
Dr. Codd introduced the term “theta operators” in his early papers for what a programmer would have called a comparison predicate operator. The large number of data types in SQL makes doing comparisons a little harder than in other programming languages. Values of one data type have to be promoted to values of the other data type before the comparison can be done. SQL is a strongly typed language which means a lot of type castings are not possible – you cannot turn Christmas into a number and find its square root.
The comparison operators are overloaded and will work for numeric, character, and temporal data types. The symbols and meanings for comparison operators are shown in the table below. Thus, the symbol <= means “at most” when the items are numeric, means “collates before or equal to” with character data types and means “no earlier than” with temporal data types.
The comparison operators will return a logical value of TRUE, FALSE or UNKNOWN. The values TRUE and FALSE follow the usual rules and UNKNOWN is always returned when one or both of the operands is a NULL.
SQL Programmers today do not remember the early days when NULLs were controversial. No procedural programming language had anything like this. The closest thing was in spreadsheets where various proprietary conventions existed for missing data.
The early Sybase SQL Server implementation allowed you to write “<expression> = NULL” and have it treated as “<expression> IS NULL”; this became a configuration option. But at the same time, “<expression> <non-equality operator> NULL” would work correctly and return UNKNOWN.
To make things even more confusing, SQL has two different equivalence relations. Let me give you a little math. An equivalence relation takes elements of a set and partitions them into “equivalence classes”. Each element belongs to one and only one class. Given any two elements from the set, you use the equivalence operator to determine if the elements are in the same class or not. The rules are:
|
1 2 3 4 5 |
a = a; idempotent property (a = b) â (b = a); symmetric property (a = b) â§(b = c) â (a = c); transitivity property |
Obviously, good old “equals” is such a relationship. But so does a Modulus function. Think about defining the old Pascal Boolean EVEN() function defined as MOD (x, n) where (n=2).
|
1 2 3 |
EVEN(a) = EVEN(a); (EVEN(a) = EVEN(b)) â(EVEN(b) = EVEN(a)); (EVEN(a) = EVEN(b))⧠(EVEN(b) = EVEN(c)) â(EVEN(a) = EVEN(c)); |
It partitions integers into odd or even numbers. You could do this for any value of (n).
In SQL, when you do a GROUP BY, you get a partitioning, and the NULLs are all put into one group. This was debated in the ANSI X3H2 Committee. If we had used strict equality, each NULL would be its own class and things would be a mess. So we invented grouping. Grouping is handy for many queries and not just for aggregate functions. It has the nice property of getting us back to two valued logic (2VL) and we like that.
This has lead programmers to write expressions to treat NULLs as members of the same equivalence class outside of aggregations. The most common idioms you will see are:
|
1 |
((<exp1> = <expr2) OR (<exp1> IS NULL = <expr2> IS NULL)) |
or
|
1 |
(COALESCE (<exp1>, <absurd value>) = COALESCE (<exp2>, <absurd value>) |
You have to be sure that <absurd value> is just that; something that cannot occur in either expression. Neither of these idioms is easy to read or to write. And until the optimizer gets smarter, they do not compile as well as you might like.
The SQL:2003 Standards added a verbose but useful theta operator.
|
1 |
<expression 1> IS NOT DISTINCT FROM <expression 2> |
is logically equivalent to
|
1 2 3 4 |
((<expression 1> IS NOT NULL AND <expression 2> IS NOT NULL AND <expression 1> = <expression 2>) OR (<expression 1> IS NULL AND <expression 2> IS NULL)) |
The following the usual pattern for adding NOT into SQL constructs,
|
1 |
<expression 1> IS DISTINCT FROM <expression 2> |
is a shorthand for
|
1 |
NOT (<expression 1> IS NOT DISTINCT FROM <expression 2>) |
This double negative was because the IS NOT DISTINCT FROM was defined first. I have no idea why.
The practical problems of missing or unknown data can be deemed to be solved by the use of NULLs as the convention in SQL. Hooray for us! But now the problem is data quality.
