
History
Tables, in a properly designed schema, model either an entity or a relationship, but not both. Slightly outside of the tables in the data model, we have other kinds of tables. Staging tables bring in “dirty data” so we can scrub it and then insert it into base tables. Auxiliary tables hold static data for use in the system, acting as the relational replacement for computations.
This is not a new idea. If you can find an old text book (1960’s or earlier), there is a good chance you will find look-up tables in the back. Finance books had compound interest, net present value (NPV) and internal rate of return (IIR). Trigonometry books had sines, cosines, tangents and maybe haversines and spherical trig functions.
There were no cheap calculators; and slide rulers were good to only three decimal places and required some skill to use. Look up tables were easy for anyone to use and usually went to five decimal places.
I still remember my first Casio scientific calculator that I bought with my Playboy Club Key account in 12 monthly installments. The price of that model dropped to less than one payment before I paid it off. These machines marked the end of look-up tables in textbooks. Today, you can get a more powerful calculator on a spike card in the check-out line of a school bookstore.
Basic Look-up Table Design
The concept of pre-calculating a function and storing the outputs can be carried over to databases. Programmers do it all the time. Most of the time, they are used for display purposes rather than computations. That is, you are likely to see a table which translates an encoding into a description that a human being can understand.
The ISO-11179 data element-naming conventions have the format [<role>_]<attribute>_<property>. The example used in the base document was an attribute of “tree” with properties like “tree_diameter“, “tree_species” and so forth. Some properties do not apply to some attributes — “employee_diameter” is not something we need to model just yet and “employee_species” is a bit insulting.
The attribute properties that deal with encodings for scales are the candidates for look-up tables. Here is a list and definitions for some of the basic ones I introduced my my book SQL PROGRAMMING STYLE.
- “
_id” = Identifier, it is unique in the schema and refer to one entity anywhere it appears in the schema. A look-up table deals with attributes and their values, not entities, so by definition, this is not used in such tables. That is why things like “_category_id” or “_type_id” are garbage names.
Never use “<table name>_id“; that is a name based on location and tell you this is probably not a real key at all. Just plain “id” is too vague to be useful to anyone and will screw up your data dictionary when you have to find a zillion of them, all different, but with the same data element name and perhaps the same oversized data type. - “
_date” or “dt” = date, temporal dimension. It is the date of something — employment, birth, termination, and so forth; there is no such column name as just a date by itself. - “
_nbr” or “num” = tag number; this is a string of digits or even alphanumrics that names something. Do not use “_no” since it looks like the Boolean yes/no value. I prefer “nbr” to “num” since it is used as a common abbreviation in several European languages. - “
_name” or “nm” = this is an alphabetic name and it explains itself. It is also called a nominal scale. - “
_code” or “_cd“= A code is a standard maintained by a trusted source outside of the enterprise. For example the ZIP code is maintained by the United States Postal Service. It has some legal authority to it. - “
_size” = an industry standard or company scale for a commodity, such as clothing, shoes, envelopes or machine screws. There is usually a prototype that defines the sizes kept with a trusted source. - “
_seq” = sequence, ordinal numbering. This is not the same thing as a tag number, since it cannot have gaps. It also has a rule for successors in the sequence. - “
_cat” = Category, an encoding that has an external source that has very distinct groups of entities. There should be strong formal criteria for establishing the category. The classification of Kingdom is in biology is an example. - “
_class” = an internal encoding that does not have an external source that reflects a sub-classification of the entity. There should be strong formal criteria for the classification. The classification of plants in biology is an example. - “
_type” = an encoding that has a common meaning both internally and externally. Types are usually less formal than a class and might overlap. For example a driver’s license might be for multiple kinds of vehicles; motorcycle, automobile, taxi, truck and so forth.
The differences among type, class, and category are an increasing strength of the algorithm for assigning the type, class, or category. A category is very distinct; you will not often have to guess if something “animal, vegetable or mineral” to put it in one of those categories.
A class is a set of things that have some commonality; you have rules for classifying an animal as a mammal or a reptile. You may have some cases where it is harder to apply the rules, such as the egg laying mammal in Australia, but the exceptions tend to become their own classification — monotremes in this example.
A type is the weakest of the three, and it might call for a judgment. For example, in some states a three-wheeled motorcycle is licensed as a motorcycle. In other states, it is licensed as an automobile. And in some states, it is licensed as an automobile only if it has a reverse gear.
The three terms are often mixed in actual usage. For example, ablood_typehas a laboratory procedure to obtain a value of {A, B, AB, O}. of you want to know for sure. Stick with the industry standard, even if violates the definitions given above. - “
_status” = an internal encoding that reflects a state of being which can be the result of many factors. For example, “credit_status” might be computed from several sources. The words “status” comes from “state” and we expect that there are certain allowed state changes. For example, your marital status can change to “Divorced” only if it is “Married” currently.
Here is where programmers start to mess up. Consider this table, taken from an actual posting:
|
1 2 3 |
CREATE TABLE Types (type_id INTEGER, type_name VARCHAR(30)); |
Is this for blood, work visas or what? The table name cannot be more vague. There is no key. The first column is absurd as well as vague. An attribute can be “<something>_type” or “<something>_id” but never both. Entities have identifiers; scalar values do not. Think about a table of mathematical constants and tell me the identifier of pi, e or phi. Type_id is stupid for the same reason. Hey, why not carry this silliness from “type_id” to “type_id_value” and beyond.
Another version of the same disaster, taken from actual postings, is to add a redundant, non-relational IDENTITY table property.
|
1 2 3 4 |
CREATE TABLE Product_Types (product_type_id INTEGER IDENTITY NOT NULL, -- is this the key? product_type_code CHAR(5) NOT NULL -- is this the key? type_generic_description VARCHAR(30) NOT NULL); |
All these simple look-up tables need is a column for the <attribute>_<property> as the key and the description or name or both. If you don’t get the difference between a name and a description, consider the name “Joe Celko” and “Creepy looking white guy” which is a description. A look-up table of three-letter airport codes will probably return a name. For example, the abbreviation code “MAD” stands for “Barajas International Airport” in Madrid.
An encoding for, say, types of hotels might return a description, like types
|
hotel type |
description |
|
R0 |
Basic Japanese Ryokan, no plumbing, no electricity, no food |
|
R1 |
Japanese Ryokan, plumbing, electricity, Japanese food |
|
R2 |
Japanese Ryokan, like R1 with internet and television |
|
R3 |
Japanese Ryokan, like R2 with Western meal options |
A product code will probably return both as name and a description. For example, the name might be “The Screaming Ear Smasher” and the description be “50000 Watt electric guitar and amplifier” in the catalog.
If you build an index on <attribute>_<property> key, you can use the INCLUDE feature to carry the name and/or description into the index and the table itself is now redundant.
One True look-up Table
The One True look-up Table (OTLT) is a nightmare that keeps showing up. The idea is that you put ALL the encodings into one huge table rather than have one table for each one. I think that Paul Keister was the first person to coin the phrase “OTLT” (One True Look-up Table) and Don Peterson (www.SQLServerCentral.com) gave the same technique the name “Massively Unified Code-Key” or MUCK tables in one of his articles.
The rationale is that you will only need one procedure to maintain all of the encodings, and one generic function to invoke them. The “Automobiles, Squids and Lady GaGa” function! The technique crops up time and time again, but I’ll give him credit as the first writer to give it a name. Simply put, the idea is to have one table to do all of the code look-ups in the schema. It usually looks like this:
|
1 2 3 4 5 |
CREATE TABLE OTLT -- Generic_Look_Ups? (generic_code_type CHAR(10) NOT NULL, -- horrible names! generic_code_value VARCHAR(255) NOT NULL, -- notice size! generic_description VARCHAR(255) NOT NULL, -- notice size! PRIMARY KEY (generic_code_value, generic_code_type)); |
The data elements are meta-data now, so we wind up with horrible names for them. They are nothing in particular, but magical generics for anything in the universe of discourse.
So if we have Dewey Decimal Classification (library codes), ICD (International Classification of Diseases), and two-letter ISO-3166 country codes in the schema, we have them all in one, honking big table.
Let’s start with the problems in the DDL and then look at the awful queries you have to write (or hide in VIEWs). So we need to go back to the original DDL and add a CHECK() constraint on the eneric_code_type column. Otherwise, we might “invent” a new encoding system by typographical error.
The Dewey Decimal and ICD codes are digits and have the same format — three digits, a decimal point and more digits (usually three); the ISO-3166 is alphabetic. Oops, need another CHECK constraint that will look at the generic_code_type and make sure that the string is in the right format. Now the table looks something like this, if anyone attempted to do it right, which is not usually the case:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
CREATE TABLE OTLT (generic_code_type CHAR(10) NOT NULL CHECK(generic_code_type IN ('DDC', 'ICD', 'ISO3166', ..), generic_code_value VARCHAR(255) NOT NULL, CONSTRAINT Valid_Generic_Code_Type CHECK (CASE WHEN generic_code_type = 'DDC' AND generic_code_value LIKE '[0-9][0-9][0-9].[0-9][ 0-9][ 0-9]' THEN 'T' WHEN generic_code_type = 'ICD' AND generic_code_value LIKE '[0-9][0-9][0-9].[0-9][ 0-9][ 0-9]' THEN 'T' WHEN generic_code_type = 'ISO3166' AND generic_code_value LIKE '[A-Z][A-Z]' THEN 'T' ELSE 'F' END = 'T'), generic_description VARCHAR(255) NOT NULL, PRIMARY KEY (generic_code_value, generic_code_type)); |
Since the typical application database can have dozens and dozens of codes in it, just keep extending this pattern for as long as required. Not very pretty is it? Before you think about some fancy re-write of the CASE expression, SQL Server allows only ten levels of nesting.
Now let us consider adding new rows to the OTLT.
|
1 2 3 |
INSERT INTO OTLT (generic_code_type, generic_code_value, generic_description) VALUES ('ICD', 259.0, 'Inadequate Genitalia after Puberty'), ('DDC', 259.0, 'Christian Pastoral Practices & Religious Orders'); |
If you make an error in the generic_code_type during insert, update or delete, you have screwed up a totally unrelated value. If you make an error in the generic_code_type during a query, the results could be interesting. This can really hard to find when one of the similarly structured schemes had unused codes in it.
When I update the OTLT table, I have to lock out everyone until I am finished. It is like having to carry an encyclopedia set with you when all you needed was a magazine article
The next thing you notice about this table is that the columns are pretty wide VARCHAR(n), or even worse, that they are NVARCHAR(n) which can store characters from a strange language. The value of (n) is most often the largest one allowed.
Since you have no idea what is going to be shoved into the table, there is no way to predict and design with a safe, reasonable maximum size. The size constraint has to be put into the WHEN clause of that second CHECK() constraint between generic_code_type and generic_code_value. Or you can live with fixed length codes that are longer than what they should be.
These large sizes tend to invite bad data. You give someone a VARCHAR(n) column, and you eventually get a string with a lot of white space and a small odd character sitting at the end of it. You give someone an NVARCHAR(255) column and eventually it will get a Buddhist sutra in Chinese Unicode.
Now let’s consider the problems with actually using the OTLT in a query. It is always necessary to add the generic_code_type as well as the value which you are trying to look-up.
|
1 2 3 4 5 |
SELECT P1.ssn, P1.lastname, .., L1.generic_description FROM OTLT AS L1, Personnel AS P1 WHERE L1.generic_code_type = 'ICD' AND L1.generic_code_value = P1.disease_code AND ..; |
In this sample query, you need to know the generic_code_type of the Personnel table disease_code column and of every other encoded column in the table. If you got a generic_code_type wrong, you can still get a result.
You also need to allow for some overhead for data type conversions. It might be more natural to use numeric values instead of VARCHAR(n) for some encodings to ensure a proper sorting order. Padding a string of digits with leading zeros adds overhead and can be risky if programmers do not agree on how many zeros to use.
When you execute a query, the SQL engine has to pull in the entire look-up table, even if it only uses a few codes. If one code is at the start of the physical storage, and another is at the end of physical storage, I can do a lot of caching and paging. When I update the OTLT table, I have to lock out everyone until I am finished. It is like having to carry an encyclopedia set with you when all you needed was a magazine article.
Now consider the overhead with a two-part FOREIGN KEY in a table:
|
1 2 3 4 5 6 7 8 9 |
CREATE TABLE EmployeeAbsences (.. generic_code_type CHAR(3) -- min length needed DEFAULT 'ICD' NOT NULL CHECK (generic_code_type = 'ICD'), generic_code_value CHAR(7) NOT NULL, -- min length needed FOREIGN KEY (generic_code_type, generic_code_value) REFERENCES OTLT (generic_code_type, generic_code_value), ..); |
Now I have to convert the character types for more overhead. Even worse, ICD has a natural DEFAULT value (000.000 means “undiagnosed”), while Dewey Decimal does not. Older encoding schemes often used all 9’s for “miscellaneous” so they would sort to the end of the reports in COBOL programs. Just as there is no Magical Universal “id”, there is no Magical Universal DEFAULT value. I just lost one of the most important features of SQL!
I am going to venture a guess that this idea came from OO programmers who think of it as some kind of polymorphism done in SQL. They say to themselves that a table is a class, which it isn’t, and therefore it ought to have polymorphic behaviors, which it doesn’t.
Look-Up Tables with Multiple Parameters
A function can have more than one parameter and often do in commercial situations. They can be ideal candidates for a look-up when the computation is complex . My usual example is the Student’s T-distribution, since I used to be a statistician. It is used for small sample sizes that the normal distribution cannot handle. It takes two parameters, the sample size and confidence interval (how sure do you want to be about your prediction).
The probability density function is:
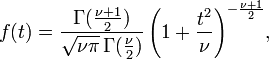
Got any idea just off the top of your head how to write this in T-SQL? How many of you can identify the Greek letters in this thing? Me neither. the nice part about using this in the real world is that you don’t need all the possible values. You work with a set of three to ten confidence intervals and since it is meant for small samples, you don’t need a lot of population values. Here is a table cut and pasted from Wikipedia.com.
|
One Sided |
75% |
80% |
85% |
90% |
95% |
97.5% |
99% |
99.5% |
99.75% |
99.9% |
99.95% |
|---|---|---|---|---|---|---|---|---|---|---|---|
|
Two Sided |
50% |
60% |
70% |
80% |
90% |
95% |
98% |
99% |
99.5% |
99.8% |
99.9% |
|
1 |
1.000 |
1.376 |
1.963 |
3.078 |
6.314 |
12.71 |
31.82 |
63.66 |
127.3 |
318.3 |
636.6 |
|
2 |
0.816 |
1.061 |
1.386 |
1.886 |
2.920 |
4.303 |
6.965 |
9.925 |
14.09 |
22.33 |
31.60 |
|
3 |
0.765 |
0.978 |
1.250 |
1.638 |
2.353 |
3.182 |
4.541 |
5.841 |
7.453 |
10.21 |
12.92 |
|
4 |
0.741 |
0.941 |
1.190 |
1.533 |
2.132 |
2.776 |
3.747 |
4.604 |
5.598 |
7.173 |
8.610 |
|
5 |
0.727 |
0.920 |
1.156 |
1.476 |
2.015 |
2.571 |
3.365 |
4.032 |
4.773 |
5.893 |
6.869 |
|
6 |
0.718 |
0.906 |
1.134 |
1.440 |
1.943 |
2.447 |
3.143 |
3.707 |
4.317 |
5.208 |
5.959 |
|
7 |
0.711 |
0.896 |
1.119 |
1.415 |
1.895 |
2.365 |
2.998 |
3.499 |
4.029 |
4.785 |
5.408 |
|
8 |
0.706 |
0.889 |
1.108 |
1.397 |
1.860 |
2.306 |
2.896 |
3.355 |
3.833 |
4.501 |
5.041 |
|
9 |
0.703 |
0.883 |
1.100 |
1.383 |
1.833 |
2.262 |
2.821 |
3.250 |
3.690 |
4.297 |
4.781 |
|
10 |
0.700 |
0.879 |
1.093 |
1.372 |
1.812 |
2.228 |
2.764 |
3.169 |
3.581 |
4.144 |
4.587 |
|
11 |
0.697 |
0.876 |
1.088 |
1.363 |
1.796 |
2.201 |
2.718 |
3.106 |
3.497 |
4.025 |
4.437 |
|
12 |
0.695 |
0.873 |
1.083 |
1.356 |
1.782 |
2.179 |
2.681 |
3.055 |
3.428 |
3.930 |
4.318 |
|
13 |
0.694 |
0.870 |
1.079 |
1.350 |
1.771 |
2.160 |
2.650 |
3.012 |
3.372 |
3.852 |
4.221 |
|
14 |
0.692 |
0.868 |
1.076 |
1.345 |
1.761 |
2.145 |
2.624 |
2.977 |
3.326 |
3.787 |
4.140 |
|
15 |
0.691 |
0.866 |
1.074 |
1.341 |
1.753 |
2.131 |
2.602 |
2.947 |
3.286 |
3.733 |
4.073 |
|
16 |
0.690 |
0.865 |
1.071 |
1.337 |
1.746 |
2.120 |
2.583 |
2.921 |
3.252 |
3.686 |
4.015 |
|
17 |
0.689 |
0.863 |
1.069 |
1.333 |
1.740 |
2.110 |
2.567 |
2.898 |
3.222 |
3.646 |
3.965 |
|
18 |
0.688 |
0.862 |
1.067 |
1.330 |
1.734 |
2.101 |
2.552 |
2.878 |
3.197 |
3.610 |
3.922 |
|
19 |
0.688 |
0.861 |
1.066 |
1.328 |
1.729 |
2.093 |
2.539 |
2.861 |
3.174 |
3.579 |
3.883 |
|
20 |
0.687 |
0.860 |
1.064 |
1.325 |
1.725 |
2.086 |
2.528 |
2.845 |
3.153 |
3.552 |
3.850 |
|
21 |
0.686 |
0.859 |
1.063 |
1.323 |
1.721 |
2.080 |
2.518 |
2.831 |
3.135 |
3.527 |
3.819 |
|
22 |
0.686 |
0.858 |
1.061 |
1.321 |
1.717 |
2.074 |
2.508 |
2.819 |
3.119 |
3.505 |
3.792 |
|
23 |
0.685 |
0.858 |
1.060 |
1.319 |
1.714 |
2.069 |
2.500 |
2.807 |
3.104 |
3.485 |
3.767 |
|
24 |
0.685 |
0.857 |
1.059 |
1.318 |
1.711 |
2.064 |
2.492 |
2.797 |
3.091 |
3.467 |
3.745 |
|
25 |
0.684 |
0.856 |
1.058 |
1.316 |
1.708 |
2.060 |
2.485 |
2.787 |
3.078 |
3.450 |
3.725 |
|
26 |
0.684 |
0.856 |
1.058 |
1.315 |
1.706 |
2.056 |
2.479 |
2.779 |
3.067 |
3.435 |
3.707 |
|
27 |
0.684 |
0.855 |
1.057 |
1.314 |
1.703 |
2.052 |
2.473 |
2.771 |
3.057 |
3.421 |
3.690 |
|
28 |
0.683 |
0.855 |
1.056 |
1.313 |
1.701 |
2.048 |
2.467 |
2.763 |
3.047 |
3.408 |
3.674 |
|
29 |
0.683 |
0.854 |
1.055 |
1.311 |
1.699 |
2.045 |
2.462 |
2.756 |
3.038 |
3.396 |
3.659 |
|
30 |
0.683 |
0.854 |
1.055 |
1.310 |
1.697 |
2.042 |
2.457 |
2.750 |
3.030 |
3.385 |
3.646 |
|
40 |
0.681 |
0.851 |
1.050 |
1.303 |
1.684 |
2.021 |
2.423 |
2.704 |
2.971 |
3.307 |
3.551 |
|
50 |
0.679 |
0.849 |
1.047 |
1.299 |
1.676 |
2.009 |
2.403 |
2.678 |
2.937 |
3.261 |
3.496 |
|
60 |
0.679 |
0.848 |
1.045 |
1.296 |
1.671 |
2.000 |
2.390 |
2.660 |
2.915 |
3.232 |
3.460 |
|
80 |
0.678 |
0.846 |
1.043 |
1.292 |
1.664 |
1.990 |
2.374 |
2.639 |
2.887 |
3.195 |
3.416 |
|
100 |
0.677 |
0.845 |
1.042 |
1.290 |
1.660 |
1.984 |
2.364 |
2.626 |
2.871 |
3.174 |
3.390 |
|
120 |
0.677 |
0.845 |
1.041 |
1.289 |
1.658 |
1.980 |
2.358 |
2.617 |
2.860 |
3.160 |
3.373 |
|
â |
0.674 |
0.842 |
1.036 |
1.282 |
1.645 |
1.960 |
2.326 |
2.576 |
2.807 |
3.090 |
3.291 |
Unlike the calculus, nobody should have any trouble loading it into a look-up table.
In the January 2005 issue of The Data Administration Newsletter (www.TDAN.com) I published an article on a look-up table solution to a more difficult problem. If you watch the Food channel on cable or if you just like Memphis-style BBQ, you know the name “Corky’s”. The chain started in 1984 in Memphis by Don Pelts and has grown by franchise at a steady rate ever since. They will never be a McDonald’s because all the meats are slow cooked for up to 22 hours over hickory wood and charcoal, and then every pork shoulder is hand-pulled. No automation, no mass production.
They sell a small menu of items by mail order via a toll-free number or from their website (www.corkysbbq.com) and ship the merchandise in special boxes sometimes using dry ice. Most of the year, their staff can handle the orders. But at Christmas time, they have the problem of success.
Their packing operation consists of two lines. At the start of the line, someone pulls a box of the right size, and puts the pick list in it. As it goes down the line, packers put in the items, and when it gets to the end of the line, it is ready for shipment. This is a standard business operation in lots of industries. Their people know what boxes to use for the standard gift packs and can pretty accurately judge any odd sized orders.
At Christmas time, however, mail-order business is so good that they have to get outside temp help. The temporary help does not have the experience to judge the box sizes by looking at a pick list. If a box that is too small starts down the line, it will jam up things at some point. The supervisor has to get it off the line, and re-pack the order by hand. If a box that is too large goes down the line, it is a waste of money and creates extra shipping costs.
Mark Tutt (On The Mark Solutions, LLC) has been consulting with Corky’s for years and set up a new order system for them on Sybase. One of the goals of the new system is print the pick list and shipping labels with all of the calculations done, including what box size the order requires.
Following the rule that you do not re-invent the wheel, Mr. Tutt went to the newsgroups to find out if anyone had a solution already. The suggestions tended to be along the lines of getting the weights and shapes of the items and using a Tetris program to figure out the packing.
Programmers seem to love to face every new problem as if nobody has ever done it before and nobody will ever do it again. The “Code first, research later!” mentality is hard to overcome.
The answer was not in complicated 3-D math, but in the past 4 or 5 years of orders in the database. Human beings with years of experience had been packing orders and leaving a record of their work to be mined. Obviously the standard gift packs are easy to spot. But most of the orders tend to be something that had occurred before, too. Here are the answers, if you will bother to dig them out.
First, Mr. Tutt found all of the unique configurations in the orders, how often they occurred and the boxes used to pack them. If the same configuration had two or more boxes, then you should go with the smaller size. As it turned out, there were about 4995 unique configurations in the custom orders which covered about 99.5% of the cases.
Next, this table of configurations was put into a stored procedure that did a slightly modified exact relational division to obtain the box size required. A fancy look-up table with a variable parameter list!



Load comments