
Anyone reading this true tale of a (software) horror story, who is of a nervous disposition, can be reassured that it has a happy ending, but it has a moral too. It’s a sadly common story of legacy code, performance bottlenecks, (very) long-time caching, localization and hot CPUs busy at over 90% for no apparent reason. The plot involves a team of gurus who evolved a working system with the declared goal of making it super-scalable. At some point our hero was called in to fix the legacy code, and while he was struggling with it a bunch of HTTP 503 messages appeared in the log, and it started taking longer to open the home page of the site than going through the queue in the cafeteria at peak time.
Our hero made his own mistakes as well, but learned-or just refreshed-a lot of things about what it means to build ASP.NET web sites for the real world. In the end, I think that there was one core reason for the hassle: Paraphrasing Don Knuth, I dare say that, yes; premature scalability is another root of most of the software evil we face these days.
The Background
Once upon a time, there was a web application created in the classic four layers of DDD (Domain-Driven Design) – presentation, application, domain and infrastructure. The system was all in a single tier, quite compact and efficient. It didn’t have to support the typical million users that most architects and customers aim at. It was a humble system that was not expected to exceed the peak of a few hundred users simultaneously connected. When it first went to production, the system was right, just right, for the job; and, more importantly, it never gave signs of inadequacy. The ASP.NET process at the gate was briskly receiving and dispatching requests. Each request made it quickly to the SQL Server instance where an active list of threads was rapidly processing queries and updates and return data promptly.
What If We Make It More Scalable?
One of the Gurus posed the question “What If We Make It More Scalable?”
“The system has no intermediate cache in the backend”, he noted, “so it won’t scale properly. Also we should make it multi-tier to get ready for scaling up at any time.”
“In particular”, he said, “putting the SQL Server repositories behind a HTTP façade would be beneficial to us in two ways. Firstly, it gives us a reusable API that we can call in the same way from any sort of clients, including mobile applications. Second, we can host this API wherever we like; and if we host the API in an Azure web role we can scale up and down whenever we need to.”
The other Gurus nodded wisely. It all sounded very plausible. A Web API layer was created to hide any SQL Server details to the application layer of the frontend web site. The system went to production and it was immediately clear that the performance was not the same. The figure below attempts to explain how the problem was then tracked down.
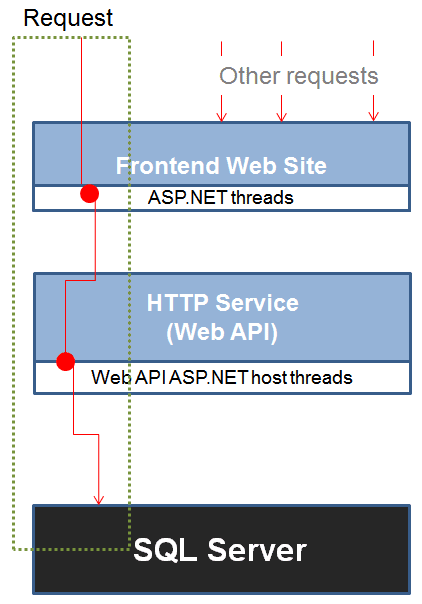
ASP.NET assigns each incoming request to a thread from its own pool and the thread remains engaged until the response is generated for the request. This means that one less thread is available to serve other concurrent requests. This is unavoidable if the thread is actually busy doing some CPU work. However, you’ll see from the figure that the ASP.NET thread was just waiting for the HTTP service and the SQL Server instance to do their work. With the architecture depicted in the figure, the cost of data serialization had become significant. In a single tier, all data is moved within the same process space and no serialization really occurs, except for the super-optimized, and inalienable, data transfer in and out of the SQL Server process. Transportation costs increase when a service is placed behind a HTTP façade. In the first place, there is the cost of the HTTP call. Secondly, you have the cost of serializing input data from HTTP chunks to usable values to arrange queries or updates. Finally, there is the cost of serializing any SQL Server response to some text format, most commonly, JSON, that can be sent across the wire.
After an overnight technical meeting, the team of Gurus determined that the quickest fix to apply was to introduce some intermediate cache in the HTTP service to reduce the response time.
“Having some cache right under the surface of the HTTP layer of services” the gurus said, “is helpful because it reduces the load on SQL Server while enabling admins to vary the cache duration according to detected traffic”.
As it happened, having the cache helped; and it improved the average response time enough for the system to go live.
Sadly, this sort of fix could only postpone the inevitable problem. At some point, the number of users visiting the site started increasing and other clients, mostly mobile applications, were built to consume the same HTTP façade. As a result, the number of requests concurrently knocking at the door of the HTTP service grew significantly enough to compromise response time again. This time, though, there was no chance of further increasing the cache. This would have frustrated the primary purpose of the site and offered uselessly-stale data to users.
The Generous Hero and Output Caching
Our hero, who inherited the legacy code to fix it, had to work out a plan and implement some working artifacts quite quickly. The first thing he tried was adding an output-cache layer.
By turning on the ASP.NET output cache, he instructs the runtime to cache the response of any given controller actions for a configurable amount of time. In this way, the same content does not need to be generated over and over again when the same controller action is invoked. This would relieve the pressure on the web server and internal components by resolving a proportion of requests at the gate without triggering the process lifecycle. The ASP.NET output cache works by varying the cached output according to a number of parameters. The most common scenario is like below:
|
1 2 3 4 5 |
[OutputCache(Duration=60, VaryByParam="*"] public ActionResult Details(int id) { ... } |
The method decorated with this attribute caches its response for a minute and a copy of the output is saved for any value of the ID parameter being passed. This means that ASP.NET creates distinct entries in the cache for the output of /details/1 and /details/2 and any other value of any other method parameters. The output cache is stored in the ASP.NET cache with a time-based dependency. When the time expires, the entry is silently removed from the cache. In this way, the next request that comes for the same URL can’t be served from the cache and goes through the regular request lifecycle. The output is cached again and the process repeats. The benefits of output caching are obvious, and take effect immediately.
Unfortunately for our hero, the system also had a couple of features that made output caching a bit harder to implement. One was the multi-tenant nature of the site and the other was the localization of large chunks of the content.
A multi-tenant site is a web application that changes skins and functions depending on the tenant. For example, a CMS or a blog engine is a multi-tenant app in the sense that the same core codebase serves different users and each user has its own URL. Without an explicit check on the absolute URL, the /details/1 page is cached in a single copy regardless of whether it comes from tenant 1 or tenant 2. A few minutes after setting up output caching support calls arrived complaining that news of user 1 appeared to user 2 and vice versa. More or less at the same time, a support call arrived because page X was first displayed in English and then in Japanese regardless of the language preference set by a particular user. The following code in global.asax fixes the multi-tenancy issue:
|
1 2 3 4 5 6 7 8 9 10 |
public override string GetVaryByCustomString( HttpContext context, string custom) { if (custom == "FullUrl") { var key = context.Request.Url.AbsoluteUri; return key; } return base.GetVaryByCustomString(context, custom); } |
The VaryByCustom feature of ASP.NET output caching is helpful when you want to take care yourself of the logic that multiplies copies of cacheable views. The code in global.asax lets you specify on a per-request basis the key that the system uses to vary cached copies. The key selected in the example is the full URL of the request. This means that /tenant1/details/1 is now cached separately from /tenant2/details/1. To enable custom strings in output caching you must add the VaryByCustom attribute to the controller method attribute:
|
1 2 3 4 5 |
[OutputCache(Duration=60, VaryByParam="*", VaryByCustom="FullUrl"] public ActionResult Details(int id) { ... } |
What about localized versions instead? If the current language ID is carried via the URL then it would fall in the realm of the custom string setting. Otherwise the VaryByHeader attribute is an option to evaluate. VaryByHeader lets you use a specified header name to distinguish copies of cached content. Which header, though? At first, it may seem that ‘accept-language‘ is the perfect choice. Unfortunately, its effectiveness depends on the logic that the site actually uses to switch language. The ‘accept-language‘ header indicates the language of the browser which is just one way for a multi-lingual site to switch content. If the site relies on explicit user’s preference or geographical detection then the ‘accept-language‘ header approach wouldn’t work. The application in question, though, used cookies; therefore the right header to use was Cookie.
|
1 2 3 4 5 |
[OutputCache(Duration=60, VaryByParam="*", VaryByCustom="FullUrl", VaryByHeader="Cookie"] public ActionResult Details(int id) { ... } |
It’s interesting to notice that the effectiveness of output caching also depends on the location where cached content is stored. By default, ASP.NET caches the output anywhere possible. This means that most content stays cached on the browser and never hits the server. This fact forces us to use VaryByHeader to cache by language. As an alternative, you can set Location equals to Server and generate a language specific key in GetVaryByCustomString.
Our Hero and the HTTP 503 Error
The performance relief for a decent response time that came from output caching was short-lived. As the number of simultaneous users increased again, the site became almost entirely unresponsive because too many requests were held in a queue. The service was just too slow to match the pace of incoming requests. When HTTP 503 error pages started to appear, it became obvious that the story about the long queue was not simply a joke. In IIS, a web site is usually allowed to have a queue of pending requests no longer than 1000 requests. It’s crucial to note that a request here means a plain request from a browser-for a CSS file, an image, an Ajax call, a full HTML page. Each browser can have a few (typically, six) concurrent sockets opened and a canonical page of a modern site usually requires more than six requests to complete. Furthermore, most page requests were hitting the HTTP façade which, even with the cache turned on, at some point became not so quick to respond.
It was clearly a design issue, but what could our hero do to fix the site right away?
In general, the first option to consider to improve performance is reduce pressure on the site adding caching layers. However, there was already a cache in the HTTP service and that was not enough. Also, there was already a cache at the IIS gate (the ASP.NET output cache) and it was also not enough because the nature of the site didn’t allow for too long caching as requests were coming along too quickly. Another option is to rewrite bits and pieces of the controller layer in an asynchronous way. In a multi-tier schema, such as in figure above, where should you intervene first to add asynchrony? Should it be the frontend web site or the Web API layer? Both layers would gain from async controllers.
Our hero was running out of time and under intense pressure, so he just focused on the frontend site. The HTTP façade had already some caching in place, and a quick intervention on the frontend site would have also speeded up requests for simpler pages and auxiliary resources. This was hardly a decisive help, but would give users the perception of a more responsive site. It is one thing to be frustratingly looking at the hourglass; quite another to looking at the hourglass, feeling angry but slowly receiving content. Suppose you have a synchronous controller method as below:
|
1 2 3 4 5 6 |
[HttpGet] public ActionResult Index() { var model = _service.GetIndexViewModel(); return View(model); } |
Here’s a possible way to quickly rewrite any controller so that it leverages asynchronous capabilities in ASP.NET MVC.
|
1 2 3 4 5 6 7 8 9 10 |
[HttpGet] public async Task IndexAsync() { return await Task.Factory.StartNew(InvokeIndex); } private IndexViewModel InvokeIndex() { var model = _service.GetIndexViewModel(); return View(model); } |
In addition, yet another caching layer of a few seconds was added on the frontend so that a smaller number of requests were actually hitting the HTTP layer.
A more ambitious and deeper rewrite would probably turn the middle tier into an async layer. However, these little changes quickly fixed the dramatic performance issues of the website. At least for the range of users that commonly visit the site, performance was again just right: As right as it was before an incautious attempt to scale the site was made. The net effect is that performance was fixed; but the site is not scalable at all.
Moral of the Story
A system that was originally fine-tuned, compact, simple and efficient was inadvertently turned into a ‘finely-tuned’ system as slow and cumbersome as a tuna in the net, and as lively as tinned tuna. Beyond all the incautious design choices, and the additional mistakes made along the way, I think there’s a noticeable moral in this software horror story. These days, scalability is better achieved with a super-optimized and compact single tier web application that is then deployed to some cloud infrastructure. When, and if, it faces high traffic levels, it can then be promptly fine-tuned to cope with the traffic levels it faces.
Manually created tiers are still an option, sometimes an undeniably reasonable option, but manual tiers require a lot of care and careful multi-threading and caching instructions. And if you fail at that, well, you’ll have a (software) disaster on your hands.
PS: A similar project created later facing the same traffic works beautifully in production. It’s single tier and makes plain direct calls to SQL Server with only a little bit of output cache. No data caching, no HTTP intermediary; just the pure power of IIS and SQL Server. OK, it’s not like, say, Facebook, but the customer on the other hand didn’t ask to build a social network scale system!
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments