

Key Issues
Some of the simplest concepts in relational databases can catch out even the more-experienced programmer. Surely, everyone understands database keys? Perhaps not. The usage of keys is a subject that has never quite bedded down to a happy consensus. It causes some heat, and raised voices, amongst database people. We’ll try out a few things, and try to introduce a few concepts as we go. We’ve put a glossary at the end. You might need it.
Difficulties with James Bond
This workbench got started when we got arguing how the Natural Key 007 would have got allocated to James Bond, and then how they could distinguish James Bond from the previous 007s in order to do any accounting, such as calculating expenses or sending out a Bar (Mess) bill. We ended up concluding that it was completely useless, and probably masked a surrogate key.
From the stories, it would seem that there were only nine or ten agents who were licensed to kill, and they were all double-O (00x) agents. There are references in the Bond books to the fact that there was quite a turnover, with only ten agents active at a time. There could have been 999 agents at any one time using one of these codes. Presumably, with only one 0, the ninety nine were licensed to give a pretty nasty bruises, and the others were licensed to stick to satire, invective and irony. In the key 007, there is lurking a Smartkey, since two separate bits of information are shoehorned together
In fact to insert a new secret agent into a table, you’d probably want to allocate the lowest available number.
Imagine we had an agent table …
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
--clear up, if you are re-running the workbench IF OBJECT_ID(N'FK_PhoneNumbers_agent') IS NOT NULL ALTER TABLE [dbo].[PhoneNumbers] DROP CONSTRAINT [FK_PhoneNumbers_agent] IF OBJECT_ID(N'agent') IS NOT NULL DROP TABLE agent --and create the agent table CREATE TABLE agent( [code] AS RIGHT('00000'+RIGHT(CONVERT(VARCHAR(15),[MyNumber]),3),3) PERSISTED NOT NULL ,--e.g. 007. --This is just a string representation of the MyNumber column. MyNumber INT NOT NULL UNIQUE, FirstName VARCHAR(50) NOT NULL, Lastname VARCHAR(50) NOT NULL, PRIMARY KEY (code) here we define a calculated column as being a primary key ) GO * now you can get the agents into the table, just by executing the file we supply, ...*/ |
Load the agents here from the file attached.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 |
/* Allocating the next valid agent number would be interesting. it would depend whether they were 1/ Licensed to kill 2/ licensed to give a nasty bruise 3/ licensed to hurl invective.*/ /* we'll do a stored procedure for this */ IF OBJECT_ID(N'InsertNewAgent') IS NOT NULL DROP PROCEDURE InsertNewAgent GO CREATE PROCEDURE InsertNewAgent @FirstName VARCHAR( 50), @Lastname VARCHAR( 50), @type INT AS DECLARE @base INT,@Highest INT , @key INT IF COALESCE( @firstname+@lastname,'') ='' BEGIN RAISERROR ( 'an agent must have a name',16,1 ) RETURN 1 END SELECT @Base=CASE @type WHEN 1 THEN 1 WHEN 2 THEN 10 ELSE 100 END, @highest=CASE @type WHEN 1 THEN 9 WHEN 2 THEN 99 ELSE 999 END BEGIN TRANSACTION --think of the mess if two agents were created at once SELECT @Key= CASE WHEN EXISTS (SELECT 1 FROM agent WITH (TABLOCKX) WHERE MyNumber BETWEEN @Base AND @Highest ) THEN (SELECT TOP 1 A.MyNumber+1--allocate the next unused number in the sequence FROM agent A (TABLOCKX) LEFT OUTER JOIN agent B ON B.MyNumber=A.MyNumber+1 WHERE B.MyNumber IS NULL AND a.MyNumber >= @base ORDER BY a.MyNumber ) ELSE @base END IF @key NOT BETWEEN @Base AND @Highest BEGIN ROLLBACK TRANSACTION RAISERROR ( 'You can''t have any more agents of this type, (between %d and %d)' ,16,1,@base,@highest) RETURN 1 END INSERT INTO agent(Firstname,Lastname,MyNumber)--at last we can insert --the name into the table. SELECT @FirstName, @Lastname,@key COMMIT TRANSACTION RETURN 0 GO --and you would use it like this. EXEC InsertNewAgent 'Jim','Carruthers',1--licensed to kill EXEC InsertNewAgent 'Jane','Moneypenny',3--persuasion only SELECT * FROM Agent WHERE lastname IN ('Bond','Carruthers','Moneypenny') /* code MyNumber FirstName Lastname ---- ----------- -------------- ---------------- 002 2 Jim Carruthers 007 7 James Bond 063 63 Keri Bond 105 105 Jane Moneypenny */ --This insertion method is very quick to run: We timed it at 15 milliseconds --in a one million row table |
This is OK as far as it goes. The trouble is that it doesn’t go very far. The only way you could use this as a primary key is if you deleted all references to the previous agent with the same code. If you have referential constraints in place, then you are prevented from doing anything silly by mistake. Yes, you will find systems where it is done like this.
