
The JOIN statement is one of the most common operations SQL developers perform. Yet in a world ruled by Inner and Left Joins, the poor Full Outer Join is like Cinderella before the ball – allowed out on only the rarest of occasions. In an (unscientific) survey I once performed of SQL developers at one Fortune 100 firm, half of the developers had never used a Full Outer Join in production code, and the rest had used it in a tiny handful of occasions.
The FULL OUTER JOIN (hereafter ‘FOJ’) is generally considered as a tool for rare corner cases such as comparing or merging different table versions, but the objective of this article is to show that its uses go beyond this, even as far as optimizing query performance in cases that most people would never consider. The FOJ is definitely an underappreciated tool. Cinderella has some tricks up her sleeve.
Understanding SQL Join Types
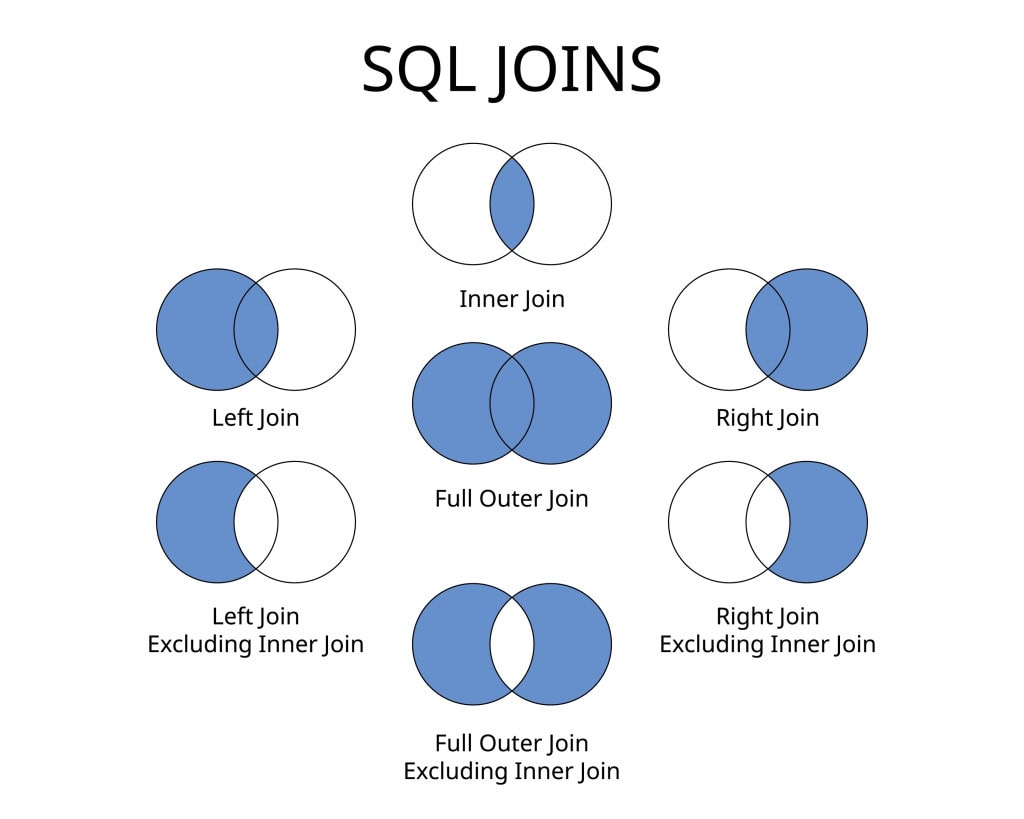
Let’s start with a quick review of the various join types … and how better to do that than with Venn diagrams? The image below illustrates a basic key value join between two tables:
An INNER JOIN on two tables returns all values common between them. (The ‘values’ in this case are those specified in the join condition).
A LEFT JOIN adds non-matching row from Table A, whereas a RIGHT JOIN yields the mirror image of that. Finally, the FULL OUTER JOIN returns everything: all rows from both tables are included, whether or not they match.
When to Use FULL OUTER JOIN
The most common use of the FOJ is in merging tables that contain some degree of overlap. Let’s consider a simple example: a school system database holds parents in one table and teachers in another. We want to combine these into an email list containing both — but some parents are also teachers, and some teachers are also parents. Because some rows exist in both tables, we can’t simply UNION the two result sets together. A UNION DISTINCT might work, but not only is this expensive performance-wise for larger tables, it requires that all retrieved columns be identical, which may not be the case.
With a FOJ, though, this becomes easy. Our (unrealistically simple) example tables look like this:
|
1 2 3 4 5 6 7 8 |
CREATE TABLE teachers ( email varchar(256), workphone varchar(256) ); CREATE TABLE parents( email varchar(256), cellphone varchar(256) ); |
We’ll assume two contacts are identical if their emails match, so our join condition is on email. We also want a contact phone number, which for teachers should be their work number, and for parents, their cell number:
|
1 2 3 |
SELECT t.workphone, t.email, p.email, p.cellphone FROM Teachers t FULL OUTER JOIN Parents p ON t.email = p.email |
(If you wish to experiment with this yourself, Appendix I contains a script that creates these tables and loads sample data).
Structuring the query this way works, but gives a lot of null values — any row that doesn’t exist in both tables will contain nulls on one side:
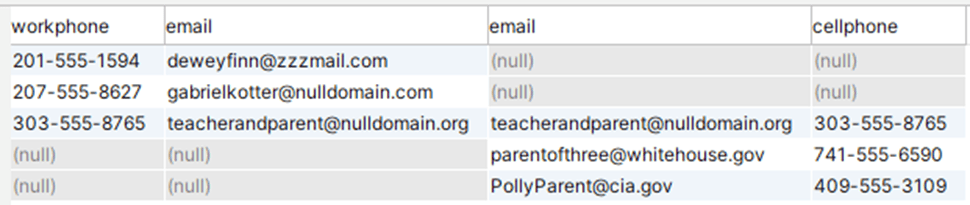
If this is a problem, we can eliminate it by using COALESCE to “fold together” the left and right halves of the result set:
|
1 2 3 |
SELECT COALESCE(t.workphone,p.cellphone), COALESCE(t.email, p.email) FROM Teachers t FULL OUTER JOIN Parents p ON t.email = p.email |
This yields a much more compact result set:
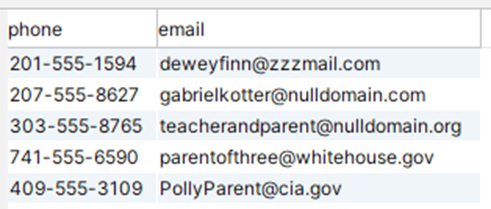
Fast, simple and concise: how can you not appreciate the FULL OUTER JOIN?
The fast and easy way to write, format and debug SQL
Real-World Examples of FULL OUTER JOIN in Action
Now let’s look at a problem for which you might not consider a FOJ. Imagine a table of vehicles held in an extended-stay parking lot. Once per day an attendant goes through the lot and inventories all the vehicles, recording the date and tag number. Our table looks like this:
|
1 2 3 4 |
CREATE TABLE parked_vehicles ( day DATE, veh_tag_no VARCHAR(32) ); |
The task is to write a query that returns all the vehicles that either entered or exited the lot today. In other words, we want two sets of rows:
- All vehicles present yesterday who are not there today
- All vehicles present today who were not there yesterday
The problem, of course, is that we lack vehicle enter and exit dates – they must be calculated from changes in the data. A simple problem … but how best do we solve it?
Being tidy, structured SQL programmers, we begin the query with two Common Table Expressions (CTEs), one defining the “present yesterday” and the other the “present today” list:
|
1 2 3 4 5 6 7 |
WITH yesterday AS ( SELECT * FROM parked_vehicles WHERE day = CURRENT_DATE - '1 DAY'::INTERVAL ), today AS ( SELECT * FROM parked_vehicles WHERE day = CURRENT_DATE ) {...query continues ….} |
Now what? We want a join that gives us all the rows from both tables except where they overlap. In Venn Diagram terms, we want this:
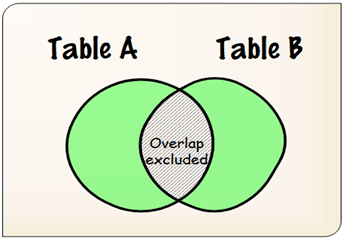
Using the canonical set operator EXCEPT, we would complete the query as:
|
1 2 3 4 5 |
SELECT veh_tag_no FROM yesterday EXCEPT SELECT veh_tag_no FROM today UNION ALL ( SELECT veh_tag_no FROM today EXCEPT SELECT veh_tag_no FROM yesterday ); |
This works, but is very slow, as it must make two passes through the table then combine the results. (Note: since the two EXCEPTs are mutually exclusive, we can use UNION ALL rather than the slower UNION DISTINCT).
Also, with this syntax we can directly select only the vehicle tag number — to get the day column, we need to wrap the EXCEPTs in a join, making the query not only cumbersome, but hard to read as well.
Many developers would use an alternate syntax: maintaining the union, but replacing the EXCEPTs with a NOT EXISTS subquery:
|
1 2 3 4 5 |
SELECT * FROM yesterday y WHERE NOT EXISTS (SELECT 1 FROM today t WHERE t.veh_tag_no = y.veh_tag_no) UNION ALL ( SELECT * FROM today t WHERE NOT EXISTS (SELECT 1 FROM yesterday y WHERE y.veh_tag_no = t.veh_tag_no) ); |
Again, it works, but is no faster than our first try — most SQL dialects will produce the same query plan for this as the one above. If our tables are large, a two-pass solution can be unacceptably slow.
FULL OUTER JOIN to the rescue! Look again at our Venn diagram above. What we want is a query that returns Section A and B only, excluding the Section C overlap. We can do this in a single pass using a FULL OUTER JOIN, with a WHERE clause to exclude the overlapping rows:
|
1 2 3 4 |
…SELECT * FROM yesterday y FULL OUTER JOIN today t ON y.veh_tag_no = t.veh_tag_no WHERE y.veh_tag_no IS NULL or t.veh_tag_no IS NULL |
As we saw above, a simple SELECT * returns two sets of columns: one from each table, and one of which will always be NULL. If that’s inconvenient, we can use the same “folding” technique to eliminate the null values:
|
1 2 3 4 |
…SELECT COALESCE(y.day,t.day), COALESCE(y.veh_tag_no,t.veh_tag_no) FROM yesterday y FULL OUTER JOIN today t ON y.veh_tag_no = t.veh_tag_no WHERE y.veh_tag_no IS NULL or t.veh_tag_no IS NULL |
Using the random data from the script in Appendix I, this executes nearly twice as fast in SQL Server as the UNION approaches above — a significant improvement. The execution plans for each query reveal why: the FOJ query performs a single hash join on the table to itself, whereas the UNION query must perform this hash join twice (scanning our base table four times in total), then merge the results:
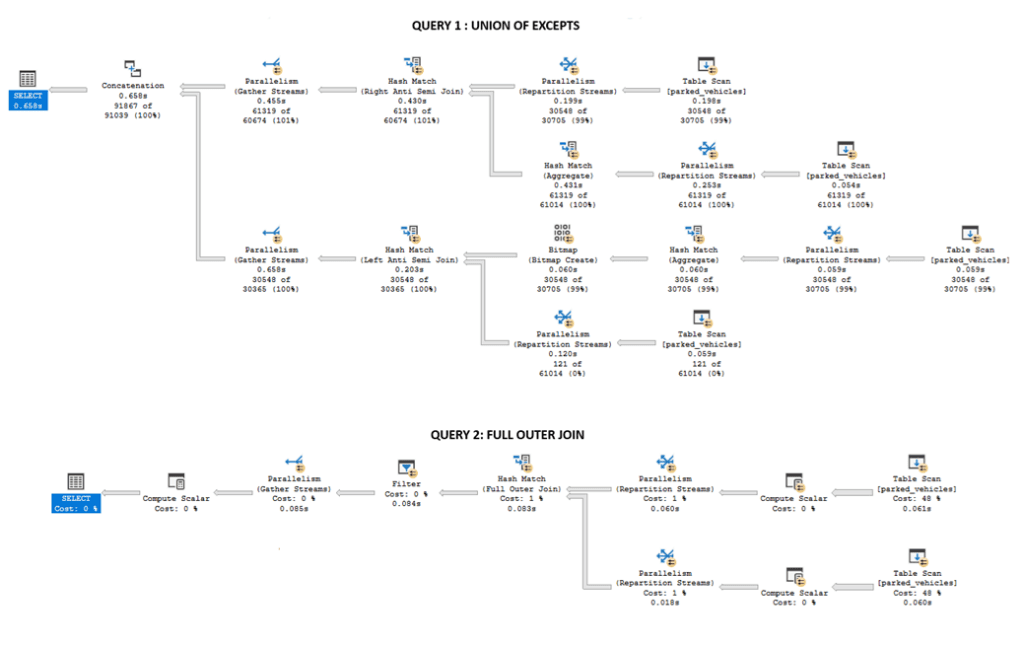
The amount of data retrieved at each step, along with the presence of indexes, etc, will impact the actual performance difference – but there should be no case where the FOJ is slower than a UNION. Simpler is always better.
Enjoying this article?
Exception Reporting
Another case where the FOJ is useful is in identifying broken or missing links in data. For our last example, consider a pair of tables in an auto enthusiasts’ database, to match owners to the vehicles they possess:
|
1 2 3 4 5 6 7 8 9 |
CREATE TABLE owners ( owner_id INT PRIMARY KEY, owner_name VARCHAR(64) ); CREATE TABLE autos ( auto_id INT PRIMARY KEY, owner_id INT NOT NULL, descrip VARCHAR(64) ); |
To be valid, each owner must have at least one registered vehicle, and each auto must also have an owner. Normally, referential integrity like this would be enforced via a database constraint, but let’s assume this didn’t happen for some reason, such as the data being imported from an external source. Our task is to write a query that returns both error types: owners without vehicles, and vehicles without owners.
This is another case where your first instinct likely is to be to UNION together the results of two queries: one for each error type. But again, a FOJ is faster and simpler. We’ll use a WHERE clause to include only the error cases, and, as we did above, use the COALESCE function to eliminate nulls. The actual query is very simple:
|
1 2 3 4 5 6 |
SELECT COALESCE(a.auto_id, o.owner_id) AS "ID", COALESCE('Missing Owner: ' || a.descrip, 'No Vehicles: ' || o.owner_name) AS "Error" FROM owners o FULL OUTER JOIN autos a ON o.owner_id = a.owner_id WHERE a.auto_id IS NULL or o.owner_id IS NULL |
And on our small batch of test data, it yields the following output:
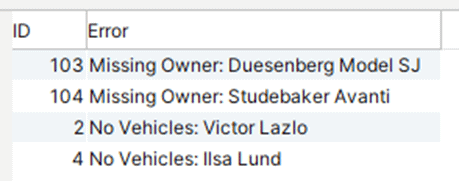
Note: this is the first time in this article we’ve had a 1:M (one to many) relationship between joined tables. That’s fine: FOJ works perfectly well in this scenario. If that’s hard to visualize, think of a FOJ as a LEFT and RIGHT join combined: it returns all rows meeting the JOIN condition, as well as non-matched rows from both tables participating in the join.
Conclusion: Give FULL OUTER JOIN a Chance
FULL OUTER JOIN isn’t simply some historical anomaly of SQL, included only for completeness. Cinderella’s shoe may have only fit one foot, but the FOJ has many use cases for which it is indisputably the best tool for the job. It deserves more respect — and use — than it gets.
To tease Part II of this series, note that our Venn diagrams above apply only for joins where the join condition contains an equal sign. When we join on a different operator — the so-called “non-equi join” — the staid, conservative JOIN statement breaks out the tequila and gets wild.
Appendix I – Sample Script (SQL Server Format)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 |
-- ---------------------------------------------- -- Pt 1: Merging Data -- ---------------------------------------------- -- Create Tables CREATE TABLE teachers ( email varchar(256), workphone varchar(256) ); CREATE TABLE parents( email varchar(256), cellphone varchar(256) ); -- Insert sample data INSERT INTO teachers VALUES ('deweyfinn@zzzmail.com', '201-555-1594'); INSERT INTO teachers VALUES ('gabrielkotter@nulldomain.com', '207-555-8627'); INSERT INTO parents VALUES ('PollyParent@cia.gov', '409-555-3109'); INSERT INTO parents VALUES ('parentofthree@whitehouse.gov', '741-555-6590'); INSERT INTO teachers VALUES ('teacherandparent@nulldomain.org', '303-555-8765'); INSERT INTO parents VALUES ('teacherandparent@nulldomain.org', '303-555-8765'); -- test query (standard version) select t.workphone, t.email, p.email, p.cellphone FROM teachers t FULL OUTER JOIN parents p ON t.email = p.email -- test query (folded version) select COALESCE(t.workphone,p.cellphone) AS phone, COALESCE(t.email, p.email) AS email FROM teachers t FULL OUTER JOIN parents p ON t.email = p.email -- ---------------------------------------------- -- Pt 2: Optimizing a Query with FOJ -- ---------------------------------------------- -- Create Table(s) CREATE TABLE parked_vehicles ( day DATE NOT NULL, veh_tag_no VARCHAR(32) NOT NULL ); -- Insert 90 days of random data. Tag #s are composed of eight random chars. INSERT INTO parked_vehicles SELECT TOP 2500000 DATEADD(D,-ROUND(RAND(CHECKSUM(NEWID())) * 90,0),GETDATE()), SUBSTRING(CONVERT(varchar(255),newid()),1,8) FROM sys.objects AS O CROSS JOIN sys.objects AS O2 CROSS JOIN sys.objects AS O3; -- Query Form 1: EXCEPT WITH yesterday AS ( SELECT * FROM parked_vehicles WHERE day = CAST(DATEADD(d,-1,GETDATE()) AS DATE) ), today AS ( SELECT * FROM parked_vehicles WHERE day = CAST(GETDATE() AS DATE) ) SELECT veh_tag_no FROM yesterday EXCEPT SELECT veh_tag_no FROM today UNION ALL ( SELECT veh_tag_no FROM today EXCEPT SELECT veh_tag_no FROM yesterday ); -- Query Form 2: Sub-selects WITH yesterday AS ( SELECT * FROM parked_vehicles WHERE day = CAST(DATEADD(d,-1,GETDATE()) AS DATE) ), today AS ( SELECT * FROM parked_vehicles WHERE day = CAST(GETDATE() AS DATE) ) SELECT * FROM yesterday y WHERE NOT EXISTS (SELECT 1 FROM today t WHERE t.veh_tag_no = y.veh_tag_no) UNION ALL ( SELECT * FROM today t WHERE NOT EXISTS (SELECT 1 FROM yesterday y WHERE y.veh_tag_no = t.veh_tag_no) ); -- Query Form 3: Full Outer Join WITH yesterday AS ( SELECT * FROM parked_vehicles WHERE day = CAST(DATEADD(d,-1,GETDATE()) AS DATE) ), today AS ( SELECT * FROM parked_vehicles WHERE day = CAST(GETDATE() AS DATE) ) SELECT COALESCE(y.day,t.day), COALESCE(y.veh_tag_no, t.veh_tag_no) FROM yesterday y FULL OUTER JOIN today t ON y.veh_tag_no = t.veh_tag_no WHERE y.veh_tag_no IS NULL or t.veh_tag_no IS NULL -- ---------------------------------------------- -- Pt 3: Exception Reporting -- ---------------------------------------------- -- Create table(s) CREATE TABLE owners ( owner_id INT PRIMARY KEY, owner_name VARCHAR(64) ); CREATE TABLE autos ( auto_id INT PRIMARY KEY, owner_id INT NOT NULL, descrip VARCHAR(64) ); -- Sample Data INSERT INTO owners VALUES (1,'Rick Blayne'); INSERT INTO owners VALUES (2,'Victor Lazlo'); INSERT INTO owners VALUES (3,'Louis Renault'); INSERT INTO owners VALUES (4,'Ilsa Lund'); INSERT INTO autos VALUES (101,1,'Porsche 911 GT3'); INSERT INTO autos VALUES (102,3,'Ferrari 250 Testa Rossa'); INSERT INTO autos VALUES (103,5,'Duesenberg Model SJ'); INSERT INTO autos VALUES (104,6,'Studebaker Avanti'); -- Test query SELECT * FROM owners o FULL OUTER JOIN autos a ON o.owner_id = a.owner_id WHERE a.auto_id IS NULL or o.owner_id IS NULL -- Test query (folded version) SELECT COALESCE(a.auto_id, o.owner_id) AS "ID", COALESCE('Missing Owner: ' + a.descrip, 'No Vehicles: ' + o.owner_name) AS "Error" FROM owners o FULL OUTER JOIN autos a ON o.owner_id = a.owner_id WHERE a.auto_id IS NULL or o.owner_id IS NULL |
FAQs: Understanding FULL OUTER JOIN in SQL Server
1. What is a FULL OUTER JOIN in SQL Server?
2. How is it different from INNER JOIN or LEFT JOIN?
3. When should I use a FULL OUTER JOIN?
4. Does FULL OUTER JOIN impact performance?
5. Can FULL OUTER JOIN be combined with WHERE clauses?
Yes, you can apply WHERE conditions, but be careful – they may filter out NULLs and defeat the purpose of a FULL OUTER JOIN.






Load comments