
Spool Operators

Eager Spool

Lazy Spool

Row Count Spool

Table Spool

Non-Clustered Index Spool
This week we’ll be featuring the Spool showplan operator. There are five types of Spool operations, each with its own behavior, and idiosyncrasies, but they all share in common the way that they save their intermediate query results on the TempDB database, and use this temporary area to search a value.
There are many tricks that Query Optimizer uses to avoid any logical problems and to perform queries better: The spool operators are a good example of this. This month, we’ll see all these types of Spool operations, one by each week.
A spool reads the data and saves it on TempDB. This process is used whenever the Optimiser knows that the density of the column is high and the intermediate result is very complex to calculate. If this is the case, SQL makes the computation once, and stores the result in the temporary space so it can search it later.
The spool operators are always used together with another operator. As it stores values, it needs to know what these values are, and so it must receive them from another operator. For instance, one spool can be used together with a clustered index scan in order to save the rows read by the scan. These rows can then be read back to an update, or a select operator.
A quite simple graphic representation about what I said above could be the following picture:

In the example represented by these icons above, the order of execution is: Clustered Index Scan sends rows to Spool and the Select reads all of these rows directly from the Spool.
Eager Spool
We’ll start with the Eager Spool Operator. The role of the Eager Spool is to catch all the rows received from another operator and store these rows in TempDB. The word “eager” means that the operator will read ALL rows from the previously operator at one time. In other words, it will take the entire input, storing each row received.
In our simple sample (SCAN -> EAGER SPOOL -> SELECT) the eager will works like this: When the scanned rows are passed to Spool then it gets all the rows, not one row at the time you’ll notice but the entire scan, and keeps them in a hidden temporary table.
Knowing that, we could say that The Eager Spool is a blocking operator. I believe that I haven’t yet written about the difference between blocking operators and non-blocking operators. Let’s open a big parenthesis here.
There are two categories of showplan operators: The “non-blocking” operators and the “blocking” operators or “stop-and-go”:
- Non-blocking operators are those that read one row from their input and return the output for each read row. In the method known as GetRow(), the operator executes its function and returns the row to the next operator as soon as the first row has been read.
The “nested loop” operator is a good example of this ‘non-blocking’ behavior: When the first row is read; SQL needs to perform a Join with the outer table, if the outer table joins with the inner table than a row is returned. This process repeats until the end of the table. To each received row, SQL tries to join the rows and return the required values.
- A blocking operator needs to read all the rows from its input to perform some action and then return the data. A classic sample of a blocking operator is the Sort operator, it needs to read all rows, sort the data and then return the ordered rows. The execution of the query will wait until all rows to be read and ordered, before continuing with the command.
The Halloween Problem
There is a very interesting classic computing problem, called “The Halloween Problem”. Microsoft Engineers take advantage of the blocking eager spool operator to avoid this problem.
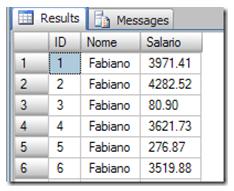
In order to illustrate this, I will start with the following code to create a table called “Funcionarios” which means Employees in Portuguese.
This script will create the table with three columns, ID, Nome (Name) and Salario (Salary), and populate them with some garbage data.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
USE TempDB GO SET NOCOUNT ON IF OBJECT_ID('Funcionarios') IS NOT NULL DROP TABLE Funcionarios GO CREATE TABLE Funcionarios(ID Int IDENTITY(1,1) PRIMARY KEY, Nome VarChar(30), Salario Numeric(18,2)); GO DECLARE @I SmallInt SET @I = 0 WHILE @I < 1000 BEGIN INSERT INTO Funcionarios(Nome, Salario) SELECT 'Fabiano', ABS(CONVERT(Numeric(18,2), (CheckSUM(NEWID()) / 500000.0))) SET @I = @I + 1 END CREATE NONCLUSTERED INDEX ix_Salario ON Funcionarios(Salario) GO |
This is what the data looks like.
Ok: Now that we have run the script, we can return to where we left off when describing the operator Eager Spool.
To show the functionality of the Eager Spool we’ll go back in time a bit, to the time when I was just a project being planned, but some other geeks working intensively with databases.
It was Halloween; the cold winter’s night was black as pitch, (I really don’t know if was winter, but I thought it would sound more thrilling) and the wind howled in the trees. It was 1976 and the children was demanding “tricks or treat” in the houses. The full moon shone and illuminated the whole city when suddenly, some clouds crossed the moon making the night even more dark and gloomy. It was possible to smell and taste the tension in the air like a stretched rubber band so close to burst. People walking in the street felt that someone was observing them, and when they looked closely in their back, they see two red eyes waiting and looking out for a prey unprotected.
Was that their imagination? Or just the wrong night to work with databases?
Meanwhile in a place not far away, an update was started on a database by a skeleton staff, to update the salary by 10% of all employees who earned less than $ 25.000,00 dollars. Their feelings of impending doom increased as the query failed to complete in the expected time. When, at length, it did, they found to their horror that every employee had their pay increased to $ 25.000,00. It was the stuff of DBA nightmares.
So begins the story of a problem known as “Halloween Problem”, IBM engineers were the first to find the problem, but several databases have suffered similar problems over the years, including our lovely SQL Server as we can see here. The Halloween problem happens when the write cursor interferes with the read cursor. The selection of the rows to update is affected by the actual update process. This can happen when there is a index on the particular column being updated. When the update is made, the same row can be updated several times.
All updates are executed in two steps, the first is the read step, and the second is the update. A read cursor identifies the rows to be updated and a write cursor performs the actual updates.
|
1 2 |
UPDATE Funcionarios SET Salario = 0 WHERE ID = 10 |
For the execution of this query, the first step is to locate the records that need updating, and then the second step needs to update these records. If there is an index on the column being modified (Salario) then this index also needs to be updated.
As we know, all non-clustered indexes need to be updated when a value changes that is used in the index.
The problem can happen if SQL Server chooses to read the data using this index during the read step. This value can then change when the second step is being performed.
Let’s see some examples using the same type of query that was being used when the problem was first found by the IBM engineers.
Suppose that I want to give 10% of increase salary to all employees that earn less than R$ 2000,00 reais (the Brazilian currency). I could run the following query:
|
1 2 3 |
UPDATE Funcionarios SET Salario = Salario * 1.1 FROM Funcionarios WHERE Salario < 2000 |
We have the following graphical execution plan:

Text execution plan:
|
1 2 3 4 5 6 |
|--Clustered Index Update(OBJECT:([Funcionarios].[PK]), OBJECT:([Funcionarios].[ix_Salario]), SET:([Funcionarios].[Salario] = [Expr1003])) |--Compute Scalar(DEFINE:([Expr1016]=[Expr1016])) |--Compute Scalar(DEFINE:([Expr1016]=CASE WHEN [Expr1007] THEN (0) ELSE (1) END)) |--Top(ROWCOUNT est 0) |--Compute Scalar(DEFINE:([Expr1003]=CONVERT_IMPLICIT(numeric(18,2),[Funcionarios].[Salario]*(1.1),0), [Expr1007]=CASE WHEN [Funcionarios].[Salario] = CONVERT_IMPLICIT(numeric(18,2),[Funcionarios].[Salario]*(1.1),0) THEN (1) ELSE (0) END)) |--Clustered Index Scan(OBJECT:([Funcionarios].[PK]), WHERE:([Funcionarios].[Salario]<(2000.00)) ORDERED) |
For now, let us just to look at the steps that I mentioned. In the Clustered Index Scan, we see that SQL selects all the rows that will be updated, and the Clustered Index Update then updates these rows in the cluster index (PK) and the non-clustered index ix_salario.
Well, if we follow this logic, what do we predict will happen? Let’s take this a step at a time to see how this will work.
We know that the clustered index is ordered by ID column: SQL Server is using this index to look at what rows needs to be updated, so we have the following:
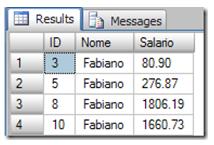
The first selected row is the ID = 3
After we select the row, we need to update the “salario” column.
So, we could perform the update of the salary with the actual value * 1.1.
After the update we have the following:
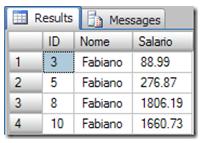
Note that the salary earned a 10% increase, from 80.90 to 88.99. We then continue by selecting the next row, ID = 5, and this process will then continue until the end of the selected rows.
So far, we can see that the use of this clustered index generates no error. If SQL Server continues with this logic until the end of the process, then all rows will be updated correctly. What if SQL chose, instead, to use the non-clustered index ix_salario to read the rows that will be updated (first step of the update), what will happen then?
Let’s use the same illustration that we used above. But this time we’ll force the use of the non-clustered index ix_salario.
|
1 2 3 |
UPDATE Funcionarios SET Salario = Salario * 1.1 FROM Funcionarios WITH(INDEX=ix_Salario) WHERE Salario < 2000 |
Graphical execution plan:

Text execution plan:
|
1 2 3 4 5 6 7 |
|--Clustered Index Update(OBJECT:([Funcionarios].[PK]), OBJECT:([Funcionarios].[ix_Salario]), SET:([Funcionarios].[Salario] = [Expr1003])) |--Compute Scalar(DEFINE:([Expr1016]=[Expr1016])) |--Compute Scalar(DEFINE:([Expr1016]=CASE WHEN [Expr1007] THEN (0) ELSE (1) END)) |--Top(ROWCOUNT est 0) |--Compute Scalar(DEFINE:([Expr1003]=CONVERT_IMPLICIT(numeric(18,2),[Funcionarios].[Salario]*(1.1),0), [Expr1007]=CASE WHEN [Funcionarios].[Salario] = CONVERT_IMPLICIT(numeric(18,2),[Funcionarios].[Salario]*(1.1),0) THEN (1) ELSE (0) END)) |--Table Spool |--Index Seek(OBJECT:([Funcionarios].[ix_Salario]), SEEK:([Funcionarios].[Salario] < (2000.00)) ORDERED FORWARD) |
You’ll see from the execution plan that, this time, after reading the data using the index ix_Salario, SQL Server uses a Blocking operator called Table Spool(Eager Spool). As I mentioned earlier in this article, when the Eager is called the first time, it will read all data and then move to the next operator. In our example, the Eager Spool writes the data returned from the index ix_Salario into a temporary table. Later, the updates do not read ix_salario any more; instead all reads are performed using the Eager Spool.
You may would be wondering, ‘Hey Fabiano where is the Halloween problem?‘ We will get there now.
Let’s suppose that SQL Server hadn’t used the Eager Spool operator. Let’s assume that we have the same execution plan above but without the Eager Spool operator.
If SQL Server hadn’t used the Eager Spool to read the data, it would have read rows directly from the index ix_Salario. It will read the first row, update the value with 10%, that get the next row and so on.
We know the index ix_Salario is ordered by column Salario, so let’s draw the things again to see what will happen.
The data returned to the Index would be:
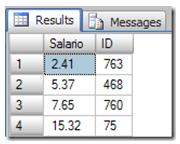
The first row is the ID 763, when the SQL Server updates the row the data in the index will be the following:
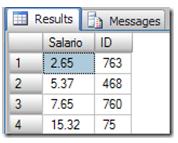
Now the next row is the ID 468.
Using this data we will not have a problem. But tell me one thing, if the data was distributed like that?
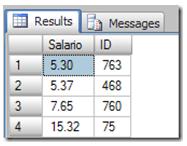
Well, that would be a very dangerous problem, Let’s go again, get the first row, ID = 763. Update this value with 10%, the data in the index will be the following:
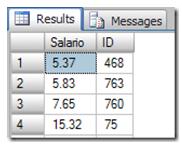
Now, get the next row, which was what? The ID 763 again? Yes, take it easy; let’s understand why the row 763 ended up in the second row. Wasn’t it in the first row?
Yes it was, but when SQL Server updated the Salario column value by 10% it updated the non-clustered index ix_Salario (see into the execution plan, the clustered index updates ix_Salario and the PK) too, which meant that data was repositioned in the non-clustered index. The index needs to keep the data physically sorted by salario. Once a value changes, it resets this value in the balanced tree.
The outcome would be that the employee with ID = 763 has the salary increased by 20% (well that could be good, since he calls Fabiano). The problem found at IBM, the engineers said the end of the query all employees were earning $ 25,000.00. And then they had to start to understand what had happened.
The team at Microsoft that develops the Query Processor uses blocking operators to ensure that the read data will be the same regardless whether there is a later update. In our query example, SQL uses the SQL Eager Spool: When it needs to read the rows for the second time, it will not use the index ix_Salario but will read from the Spool. The spool has a copy of rows of index ix_Salario in TempDB database.
Well, we saw that the Eager Spool can be used to avoid the problem known as “Halloween problem”, but it can also be used in your queries by the Query Optimizer whenever it reckons that it pays to create a copy of the data. Keep eye to see more about the Spool operators, Next week we will describe the Lazy Spool operator.
That’s all folks, I see you next week with more “Showplan Operators”.
If you missed last week’s thrilling Showplan Operator, BookMark/Key Lookup, you can see it here.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved




Load comments