The trouble is that Databases generally need a history. No accountant would tolerate a system where all the records relating to an employee were deleted the moment the agent was exterminated by a villain. Nothing would balance. A payment to an employee remains a payment even after the employee has been eaten by a shark. Let’s face it, you’re going to need a surrogate key.
What do we do about the 007 nonsense? Ah, they want to keep it. They point out that they are unique because the code is only assigned to the current agent. It would cost too much for the business to change the system.
We then arrive at an uneasy truce. We use a compound key to ensure uniqueness.
Just to make it even more scary, one part of the key is a derived field! But we’ll also slip in a surrogate candidate key:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
IF OBJECT_ID(N'agent') IS NOT NULL DROP TABLE agent CREATE TABLE agent( [code] AS RIGHT('00000'+RIGHT(CONVERT(VARCHAR(15),[MyNumber]),3),3) PERSISTED NOT NULL ,--e.g. 007 MyNumber INT NOT NULL, holder INT NOT NULL DEFAULT 0,-- 0 if the current holder, --otherwise 1..n FirstName VARCHAR(50) NOT NULL, Lastname VARCHAR(50) NOT NULL, AGENT_id INT IDENTITY(1,1) UNIQUE,--the surrogate key PRIMARY KEY (code,holder) /*we define a compound primary key made up of two columns */ ) GO --insert sample data now--- |
Now Dion Prince gets sliced in two by a laser so we retire him by taking away his 0 in the holder column so someone else can now have his cherished 003 moniker. At this point, it is easy because the key hasn’t been used!
|
1 2 3 4 5 6 7 |
UPDATE agent SET holder= (SELECT COUNT(*) FROM agent a WHERE a.MyNumber = agent.Mynumber) -- he was the first holder WHERE firstname='dion' AND lastname LIKE 'Prince' AND holder=0 |
This is unrealistic, because in a real database the primary key will have been used and so this will cause an error. We’ll come back to this issue later. Normally we take great care to ensure that a candidate key is immutable.
Now the stored procedure can be altered slightly to add the fact that there can have been several holders of the 003 moniker but we want to reallocate it only if it isn’t there, or it is currently vacant.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
--the actual logic goes like this (for a double-0 agent) --what is the lowest currently available key in the 00 range? SELECT CASE WHEN EXISTS (SELECT 1 FROM agent WHERE MyNumber BETWEEN 1 AND 9 ) THEN (SELECT TOP 1 A.MyNumber+1--allocate the next unused number in the sequence FROM agent A (tablockx) LEFT OUTER JOIN agent B ON B.MyNumber=A.MyNumber+1 AND a.holder=0--current agent AND b.holder=0--current agent WHERE a.holder=0 AND B.MyNumber IS NULL ORDER BY a.MyNumber ) ELSE 1 END |
Key Confusions
we’ve now jumped through a few hoops in order to allow the business their natural key. Why all the fuss?
You will get people arguing that keys must be natural (or, perversely, that they shouldn’t be) or that they must be immutable (that you should never change its value). I’ve even heard it said that all joins must be on key values. Nope. Do what you think best. There are no ‘best practices’ or hard and fast rules, but you will have an easier life if you deviate from normal practice only when you have to.
We’ve sneaked in a surrogate key. Although the combination of moniker and holder number will be useful in tables which hold the agents’ information, so it is easy to check things like addresses, contact numbers and so on, we’ve decided to use a surrogate key as well, for tables that pertain to entities that have no ‘public’ meaning.
Getting bulk data in place
What about a bulk insertion? No problem. As we are doing a once-only import on a new table, We’ll drop the the Code field altogether for now, and then recreate and populate it after the bulk import. In fact, you can do bulk inserts later on an existing table but they’ll be slower. We’ll have to assume that the first nine imported rows are 00 status, then the next ninety are 0 status and the following 900 are boring three-figure numbers. the next thousand will be replacements, and so on.
|
1 2 3 4 5 6 7 |
IF OBJECT_ID(N'agent') IS NOT NULL DROP TABLE agent CREATE TABLE agent( FirstName VARCHAR(50) NOT NULL, Lastname VARCHAR(50) NOT NULL, MyNumber INT NOT NULL--a number between 1 and 999 ) GO |
At this point onwards, we used SQL Data Generator. Apologies to anyone who hasn’t already got it. To follow this bit, you’ll need to download it for a fourteen day free trial! The reason is that, later on in the workbench, importing into tables that involve foreign key constraints is tricky to do by hand. Also the million agents were a big file, (to say nothing about two million phone numbers).
|
1 |
--Add in the million rows here! (25 secs) |
Now we want to calculate the Holder value to make each of the composite keys unique. Notice that we need to create a clustered index so that the updates happen in the order we want (the order of the clustered index.)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 |
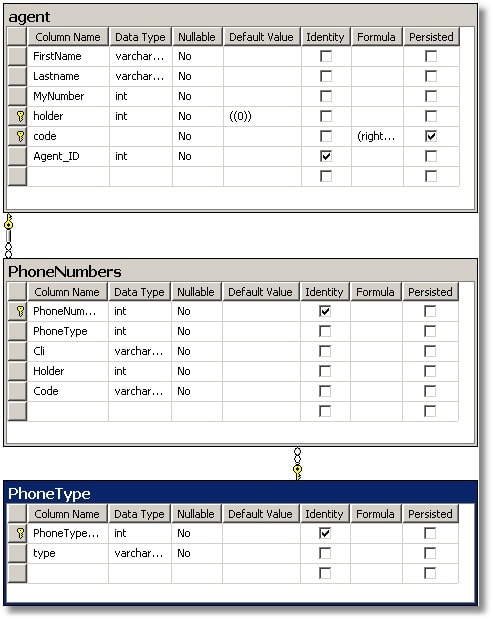
CREATE CLUSTERED INDEX idxMyNumber ON agent(MyNumber) --4 seconds ALTER TABLE agent ADD [holder] INT NOT NULL DEFAULT 0 --6 seconds GO DECLARE @Holder INT, @MyNumber INT SELECT @MyNumber=0,@MyNumber=-1 UPDATE agent SET @Holder= holder=CASE WHEN Mynumber<>@MyNumber THEN 0 ELSE @holder +1 END, @Mynumber=Mynumber --this took 4 seconds SELECT COUNT(*) FROM agent GROUP BY MyNumber,holder HAVING COUNT(*)>1 --check for unique! (5 seconds) --now we can construct the visible part of the moniker ALTER TABLE agent ADD [code] AS RIGHT('00000'+RIGHT(CONVERT(VARCHAR(15),[MyNumber]),3),3) PERSISTED NOT NULL --6 seconds -- and we can add a surrogate key as well. -- The unique constraint provides an index ALTER TABLE agent ADD [Agent_ID] INT IDENTITY(1,1) UNIQUE --10 secs DROP INDEX agent.idxMyNumber--we only needed this to do the 'holder' -- part of the key --2 secs --we'll generally use the normal way of identifying people CREATE CLUSTERED INDEX idxName ON agent(lastname) --8 secs --create a composite key ALTER TABLE agent WITH NOCHECK ADD CONSTRAINT PK_AgentIdentifier PRIMARY KEY NONCLUSTERED (code,holder) --7 seconds --instantaneous! --The first twenty agents whose lastname begins with 'Z' SELECT TOP 20 Firstname,lastname, code, holder FROM agent WHERE lastname LIKE 'z%' --The current holder of 007 followed by previous ones SELECT TOP 20 Firstname,lastname, code, holder FROM agent WHERE code='007' ORDER BY holder ASC --current agents SELECT TOP 20 Firstname,lastname, code FROM agent WHERE holder=0 ORDER BY MyNumber ASC IF OBJECT_ID(N'FK_PhoneNumbers_PhoneType') IS NOT NULL ALTER TABLE [dbo].[PhoneNumbers] DROP CONSTRAINT [FK_PhoneNumbers_PhoneType] IF OBJECT_ID(N'PhoneType') IS NOT NULL DROP TABLE PhoneType CREATE TABLE dbo.PhoneType ( PhoneType_ID INT NOT NULL IDENTITY (1, 1), [Type] VARCHAR(10) NOT NULL ) ON [PRIMARY] GO ALTER TABLE dbo.PhoneType ADD CONSTRAINT PK_PhoneType PRIMARY KEY CLUSTERED ( PhoneType_ID )ON [PRIMARY] GO IF OBJECT_ID(N'PhoneNumbers') IS NOT NULL DROP TABLE PhoneNumbers CREATE TABLE dbo.PhoneNumbers ( PhoneNumber_ID INT NOT NULL IDENTITY (1, 1), PhoneType INT NOT NULL, Cli VARCHAR(30) NOT NULL, Holder INT NOT NULL, Code VARCHAR(3) NOT NULL ) ON [PRIMARY] GO ALTER TABLE dbo.PhoneNumbers ADD CONSTRAINT PK_PhoneNumbers PRIMARY KEY CLUSTERED ( PhoneNumber_ID )ON [PRIMARY] GO ALTER TABLE dbo.PhoneNumbers ADD CONSTRAINT FK_PhoneNumbers_agent FOREIGN KEY ( Code, Holder ) REFERENCES dbo.agent ( code, holder ) ON UPDATE NO ACTION -- CASCADE (if primary key changes! SQL 2000 or above) ON DELETE NO ACTION GO --we now add the foreign key constraint ALTER TABLE dbo.PhoneNumbers ADD CONSTRAINT FK_PhoneNumbers_PhoneType FOREIGN KEY ( PhoneType ) REFERENCES dbo.PhoneType ( PhoneType_ID ) ON UPDATE NO ACTION ON DELETE NO ACTION ---and here we'll add in two million telephone numbers -- at this stage we have to use SQL Data Generator, really, as --anything else is just too tedious. |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
CREATE NONCLUSTERED INDEX idxCli ON dbo.PhoneNumbers ( [Cli] ASC ) ON [PRIMARY] --get the first 20 agents whose phone-numbers start with '01' SELECT TOP 20 dbo.agent.FirstName, dbo.agent.Lastname, dbo.PhoneNumbers.Cli FROM dbo.agent INNER JOIN dbo.PhoneNumbers ON dbo.agent.code = dbo.PhoneNumbers.Code AND dbo.agent.holder = dbo.PhoneNumbers.Holder WHERE cli LIKE '01%' --get the agent(s) whose phone-number is '0142211065' SELECT TOP 20 dbo.agent.FirstName, dbo.agent.Lastname, dbo.PhoneNumbers.Cli,PhoneType.TYPE FROM dbo.agent INNER JOIN dbo.PhoneNumbers ON dbo.agent.code = dbo.PhoneNumbers.Code AND dbo.agent.holder = dbo.PhoneNumbers.Holder INNER JOIN dbo.PhoneType ON PhoneType.PhoneType_ID=phoneNumbers.PhoneType WHERE cli LIKE '0142211065' /*9 ms FirstName Lastname Cli Type ----------- --------- -------------------- ------- Elisa Parrish 0142211065 Fax (1 row(s) affected)*/ |
Now we have the simplest possible database with foreign keys. We now hear the sad news that 005 has been cut in half by a laser.
We retire him by a stored procedure that involves changing a component of the primary key! We can do this bit automatically simply by means of a cascading update on the FK_PhoneNumbers_agent constraint on PhoneNumber, but we’ll do it explicitly as well for those poor souls on SQL Server 7
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 |
IF OBJECT_ID(N'RetireAgent') IS NOT NULL DROP PROCEDURE RetireAgent GO CREATE PROCEDURE RetireAgent -- @code CHAR(3) AS DECLARE @NewHolder INT IF NOT EXISTS (SELECT 1 FROM agent WHERE code=@code AND holder=0) BEGIN RAISERROR ('The agent has already been retired',16,1) RETURN(1) END SELECT @Newholder= COUNT(*) FROM agent a WHERE a.MyNumber = @code --in SQL Server 2000 up you would use a CASCADE condition on the --ON UPDATE clause of the foreign key constraint for each table BEGIN TRANSACTION--retire the agent along with his phone numbers INSERT INTO agent (firstName, Lastname,MyNumber,Holder) SELECT firstName, Lastname,MyNumber,@NewHolder FROM agent WHERE code=@code AND holder=0 UPDATE Phonenumbers SET holder=@Newholder WHERE code=@code AND holder=0 DELETE FROM agent WHERE code=@code AND holder=0 COMMIT TRANSACTION GO EXECUTE RetireAgent '007'--1.5 seconds. IF OBJECT_ID(N'InsertNewAgent') IS NOT NULL DROP PROCEDURE InsertNewAgent GO CREATE PROCEDURE InsertNewAgent @FirstName VARCHAR(50), @Lastname VARCHAR(50), @type INT AS DECLARE @base INT,@Highest INT, @key INT IF COALESCE(@firstname+@lastname,'')='' BEGIN RAISERROR ('an agent must have a name',16,1) RETURN 1 END SELECT @Base=CASE @type WHEN 1 THEN 1 WHEN 2 THEN 10 ELSE 100 END, @highest=CASE @type WHEN 1 THEN 9 WHEN 2 THEN 99 ELSE 999 END BEGIN TRANSACTION --think of the mess if two agents were created at once SELECT @Key= CASE WHEN EXISTS (SELECT 1 FROM agent WITH (TABLOCKX) WHERE MyNumber BETWEEN @Base AND @Highest ) THEN (SELECT TOP 1 A.MyNumber+1--allocate the next unused number in the sequence FROM agent A (TABLOCKX) LEFT OUTER JOIN agent B ON B.MyNumber=A.MyNumber+1 AND a.holder=0--current agent AND b.holder=0--current agent WHERE a.holder=0 AND B.MyNumber IS NULL ORDER BY a.MyNumber ) ELSE @base END IF @key NOT BETWEEN @Base AND @Highest BEGIN ROLLBACK TRANSACTION RAISERROR ( 'You can''t have any more agents of this type, (between %d and %d)' ,16,1,@base,@highest) RETURN 1 END INSERT INTO agent(Firstname,Lastname,MyNumber)--at last we can insert --the name into the table. SELECT @FirstName, @Lastname,@key COMMIT TRANSACTION RETURN 0 GO --and now we can add a new volunteer to die for his country! EXEC InsertNewAgent 'Jim','Carruthers',1--licensed to kill |
Conclusion
So what have we learned? Although natural keys can be made to work, and can perform well, there is always a payoff. The database designer is right to use surrogate keys wherever he can but he should not be afraid of circumstances where that isn’t possible. Where all the business operations are done through stored procedures, then the complexity can be hidden from the application programmers, and one can cheerfully commit ‘crimes’ such as changing things that ought, perhaps, to be immutable. We’re inclined to agree with C J Date and Joe Celko that we should be less doctrinaire about keys. Above all, we reckon that this sort of approach should be tried out on a slow machine, with as much data as possible, with all metrics switched on!
Glossary
These terms are in common currency, but a few are more widely used in Oracle
- Key
- To be usable, in other words to be able to unambiguously identifify a database entity, a key must be unique and known (i.e. not NULL). It can consist of one or more attributes (columns). A key is no more than a ‘candidate’ until you use it and you can have as many candidate keys in a table as you like.
- Fat key
- A key that contains more than 16 bytes. It is said that these do not perform as well, but if this is true, it is usually too slight to notice.
- Primary key
- the default candidate key for a table. Primary keys are simply the default keys for a table. They are no longer required by relational theory for a table, just a candidate key, and are, according to CJ Date, included only for historical reasons. However, they should be used as there is no other way to specify to other processes which key should be used by default. A Primary key is no more than an indexed key whose value, taken together across all component columns, is unique and known. SQL Server creates a clustered unique index when you specify a primary key, but this is not always the best solution, since a clustered index works best when it is not unique, not null and when the values are reasonably evenly distributed
- Compound key
- A key consisting of several columns, in which all values are known (not null) and, in combination, are unique.
- Foreign key
- a reference to a key in another table
- Candidate key
- a key with a unique and ‘not null’ constraint.
- Unique key
- a key containing unique values across all component columns.
- Natural key
- a key containing information used by people. Primary keys for business entities such as invoices, deliveries or products are generally best if they are composed of something the business already uses, such as a product code, shipment reference, customer reference, or invoice number. and is part of their culture. This type of key is the so-called ‘natural key’. There is a problem with having a meaningful key. If the data that formed the natural key (such as a person’s initials) was was wrongly entered, the key will be wrong but the business will already “know” the wrong version.
- Surrogate key
- a computer-generated candidate key. Surrogate keys such as the ‘Identity field key’ are the normal way of getting round the complexities of trying to handle Natural keys. If the business uses incrementing numbers that can be huge, and they don’t mind gaps, then you can use these identity fields. However, more often you’ll find that businesses have arcane rules, passed down from distant tribal ancestors, and they resent having to change their system. There are often good reasons for this. The cost of retraining, or changing the corporate culture can be astronomical. It is their choice. As Codd says, ‘Users […] are no longer compelled to invent a user-controlled key if they do not wish to’. We can play it either way. Obviously, where a table represents something that has meaning only within the database schema, a surrogate unique key that is machine-generated, such as an identity field or GUID, is fine. However, where this isn’t the case, you are running a risk by using one because, when things go wrong, it is much easier to sort things out if the keys are meaningful, and errors are so much easier to spot too before damage is done.
- SmartKey (or contatenated key)
- a key containing a single value usually composed of the values of several columns. If the data that made up part of the key was was wrongly entered, the key will be wrong but the business will already “know” the wrong version. All smart keys, such as postcodes, eventually run into trouble, however preferable they are. A difficulty with compound keys is that you cannot select a ‘set’ of rows by using the IN clause e.g.*/
123456789Delete from product where product_ID in(select max(product_ID)from productgroup by productnamehaving count(*)>1)
While Surrogate keys make the coding of databases easier, they are disliked by book-keepers accountants, retailers or anyone else who has to handle them. They aren’t human-friendly. Also, identity fields that are so often used to create surrogates can sometimes catch you out in surprising ways.
- Composite key
- A key that uses several non-null columns.
- Alternate key.
- A candidate key not assigned to be the primary key.
- Foreign key
- A foreign key restrains, at all times, one or more columns in a relvar to refer to a corresponding relvar via a candidate key in the referenced table. The enforcement is done via a foreign key constraint
- Key Constraint
- This is a constraint to the effect that one or more columns in a table are to be a candidate key. A primary Key constraint just defines the default candidate key.
- Immutable key
- This is a key whose value cannot be changed. This is the normal assumption, though it is seldom enforced.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved






Load comments