
SQL Server 2012 has introduced a brand-new feature called ‘Selective XML Indexes’, available in the SP1 update. Selective XML indexes work to extend the existing XML indexing options by offering what can be a much more efficient indexing solution. Selective XML indexes have the benefits of standard XML indexes, but have a dramatically reduced storage and maintenance requirement. They can be customized during creation to accommodate specific types of XML queries.
How Are Selective XML Indexes Different?
One of the main compromises of using standard XML indexes is that you’re likely to have to use huge amounts of disk space to store the index. When a standard XML index is created, the entire XML document or fragment is shredded to provide a relational version of the data because a relational index table is actually created from the nodes in the XML document. This index table is usually many times larger than the original size of the XML document. Even if you only need to query certain nodes or paths, the XML indexing process shreds all portions of the document. Selective XML indexes, however, shred only the node paths of the XML document that are explicitly specified on index creation – thereby greatly reducing the index overhead in terms of storage space and creation time. Therefore, the main advantages of using a selective XML index over standard XML indexes are:
- Greatly decreased storage requirements
- Greatly decreased index creation times
- Greatly decreased index maintenance costs
Selective XML Index Basics
To demonstrate the advantages of selective XML indexes, let’s run a script that will generate an XML representation of the SalesOrderHeader and SalesOrderDetails tables from the AdventureWorks2012 sample database:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
--create database and table to hold generated xml data CREATE DATABASE Sales_XML GO CREATE TABLE Sales_XML.dbo.SalesOrdersData ( ID INT PRIMARY KEY, SalesOrdersDetail XML ) GO --use AdventureWorks2012 sample database to generate xml data DECLARE @counter INT = 1 DECLARE @row VARCHAR(MAX) --for each sales order (SalesOrderHeader record), find all associated line items (SalesOrderDetail records) WHILE @counter <= (SELECT COUNT(*) FROM AdventureWorks2012.Sales.SalesOrderHeader) BEGIN WITH Orders AS ( --use ROW_NUMBER() to enumerate SalesOrderHeader records SELECT ROW_NUMBER() OVER(ORDER BY SalesOrderID) AS RowNum, * FROM AdventureWorks2012.Sales.SalesOrderHeader ) SELECT @row = ( SELECT o.SalesOrderID AS '@ID', o.OrderDate, o.PurchaseOrderNumber, o.SalesPersonID, ( --associated SalesOrderDetail records SELECT d.SalesOrderDetailID AS '@ID', d.OrderQty, d.rowguid AS 'RowGUID', d.ProductID, d.LineTotal, d.UnitPrice FROM AdventureWorks2012.Sales.SalesOrderDetail AS d WHERE o.SalesOrderID = d.SalesOrderID FOR XML PATH('SalesOrderDetail'), TYPE ) AS SalesOrderDetails FROM Orders AS o WHERE o.RowNum = @counter FOR XML PATH('SalesOrder'), ROOT('SalesOrders') ) INSERT Sales_XML.dbo.SalesOrdersData VALUES(@counter, CONVERT(XML,@row)) SET @counter += 1 END |
The reason we’ve added the ‘ID’ column to our new Sales_XML table is because a primary key is required in order to use selective XML indexes. After we’ve run the above script, let’s take a look at a random XML fragment:
|
1 2 3 4 5 |
--get a random record from the new XML table SELECT TOP 1 SalesOrdersDetail FROM Sales_XML.dbo.SalesOrdersData ORDER BY NEWID() GO |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
<SalesOrders> <SalesOrder id="gt;" <Orderdate>2008-03-30T00:00:00</Orderdate> <SalesOrderDetails> <SalesOrderDetail id="gt;"> <OrderQty>1</OrderQty> <RowGUID>E55F8171-2B62-43D1-8A53-EE83F057D08</RowGUID> <ProductID>878</ProductID> <LineTotal>21.980000</LineTotal> <UnitPrice>21.9800</UnitPrice> </SalesOrderDetail> <SalesOrderDetail id="gt;"> <OrderQty>1</OrderQty> <RowGUID>7CE490FB-D798-41C9-B893-F0D6124880F8</RowGUID> <ProductID>716</ProductID> <LineTotal>49.990000</LineTotal> <UnitPrice>49.9900</UnitPrice> </SalesOrderDetail> </SalesOrderDetails> </SalesOrder> </SalesOrders> |
You’ll notice that the XML fragment contains relevant data from the SalesOrderHeader record, combined with data from all associated SalesOrderDetail records. In this case, there are two associated SalesOrderDetail records. We can quickly verify that this is an accurate count by checking the originating table:
|
1 2 3 4 5 |
--cross-check the number of detail records SELECT SalesOrderDetailID, ProductID FROM AdventureWorks2012.Sales.SalesOrderDetail WHERE SalesOrderID = 67180 GO |
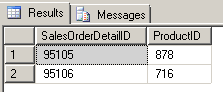
There are indeed two SalesOrderDetail records for SalesOrderID 67180. We will also check to see that a record has been generated for every sales order (SalesHeaderOrder record):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
--find count of matching SalesOrderIDs between original header record SalesOrderIDs and new xml record SalesOrderIDs SELECT COUNT(*) FROM ( SELECT SalesOrdersDetail.value('(//SalesOrder/@ID)[1]', 'varchar(20)') AS SalesOrderID FROM Sales_XML.dbo.SalesOrdersData ) x JOIN AdventureWorks2012.Sales.SalesOrderHeader a ON a.SalesOrderID = x.SalesOrderID GO --compare to count of ALL header records SELECT COUNT(*) FROM AdventureWorks2012.Sales.SalesOrderHeader GO |
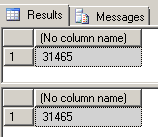
This verifies that there exists an XML fragment (containing all related SalesOrderDetail records) in the new Sales_XML table for every SalesOrderID in the SalesOrderHeader table.
Now that we have XML data, we can start experimenting with a selective XML index. Although we are only allowed to have one selective XML index per XML column, we can customize a single index to work with several types of XML queries. Initially, let’s plan on writing queries that filter the XML fragments by SalesPersonID, like the following:
|
1 2 3 4 5 |
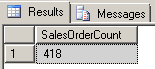
--get sales order count for a given salesperson SELECT COUNT(*) AS SalesOrderCount FROM Sales_XML.dbo.SalesOrdersData WHERE SalesOrdersDetail.exist('/SalesOrders/SalesOrder/SalesPersonID[.=276]') = 1 GO |
This query will give us the number of sales orders that were handled by the salesperson having ID #276. Let’s run the query before we add a selective XML index – but first we’ll SET STATISTICS TIME ON so we can see the query time before and after creating the index:
|
1 2 |
--turn on statistics time SET STATISTICS TIME ON |
Now we’ll run the above ‘sales order count’ query:
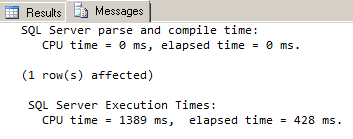
In the Messages tab, we see that the query execution time was 428 ms:
To see if we can speed up this type of query, we’ll create a basic selective XML index:
|
1 2 3 4 5 6 7 8 |
--create a selective XML index CREATE SELECTIVE XML INDEX SXI_Selective_SalesOrdersDetails ON Sales_XML.dbo.SalesOrdersData(SalesOrdersDetail) FOR ( pathSalesPersonID = '/SalesOrders/SalesOrder/SalesPersonID' ) GO |
Note that we’ve customized this index for a specific XQuery path (/SalesOrders/SalesOrder/SalesPersonID’), and we’ve given it a name (pathSalesPersonID). However, we get the following error when running the create index statement:

This is because selective XML indexes must be enabled for each database. To enable selective indexes, use the sp_db_selective_xml_index stored procedure:
|
1 2 |
--enable selective XML indexes for the database EXECUTE Sales_XML.sys.sp_db_selective_xml_index Sales_XML, TRUE |
Interestingly, in order to reverse this, the database must be set to the simple recovery model. If the recovery model is set otherwise, the following message is seen:
|
1 2 |
--disable selective XML indexes for the database EXECUTE Sales_XML.sys.sp_db_selective_xml_index Sales_XML, FALSE |

Now that selective XML indexes are enabled for the Sales_XML database, we can run the create index script again, and we can also check to make sure that the index was created:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
--find all XML indexes in the database USE Sales_XML GO SELECT i.name as IndexName, o.name as TableName, c.[name] as ColumnName FROM sys.indexes i JOIN sys.objects o ON i.object_id = o.object_id JOIN sys.index_columns ic ON ic.object_id = i.object_id AND ic.index_id = i.index_id JOIN sys.columns c ON c.object_id = i.object_id AND c.column_id = ic.column_id WHERE i.type_desc = 'XML' AND is_disabled = 0 GO |

The index exists. We can also verify that it is a selective XML index by expanding the Indexes node for the table in Object Explorer:
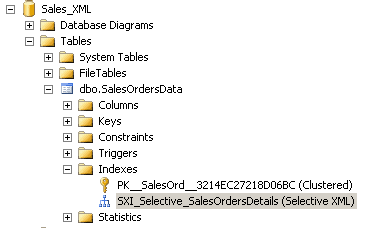
Let’s run our query again:
|
1 2 3 4 5 |
--get sales order count for a given salesperson SELECT COUNT(*) AS SalesOrderCount FROM Sales_XML.dbo.SalesOrdersData WHERE SalesOrdersDetail.exist('/SalesOrders/SalesOrder/SalesPersonID[.=276]') = 1 GO |
We now see a greatly reduced query execution time:
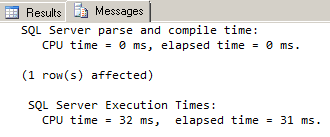
That’s a reduction in query execution time by more than 90%!
Selective XML Index Optimizations
Selective XML indexes make allowances for some fine-tuning customizations of path specifications, using either XQuery or SQL Server data types (for untyped XML). By using XQuery data types, we can take advantage of what is called ‘user-specified mapping mode’. In this mode, optional optimization hints and XQuery data types are defined, in addition to the XQuery path specifications. When default mapping mode is used, only the path is specified. SQL Server data types, on the other hand, are designed to efficiently handle return values from the XQuery value() method. Although better query performance can be expected when using optimization hints on untyped XML, there is a risk of failed cast operations. This is because the index assumes that data of the correct type will be present in the path, when this may not always be the case. By using default mapping mode (no optimization hints), one can guarantee that there will be no cast operation failures. In the case of typed XML, there is no reason to specify the data type, as data types are discovered by using the schema.
We’re using untyped XML, so let’s try to improve our query execution time by adding an optimization hint. Before we specify an appropriate hint, we will need to define an XQuery data type for the SalesPersonID node.
The available XQuery types for untyped XML are:
- xs:boolean
- xs:double
- xs:string
- xs:date
- xs:time
- xs:dateTime
Notice that there is no xs:integer type. We’ll use the closest available type, xs:double. Also, since we are familiar with our data, we know that there is always only one SalesPersonID node in its parent (SalesOrder node). This will allow us to implement the SINGLETON optimization hint. The SINGLETON hint expects that a node appears only once inside its parent node. Again, as with data type casting, there is a slight risk of failure if the SINGLETON hint is used where there may be more than one node (of its kind) in a parent node.
Before we recreate our index to include our optimization hint, let’s record the current size of the index:
|
1 2 |
--check index size EXEC sp_spaceused |
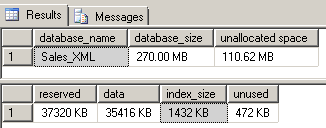
The current index size is 1432 KB. We’ll now drop the selective index and recreate it, this time using an XQuery type and optimization hint:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
--drop selective XML index DROP INDEX SXI_Selective_SalesOrdersDetails ON SalesOrdersData GO --recreate selective XML index using optimization hint CREATE SELECTIVE XML INDEX SXI_Selective_SalesOrdersDetails ON Sales_XML.dbo.SalesOrdersData(SalesOrdersDetail) FOR ( pathSalesPersonID = '/SalesOrders/SalesOrder/SalesPersonID' AS XQUERY 'xs:double' SINGLETON ) GO |
Does this optimization improve our query speed? Let’s check it by running our sales order count query once again:
|
1 2 3 4 5 |
--get sales order count for a given salesperson SELECT COUNT(*)AS SalesOrderCount FROM Sales_XML.dbo.SalesOrdersData WHERE SalesOrdersDetail.exist('/SalesOrders/SalesOrder/SalesPersonID[.=276]') = 1 GO |
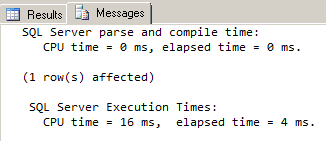
This shows a reduction in query time by almost another 90%, down to 4 ms! We can see how important it is to tune the index by using appropriate optimization hints. A quick index size check reveals only a tiny storage cost increase (8 KB) that is offset by a huge performance gain:
|
1 2 |
--check index size EXEC sp_spaceused |
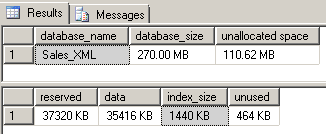
Adding Additional XQuery Paths to the Index
Suppose that we must also support slightly more complex queries that find PurchaseOrderNumbers for a given salesperson, using our existing selective index. We’ll be dealing with queries that look like this:
|
1 2 3 4 5 |
--get purchase order numbers for all sales orders owned by a given salesperson SELECT SalesOrdersDetail.value('(/SalesOrders/SalesOrder/PurchaseOrderNumber)[1]','varchar(13)') AS PurchaseOrderNumber FROM Sales_XML.dbo.SalesOrdersData WHERE SalesOrdersDetail.exist('/SalesOrders/SalesOrder/SalesPersonID[.=276]') = 1 GO |
Before we do anything to our existing selective index, let’s see how this query performs with the current index configuration:
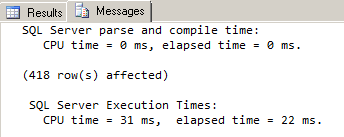
Remember how we mentioned that you can handle XQuery value() method return values effectively by using SQL Server data types in a selective index path? Let’s try using a SQL Server data type here, instead of an XQuery data type. We can still use an optimization hint in conjunction with the SQL Server data type. We don’t have to start over with our index; all we have to do is add a new path:
|
1 2 3 4 5 6 7 8 9 |
--add a second path specification for the selective index ALTER INDEX SXI_Selective_SalesOrdersDetails ON Sales_XML.dbo.SalesOrdersData FOR ( ADD pathPurchaseOrderNumber = '/SalesOrders/SalesOrder/PurchaseOrderNumber' AS SQL VARCHAR(13) SINGLETON ) GO |
You’ll have seen that we defined the SQL Server data type as VARCHAR(13). This is because the maximum length of any existing PurchaseOrderNumber is 13 (If we expect that there could be future data with longer PurchaseOrderNumber values, we would want to allow for this by using a larger VARCHAR size).
