
The series so far:
It’s an easy guess that only a small fraction of today’s developers had a chance to experience what it was writing code in the 1990s or even in the early 2000s. In many cases, every developer used to write code on her own machine and then manually merge it to other versions of it possibly managed by teammates. Maintaining a clean and clear history of different versions of the code was, for the most part, an unattainable dream. It was definitely quite a naïve approach, but quite common, too. It wouldn’t last for too long, however.
In this article, I’ll go through the motivation that in two decades brought the creation of a number of source control systems up to Git—the universal standard these days.
A Bit of History
Since the early days of software development, those who had to produce large and solid codebases, such as the components of an operating system like Unix, felt the need for a control system that was able to track all the changes being made over time. Historically, the first attempt to build such a control system dates back to the early 1970s, but it was only a decade later that it solidified into a common-use tool, although fairly limited in both functionality (only individual text files tracked) and usability (only single users).
The first centralized source code control systems appeared in the 1990s, and Perforce was the most popular of them. Perforce was widely used within Google and was the de facto standard that most companies used in the years of the Internet bubble. Then came Subversion, the product that introduced features comparable to those we have in modern tools today. Subversion extended tracking capabilities to non-text files and, more importantly, shifted the tracking focus from the individual file to the individual directory. This allowed tracking of all file operations including renames, moves and deletes.
On the Microsoft side, the history of source control systems is curious and worth a look. Microsoft had SourceSafe—its first source control system—back in the 1990s. Technically, it was a product originally developed by another company that Microsoft just bought. Microsoft kept control over the development of SourceSafe only for the Windows platform and delegated the development of the product for Mac and Unix to other companies. For many years, SourceSafe was only a local source control system and not specifically designed for a multi-user environment. Only in its final release (dated 2005), SourceSafe became a product that was able to work in a client/server mode—definitely too late. Interestingly, very few development teams within Microsoft ever used SourceSafe for their own activity. Most teams opted for a customized version of the Perforce product named SourceDepot.
In 2004, the same Microsoft, however, released a brand-new source control product—Team Foundation Server (TFS)—sold as part of Visual Studio Team Systems, a larger lifecycle management product. The most relevant aspect of TFS was the tight integration with the Visual Studio environment that enabled developers to check their code in and out right in place. In addition, TFS introduced support for bug tracking, work items, and automated testing.
In a way, the initial version of TFS was the last of a closing era. The new era was the era of distributed source control systems.
Distributed Source Code Control
The key difference between a distributed and a centralized source code control platform is the currency that users of both systems exchange with the main server. In a centralized, old-style system, the currency is the list of changes made locally. In a distributed scenario, instead, the currency is the whole code repository. The picture below shows the architecture of a centralized source control system.
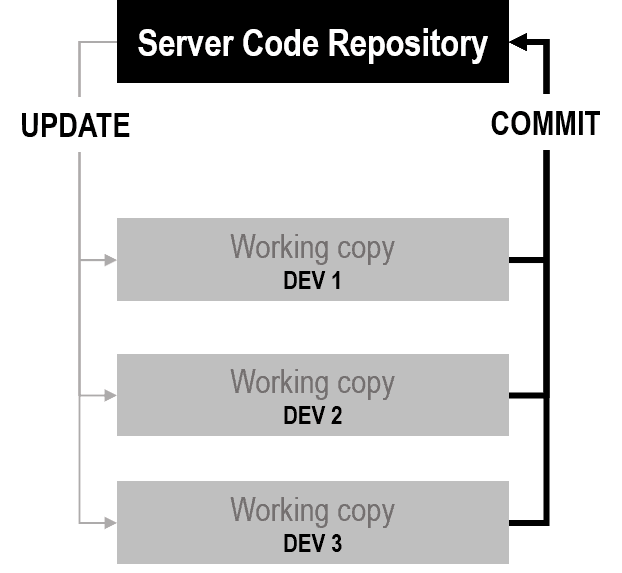
As you can see, multiple users download the latest updates autonomously from the server, then work on it locally on their machines and, at some point, they commit it back to the server. In a distributed scenario, there’s an additional layer of code and data in the middle. Here’s the architectural diagram of a distributed source code control system.
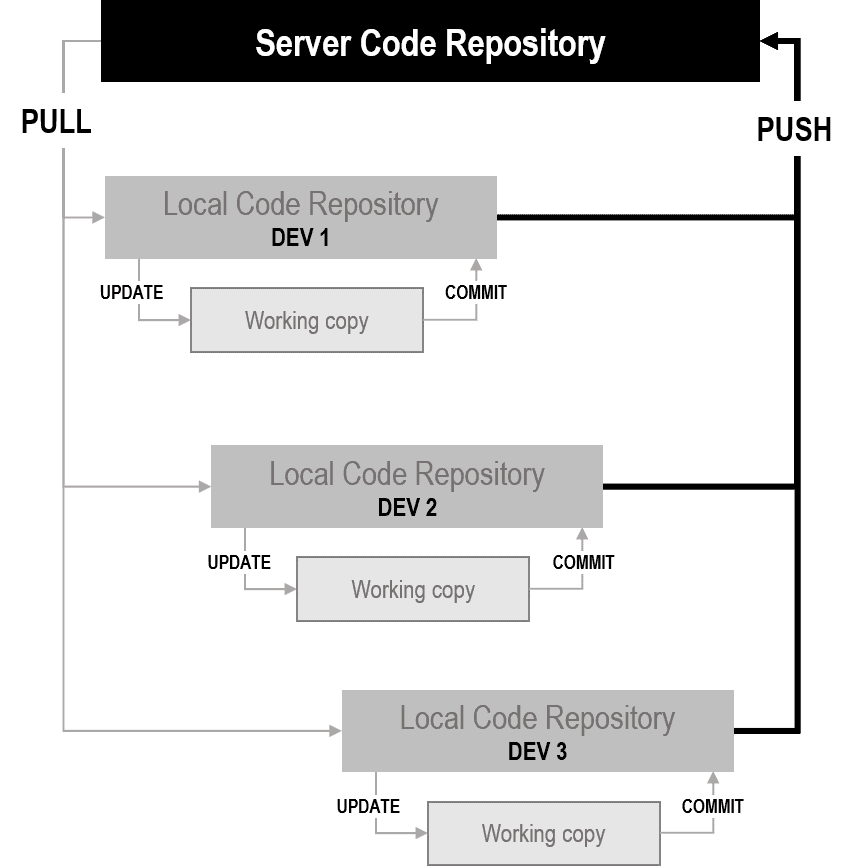
Active users own a local repository and can share it with the server and/or with other individual users. Put another way, the distributed system allows developers to share code between nodes of a distributed network of repositories. On every single machine, the local code repository is updated through update and commit commands. Synchronization with the main server, instead, goes through the pair of pull and push commands.
The distributed approach is mainstream today thanks to Git, and it is even more interesting to trace back how exactly Git came up and why.
The Birth of Git
As you may know, Git was written by Linus Torvalds around 2005. For many years, the community of contributors to the Linux’s kernel didn’t use any version control systems at all. For them, the typical commit procedure was like this:
- Post changes to a specific mailing list
- Have Linus in person approve and apply changes to his own source tree
- Wait for the green to download any Linus-validated new source tree
It worked in some ways, but specific patches were indistinguishable from one another, and changes were detectable only through a giant diff between two consecutive releases of the main source tree. In 2002, when such a way of working became no longer sustainable, Linus surprisingly picked up a commercial versioning product—BitKeeper—over the variety of free tools doing the same job.
Torvalds justified the choice with the edge that, feature-wise, BitKeeper could give to competitors. BitKeeper was a distributed source code control system whose workflow was a perfect fit for the kernel group workflow. Secondly, BitKeeper made it ridiculously simple to fork and merge even large code repositories. The combination of these two factors was the rationale behind an otherwise weird choice. With BitKeeper, in fact, selected small groups of trusted developers could work and sync autonomously and submit to Linus only the final result to integrate in a fully trusted manner. Torvalds, though, managed to get a free community edition of BitKeeper in return of some restrictions mostly aimed at protecting the intellectual property of BitMover—the company behind the product.
For the next three years, prominent members of the Linux community worked hard to create a brand-new distributed source code control tool that could replace BitKeeper. None of them, though, got enough feedback from Torvalds to go straight to the point that could make the new tool technically superior to BitKeeper. Then in 2005, all of a sudden, it all changed and for a completely different reason. As a harsh reaction to a documented attempt of reverse-engineering the source code, BitMover discontinued the free use of BitKeeper for the Linux kernel development team.
In a matter of months, in the middle of 2005, Torvalds created the Git engine and made it fast, strong, and solid enough to be suitable to sustain the development of a large, and largely distributed, project such as the Linux kernel. After that, Torvalds handed the whole development of Git over to Junio Hamano and returned to focusing on Linux kernel development.
The Philosophy of Git
At first, Git looked quite weird to the eyes of many Linux developers. It was sold as the source code control system of choice but did not resemble any of the most popular source control systems of the time. In particular, it looked different for one key aspect. Instead of storing the delta between old and new versions of the same file (aka, patches), Git stored the whole updated file side by side with a copy of the original file being modified.
Such an unusual approach was strictly functional to the Torvalds’ primary goal: keeping it blazingly fast! Having just to copy and/or replace files on the target repository, in fact, enables Git to handle forks, merges and generate patches quite quickly. The original operations that Torvalds devised—too much low level and file-oriented—have been abstracted away by Hamano over time. The result is Git as we know it today—the de facto standard distributed version control system for tracking changes in source code. What makes Git fairly unique in the landscape of version control systems is that every directory on every computer is a repository with its own history of changes. In other words, Git enables individual developers to host locally a full-fledged version control system that works independently of network access but can optionally be synced to a remote repository.
Git is open-source software available at https://git.kernel.org/pub/scm/git/git.git/ and is distributed under version 2 of the GNU General Public License. In 2016, eleven years after the break-up with the Linux kernel development group, quite ironically, BitKeeper was turned into an open-source product under the Apache License 2.0. (See https://www.bitkeeper.org.)
Finally, here’s a note on the name. According to the Merriam-Webster dictionary, the word “git” indicates a foolish or worthless person but can also be taken for a dialectal version of the verb “get”. Here, in the original readme file written by Torvalds, it is presented as the “information manager from hell” and the “stupid content tracker”.
https://github.com/git/git/blob/e83c5163316f89bfbde7d9ab23ca2e25604af290/README
Git and All the Rest of Them
According to Wikipedia, at the moment about 30 different products are actively developed and enrolled in the virtual competition for the “best source code control system” award. They differ in a number of factors including the platforms supported, the license through which they are made available, and the cost. Let’s see a few of them.
Azure DevOps. Owned by Microsoft, it runs on Windows but is reachable as-a-service from other platforms. It’s free for open-source projects and as-a-service for up to 5 users. Otherwise, it is licensed through an MSDN subscription.
Mercurial. Developed by Matt Mackall, it runs on Windows, macOS and Unix-like operating systems. It’s free for use under the GNU GPL license.
Helix. Owned by Perforce, it runs on Windows, macOS and Unix-like operating systems. It’s available for sale through a perpetual license or subscription.
Subversion. Created by Collabnet, it runs on Windows, macOS and Unix-like operating systems. It’s free for use under the Apache license.
ClearCase. Owned by IBM Rational, it runs on Linux, Windows, AIX, Solaris and a bunch of other IBM operating systems. It follows a custom pricing model.
CVS. Maintained by a community of developers, it doesn’t receive new features since 2008. Runs on Windows, macOS and Unix-like operating systems, and it’s free for use under the GNU GPL license.
Monotone. Written by Nathaniel Smith and Graydon Hoare, it runs on Windows, macOS and Unix-like operating systems. It’s free for use under the GNU GPL license.
From a more technical standpoint, all source code control systems also vary in the model they use to implement the repository and handle concurrency.
As far as the repository is concerned, two are the main options: client/server (centralized) and distributed. Of the products listed above, ClearCase, CVS and Subversion are client/server whereas Monotone and Mercurial are distributed. Azure DevOps and Helix, instead, support both repository models.
Concurrency refers to the policy the product employs to manage changes to the working copy of the repository. The purpose of the policy is preventing simultaneous edits that may corrupt files. One option is lock, meaning that the write access to any file is only granted to one user in exclusive mode. The other option is merge, meaning that users are left free to edit files but receive a warning any time a conflict may occur. Resolving conflicts is a further step, automatic or manual. CVS, Mercurial and Monotone only support the merge model. The other products in the above list support both models.
Summary
This is the first article of a new series aimed at covering Git as a core product and the universe around it including Github. This introductory article laid the ground of Git and covered the general topic, and partly the history, of source code control systems and offered a quick comparison of alternatives to Git. However, while many alternatives exist, Git is today the de facto standard for tracking changes to files in software projects. In the upcoming article, we’ll begin a journey around the typical operations one could perform with Git.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments