’m always loath to use MS_Description for special purposes because there is always someone, me in this case, who is considering whether to use them for something else.
I provided a stored procedure that creates a table build script that can use both the table and column extended properties called sp_ScriptFor which is available here. It is not a complete table script, but provides enough for exploring a database.
Now, how about reporting from our structured headers? Before we think about parsing the structured information, we have to consider how to extract the extended properties. These were originally accessible only via a rather awkward function called fn_listextendedproperty . Mercifully, Microsoft added a system catalog view called sys.extended_properties that is much easier to use. The extended properties that we have called ‘documentation’ in the current database can be extracted for all our tables by means of this SQL
|
1 2 3 4 5 6 7 8 9 10 11 |
SELECT SCHEMA_NAME(tbl.schema_id) AS [Table_Schema], tbl.name AS [Table_Name], p.value FROM sys.tables AS tbl INNER JOIN sys.extended_properties AS p ON p.major_id=tbl.object_id AND p.minor_id=0 AND p.class=1 where p.name like 'Documentation' ORDER BY [Table_Schema] ASC, [Table_Name] ASC |
And you can do the same for the columns with code such as this
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
SELECT SCHEMA_NAME(tbl.schema_id) AS [Table_Schema], tbl.name AS [Table_Name], clmns.name AS [Column_Name, CAST(p.value AS SQL_VARIANT) AS [Value] FROM sys.tables AS tbl INNER JOIN sys.all_columns AS clmns ON clmns.object_id=tbl.object_id INNER JOIN sys.extended_properties AS p ON p.major_id=clmns.object_id AND p.minor_id=clmns.column_id AND p.class=1 where p.name like 'Documentation' ORDER BY [Table_Schema] ASC, [Table_Name] ASC, [Column_ID] ASC, [Name] ASC |
Extracting headers
Having extracted our documentation, what can we do with it? Because we’ve chosen YAML as our standard, purely because of its readability
YAML
YAML, which is a superset of JSON, was first proposed by Clark Evans in 2001. YAML is a recursive acronym for “YAML Ain’t Markup Language”. It is a means of serializing both objects and relational data in a way that is reasonably intuitive. It is intended to be data-oriented notation, rather than document markup. Instead of using delimiters such as quotation marks, brackets, braces, and open/close-brackets, it uses indentation to represent hierarchical information. The specific number of spaces in the indentation is unimportant as long as parallel elements have the same left justification and the hierarchically nested elements are indented further. Strings do not have to be delimited. YAML handles indents as small as a single space, and so achieves better compression than markup languages. One can revert to JSON “inline-style” (i.e JSON-like format) without the indentation, if indentation is inconvenient.
The white space delimiters allow YAML files to be filtered with line oriented commands within grep, awk, perl, ruby, and python.
We can extract the contents of all the headers in a database in a number of different ways. The most obvious way to do it is with PowerShell. I use PowerYAML for parsing YAML, and I use my own ConvertTo-YAML to create headers.
Here is a simple routine that creates a report of all the routines (Procedure, Replication-filter-procedure, view, DML triggers, user functions, and rules) and tables in a database. A SQL Server database contains information about a database object already, and the routine shows how to incorporate that. Where you have used a YAML-based header, it uses that to supplement what it finds from the metadata. The result in PowerShell, ‘$Routines’, is an array of hashtables, each of which represent a routine. This can be converted into an XML fragment and then translated into any required format with XSLT. You can write it into an excel or MS ~Word report, You can use the ConvertTo-YAML with to create a YAML document of the routines that can then be consumed by Ruby or Python and converted into native object formats.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 |
Import-Module PowerYaml.psm1 # import the YAML parser if necessary (get it via PSGET) set-psdebug -strict # catch a few extra bugs $ErrorActionPreference = "stop" # nothing can be retrieved $ServerName = 'MyServer# the server it is on $Database = 'MyDatabase' # the name of the database you want to script as objects $PasswordIfNecessary = 'password=MyPassword; uid=MyName'#leave blank if windows authentication if ($PasswordIfNecessary.Trim() -eq '') {$ConnectionString = 'Integrated Security="True"'} else {$ConnectionString = $PasswordIfNecessary} # and now we create the SQL String that will be executed. $SQL =@" --don't need USE $database as the connection is for this database SELECT CONVERT(NVARCHAR(MAX),Object_SCHEMA_NAME(tbl.OBJECT_ID)+'.'+tbl.name) AS [Name], 'table' AS type_desc, Create_date, Modify_date, COALESCE('/**'+ CONVERT(NVARCHAR(MAX),p.value) + '**/' ,'') AS definition FROM sys.tables AS tbl LEFT OUTER JOIN sys.extended_properties AS p ON p.major_id=tbl.OBJECT_ID AND p.minor_id=0 AND p.class=1 AND p.name LIKE 'Documentation' UNION ALL SELECT CONVERT(NVARCHAR(MAX),Object_schema_name(sys.objects.OBJECT_ID)+'.'+name) AS [name], LOWER(REPLACE(type_desc,'_',' ')) AS type_desc, Create_Date, Modify_date, definition FROM sys.sql_modules INNER JOIN sys.objects ON sys.sql_modules.OBJECT_ID=sys.objects.OBJECT_ID WHERE is_ms_shipped=0 AND name NOT LIKE 'sp[_]%' "@ # create the SqlClient connection $conn = new-Object System.Data.SqlClient.SqlConnection("Server=$Servername;DataBase=$Database;$ConnectionString")# $conn.Open() | out-null #open the connection # We add a handler for the warnings just in case we get one $message = [string]''; $handler = [System.Data.SqlClient.SqlInfoMessageEventHandler] { param ($sender, $event) $global:message = "$($message)`n $($event.Message)" }; $conn.add_InfoMessage($handler); $conn.FireInfoMessageEventOnUserErrors = $true $cmd = new-Object System.Data.SqlClient.SqlCommand($SQL, $conn) $rdr = $cmd.ExecuteReader() $datatable = new-object System.Data.DataTable $datatable.Load($rdr) if ($message -ne '') { Write-Warning $message } # tell the user of any warnings or info messages $Routines = @() #initialise the array of hashtables foreach ($Row in $datatable.Rows) # we read the routines row by row { #pick up any structured headers # if you have picked up SMO headers like this into the actual definition... # /****** Object:UserDefinedFunction [dbo].[fnParseList] Script Date: 05/05/2015 18:21:42 ******/ # you will need to change the regex slightly (it is a bit slower) if ("$($Row['definition'])" -cmatch '(?ism)(?<=/\*\*).*?(?=\*\*/)') { try { # if there is a structured header then... $yaml = Get-Yaml "---`r`n$($matches[0])" #parse the YAML into a hashtable #now add in the information that the databae metadata knows about if (-not $yaml.ContainsKey('Name')) { $yaml.Add('Name', "$($Row['name'])") } if (-not $yaml.ContainsKey('Created')) { $yaml.Add('Created', "$($Row['Create_Date'])") } if (-not $yaml.ContainsKey('Last-modified')) { $yaml.Add('Last-modified', "$($Row['Modify_Date'])") } if (-not $yaml.ContainsKey('Type')) { $yaml.Add('Type', "$($Row['type_desc'])") } } catch { write-warning "could not parse $($Row['name']) `r`n---`r`n$($matches[0])" } } else { #otherwise we just give the information we got from the metadata. $yaml = Get-Yaml @" --- Name: $($Row['name']) Created: $($Row['Create_Date']) Last-modified: $($Row['Modify_Date']) Type: $($Row['type_desc']) "@ } $Routines += $yaml; #and add-in each routine to the array. } # at this point it is game over. We can convert this to whatever form we want #just as an example, we'll do this to list them out foreach ($routine in $routines) { "$($routine.Name) ($($routine.Type)) Created: $($routine.Created) Last modified: $($routine.'Last-modified') -- $($routine.Summary) " } |
Conclusions
It isn’t surprising that the proper documentation of database code has been so neglected by Microsoft or the third-party tool providers. The existing standards of procedural languages are clumsy to use, and the tools that are developed for them cannot be used for database scripts.
YAML, which has always seemed like a solution looking for a problem, has emerged as a perfect means of embedding readable structured, hierarchical information into the script of database objects. Even if the methods of converting this information into help text or intranet sites is currently slightly awkward, the method is useful as it is easy to scan at a glance when you are inspecting the code itself.
This article is updated from a chapter of ‘SQL Server Team-Based Development’ by Phil Factor, Grant Fritchey, Alex Kuznetsov and Mladen Prajdic; Simple Talk Publishing 2010
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved






Load comments