|
1 2 3 4 |
--find max length of all existing purchase order numbers SELECT MAX(LEN(PurchaseOrderNumber)) FROM AdventureWorks2012.Sales.SalesOrderHeader GO |
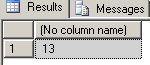
Since there is always just one PurchaseOrderNumber node in its parent, we can use the SINGLETON hint once again in this new path. Now that we’ve added a second path to our selective XML index, let’s run our query again, and see if the new path specification will reduce our current query execution time (22 ms):
|
1 2 3 4 5 |
--get purchase order numbers for all sales orders owned by a given salesperson SELECT SalesOrdersDetail.value('(/SalesOrders/SalesOrder/PurchaseOrderNumber)[1]','varchar(13)') AS PurchaseOrderNumber FROM Sales_XML.dbo.SalesOrdersData WHERE SalesOrdersDetail.exist('/SalesOrders/SalesOrder/SalesPersonID[.=276]') = 1 GO |
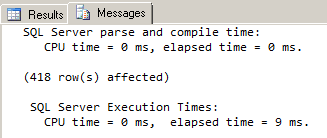
The addition of the second path specification has reduced the execution time by more than 50%.
Storage Savings
Our current index storage cost, which includes two path specifications and associated hints, is 1536 KB:
|
1 2 |
--check index size EXEC sp_spaceused |
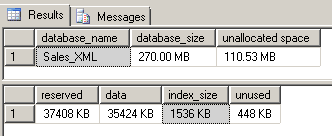
Let’s take a look at what our storage cost would have been if we had used a primary XML index instead of a selective XML index. Remember, standard XML indexes shred and index the entire XML document, instead of only the specific paths that will be used for queries, as selective indexes do. Let’s replace our selective index with a primary XML index to see what our hypothetical storage savings are:
|
1 2 3 4 5 6 7 8 9 10 11 |
--drop the existing selective XML index DROP INDEX SXI_Selective_SalesOrdersDetails ON SalesOrdersData GO --create a standard primary XML index CREATE PRIMARY XML INDEX IX_Primary_SalesOrdersDetails ON Sales_XML.dbo.SalesOrdersData(SalesOrdersDetail) GO --check index size EXEC sp_spaceused |
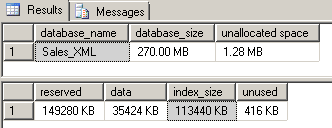
A huge increase in storage space is seen. So, by using a selective XML index instead of an ordinary primary XML index, we’ve reduced our storage cost by over 98%.
Requirements/Limitations
Some prerequisites and limitations regarding selective XML indexes include:
- A clustered index and a primary key are required on the table that a selective XML index is created on. If a selective index creation is attempted on a table with no primary key, the following error will result:

- Each XML column in a table can have only one selective XML index. Conversely, a selective XML index must be created to index only one column. In other words, an XML column can have at most one selective index, and a single selective index cannot span multiple XML columns. However, a table can contain up to 249 selective indexes.
When Not to Use Selective XML Indexes
Microsoft recommends using selective XML indexes for most XML query operations. However, if you find that a large number of node paths need to be mapped in the selective index, you may benefit more from standard XML indexes than selective indexes. Also, selective indexes are not recommended if your queries search for unknown elements or unknown node locations.
Summary
We’ve gone over some operations involving basic uses of selective XML indexes. We’ve used examples that showed the advantages to using selective XML indexes over standard XML indexes – we saw that index storage and creation time costs are greatly reduced with selective indexes. We also implemented optimization hints, and discovered how they can considerably increase index performance. Finally, we looked into some of the basic prerequisites to using selective indexes, such as the clustered primary key requirement, and the one-selective-index-per-column limitation.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments