
Introduction
Even if we don’t buy into the whole Agile methodology, we, as developers, are increasingly following Agile strategies in our code. This is most likely to involve continuous refactoring, continuous integration, and test-driven development. Where the database is concerned we will, by contrast, follow the more traditional ‘Big Design’ Up-Front approach in which the design is completed before the solution is implemented. If your requirements are extremely stable, immaculately analyzed, and you follow a waterfall process throughout the development life cycle, this may work: But the chances aren’t good.
Those same reasons that make a convincing argument for following agile processes in your development life cycle also hold true as arguments for following agile methodology with the database.
These reasons, in a nutshell are that
- Requirements are rarely well-defined
- Requirements will almost certainly change.
- Agile processes become increasingly advantageous the more dynamic the requirements.
While up-front design can make development easier, it will only happen if the requirements remain stable. If the requirements change faster than the application can be designed and implemented, the project will be caught running full-pelt in a hamster-exercise-wheel from which exit is difficult. Not to mention, in the end you may not actually deliver what the users want. At the very least, they wind up waiting longer than they want.
If, on the other hand, you can use Agile techniques to respond to changes in requirements during your development life cycle, the chances of a timely delivery of the project are enhanced, but only if the same flexibility can be achieved in parallel with the development of the supporting database.
Evolutionary Database Design
In a recent article, I wrote about the practice of Database Refactoring. Scott Ambler adapts Martin Fowler’s definition of refactoring to become “a simple change to a database schema that improves its design while retaining both its behavioral and informational semantics”. He takes a broad definition for database schema that includes not just the database structure but also views, stored procedures and triggers.
Together with Pramodkumar J. Sadalage they wrote the book ‘Refactoring Databases: Evolutionary Database Design’, a part of which was published by Simple-Talk here. Scott maintains the site http://www.agiledata.org/. They are attempting to bring the Refactoring discipline to database design, to try to overcome the current difficulties in making changes to databases as part of an evolutionary development process.
Much of the inflexibility of the development process, even when faced with changing requirements, has been cultural rather than technical. This is especially true of the database. Changing stored procedures and triggers is usually not too controversial, but it is typical to find that any suggestion of making any changes to database structures that are already in production will be met with hostile ridicule. There is often a good reason for this, especially if nobody clearly knows all of the applications that will be affected. If you perform a refactor such as ‘Move Column’, this will quickly bring to light the affected applications, from the complaints of anguished users. This is a real risk, but also highlights that refactoring the database may be long overdue. In fact, if not knowing what will be affected by making a change deters you from making a change that is needed, you may have a bigger problem on your hands than you may have originally thought.
As developers how do we move beyond this?
What is involved in Database Refactoring?
Refactoring a database is more complex than refactoring code. A code-refactoring exercise will generally be self-contained within a single application; for a database, this will often involve many applications. Each of these applications will often have different release schedules: This means that the database must support applications that have been updated to accommodate the change as well as applications that have not. To support both, we would need to devise the means to allow the database to work simultaneously with both types of applications. This type of ‘split personality’ would certainly be needed in the transitional stage while these applications are updated. Sometimes, this may take more than a year.
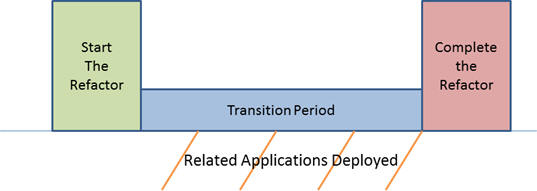
There are a couple of strategies that we can follow to minimize this pain. Some of these, we must adopt from the beginning, some can be added in after the fact.
As much as possible, you should limit the number of applications that directly access your database. We will often setup a separate database just for reporting that is “fed” from the transaction system. This keeps the reporting system separate from the transaction system. The Extract Transform Load (ETL) processes that move the data from the transaction database to the reporting database shields the reporting system from changes in the transaction system. Only the ETL processes and not every report need to be updated when we change the transaction system. We can follow similar approaches for other transaction systems that need access to our database.
Instead of allowing another application to insert data into your database, keep them separate and only communicate through import / export files, or require applications to access your data through published web service interfaces or similar APIs. This limits the scope of the change. Applications that are interacting with your database do not need to be changed, only the interfaces that they use.
If you don’t already have such structures in place, you may need to introduce triggers or views to simulate the original database structures while the affected applications are updated.
In the meantime, we also have to keep track of which affected applications have been updated and which still need to be updated. Once we know that everyone has been updated, we are be able to remove the supporting mechanism that exposes different APIs of the database to different applications.
For instance, to perform a ‘Move Column’ refactor, you might follow these steps:
- Add the column to the destination table
- Add an update trigger to the original table that will update the destination table
- Test
- Add an update trigger to the destination table that will update the original table
- Test
- Track as each affected system is updated
- Remove the original column and the triggers
- Test
The Refactoring Databases book steps through dozens of similar examples of refactors, which are well worth studying, along with the methodology that the authors have developed.
This sounds like a lot of Work, Why Bother?
If the application development can be supple, and the database can’t, then there are bound to be problems. The fault lines are easy to spot: At one place where I worked, any idea of changing a database structure that was already in Production was frowned upon as severely as if you were making code changes directly in Production. We could add a new column, but a table that was no longer needed could not be dropped. Forget about dropping an obsolete column, and if a column had a bad name, we were forever doomed to live with the bad name. With a lot of effort, we could convert a one-to-many relationship to a many-to-many relationship, but we were stuck with the original foreign keys even if they were no longer needed. Over time, the data model degraded to sparsely populated tables riddled with columns that were no longer used.
Eventually, we even resorted to reusing existing columns. It was easier to press an existing column back into service than it was to push through a new column. You were given the fifth degree to even add a new column. “Are you sure you need this column?” “You were once sure that you would need this other column!” “Why do you think you will need this new column when you no longer need this other column?”
This would be accompanied with drawn out discussions of where to add a new column. Should this be part of the Borrower record or the BorrowerDetail record or the BorrowerIncome record? The stakes were high if you got it wrong. In this particular application, there was one BorrowerDetail record for the loan, one Borrower record for each borrower on the loan application, and a BorrowerIncome record for each source of income. If you add it to the wrong table, you may end up with lots of brittle logic to cover up the mistake.
We were plagued with multiple naming conventions as new best practices came into fashion. Consistency was just a pipe dream.
Eventually we defined a standard that all table relationships would be defined as many to many, just in case it was eventually needed. After all one-to-one, one-to-many, and many-to-one are all special cases of the more generalized many-to-many relationship. Sounded very reasonable at the time, but it does not take much imagination to see how this can lead to chaos. While you may often really need to define a many to many relationship, you don’t always. We needed a lot of extra code to enforce the relationships and constraints through code that the database could have easily supported had it been properly defined.
OK, I am exaggerating a little. The situation was not quiet this bad, but It was close. It takes a great deal of wasted energy to make developments work when the database design is set rigid.
Best Practices
Is there any way that Database developers and DBAs can solve the problem of an application with an evolving data schema, and a database that has to accommodate existing applications? There are several ways that we can minimize the pain when we refactor databases.
Database Encapsulation
This is basically the discipline of creating a database abstraction layer (DAL), a way of reducing the interdependencies between your application and your data access logic. We are all familiar with encapsulation as one of the fundamental tenants of object oriented programming. For Database Encapsulation, we get several key advantages:
- All data access logic is centrally located
- You can focus on application logic and not have to worry about data access, and then focus on data access logic without having to get bogged down in application logic
- The better the database structures and application structures are separated, the more easily each can be modified without affecting the other.
There are a couple of guiding principles that we need our database encapsulation to follow to achieve these wonderful benefits:
- Application code outside of the DAL should need to know nothing about the actual database being used, or its implementation details. When writing application logic, you don’t even care that it is an Oracle database or a SQL Server database.
- Every object returned from the DAL should be POCO (Plain Old CLR Objects) this means no DataTable, no DataSets, and no DataReaders, nothing from any of the System.Data namespaces.
- Queries should return Lists of the POCOs exposed by the DAL.
Although basing a DAL on stored procedures and views is effective, it is not the only alternative. ORMs are another way of abstracting the database layer. ORM tools such as NHibernate, ADO.Net Entity Framework or SubSonic each make excellent Data Encapsulation layers. While this shields most of the application logic from the database details and schema, it does not shield the developer from knowing and understanding the database and schema. In fact, the more the developer knows about the database and the better we understand the schema, the easier our lives will be.
Common Development Guidelines
Guidelines should include:
- Standardize on a set of acceptable data types and when they are to be used.
- The number of characters for common fields like phone numbers, city names, descriptions, etc.
- The numeric precisions for common fields like currency, percentages, ratios, etc.
- The precision for date fields
- The acceptable ranges for data
- Standardize on naming conventions
- Acceptable abbreviations
- Acceptable acronyms
- Use underscores or not
- Standardize on a primary key strategy
- Avoid common database smells:
- Multi-purpose columns a column serving more than one purpose such as a “name” column being used to store the First Name of a customer or the DBA for a Company. Extra code is needed to ensure that the column is used the “right way”
- Multi-purpose tables a table serving more than one purpose. This happens when two or more entities are being stored in the same table. The problem is that many field combinations may never be used and extra code will be needed to ensure that the table is used properly and proper database constraints cannot be defined.
- Redundant Data is always a problem. Storing the same piece of data in multiple places guarantees that there will be consistency problems
- Tables with too many columns are a lot like procedures with too many lines of code. They lack cohesion. Often this means that related columns need to be extracted to a new table. This will help normalize the data model.
- “Smart” Columns that need to be parsed to get full details out. For example, storing City State and Zip in a CSZ field instead of three separate fields. Data validations are complicated and the parsing logic is duplicated throughout the system. It is almost always better to store this data unparsed, just as it is always better to store the components of a calculation and not just the result.
Test Driven Database Development (TDDD)
Test Driven Development for our code is nothing new, but the techniques of testing the DAL from the application layer are not as well-known. We will often ignore the database all together, testing our business logic against mock objects. But we are left skipping the foundation that our application is built on.
One approach is to use the unit testing framework used to test your application logic to test the mapping for the OR/M. This could take the form of a test for each persistent object that will simply retrieve a record and ensure that there are no errors thrown.
If you are using stored procedures instead of an OR/M, your testing approach may center on invoking each stored procedure. You can, at least, test to verify that the parameters are the same. You can also verify that the columns in the result set have not changed
You may want to setup a test-bed that will insert a record, update the record, retrieve the record verifying the updates, and delete the record when you are through. This will ensure that all of your CRUD operations are in place and valid. You will need to also to test for the concurrency of these operations under stress, and be certain that they are atomic and consistent under high loadings.
You may also want to include tests to verify that key reference data is configured properly. Alex Kuznetsov has explored these issues at length over several articles. It is important to test from both the perspective of your code and the databases to not only ensure that the data access logic works but that it works in the context of your application.
Obviously these will take longer to run than tests that are run in memory against mock objects. I will often set these up in a separate test project. You don’t need to run through these tests as often as you would your continuous integration, but they should be a regular part of your development processes.
Configuration Management of Database Artifacts
Most shops have adopted strong configuration management for the code artifacts. We wouldn’t dream of not having source code under version control. It is usually a foregone conclusion that version control of some sort is available for your code, but a version control for your database artifacts is a luxury that far too few teams enjoy.
Red Gate provides a tool, SQL Source Control 2.0 that will allow you to integrate with your existing Version Control System. This also brings the power of SQL Compare and Data Compare into the mix to quickly identify what revisions a database is missing and fix it.
Adding version control for your database artifacts to your development life cycle will greatly improve the quality of your development process, and allow you to do continuous integration.
Train developers in Basic Data Skills and Train DBAs in Basic Development Skills
On his web site Scott Ambler talks about what he calls the Cultural Impedance Mismatch. We are all familiar with the Technological Impedance Mismatch that exists between Relational Databases and Object Oriented programs. We often have similar problems interacting with the individuals responsible for developing or maintaining them. This problem stems from a lack of understanding on both sides for the issues confronting the other side.
Some signs that you might have this problem include:
- DBAs who believe that developers are the biggest threat to their databases
- Developers who will resort to anything to avoid seeking help from a DBA
- Developers who believe that because they’re using a persistence framework they don’t need to understand anything about the underlying data technology
- DBAs who complain about the data messes created by application developers but are reluctant to get involved in improving the training
The only way to combat this is training on both sides. We must learn what the other side does; gain an appreciation for their skills, and challenges. Only through working together from a position of respect can we solve the challenges our industry faces. We get caught up playing blame games among ourselves, but from the outside looking in, we are all blamed for failed projects and no one else draws the distinctions that we do.
Conclusion
Refactoring the database is the next step in developing an evolutionary approach to application development. This is more challenging than refactoring code, but there are also great rewards. Imagine how much smoother your project would run if instead of forcing a database to support an application that it was not designed for you could evolve the database to keep up with the evolution of the application. No matter how much we may wish it was different, requirements change. We all need every tool we can get. Refactoring the database is a great tool to make sure that we have at our disposal.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved


Load comments