Data Quality as The Next Problem
Let me refer you to the work of Larry English, David Loshin, Jack Olson and Tom Redman. There is a good list of books on this topic here.
The basic message is that we have databases full of bad data. This is not a great surprise to anyone who still has a job in IT. I propose that we add a new theta operator to SQL in the next SQL Standard to help with this problem. Let me give the syntax and then explain it:
|
1 |
<fix the mess predicate> ::= <expression 1> SHOULD [NOT] HAVE BEEN <expression 2> |
As usual, we will follow the ANSI SQL Standard convention that:
|
1 |
<expression 1> SHOULD NOT HAVE BEEN <expression 2> |
is equivalent to:
|
1 |
NOT (<expression 1> SHOULD HAVE BEEN <expression 2>) |
Implementation details are left to SQL optimizer writers; we Standards writers are only obligated to provide unambiguous BNF syntax and a narrative description of the effects that uses the “standard speak” requirements.
In the case of SQL, we decided we wanted an LALR(1) grammar. You are probably thinking that you should have been sober when Professor Celko got to that stuff in his compiler writing class. But since I was not sober either, I can forgive you.
The predicate describes itself. But let’s look at this as compared to an equivalence relation. It is idempotent:
|
1 |
a SHOULD HAVE BEEN a |
This says that we trust the data; it looks good. The symmetric and transitivity properties do not apply. Constants can appear on either side, so this is asymmetric, like the LIKE predicate.
The first purpose of the predicate is to allow us to use bad data in queries, insert, update and delete statements. However it is useful in DDL CHECK() constraints.
Windowed Aggregate Functions
The rule for NULLs is that they are dropped from Aggregate functions. That is to compute the SUM([ALL | DISTINCT] <expression>), AVG([ALL | DISTINCT] <expression>), MIN([ALL | DISTINCT] <expression>), MAX([ALL | DISTINCT] <expression>) and COUNT([ALL | DISTINCT] <expression>) first drop all of the NULLs, then drop redundant duplicate values if DISTINCT is specified and finally the function is performed.
The regular aggregate functions can now take a window clause.
|
1 2 3 4 5 6 7 8 |
<aggregate function> OVER([PARTITION BY <column list>] [ORDER BY <sort column list>] [<window frame>] [FUDGE TO <expression> [<fudge factor>]] --- proposed extension ) <fudge factor> ::= PLUS OR MINUS <expression> |
They are easier to explain with the help of a diagram.
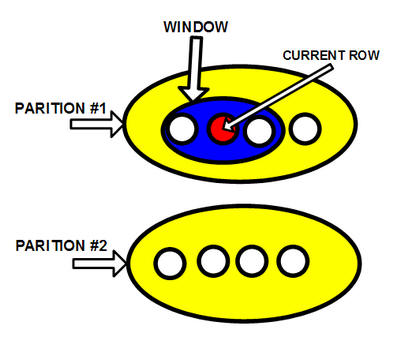
The Window Clause
The window clause is also called the OVER() clause informally. It is an extension for aggregate functions. The idea is that the table is first broken into partitions with the PARTITION BY subclause. The partitions are then sorted by the ORDER BY clause. An imaginary cursor sits on the current row where the windowed function is invoked. A subset of the rows in the current partition is defined by the number of rows before and after the current row by the [ROW | RANGE] subclause. Finally, the subset is passed to an aggregate or ordinal function to return a scalar value.
PARTITION BY Subclause
A set of column names specifies the partitioning, which is applied to the rows that the preceding FROM, WHERE, GROUP BY, and HAVING clauses produced. If no partitioning is specified, the entire set of rows composes a single partition and the aggregate function applies to the whole set each time. Though the partitioning looks a bit like a GROUP BY, it is not the same thing. A GROUP BY collapses the rows in a partition into a single row. The partitioning within a window, though, simply organizes the rows into groups without collapsing them.
ORDER BY Subclause
The ordering within the window clause is like the ORDER BY clause in a CURSOR. It includes a list of sort keys and indicates whether they should be sorted ascending (ASC) or descending (DESC). The important thing to understand is that ordering is applied within each partition.
|
1 2 3 4 5 6 7 8 9 |
<sort specification list>::= <sort specification> [{,<sort specification>}...] <sort specification>::= <sort key> [<ordering specification>] [<null ordering>] <sort key>::= <value expression> <ordering specification>::= ASC | DESC <null ordering>::= NULLS FIRST | NULLS LAST |
The NULLS FIRST and NULLS LAST options are trickier than they first look, but T-SQL does not have them yet so do not panic yet.
Window Frame Subclause
The tricky one is the window frame. T-SQL does not have it yet and many MVPs want Microsoft to catch with DB2 and Oracle. Here is the BNF, but you really need to see code for it to make sense.
|
1 2 3 4 |
<window frame clause>::= <window frame units> <window frame extent> [<window frame exclusion>] <window frame units>::= ROWS | RANGE |
RANGE works with a single sort key. It is for data that is a little fuzzy on the edges, if you will. If ROWS is specified, then sort list is made of exact numeric with scale zero.
|
1 2 3 4 5 6 |
<window frame extent>::= <window frame start> | <window frame between> <window frame start>::= UNBOUNDED PRECEDING | <window frame preceding> | CURRENT ROW <window frame preceding>::= <unsigned value specification> PRECEDING |
If the window starts at UNBOUNDED PRECEDING, then the lower bound is always the first row of the partition; likewise, CURRENT ROW explains itself. The <window frame preceding> is an actual count of preceding rows.
|
1 2 3 |
<window frame bound>::= <window frame start> | UNBOUNDED FOLLOWING | <window frame following> <window frame following>::= <unsigned value specification> FOLLOWING |
If the window starts at UNBOUNDED FOLLOWING, then the lower bound is always the last row of the partition; likewise, CURRENT ROW explains itself. The <window frame following> is an actual count of following rows.
|
1 2 3 4 5 6 |
<window frame between>::= BETWEEN <window frame bound 1> AND <window frame bound 2> <window frame bound 1>::= <window frame bound> <window frame bound 2>::= <window frame bound> |
FUDGE TO Subclause
The windowed functions need to be extended to handle bad data, just as we are doing with the SHOULD HAVE BEEN comparison operator. This is handled by the proposed FUDGE TO subclause.
Imagine that you want to do a sum and to keep it simple let’s ask “What is two plus two?”
A Liberal Arts major will tell you that it is 22. A social worker will tell you that they don’t know the answer but that they are very glad that we had the opportunity to discuss it. They are both useless.
An engineer will tell you the answer is somewhere between 3.999 and 4.001 because of floating point errors. A SQL programmer will tell you it is four because of integer math. These are useful, but only if you have clean data.
The new FUDGE TO subclauses will look at the normal result value then will adjust it to whatever your boss wants it to be. This uses a fudge factor value arrive at the target values. This is an old informal concept used by accountants and bureaucrats. Formalizing it is an implementation detail.
Future Work
We hope that the research that IBM put into their Watson project (www.ibm.com/watson) can be put into SQL. Watson is the super computer has defeated the two greatest human champs in the history of the television quiz show “Jeopardy” this year.
The goal is to have the compiler read the code and read the comments. When they disagree. It compiled the comments instead of the code.
To celebrate April Fool’s day, Joe wrote this specially-commissioned article that mixes the profound with the silly.
We will be giving away two big prizes for the winners who correctly identify all the April Fool jokes in this article. Please email your solutions to editor@simple-talk.com with the words ‘April Fool’ in the subject line. The two winners will be drawn out of the hat containing the names of the correct entries and will get either a SQL Developer Bundle license worth £895 or a SQL DBA Bundle license worth £825 (please state your preferences) . The next six correct entries will get a NET Reflector VS Pro license worth £60. Winners for the competition must be subscribers to either SQLServerCentral or Simple-Talk. Joe Celko and Phil Factor will, between them, decide on what constitutes a correct entry. Entries by April 3rd 2011.






Load comments