


In today’s cloud-driven, multi-platform environments, answering the simple question – who owns that database? – is no longer straightforward. As teams adopt open-source tools and spin up cloud services on demand, ownership is becoming fragmented across development, operations, and data teams. This shift is accelerating innovation but also creating new challenges in visibility, control, and accountability, as Grant Fritchey explains.
This is the first part of Grant’s mini-series on overcoming cloud migration challenges in 2026.
“Who owns that database?”
Have you ever asked that question (or variations of it using “cluster”, “server”, “instance” instead of database?) And have you noticed that, at the beginning of your migration to the cloud, you’re asking it more and more?
Well, you’re not alone. In Redgate’s 2026 State of the Database Landscape report, development (73%), operations (50%), data managers (65%), and DBAs (69%) report that they must support multiple data platforms across an increasingly hybrid environment. As a result, the fracturing of processes and ownership is almost inevitable.
The questions are, how does this come about – and how are teams dealing with it?
Why is database ownership fragmenting?
In the old days (15 years ago or more), the only time you’d see ownership fragmentation was when you found a database server hiding under someone’s desk, running some type of software that nobody in IT knew about.
Alternately, a group within the organization may have “gone rogue” – purchasing a management tool that ran on a platform you didn’t support. OK, these instances were pretty rare, but nowadays it’s a different picture.
With two major innovations – open-source and cloud adoption – both directly impacting nearly every organization, we’re seeing a lot of ownership issues. Worse yet, the combination of the two is exacerbating the problem.
When it comes to open-source software, it’s simple enough to understand and explain. First, it’s “free” (yes, in quotes because nothing is ever, completely free), or at least license-cost free. That makes implementation pretty simple. No development team needs to go through a procurement or financial approvement process when there’s no money changing hands.
However, that’s not why the best teams are moving towards open source. The real reason is speed of development and the quality of code, especially at enterprise level. The ‘better’ open-source projects (like PostgreSQL) are innovating in ways that a single company working only on their proprietary software can’t replicate.
Between the two, when a new project kicks off, it just makes sense for a wise development team to pick the right tool for the job in question – even if that tool isn’t currently supported by their IT organization. The only limiting factor to this is control over the infrastructure.
If you’re the responsible party for hardware and virtual machines within your on-premises organization, you have the ability to exercise at least some control over this fragmentation of ownership. That is, until your organization starts to use the cloud.
The pros and cons of cloud adoption
A significant benefit of the cloud (and frankly one of the reasons I’ve been in love with the concept since I first heard about it), is the ability to spin up your own platform. You don’t have to wait for permission, or involvement from other teams. You can simply log on to a cloud platform and get your own MariaDB instance running.
Want to work with CosmosDB but as a PostgreSQL compatible data store? Cool. Spin that sucker right up. No waiting, no approvals, and no slowdowns. Also, no oversight, limited monitoring, potentially poor security practices, violations of various compliance requirements…in short, chaos.
The issues don’t end there. Everyone agrees that there are challenges to cloud implementations. However, we don’t agree on what those challenges even are:
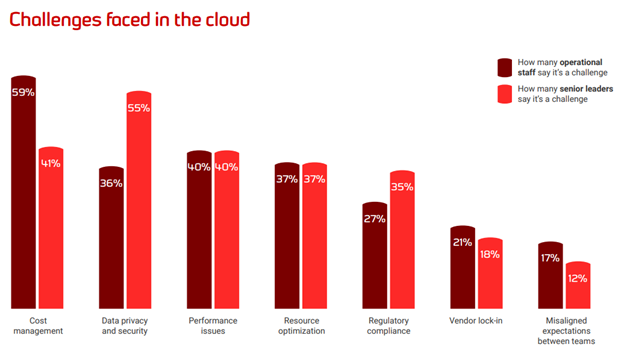
Cost management and security are the leading cloud concerns
You’ll note that technical people are extremely worried about cost management, while senior leaders are clearly less concerned. Yet, start talking security, and senior staff are very clearly worried, while technical staff are relaxed (without a doubt, overly so!)
Most everything else is roughly the same except, again, where senior staff worry far more about compliance than technical people do. All of this creates friction, which isn’t good in an IT environment. Much like friction on an otherwise featureless plane, it causes anything in motion – be it objects/projects/migrations, or all three – to slow down.
For example, it’s easy enough for a team to pick AWS Aurora for PostgreSQL because of its high-performance compatibility and high-availability functionality with the platform. However, if the operations team isn’t ready for automated deployment to that environment, the implementation of the project will slow.
Additionally, if the database team doesn’t have a good set of skills for monitoring, tuning, and ensuring availability for the platform, then it’s possible to see outages or gaps in coverage – again slowing down the cloud migration for the organization.
Finally, the IT team may not even know that this new database even exists. That opens up the potential for the organization to suffer with data breaches or compliance issues.
Cloud adoption is accelerating, but database migrations aren’t keeping pace. Find out why.
How are organizations dealing with database ownership in 2026?
Slow-paced approval and procurement processes slow down – or stop – innovation, and migrations to the cloud. So, what are teams doing to prevent this?
First, it’s all about communication. More people are, thankfully, adopting methodologies and processes that increase communication across teams:
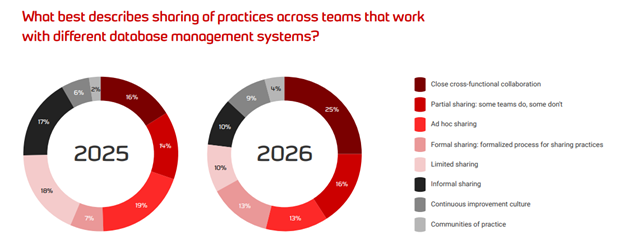
As you can see, the number of teams with a completely informal sharing process has nearly halved year-on-year (17% to 10%). Teams with limited sharing practices have reduced even further, from 18% to 10%.
So – what are they doing instead? Well, they’re adopting the many well-established best practices, the ones that have long been known to work. Put simply: organizations are implementing formal processes and establishing methods of cross-functional collaboration. People across the company are talking to each other.
Part of that talking involves adopting a culture of continuous improvement – an area we’ve seen jump 50% in a year (from 6% to 9%). And one of the most exciting things I see – because I really do believe in sharing knowledge – is that building communities of practice has doubled from 2% to 4% in a year. Yes, that one is still exceedingly small, but it’s growing!
Chris Yates, Senior Vice President, Managing Director of Data and Architecture at Republic Bank, probably put it best when he said:
As organizations modernize legacy infrastructure and scale operations, the challenge is no longer just about moving fast – it’s about moving smart.
Conclusion: how best to establish data ownership in 2026
The issues of database ownership are quite real – as are the issues of ownership around servers, virtual machines (VMs), and the rest of the data platform. As things move faster and faster with open-source adoption and cloud migration, we’re experiencing real friction that ultimately slows down our innovation and migration between platforms.
However, there really are mechanisms – established, documented mechanisms – that can help you improve your processes. It’s mostly a matter of getting the 32% of people who are not following any processes (or a following informal or ad hoc processes), to create more formalized processes within their organization.
In particular, I suggest putting special attention into communities of practice within your organization. You have good people working for you. Encourage them to share with one another, very directly, and you’ll reap the benefits.
Most of all, though, embrace the fact that migrations to new (and more), data platforms are going to occur, and occur at a fast pace. As Chris Yates put it: move smart!
FAQs: Why database ownership is so fragmented in 2026 – and what you can do about it
1. Why is database ownership becoming harder to track?
2. How widespread is the multi-platform database challenge in 2026?
3. What are the risks of untracked cloud database deployments?
4. Do senior leaders and technical teams agree on the biggest cloud challenges?
5. How can organizations improve database governance and ownership in 2026?


This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved


Load comments