

Consider the last few database bugs you had to fix: Were they easy to find? When you fixed them, how sure were you that something else didn’t break? Did it result in an incorrect value being recorded? Was the user presented with erroneous data? If so, were they aware of it at the time, or were they unaware and it resulted in a potentially poor (or even dangerous) decision?
SQL code controls how data is retrieved, stored and maintained in many applications. It includes views, stored procedures, functions, triggers, the creation of tables and the relationships between them, and query statements embedded in other programming languages. Writing this code often involves decisions about the nature of data being processed, complicated joining and filtering to retrieve or modify the correct data, performance tuning, data cleansing, replication and data maintenance. In far too many cases, the testing performed on this code is insufficient to prevent serious defects.
Much of the testing done on SQL code today involves manually executing the code on a copy of production data and hand checking the results. Manual testing results in a laborious process and some test cases being forgotten as the code changes. Using existing data means that the code is not tested against cases that are not currently in the system, but may be tomorrow. Hand checking the results introduces subjectivity and human error to the process.
Sophisticated database developers have tried their hand with the unit testing tools available for SQL testing. However, many abandon their efforts as test case maintenance using these tools becomes prohibitively expensive. There are two primary reasons for this expense: making changes to the single set of data used to populate the test database causes test cases to break; or the test cases break as the structure of the database changes.
Many attempts at database unit testing prescribe a pre-populated test database which includes the record required by the tests. If a new test case is written that requires data that is not in the test database the existing data must be augmented. It does not take long before augmenting data for a new test case causes several other test cases relying on the same data set to break. Furthermore, some test cases become impossible to write with the existing test data. For example, a test case which tests the result of a query when data does not exist with certain criteria.
The solution to the problem of data sharing is to have each test case create its own set of test data. Each test case assumes an empty or nearly empty database. At the beginning of the test, the test case inserts all of the data required for the test case to execute. In order to satisfy constraints, data will often need to be inserted into columns and tables which are unrelated to the code being tested. As the number of test cases grows, there will be more places that must be updated if a column is modified or a table with a foreign key constraint is added.
The tSQLt unit testing framework for SQL Server was created to address these problems. It allows each test case to create the necessary data, while eliminating the pain of test case maintenance due to unrelated schema changes. It is a freely available, open-source project which can be downloaded from: http://www.tsqlt.org..
A Simple Test Case
Let’s walk through some examples of unit test cases written in tSQLt to look at how it solves these problems. Imagine we have an application that accepted user-entered input for daily temperature data, and recorded it in a table. The application started off rather informally so no restrictions were put on the data the user could enter, but now we need to make serious use of the data so we need to interpret consistently. Here’s an example of some of the data in the DailyWeatherInfo table:
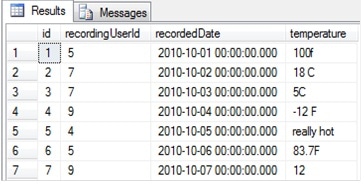
There may be other data in the table, and by the time we deploy our solution, there might be new records which we haven’t seen before. One of the things we’d like to do is standardize all the values to the same system. We’ll choose Celsius for this example and, for simplicity, work with output values rounded off to the nearest integer value only. We’ll need a Fahrenheit to Celsius conversion function. Let’s write our first test case:
|
1 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 EXEC tSQLt.NewTestClass 'TemperatureCleansing'; GO CREATE PROCEDURE TemperatureCleansing.[test 32 Fahrenheit converts to 0 Celsius] AS BEGIN DECLARE @celsiusValue INT; SELECT @celsiusValue = dbo.ConvertFahrenheitToCelsius(32); EXEC tSQLt.AssertEquals 0, @celsiusValue; END; GO EXEC tSQLt.Run 'TemperatureCleansing'; |
First (line 1), creates a new test class. A test class is a grouping of related test cases. In reality, a test class is a schema in the database. When we create the test case procedure on line 4, we create it on the test class schema. Notice how on line 14 we can refer to the test class name when we write run the test.
tSQLt allows test case names to have numbers, spaces and most other symbols in the name as long as it conforms to the naming standards of SQL Server stored procedures and the name starts with the word “test”. tSQLt identifies stored procedures on a test class schema whose name starts with the word “test” as test cases.
Lines 7 and 8 execute the function that we want to test and store the result in the @celsiusValue variable. Line 10 compares the expected result (0) with the actual result (@celsiusValue). If the two values are not equal, then the test case fails.
Let’s look at the result if the ConvertFahrenheitToCelsius function has a bug and returns 5 instead of 0:
|
1 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 [TemperatureCleansing].[test 32 Fahrenheit converts to 0 Celsius] failed: Expected: <0> but was: <5> +---------------------+ |Test Execution Sumary| +---------------------+ |No|Test Case Name |Result | +--+-----------------------------------------------------------------+-------+ |1 |[TemperatureCleansing].[test 32 Fahrenheit converts to 0 Celsius]|Failure| ------------------------------------------------------------------------------ Msg 50000, Level 16, State 10, Line 1 Test Case Summary: 1 test case(s) executed, 0 succeeded, 1 failed, 0 errored. ------------------------------------------------------------------------------ |
The first line tells us which test case failed and why. The table from lines 7-13 provides a summary of all test cases which were executed and their results. Lines 11-12 are raised as an error so that other programs working with tSQLt can easily detect test case failure and quickly brings your attention to the fact that a failure happened when running in SQL Server Management Studio.
We would create several more test cases including tests for negative and positive values, null, and decimal values. Each time we add a test or change the code, we can re-run all of the tests and make sure that everything is still working.
Independence from Constraints
Now, let’s try a more complicated test case. Before cleansing the data, the manager wants to know how many Fahrenheit values will be converted to Celsius. Hence, we will want to create a view that returns the count. For the view to work, we’ll have to put data into the DailyWeatherInfo table. However, the other columns such as id, recordingUserId and recordedDate are not relevant. Nor is it important to this test case for there to actually be data in the User table foreign keyed to with the recordingUserId column. Finally, the locationId column that someone is thinking about adding next week also should not break this test case. We want our test case to be independent of these unrelated concerns.
To achieve this independence, tSQLt provides the FakeTable procedure as seen in this test case:
|
1 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 CREATE PROCEDURE TemperatureCleansing.[test Fahrenheit temperature records are counted] AS BEGIN EXEC tSQLt.FakeTable 'dbo', 'DailyWeatherInfo'; INSERT INTO dbo.DailyWeatherInfo (temperature) VALUES ('100f'); INSERT INTO dbo.DailyWeatherInfo (temperature) VALUES ('12c'); INSERT INTO dbo.DailyWeatherInfo (temperature) VALUES ('32'); INSERT INTO dbo.DailyWeatherInfo (temperature) VALUES ('83 F'); INSERT INTO dbo.DailyWeatherInfo (temperature) VALUES ('24.2 C'); DECLARE @numFahrenheitRecords INT; SELECT @numFahrenheitRecords = numFahrenheitRecords FROM dbo.FahrenheitRecordsCount; EXEC tSQLt.AssertEquals 2, @numFahrenheitRecords; END; GO |
Notice how the test case only deals with the specific table and the columns that it needs. It is not complicated by the other details about the database. This keeps test cases easy to maintain, easy to read, faster to write and faster to execute.
FakeTable works by creating an empty copy of the original table without the constraints or relationships. Only the column names and data types are preserved. Each tSQLt test cases is executed within a transaction which is rolled back when the case completes. Therefore, the original table is put back in place when the test case finishes.
Operating inside of a transaction also means that any work done by the code you are testing is undone. This is important, to keep all test cases independent of one another. In SQL test frameworks without transactions, one test case can unwittingly modify data needed by another test case. If the test cases are executed in random order, some test cases will appear to fail randomly. Nobody wants to debug those situations, so tSQLt was written to automatically place each test case in a transaction to avoid those problems.
Comparing Sets
So far, we’ve only been looking at single valued results. Much of the time we really work with sets of data and want to validate the results of a query or a data modification statement. Just checking the number of rows returned or updated is not sufficient! Many defects are missed when test cases only check the amount of data returned but not the contents. However, writing code to loop through and check each result of a query or data modification is tedious.
The AssertEqualsTable procedure compares the data in two tables. Let’s take a look at a test case that uses AssertEqualsTable to check the result of a data modification.
|
1 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 CREATE PROCEDURE TemperatureCleansing.[test multiple Fahrenheit records converted to Celsius] AS BEGIN EXEC tSQLt.FakeTable 'dbo', 'DailyWeatherInfo'; INSERT INTO dbo.DailyWeatherInfo (temperature) VALUES ('91f'); INSERT INTO dbo.DailyWeatherInfo (temperature) VALUES ('57 F'); INSERT INTO dbo.DailyWeatherInfo (temperature) VALUES ('78 F'); EXEC dbo.CleanseTemperatureData; SELECT temperature INTO #Actual FROM dbo.DailyWeatherInfo; CREATE TABLE #Expected ( temperature INT ); INSERT INTO #Expected (temperature) VALUES (33); INSERT INTO #Expected (temperature) VALUES (14); INSERT INTO #Expected (temperature) VALUES (26); EXEC tSQLt.AssertEqualsTable '#Expected', '#Actual'; END; GO |
As in the previous example we’re using FakeTable and INSERT statements to create the test data (lines 4-8). Next we execute the procedure we are testing, CleanseTemperatureData (line 10). After the procedure executes, we want to capture the changes it made to the DailyWeatherInfo into a working table which we’ll call “#Actual” (lines 12-14). Then we want to setup the expected results in a table of their own (lines 16-22). Finally we compare the results in the “#Expected” and “#Actual” tables (line 24).
This establishes a common pattern of writing unit tests which need to compare set based results: we perform the action, store the results in an “#Actual” table, create the expected results in an “#Expected” table and then compare the two.
Let’s take a look at the result of this test case if the CleanseTemperatureData procedure had a defect where it did not actually perform the calculation of Fahrenheit to Celsius, but only chopped off the “F”:
|
1 |
1 2 3 4 5 6 7 8 9 10 [TemperatureCleansing].[test multiple Fahrenheit records converted to Celsius] failed: unexpected/missing resultset rows! |_m_|temperature| +---+-----------+ |< |33 | |< |14 | |< |26 | |> |57 | |> |78 | |> |91 | |
The column, _m_ indicates the result of the comparison for each row. The less than sign (<), indicates that a result was found in the Expected table but was not found Actual table (lines 5-7). Similarly a greater than sign (>) indicates that a result was found in the Actual table but was not found in the Expected table (lines 8-10). If a row was exactly matched, an equals sign (=) would be present in the _m_ column. For two rows to match, all values in every column must be equal. For a more in-depth look at the reasoning behind tSQLt’s table comparison algorithm, please click here.
Your Next Steps
You’ve now seen an approach to overcoming the greatest technical obstacles to database unit testing. The tSQLt framework supports your unit testing efforts by isolating your test cases from constraints and schema changes, handling the transaction management required to execute independent test cases and providing the framework basics such as assertions, grouping test cases into test classes and executing test cases. tSQLt can also produce output conforming to the JUnit XML output format so that it can be integrated with popular continuous integration servers. We encourage you to try it for yourself and write your own robust unit test cases.

Load comments