



LLMs should be used in data pipelines for unstructured text, semantic search, and natural language queries – but avoided for deterministic, high-volume, or regulated tasks. Drawing on my real-world experience building large-scale ML systems, in this guide I’ll explain exactly where LLMs belong in your data pipeline and, just as importantly, where they don’t.
Someone on your team just got back from a conference. Or maybe they spent 20 minutes on LinkedIn. Either way, the message lands in Slack: “We should be using LLMs in our pipeline.”
I’ve watched this play out more times than I can count – and I get it. LLMs (large language models) are genuinely exciting. However, what usually follows that Slack message is not so exciting. It’s a weeks-long detour that ends with an infrastructure bill that makes the VP of Engineering visibly uncomfortable. A pipeline that’s three times slower than before. And a compliance team asking questions nobody prepared for.
I’ve spent the last few years building production ML (machine learning) systems that touch hundreds of millions of users – customer journey optimization, support analytics, behavioral data at petabyte scale. The clearest lesson from all of it: the teams that get LLMs right aren’t the ones who use them everywhere. They’re the ones who are ruthlessly specific about exactly where they use them.
This article is my attempt to give you a concrete framework for making that call – not in theory, but instead in the kind of production environment where things break at 2am and someone has to explain the AWS bill.
Why LLMs are being over-applied
The appeal of LLMs is obvious. It can read a messy support ticket, figure out what the customer actually wants, classify it, summarize it, and draft a reply – all in one API call. Three years ago that would’ve been four separate models and a custom NLP (natural language processing) pipeline. Now, it’s a weekend prototype.
The problem, however, shows up later. Token costs scale with volume, and latency is real. The output is probabilistic (meaning identical inputs don’t always produce identical outputs), and when something goes wrong, debugging an LLM call is nothing like debugging a SQL transformation. There’s no stack trace for “the model decided to phrase it differently this time.”
The trap springs during the proof-of-concept phase. The demo looks great. The prototype handles edge cases, tolerates messy input and produces readable output…but the demo doesn’t run on ten million rows. It doesn’t have a 50-millisecond latency budget. And nobody from compliance is watching when you build it.
That gap between demo performance and production fitness is where most LLM projects run into trouble.
Where do LLMs genuinely belong in a data pipeline?
Let’s start with where LLMs actually earn their keep…
1. Unstructured text parsing and enrichment
If your pipeline ingests free-form text (support tickets, reviews, medical notes, legal documents, call transcripts), LLMs are doing something rule-based systems genuinely cannot.
A regex extracts a phone number. It doesn’t extract the emotional tone of a complaint, the buried risk clause in paragraph 14 of a contract, or the intent behind “this thing keeps doing the thing again.” In one large-scale support analytics deployment I worked on, LLM-based enrichment of call transcripts gave us classification accuracy that would’ve taken hundreds of hand-crafted rules to approximate – rules that would have needed updating every time a new product launched. Instead, we simply updated a prompt.
2. Semantic search and RAG
This is the clearest LLM win in data pipelines, full stop. When users need to query a knowledge base or documentation corpus using natural language – and when keyword matching falls short – RAG architectures are purpose-built for the job.
RAG isn’t even just a fallback option – for retrieval tasks, it’s the architecturally correct first choice. It’s traceable (the model can cite its sources), updatable without retraining (swap the vector database, not the model), and doesn’t silently degrade when your data changes. In a separate piece I’ve written on RAG-first architectures, I argue that roughly 70% of production AI use cases are better served by RAG and smart prompting than by fine-tuning. Retrieval is the clearest example of why.
3. Natural language to SQL
What surprises people is that LLMs are actually quite good at translating natural language questions into SQL – as long as the context is right. Pass in your schema, a few example queries, and relevant table descriptions, and you’ve turned a hallucination-prone model into a reliable query generator.
4. Explaining what your models found
Statistical models are good at detecting anomalies but terrible at explaining them to whoever needs to take action. An LLM can take the outputs of your monitoring system – such as churn spike, support ticket surge, or regional drop-off – and turn them into a paragraph a product manager can actually use.
This is also a relatively low-volume use case. You’re not narrating a billion events; you’re narrating a handful of alerts. The cost profile is fine.
Future-proof database monitoring with Redgate Monitor
Where LLMs do not belong
Now the harder part. LLMs can technically be wedged into almost any pipeline task, but the question is whether you should. Usually, the answer is no.
1. Deterministic transformations
If your transformation has a single correct answer – convert this timestamp to UTC, calculate a 30-day rolling average, join two tables on customer ID – use SQL or a dataframe operation. That’s it. LLMs add probabilistic variability to tasks that require deterministic correctness, and they do it at orders-of-magnitude higher cost and latency.
I’ve seen teams run LLM calls to “clean” structured fields that a two-line Python function would have handled the same way, for a thousandth of the price. The justification is usually that the LLM handles edge cases better. Sometimes that’s true. However, it more often means the edge cases haven’t been properly defined. The fix here is to define them – not hand the problem to a model that charges per token.
2. High-volume, low-latency enrichment
Petabyte-scale pipelines and LLM token costs do not coexist peacefully. If you’re enriching a billion user events per day with API calls, the infrastructure bill will not survive a quarterly review.
The lesson I’ve learned working at that scale: LLMs belong at the edges, on the high-value, low-volume decisions. Not in the hot path where you need sub-millisecond responses at fractions of a cent per million operations. The table below emphasizes the magnitude of this gap:
| Approach | Latency | Cost / 1M rows | Reliability |
| LLM (GPT-4 class) | 800ms–2s | $800–$2,000 | High (with guardrails) |
| LLM (smaller / local) | 200–500ms | $50–$200 | Medium |
| Classical ML | 10–50ms | $5–$20 | High (deterministic) |
| SQL / Rule-based | <10ms | <$1 | Very High |
Your numbers will vary by model, provider, and workload, but the order-of-magnitude differences are real. They don’t just disappear with optimization.
3. Regulated or compliance-sensitive outputs
If your pipeline produces outputs subject to regulatory audit – such as fraud scores, healthcare decisions and financial calculations (to name a few) – LLMs are the wrong foundation. Regulators want explainability, reproducibility, and deterministic behavior under identical inputs. LLMs don’t naturally offer any of those things.
That doesn’t mean LLMs are useless in regulated environments. They can draft, summarize, and flag items for human review. But the authoritative output – the number that goes in the record, the decision that gets logged – needs to come from something auditable.
Write accurate SQL faster in SSMS with SQL Prompt AI
A practical decision framework
Before you add an LLM to any pipeline stage, ask these four questions. They’ve saved me from making several expensive decisions.
- Is the output deterministic? If yes, reach for SQL, a dataframe library, or classical ML first. LLMs add cost and variance to problems that don’t need it.
- Is the input unstructured or semantically complex? If yes, LLMs are likely the right call. If the input is structured and well-defined, they’re probably not.
- What’s the volume and latency requirement? If you’re processing more than a few million records a day or need sub-100ms responses, run the cost and latency math before you commit.
- Can you explain this output to an auditor? If traceability matters, make sure your LLM integration includes citations, logging, and a path to human review.
Here’s how that maps across common pipeline tasks:
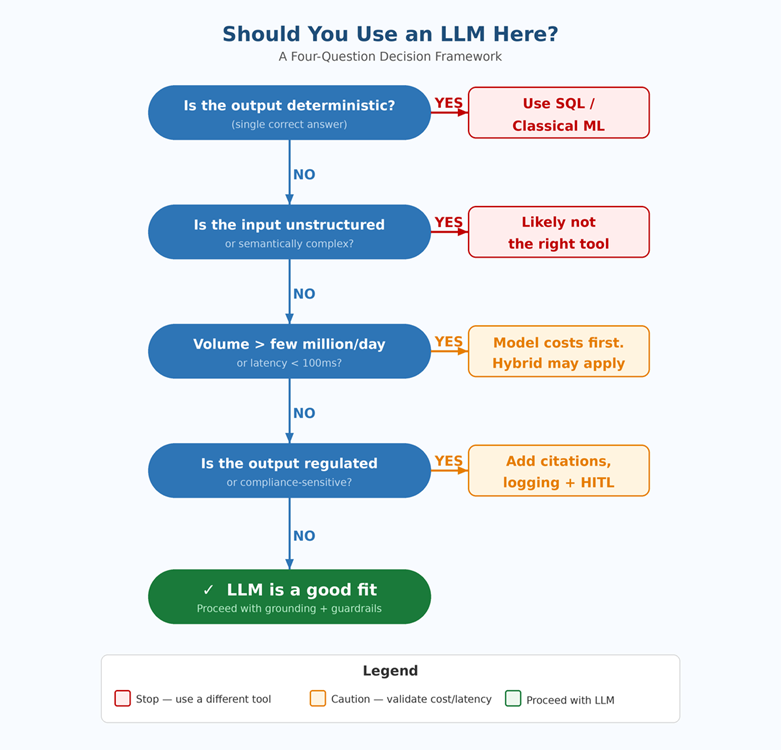
| Task Type | Use LLM? | Better Alternative | Reason |
| Unstructured text parsing | Yes | N/A | LLMs excel at flexible, context-aware extraction |
| Semantic search / Q&A | Yes | N/A | RAG + LLM is purpose-built for this |
| Dynamic SQL generation | Yes | N/A | LLMs handle schema-aware query generation well |
| Deterministic transforms | No | SQL / dbt | Rule-based is faster, cheaper, auditable |
| High-volume enrichment | Careful | Classical ML / rules | Token costs scale badly at petabyte volume |
| Regulated / compliance output | No | Deterministic logic | LLMs lack guaranteed output structure |
| Anomaly explanation | Yes | N/A | LLMs narrate statistical outputs effectively |
Real-life example: customer data enrichment
Take a task I’ve dealt with directly: enriching customer records with a “likely intent” label based on recent behavior. The input is a mix of clickstream events, support interactions, and purchase history. The output drives what the customer sees next.
You have three real options:
- SQL + rule-based heuristics: Fast, cheap and completely auditable. Works great when your intent categories are stable and well-defined. Falls apart when behavior patterns shift or when the language is ambiguous.
- Classical ML classifier: Trained on labeled historical data. Handles high volume and low latency well. Needs periodic retraining as patterns evolve. How interpretable it is depends on what model you pick.
- LLM with behavioral context in the prompt: Handles novel patterns and nuanced intent better than the other two. Expensive at scale. Fine for async batch enrichment; not for real-time serving. Outputs need validation.
The pattern that’s worked best in the high-volume deployments I’ve been part of is a hybrid: use the classical ML model for the bulk of real-time scoring, and route low-confidence cases to a secondary LLM enrichment step. Let the fast, cheap system handle the straightforward cases. Save the powerful, expensive system for the ones that actually need it. This is the same principle behind RAG-first architectures – reserve model complexity for where it genuinely moves the needle.
Conclusion: choose the right tool for the right job
The most expensive LLM mistake I see isn’t failing to adopt them. It’s adopting them without a clear reason why. LLMs are genuinely transformative for unstructured data, semantic retrieval, natural language querying, and anomaly explanation. They’re the wrong choice for deterministic transforms, high-volume hot paths, and regulated outputs.
The teams getting the most out of LLMs in production aren’t the ones who put them everywhere – they’re the ones who put them in exactly the right places and fought the urge to do anything more.
The four questions and decision table in this article aren’t exhaustive. They’re meant to create a ten-minute pause before someone adds a $0.80-per-thousand-token model to a pipeline stage that a $0.0001 SQL query was already handling correctly. LLMs are powerful – and that’s precisely why you should be selective about where you use them.
FAQs: When, and when not, to use LLMs in your data pipeline
1. When should you use LLMs in a data pipeline?
Use LLMs for unstructured text tasks like classification, summarization, semantic search, and natural language querying where traditional methods fall short.
2. When should you avoid using LLMs?
Avoid LLMs for deterministic tasks, high-volume low-latency processing, and regulated outputs that require consistency and auditability.
3. Why are LLMs expensive in production?
LLMs incur high token-based costs and latency, especially at scale, making them inefficient for large, real-time data pipelines.
4. What is the best alternative to LLMs for structured data?
SQL, rule-based systems, and classical machine learning models are faster, cheaper, and more reliable for structured and repeatable tasks.
5. How can you use LLMs efficiently in production?
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved

Load comments