
Although relational division is defined in the relational algebra, it can be a challenging query for anyone, however experienced they are with SQL. Although it is the most effective way of tackling many database tasks, it is difficult enough just to identify those particular business requirements that are best solved by relational division. We’ll be trying to help with this, and also provide some code patterns that can be used to deliver high-performance results.
Relational division is the method that is used, for example, to identify:
- Candidates for a job requirement having the skills that job requires (the primary example used in this article).
- Orders containing only a specific subset of items.
- Customers that have an operating area in two or more specific locations.
- Parts that are shared across many Bills of Material (BOMs).
- Users that have the same distinct set of licensed software, e.g., MS Office, Windows XP and MS Visual Studio, installed on their machines.
In this article, I’ll be suggesting that the performance of almost every solution to relational division can be improved by reducing the rows as much as possible before applying the final logic.
While doing the research for this article, I stumbled across Divided We Stand: The SQL of Relational Division by renowned SQL author Joe Celko as published on Simple Talk. We’ll draw heavily on his examples of relational division because he does an excellent job of explaining them. We will change our data structures to offer you an alternative picture, in the hopes that additional examples may help to make it all clearer.
Problem Scenario and Data Setup
Firstly, we’ll need to create some sample data that we can use for most of the problems we’ll be exploring in this article. If you would like to follow along without having to copy/paste the queries from this article, you can download the attached resource file: 01 CandidatesSkills Sample Queries.sql, which contains all the sample queries related to our first example.
Let’s suppose you are a recruiting company. In your database you might have, in addition to a list of candidates and a list of all the skills your many clients are interested in (e.g., SQL, SSIS, SSRS, etc.), a table you might call CandidatesSkills. This is a mapping table of candidates to the skills they possess.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
CREATE TABLE dbo.CandidatesSkills ( CandidateID INT ,SkillID INT ,CONSTRAINT cs_pk1 PRIMARY KEY(CandidateID, SkillID) ,CONSTRAINT cs_ix1 UNIQUE NONCLUSTERED(SkillID, CandidateID) ); INSERT INTO dbo.CandidatesSkills (CandidateID, SkillID) VALUES (1, 1), (1, 2), (1, 3), (1, 4) ,(2, 2), (2, 3), (2,4) ,(3, 5), (3,6), (3,7) ,(4, 1), (4,3), (4, 4), (4, 7) ,(5, 1), (5, 7); SELECT * FROM dbo.CandidatesSkills; |
We’ll use, as is customary, IDs for both candidates and skills; but we will omit the related tables for Candidates and Skills because they’re not relevant to our focus. In relational division, the CandidatesSkills table is called the dividend table. This table needs good indexing to make any of the proposed queries in our article perform well.
We’ll now further suppose that a client comes along with a job opening, and for that job opening he has a list of skills that he seeks. He is one of our more demanding clients, so he insists that any candidate we present must have all of his listed skills. Let’s put this into a helper table, which in terms of relational division, is the divisor table.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
DECLARE @JobRequirements TABLE ( JobID INT ,RequirementID INT ,SkillID INT ,PRIMARY KEY (JobID, RequirementID, SkillID) ); INSERT INTO @JobRequirements (JobID, RequirementID, SkillID) VALUES (1, 1, 2), (1, 2, 3), (1, 3, 4); SELECT * FROM @JobRequirements; |
Let’s now compare our sample data (candidates with their skills) to our requirement and identify the cases of relational division.
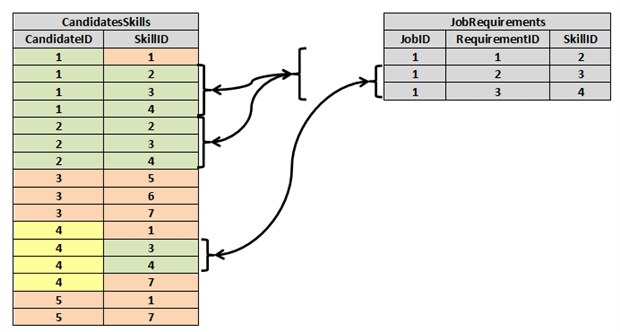
We have five candidates that seem to have relevant skills.
- Candidate 1 possesses all three required skills plus one additional
- Candidate 2 possesses only the three required skills
- Candidates 3 and 5 possess none of the required skills
- Candidate 4 possesses only two of the three required skills
Since Candidate 2 possesses only the required skills and no more, matching that candidate to the job posting is Relational Division with No Remainder (RDNR). Candidate 1 possesses the required skills plus one more, so this is known as Relational Division With Remainder (RDWR), the remainder being the one additional skill that is not required. One could argue that since Candidate 4 fulfills two of the three requirements, this could be a case of relational division as well; but we’ve excluded that case because our client demanded that all required skills are possessed in order to qualify a candidate.
Relational Division with Remainder (RDWR)
Joe Celko provided two solutions to this problem in the referenced article. He indicated that one of them performs better than the other, and I agree. That solution is as follows:
|
1 2 3 4 5 6 |
-- Joe Celko's Solution #2 for RDWR SELECT a.CandidateID FROM dbo.CandidatesSkills a, @JobRequirements b -- A CROSS JOIN in disguise WHERE a.SkillID = b.SkillID GROUP BY a.CandidateID HAVING COUNT(a.SkillID) = (SELECT COUNT(SkillID) FROM @JobRequirements); |
It is interesting to note that in the article’s discussion thread SQL MVP Peter Larsson, who may be better known for his posts under the monikers PESO or SWEPESO, came along and suggested that there’s a faster solution to the RDWR problem which he posted in his Thinking Outside the Box blog entry named Proper Relational Division with Sets. In fact, the solution that he suggested for this problem is versatile enough to solve either of the RDWR or RDNR problems (refer to the comment on the last line of code to see how).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
-- Peter Larsson (PESO) Solution for RDNR/RDWR SELECT CandidateID FROM ( SELECT t.CandidateID ,cnt=SUM(CASE WHEN t.SkillID = n.SkillID THEN 1 ELSE 0 END) ,Items=COUNT(*) FROM dbo.CandidatesSkills AS t CROSS JOIN @JobRequirements AS n GROUP BY t.CandidateID, t.SkillID ) d GROUP BY CandidateID HAVING SUM(cnt) = MIN(Items) AND MIN(cnt) >= 0; -- 1 means no remainder, 0 means remainder |
Both of these solutions yield the following results based on our sample data, which by simply reviewing the graphic we provided earlier you’ll see is correct:
|
1 2 3 |
CandidateID 1 2 |
It is, of course, important to test out your solution on a large set of data once you are satisfied that it is correct. For this purpose, we have provided a script in the attached resources files (02 Create Large CandidatesSkills Tables.sql) that interested readers can use to create two large tables of CandidatesSkills to support testing the performance of these two solutions. The results you get from these may depend to a certain extent on the dispersion of the data points within your data.
Is this the final word? Later on in this article I’ll show a technique that can be applied in conjunction with either of these solutions that can improve the performance of both.
Relational Division with no Remainder (RDNR)
For the case of RDNR, Joe also provided a solution in his article. In PESO’s blog, he actually expanded that solution set to four, presumably based on correspondence with Joe. According to my testing, the fastest of those was this one. You can try to reproduce these results for yourself using 03 Test of RDNR Solutions at 1M Rows.sql.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
SELECT D1.CandidateID FROM dbo.CandidatesSkills D1 WHERE D1.SkillID IN (SELECT SkillID FROM @JobRequirements) GROUP BY D1.CandidateID HAVING COUNT(DISTINCT D1.SkillID) = ( SELECT COUNT(*) FROM @JobRequirements ) AND COUNT(DISTINCT D1.SkillID) = ( SELECT COUNT(*) FROM dbo.CandidatesSkills D2 WHERE D2.CandidateID = D1.CandidateID ); |
When I looked at this, a slight improvement came to mind and testing confirmed that this variant is slightly faster.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
SELECT CandidateID FROM ( SELECT D1.CandidateID, cnt=COUNT(DISTINCT D1.SkillID) FROM dbo.CandidatesSkills D1 WHERE D1.SkillID IN (SELECT SkillID FROM @JobRequirements) GROUP BY D1.CandidateID ) a WHERE a.cnt = (SELECT COUNT(*) FROM @JobRequirements) AND a.cnt = ( SELECT COUNT(*) FROM dbo.CandidatesSkills D2 WHERE D2.CandidateID = a.CandidateID ); |
Also in his blog, PESO provided a solution that represents a collaboration between him and SQL MVPAdam Machanic.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
SELECT t.CandidateID FROM ( SELECT CandidateID, cnt=COUNT(*) FROM dbo.CandidatesSkills GROUP BY CandidateID ) kc INNER JOIN ( SELECT cnt=COUNT(*) FROM @JobRequirements ) nc ON nc.cnt = kc.cnt JOIN dbo.CandidatesSkills t ON t.CandidateID = kc.CandidateID JOIN @JobRequirements n ON n.SkillID = t.SkillID GROUP BY t.CandidateID HAVING COUNT(*) = MIN(nc.cnt); |
All three of these solutions produce the expected result from our sample data, which is:
|
1 2 |
CandidateID 2 |
Once again, we are not here today to compare how these solutions perform against each other. Instead we will now provide you a method whereby any of the solutions proposed so far (we’ll refer to these as the base queries) can be improved for huge row sets.
Improving Upon Relational Division with and without Remainder
Consider the query below, which we’ve built specifically to identify candidates that meet, some but not necessarily all, of the divisor criteria.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
-- Retrieve the first three job requirements SELECT @SID1=MAX(CASE WHEN RequirementID = 1 THEN SkillID END) ,@SID2=MAX(CASE WHEN RequirementID = 2 THEN SkillID END) ,@SID3=MAX(CASE WHEN RequirementID = 3 THEN SkillID END) FROM @JobRequirements; SELECT a.CandidateID, b.SkillID FROM ( -- Identify candidate matches by row reduction SELECT CandidateID FROM dbo.CandidatesSkills a -- Find rows with a match on the first job requirement WHERE SkillID = @SID1 AND -- Include only rows with a match on the second job requirement EXISTS ( SELECT 1 FROM dbo.CandidatesSkills b WHERE a.CandidateID = b.CandidateID AND SkillID = @SID2 -- Include only rows with a match on the third job requirement ) AND EXISTS ( SELECT 1 FROM dbo.CandidatesSkills b WHERE a.CandidateID = b.CandidateID AND SkillID = @SID3 ) ) a -- Join back to retrieve all the rows for the identified candidates JOIN dbo.CandidatesSkills b ON a.CandidateID = b.CandidateID; |
This produces the following results set:
|
1 2 3 4 5 6 7 8 |
CandidateID SkillID 1 1 1 2 1 3 1 4 2 2 2 3 2 4 |
This result set has some very interesting properties:
- It happens to contain only the CandidateIDs that would satisfy the RDWR and RDNR cases. However if we were looking for more job requirements (>3) then it would also contain additional rows that would need to be further checked to reduce the set down to just the target divisor.
- It contains all of the rows associated with the identified candidates.
- It is very fast with the indexes we created; producing exactly four index seeks in the query plan. Three of those seeks use the non-clustered INDEX on the table.
It does have a flaw however: If we happen to have less than 3 job requirements it won’t work. Let’s fix that and place this interesting new code into a Common Table Expression (CTE).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
WITH ReducedCandidateRows AS ( SELECT a.CandidateID, b.SkillID FROM ( -- Identify candidate matches by row reduction SELECT CandidateID FROM dbo.CandidatesSkills a -- Find rows with a match on the first job requirement WHERE SkillID = @SID1 AND -- Include only rows with a match on the second job requirement -- Short circuit the EXISTS check if <2 elements in divisor (@SID2 IS NULL OR EXISTS ( SELECT 1 FROM dbo.CandidatesSkills b WHERE a.CandidateID = b.CandidateID AND SkillID = @SID2 -- Include only rows with a match on the third job requirement -- Short circuit the EXISTS check if <3 elements in divisor )) AND (@SID3 IS NULL OR EXISTS ( SELECT 1 FROM dbo.CandidatesSkills b WHERE a.CandidateID = b.CandidateID AND SkillID = @SID3 )) ) a -- Join back to retrieve all the rows for the identified candidates JOIN dbo.CandidatesSkills b ON a.CandidateID = b.CandidateID ) SELECT * FROM ReducedCandidateRows; |
This will work even if there are less than three job requirements but at least one, and it still does the same four index seeks. The reason it works is that it “short circuits” the EXISTS check when one of the first three elements is NULL (meaning it doesn’t exist). Even more interesting is that, since all it does is produce a subset of the rows we need to examine, we can combine it with any of the five solutions presented previously for RDNR and RDWR, simply by replacing references to the CandidatesSkills table with a reference to the CTE instead! For example, if we combine it with the PESO+Adam Machanic collaboration for RDNR, we get this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
WITH ReducedCandidateRows AS ( SELECT a.CandidateID, b.SkillID FROM ( -- Identify candidate matches by row reduction SELECT CandidateID FROM dbo.CandidatesSkills a -- Find rows with a match on the first job requirement WHERE SkillID = @SID1 AND -- Include only rows with a match on the second job requirement -- Short circuit the EXISTS check if <2 elements in divisor (@SID2 IS NULL OR EXISTS ( SELECT 1 FROM dbo.CandidatesSkills b WHERE a.CandidateID = b.CandidateID AND SkillID = @SID2 -- Include only rows with a match on the third job requirement -- Short circuit the EXISTS check if <3 elements in divisor )) AND (@SID3 IS NULL OR EXISTS ( SELECT 1 FROM dbo.CandidatesSkills b WHERE a.CandidateID = b.CandidateID AND SkillID = @SID3 )) ) a -- Join back to retrieve all the rows for the identified candidates JOIN dbo.CandidatesSkills b ON a.CandidateID = b.CandidateID ) SELECT t.CandidateID FROM ( SELECT CandidateID, cnt=COUNT(*) FROM ReducedCandidateRows GROUP BY CandidateID ) kc INNER JOIN (SELECT cnt=COUNT(*)FROM @JobRequirements) nc ON nc.cnt = kc.cnt JOIN ReducedCandidateRows t ON t.CandidateID = kc.CandidateID JOIN @JobRequirements n ON n.SkillID = t.SkillID GROUP BY t.CandidateID HAVING COUNT(*) = MIN(nc.cnt); |
This can be confirmed to produce the correct result set for our sample data. We call this the Row Reduction Approach to Relational Division.
In order to truly see the impact this has on performance of the base queries, we really need to ramp up the amount of test data in our harness. This has already been done for you by creating a table (CandidateSkills2) that has approximately 10 million rows in it. We can apply each of the five queries discussed so far with the Row Reduction Approach and graph this using each base query as the basis, meaning that we’ll show the amount of elapsed time used by the Row Reduction Approach as a percentage of the base query. You may reproduce these results by running 04 With and Without Row Reduction on 10M Rows.sql.
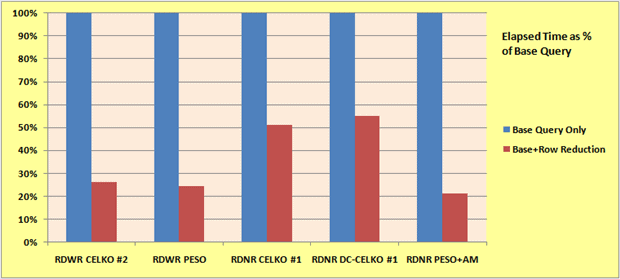
From these results it is clear that the Row Reduction Approach is beneficial in each case, reducing the elapsed time necessary to about 20-55% of that of the base query.
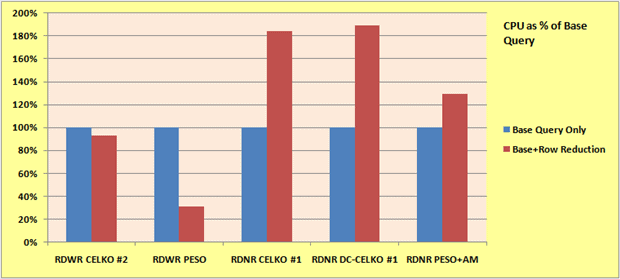
CPU usage is a bit more variable. For the RDWR problem it is generally less while for the RDNR problem generally more (and sometimes nearly twice as much). This may be a valid trade-off for the improvements in elapsed time.
Note once again that we have avoided comparing the raw speed of these five solutions against each other because that may depend on either the dispersal of the data in the dividend table and/or the number of elements to match against in the divisor table. In our case, each row reduction was applied three times. We experimented with more row reductions (up to seven in fact) and found in general that there will be a point of diminishing returns, after which more row reductions unfavorably impacts the elapsed time. The sweet spot with 10M rows of data seems to be around three or four row reductions. It may be a bit higher if you have hundreds of millions or billions of rows in your dividend table.
The bottom line here is that if you do relational division and have a favorite solution for it, using the row reductions technique (for large dividend tables) is very likely to provide you a faster performing solution.
Relational Division with Multiple Divisors
In our problems so far, we’ve been dealing with only a single, target subset of data (the divisor table) where we wish to identify the places where that data exists in our master table (the dividend table). You may be wondering why we included the column JobID in our divisor table; so now you get to find out.
Suppose we actually have two distinct job requirements. We can add the second job requirement to our divisor table like this:
|
1 2 3 4 |
INSERT INTO @JobRequirements (JobID, RequirementID, SkillID) VALUES (2, 1, 1), (2, 2, 7); SELECT * FROM @JobRequirements; |
Now we have the following data in our divisor table.
|
1 2 3 4 5 6 |
JobID RequirementID SkillID 1 1 2 1 2 3 1 3 4 2 1 1 2 2 7 |
As before, depending on whether we want an exact division (RDNR) we’d get for JobID=1 the CandidateID of 2 or for division with remainder (RDWR) for JobID=1 we’d get CandidateIDs 1 and 2. But now we also want to return matches for JobID=2, which are 5 for RDNR and 4/5 for RDWR. In PESO’s blog, he enigmatically suggested that either of the queries he suggested could be modified to handle the case of multiple divisors, so let try to see if we can do that. We’ll choose the one that can be applied to either case.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
SELECT JobID, CandidateID FROM ( SELECT n.JobID, t.CandidateID ,cnt=SUM(CASE WHEN t.SkillID = n.SkillID THEN 1 ELSE 0 END) ,Items=COUNT(*) FROM dbo.CandidatesSkills AS t CROSS JOIN @JobRequirements AS n GROUP BY n.JobID, t.CandidateID, t.SkillID ) d GROUP BY JobID, CandidateID HAVING SUM(cnt) = MIN(Items) AND MIN(cnt) >= 0; -- 1 means no remainder, 0 means remainder |
It is quite easy to demonstrate (for the case shown) that this query returns:
|
1 2 3 4 5 |
JobID CandidateID 1 1 1 2 2 4 2 5 |
It returns the following if MIN(cnt) >= 1.
|
1 2 3 |
JobID CandidateID 1 2 2 5 |
The other queries we’ve discussed can be similarly modified to handle the case of multiple divisors.
The question before us though, is whether our Row Reduction Approach is also applicable. The answer is of course yes, albeit there is a limitation. In order to apply the Row Reduction Approach, we can only do it to the intersection of the job requirements. To make this work, we must modify the query that calculates the three variables we’ll use to do the row reduction to something that looks like this (assigning the intersection of the job requirements to our three variables).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
DECLARE @XID1 INT, @XID2 INT, @XID3 INT; -- Retrieve the first three common job requirements SELECT @XID1=MAX(CASE WHEN RequirementID = 1 THEN SkillID END) ,@XID2=MAX(CASE WHEN RequirementID = 2 THEN SkillID END) ,@XID3=MAX(CASE WHEN RequirementID = 3 THEN SkillID END) FROM ( SELECT SkillID, RequirementID=ROW_NUMBER() OVER (ORDER BY SkillID) FROM @JobRequirements GROUP BY SkillID HAVING COUNT(*) = ( SELECT COUNT(DISTINCT JobID) FROM @JobRequirements ) ) a; |
We have modified the Row Reduction Approach (below) to handle the case where @XID1 can possibly be NULL. You may verify for yourself that the results are the same as before.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
WITH ReducedCandidateRows AS ( SELECT a.CandidateID, b.SkillID FROM ( -- Identify candidate matches by row reduction SELECT CandidateID FROM dbo.CandidatesSkills a -- Find rows with a match on the first job requirement (if a common -- requirement is present) WHERE (@XID1 IS NULL OR SkillID = @XID1) AND -- Include only rows with a match on the second job requirement -- Short circuit the EXISTS check if <2 elements in divisor (@XID2 IS NULL OR EXISTS ( SELECT 1 FROM dbo.CandidatesSkills b WHERE a.CandidateID = b.CandidateID AND SkillID = @XID2 -- Include only rows with a match on the third job requirement -- Short circuit the EXISTS check if <3 elements in divisor )) AND (@XID3 IS NULL OR EXISTS ( SELECT 1 FROM dbo.CandidatesSkills b WHERE a.CandidateID = b.CandidateID AND SkillID = @XID3 )) ) a -- Join back to retrieve all the rows for the identified candidates JOIN dbo.CandidatesSkills b ON a.CandidateID = b.CandidateID ) SELECT JobID, CandidateID FROM ( SELECT n.JobID, t.CandidateID ,cnt=SUM(CASE WHEN t.SkillID = n.SkillID THEN 1 ELSE 0 END) ,Items=COUNT(*) FROM dbo.CandidatesSkills AS t CROSS JOIN @JobRequirements AS n GROUP BY n.JobID, t.CandidateID, t.SkillID ) d GROUP BY JobID, CandidateID HAVING SUM(cnt) = MIN(Items) AND MIN(cnt) >= 0; -- 1 means no remainder, 0 means remainder |
Clearly this limitation becomes more restrictive when you have more divisors; because the more you have, the less likely there will be an intersection that is anything but an empty set. However we’ve shown that it can be done. If there is then an overlap, it should still help to improve the performance of the query when you have a large dividend table.
Todd’s Division
Joe Celko also proposed another relational division problem he called Todd’s Division (because he attributed it to Stephen Todd). Once again, we will re-frame the problem to offer additional insight into the types of business problems that can be addressed.
We’ll start with a ProjectTasks table, which contains multiple projects and the tasks that are required for each. Note that a particular task may overlap various projects.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
CREATE TABLE #ProjectTasks ( ProjectID VARCHAR(10) ,TaskID VARCHAR(10) ,CONSTRAINT pt_pk1 PRIMARY KEY (ProjectID, TaskID) ,CONSTRAINT pt_ix1 UNIQUE NONCLUSTERED (TaskID, ProjectID) ); INSERT INTO #ProjectTasks SELECT 'P1', 'T1' UNION ALL SELECT 'P1', 'T2' UNION ALL SELECT 'P2', 'T2' UNION ALL SELECT 'P2', 'T4' UNION ALL SELECT 'P2', 'T5' UNION ALL SELECT 'P3', 'T2'; |
We also have a ResourceTasks table, which maps resources to tasks. Once again, a task may be assigned to multiple resources.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
CREATE TABLE #ResourceTasks ( ResourceID VARCHAR(10) ,TaskID VARCHAR(10) ,CONSTRAINT rt_pk1 PRIMARY KEY (ResourceID, TaskID) ,CONSTRAINT rt_ix1 UNIQUE NONCLUSTERED (TaskID, ResourceID) ); INSERT INTO #ResourceTasks SELECT 'R1', 'T1' UNION ALL SELECT 'R1', 'T2' UNION ALL SELECT 'R1', 'T3' UNION ALL SELECT 'R1', 'T4' UNION ALL SELECT 'R1', 'T5' UNION ALL SELECT 'R1', 'T6' UNION ALL SELECT 'R2', 'T1' UNION ALL SELECT 'R2', 'T2' UNION ALL SELECT 'R3', 'T2' UNION ALL SELECT 'R4', 'T2' UNION ALL SELECT 'R4', 'T4' UNION ALL SELECT 'R4', 'T5'; |
Our desired results set is a list of projects and the resources that are assigned to them based on which project that resources’ tasks are assigned to.
|
1 2 3 4 5 6 7 8 9 |
ProjectID ResourceID P1 R1 P2 R1 P3 R1 P1 R2 P3 R2 P3 R3 P2 R4 P3 R4 |
Joe Celko suggested that either of the following queries will return the desired results, and further suggested that the second one may be just a little faster in some cases (confirmed by me).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
-- Todd's Division - CELKO 1 SELECT DISTINCT a.ProjectID, b.ResourceID FROM #ProjectTasks a, #ResourceTasks b WHERE NOT EXISTS ( SELECT * FROM #ProjectTasks JP2 WHERE JP2.ProjectID = a.ProjectID AND JP2.TaskID NOT IN ( SELECT c.TaskID FROM #ResourceTasks c WHERE c.ResourceID = b.ResourceID ) ) ORDER BY a.ProjectID, b.ResourceID; -- Todd's Division - CELKO 2 SELECT DISTINCT a.ProjectID, b.ResourceID FROM #ProjectTasks a, #ResourceTasks b WHERE NOT EXISTS ( SELECT 1 FROM #ProjectTasks c WHERE c.ProjectID = a.ProjectID AND NOT EXISTS ( SELECT 1 FROM #ResourceTasks d WHERE d.ResourceID = b.ResourceID AND c.TaskID = d.TaskID ) ) ORDER BY a.ProjectID, b.ResourceID; |
Both of these queries have two structures that, for performance reasons, I usually try to avoid where possible: a CROSS JOIN (disguised by the non-ANSI standard syntax that uses the comma between two tables) and DISTINCT. Cartesian products (from the CROSS JOIN) generate lots of unnecessary rows and DISTINCT can cause an expensive sort to occur. So let’s see if we can propose something just a little faster.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
-- Todd's Division - Dwain.C 1 SELECT j.ProjectID, s.ResourceID FROM #ProjectTasks j JOIN #ResourceTasks s ON j.TaskID = s.TaskID JOIN ( SELECT ProjectID, c_res=COUNT(*) FROM #ProjectTasks GROUP BY ProjectID ) c ON j.ProjectID = c.ProjectID GROUP BY j.ProjectID, ResourceID HAVING COUNT(*) = MAX(c_res) ORDER BY j.ProjectID, ResourceID; -- Todd's Division - Dwain.C 2 SELECT a.ProjectID, ResourceID FROM ( SELECT j.ProjectID, s.ResourceID, c_res=COUNT(*) FROM #ProjectTasks j JOIN #ResourceTasks s ON j.TaskID = s.TaskID GROUP BY j.ProjectID, ResourceID ) a JOIN ( SELECT ProjectID, c_res=COUNT(*) FROM #ProjectTasks GROUP BY ProjectID ) c ON a.ProjectID = c.ProjectID AND a.c_res = c.c_res ORDER BY a.ProjectID, ResourceID; |
I’ve actually proposed two solutions because depending on the number of rows in your test harness, one or the other may be slightly faster. If you run 05 Test Harness for Todds Division.sql exactly as it is provided, you should see timing results similar to those shown below.
|
Time (ms) |
||
|
Query |
Elapsed |
CPU |
|
Celko 1 |
14,109 |
37,209 |
|
Celko 2 |
14,251 |
37,144 |
|
Dwain.C 1 |
398 |
1,014 |
|
Dwain.C 2 |
392 |
1,186 |
If you follow the instructions within the test harness to increase the row counts,commenting out Joe Celko’s queries if you don’t want to wait for them to finish, you may find that at higher row counts my second solution is slightly faster (elapsed time) than my first. Both of these solutions represent a row reduction approach of a sort, because they use the INNER JOIN to reduce the rows that would otherwise be generated by the Cartesian product resulting from the CROSS JOIN.
This particular problem is immune from improvement by the Row Reduction Approach proposed for RDNR and RDWR, because of the number of entries in the divisor table. There would never be sufficient overlap to help reduce the execution time.
Romley’s Division
I have to give Joe Celko some credit here – for being a master of understatement. Romley’s Division (so named after Richard Romley of Salomon Smith Barney) is most certainly a quite complicated problem. Once again we’ll attempt to describe the problem but we’ll create an alternate scenario to help clarify when such a relational division might come into play.
Suppose we have a factory that has machines and assembly Lines. Each assembly line can support more than one process at a time: Each machine is uniquely associated with a single process, and can support only a single product at a time. We wish to determine for assembly lines and products, whether all, none or some of the processes are supported.
Let’s set up some sample data first and then we’ll look at possible solutions. First, the assembly lines and associated processes:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
CREATE TABLE #AssemblyLinesProcesses ( AssemblyLineID VARCHAR(10) NOT NULL ,ProcessID VARCHAR(10) NOT NULL ,CONSTRAINT mp_pk1 PRIMARY KEY(AssemblyLineID, ProcessID) ); INSERT INTO #AssemblyLinesProcesses VALUES ('L1', 'P1'), ('L1', 'P3'), ('L2', 'P2'), ('L2', 'P3'), ('L3', 'P2'), ('L4', 'P1'), ('L4', 'P2'), ('L4', 'P3'); |
For the machines and their associated products/processes, we’ll start with this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
CREATE TABLE #Machines ( MachineID VARCHAR(10) NOT NULL ,ProductID VARCHAR(10) NOT NULL ,ProcessID VARCHAR(10) NOT NULL ,CONSTRAINT p_ix1 UNIQUE (MachineID, ProcessID) ,CONSTRAINT p_pk1 PRIMARY KEY (MachineID, ProductID, ProcessID) ); -- load machine #1 data INSERT INTO #Machines VALUES ('M01', 'X1', 'P1'),('M02', 'X1', 'P1'),('M03', 'X1', 'P1'), ('M04', 'X1', 'P2'),('M05', 'X1', 'P2'),('M06', 'X1', 'P2'), ('M07', 'X1', 'P2'); -- load machine #2 data INSERT INTO #Machines VALUES ('M08', 'X2', 'P2'),('M09', 'X2', 'P2'), ('M10', 'X2', 'P2'),('M11', 'X2', 'P2'), ('M12', 'X2', 'P2'); -- load machine #3 data INSERT INTO #Machines VALUES ('M13', 'X3', 'P2'),('M14', 'X3', 'P2'),('M15', 'X3', 'P3'); |
Joe Celko proposed the following query to solve Romley’s Division:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
SELECT AssemblyLineID, ProductID ,SupportedProcesses=CASE SUM(Processes) WHEN 1 THEN 'None' WHEN 2 THEN 'All' WHEN 3 THEN 'Some' ELSE NULL END FROM ( SELECT DISTINCT a.AssemblyLineID, b.ProductID ,Processes=MAX(CASE WHEN a.ProcessID = b.ProcessID THEN 2 ELSE 1 END) FROM #AssemblyLinesProcesses a CROSS JOIN #Machines b GROUP BY a.AssemblyLineID, b.ProductID, b.ProcessID ) a GROUP BY AssemblyLineID, ProductID ORDER BY AssemblyLineID, ProductID; |
This produces the following results set:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
AssemblyLineID ProductID SupportedProcesses L1 X1 Some L1 X2 None L1 X3 Some L2 X1 Some L2 X2 All L2 X3 All L3 X1 Some L3 X2 All L3 X3 Some L4 X1 All L4 X2 All L4 X3 All |
If you look at the query’s execution plan, you’ll find that this method uses just two clustered index scans. My initial feeling when I saw that suggested it was going to be pretty hard to beat.

I’m not ashamed to admit that just solving this bad boy took me awhile, but of course my job is especially challenging because I’m ultimately trying to come up with a faster query. After some more stumbling around (I seem to do that a lot), I came up with the following solution, which certainly looks more complicated but does at least deliver the expected results set.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
WITH Machines AS ( SELECT ProductID, cnt_processes=COUNT(*) FROM #Machines GROUP BY ProductID ), AssemblyLines AS ( SELECT AssemblyLineID FROM #AssemblyLinesProcesses GROUP BY AssemblyLineID ) SELECT a.AssemblyLineID, b.ProductID ,SupportedProcesses=CASE n WHEN 0 THEN 'None' WHEN b.cnt_processes THEN 'All' ELSE 'Some' END FROM AssemblyLines a CROSS JOIN Machines b OUTER APPLY ( SELECT n=COUNT(*) FROM #Machines c JOIN #AssemblyLinesProcesses d ON c.ProcessID = d.ProcessID WHERE b.ProductID = c.ProductID AND a.AssemblyLineID = d.AssemblyLineID ) c ORDER BY a.AssemblyLineID, b.ProductID; |
The cost of the query’s execution plan for this approach is higher and it also looks quite a bit more complex.
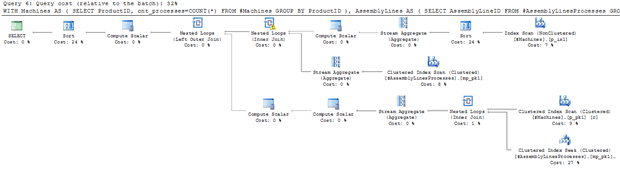 I’ve often found from personal experience that query plan costs can be deceiving. The ultimate test is how it runs with a large test harness. So we built one that could be run for two cases.
I’ve often found from personal experience that query plan costs can be deceiving. The ultimate test is how it runs with a large test harness. So we built one that could be run for two cases.
|
Attributes |
Approximate Rows |
|||||
|
Case |
Assembly Lines |
Machines |
Products |
Processes |
#AssemblyLinesProcesses |
#Machines |
|
1 |
100 |
1,000 |
100 |
100 |
950 |
1,000 |
|
2 |
1,000 |
10,000 |
100 |
100 |
9,500 |
10,000 |
You can run the test yourself by using 06 Test Harness for Romleys Division.sql. It is initially set up to run Case 1, but you can uncomment some code near the beginning to run Case 2. The result that I got when I ran these cases was:
|
Time (ms) – CELKO |
Time (ms) – Dwain.C |
|||
|
Case |
Elapsed |
CPU |
Elapsed |
CPU |
|
1 |
1,143 |
4,415 |
413 |
421 |
|
2 |
106,395 |
407,942 |
42,063 |
42,027 |
Somewhat surprisingly, this means that overall the elapsed time of my query for Romley’s Division was about 40% that of the original query, while it used only 10% of the CPU. The improvement is due to two main factors:
- The CROSS JOIN is applied to the two pre-aggregates, thus significantly reducing the size of the resulting Cartesian product. This gave me exactly the rows I needed for the first two columns of the final result.
- Using the INNER JOIN within the OUTER APPLY is sort of a row reduction of its own, and that is further reduced by the WHERE clause that limited the rows to only those applicable from the CROSS JOIN.
While not a case of using the originally proposed Row Reduction Approach (again it doesn’t apply here for various reasons), it shows that with a little effort a very tricky query can be turned into a high performance one.
Conclusion
I first was struck by the possibilities of the Row Reduction Approach to Relational Division when SQL MVPItzik Ben-Gan proposed a challenge to Identify a Subsequence within a Sequence. In part one of his article (link at left) I proposed three solutions in the post-article discussion, culminating in the Row Reduction Approach. In the discussion section of part two of the article, PESO commented that this was a special case of relational division that he called Ordered Relational Division. Also in that section, the performance results of the method were posted against the best solution proposed by the article. It was just slightly later that I realized what I had proposed could be generally applied to other more generic cases of relational division, illustrating my point early on that sometimes relational division is difficult to associate with a specific business problem. We’ll let you take a look at those two excellent articles to see what the fastest solution was.
The Row Reduction approach seems to improve the performance of any relational division query (with and without remainder), particularly if you are faced with exceedingly large row sets. This approach could even be used when your relational division has multiple remainders, albeit with some limitations.
The suggested Row Reduction approach cannot be applied to either Todd’s or Romley’s special relational division cases; but the key to achieving high performance queries in those instances also involves the principle of reducing the rows as much as possible prior to applying the final logic to solve the case.
A summary of the resource files (SQL scripts) provided with this article within the zip file at the bottom of the article follows:
- 01 CandidatesSkills Sample Queries.sql – Contains the sample data discussed in this article for RDWR, RDNR, and the sample queries for those cases (one with the Rows Reduction Approach) and for relational division with multiple divisors (i.e., all of the examples that use the CandidatesSkills table).
- 02 Create Large CandidatesSkills Tables.sql -This sets up two tables, CandidatesSkills1 and CandidatesSkills2 containing 1M and 10M rows respectively.
- 03 Test of RDNR Solutions at 1M Rows.sql – This verifies the solutions for RDNR at 1M rows so I could pick the best Joe Celko had to offer.
- 04 With and Without Row Reduction on 10M Rows.sql -This runs the five solutions we compared at 10M rows (refer to the two histograms provided).
- 05 Test Harness for Todds Division.sql – This contains a large test harness for all of the Todd’s Division queries. You can manually uncomment/comment some of the lines if you want to run as the sample queries in this section.
- 06 Test Harness for Romleys Division.sql – This contains a large test harness (Case 1) for all of the Romley’s Division queries. You can manually uncomment/comment some of the lines if you want to run as the sample queries in this section.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments