
It often becomes necessary to create, shred, combine, or otherwise reconstitute XML data, in order to make it fit a specific purpose. Sometimes business requirements dictate that XML fragments should be merged, while other requests call for XML documents or fields to be shredded and their values imported into tables. Sometimes, XML Data must be created directly from existing tables. SQL Server provides plenty of XML-related tools, but how can we know which ones to use, and when?
Let’s examine some of these tasks that require XML manipulation, using the sample AdventureWorks2012 database (Other AdventureWorks versions should work OK, but there may be variations in the data and/or table schemas).
Creating XML
One common requirement is to create an XML structure that is based on the schema of an existing table. Let’s assume that we’ve received a request to create XML data from relevant fields in the Person.Person table, for the person having BusinessEntityID 10001. We need to gather the values from this row:
|
1 2 3 4 5 |
-- select Person record SELECT * FROM Person.Person WHERE BusinessEntityID = 10001 GO |

We need to include the BusinessEntityID field and some of the name-data columns in the new XML structure. Note that there happens to be an existing XML column in the table – the Demographics field.
SQL Server provides an XML option to use with the FOR clause, allowing for an easy method of converting table data into XML nodes. FOR XML can take different arguments – let’s find out which one works for us.
The AUTO argument is one of the simplest to use. It creates one node for each record returned by the SELECT clause:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
-- create XML structure using FOR XML AUTO SELECT BusinessEntityID, PersonType, Title, FirstName, MiddleName, LastName, Suffix FROM Person.Person WHERE BusinessEntityID = 10001 FOR XML AUTO GO |

By default, the AUTO argument organizes every non-XML field into a node attribute. To specify that the values be created as node elements, not attributes, we can additionally specify the ELEMENTS argument:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
-- create XML structure using FOR XML AUTO SELECT BusinessEntityID, PersonType, Title, FirstName, MiddleName, LastName, Suffix FROM Person.Person WHERE BusinessEntityID = 10001 FOR XML AUTO, ELEMENTS GO |
The resulting XML:
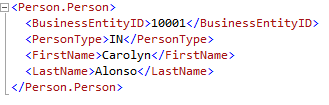
The ELEMENTS argument causes every value to be created as a node element. Now we have a separate node for every value, and a wrapper root node. In the first example the resulting XML had the same data, but the values were rendered as attributes.
We notice that the root node name is the schema and table name (Person.Person). We would like to change this to ‘Person‘. To designate a custom root element, we’ll use the PATH argument instead of AUTO:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
-- create XML using FOR XML PATH SELECT BusinessEntityID, PersonType, Title, FirstName, MiddleName, LastName, Suffix FROM Person.Person WHERE BusinessEntityID = 10001 FOR XML PATH('Person') GO |
The results:
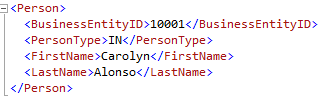
Using the PATH argument has enabled us to specify the name ‘Person’ in our root wrapper.
Combining Node Attributes and Elements
What if we want one or a few values to be created as node attributes, thereby resulting in a combination of node attributes and elements? We can create node attribute values by simply designating column aliases that use the ‘@’ symbol:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
-- designate node attribute SELECT BusinessEntityID AS '@ID', PersonType, Title, FirstName, MiddleName, LastName, Suffix FROM Person.Person WHERE BusinessEntityID = 10001 FOR XML PATH('Person') GO |
The resulting XML:
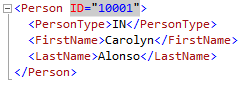
Including XML Columns
What happens if we add the XML field (Demographics) to our SELECT clause?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
-- include existing XML column SELECT BusinessEntityID AS '@ID', PersonType, Title, FirstName, MiddleName, LastName, Suffix, Demographics FROM Person.Person WHERE BusinessEntityID = 10001 FOR XML PATH('Person') GO |
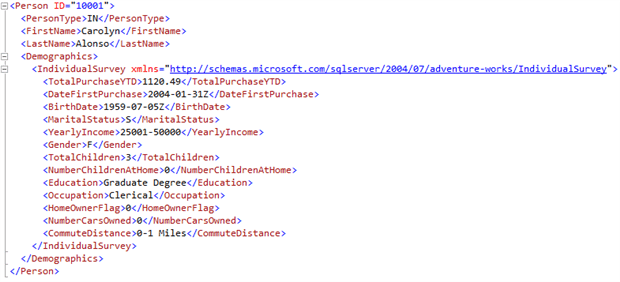
We see that an existing XML field is created as a nested node element. Note that the XML namespace data is included in the nested node.
Shredding XML
‘Shredding’ XML data is another common request. To ‘shred’ means to strip the actual data away from the markup tags, and organize it into a relational format. For example, shredding is what happens when an XML document is imported into a table, when each node value is mapped to a specific field in the table. A popular method to use for this is to use the OPENXML() function, but XQuery methods can also be engaged to perform the same tasks. OPENXML() was available to use for shredding before the SQL Server XQuery methods were introduced, and is somewhat faster for larger data operations. However, it is decidedly more complex to use, and is more memory intensive. Also, OPENXML() cannot take advantage of XML indexes as XQuery methods can.
We’ve received another request: pull data from some of the nodes (Occupation, Education, HomeOwnerFlag, NumberCarsOwned) that are contained in the Person.Person table’s Demographics XML column for BusinessEntityID 15291, and display it along with other non-XML field values (FirstName, MiddleName, LastName) from the table.
The Person.Person record for BusinessEntityID 15291, and their expanded Demographics XML instance are shown below:
|
1 2 3 4 |
SELECT * FROM Person.Person WHERE BusinessEntityID = 15291 GO |

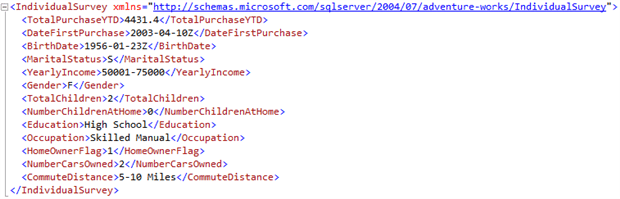
The XQuery value() method is an easy way to extract values from XML data while preserving the data types:
|
1 2 3 4 5 6 7 8 9 10 11 |
-- extract (shred) values from XML column nodes SELECT FirstName, MiddleName, LastName, Demographics.value('declare namespace ns="http://schemas.microsoft.com/sqlserver/2004/07/adventure-works/IndividualSurvey"; (/ns:IndividualSurvey/ns:Occupation)[1]','varchar(50)') AS Occupation, Demographics.value('declare namespace ns="http://schemas.microsoft.com/sqlserver/2004/07/adventure-works/IndividualSurvey"; (/ns:IndividualSurvey/ns:Education)[1]','varchar(50)') AS Education, Demographics.value('declare namespace ns="http://schemas.microsoft.com/sqlserver/2004/07/adventure-works/IndividualSurvey"; (/ns:IndividualSurvey/ns:HomeOwnerFlag)[1]','bit') AS HomeOwnerFlag, Demographics.value('declare namespace ns="http://schemas.microsoft.com/sqlserver/2004/07/adventure-works/IndividualSurvey"; (/ns:IndividualSurvey/ns:NumberCarsOwned)[1]','int') AS NumberCarsOwned FROM Person.Person WHERE BusinessEntityID = 15291 GO |

XML Namespaces
While this returns the shredded result that we want, the repetitive namespace declarations expand the size of our query – since we are returning four XML node values, we have to declare the namespace four times. Declaring the namespace is necessary because the Demographics XML structure uses typed XML – its XML data is associated with an XML schema. However, we can use a WITH XML NAMESPACES clause to declare the XML namespace instead – this lets us to declare the namespace only once for the entire code block:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
-- extract (shred) values from XML column nodes using WITH XMLNAMESPACES ;WITH XMLNAMESPACES ('http://schemas.microsoft.com/sqlserver/2004/07/adventure-works/IndividualSurvey' AS ns) SELECT FirstName, MiddleName, LastName, Demographics.value('(/ns:IndividualSurvey/ns:Occupation)[1]','varchar(50)') AS Occupation, Demographics.value('(/ns:IndividualSurvey/ns:Education)[1]','varchar(50)') AS Education, Demographics.value('(/ns:IndividualSurvey/ns:HomeOwnerFlag)[1]','bit') AS HomeOwnerFlag, Demographics.value('(/ns:IndividualSurvey/ns:NumberCarsOwned)[1]','int') AS NumberCarsOwned FROM Person.Person WHERE BusinessEntityID = 15291 GO |
XQuery nodes() Method
The XQuery nodes() method is another option that allows us to specify a particular node set in which to look for the desired child nodes:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
-- extract (shred) values from XML column nodes using XQuery nodes() method ;WITH XMLNAMESPACES ('http://schemas.microsoft.com/sqlserver/2004/07/adventure-works/IndividualSurvey' AS ns) SELECT FirstName, MiddleName, LastName, C.value('ns:Occupation[1]','varchar(50)') AS Occupation, C.value('ns:Education[1]','varchar(50)') AS Education, C.value('ns:HomeOwnerFlag[1]','bit') AS HomeOwnerFlag, C.value('ns:NumberCarsOwned[1]','int') AS NumberCarsOwned FROM Person.Person CROSS APPLY Demographics.nodes('/ns:IndividualSurvey') AS T(C) WHERE BusinessEntityID = 15291 GO |
We’ve used the nodes() method to drill down (one level) to the location of the ‘IndividualSurvey‘ node, and then returned the actual values via the XQuery value() method. We used CROSS APPLY to join the node set back to the table. A CROSS APPLY would not have been necessary if we were shredding an XML variable, instead of from an XML column in a table. The nodes() method easily shreds XML data from XML columns as well as from XML variables. The nodes() method requires table and column aliases (T(C)) in order for other XQuery methods (like the value() method) to access the node set that the nodes() method returns. The column and table alias names are irrelevant.
Notice that we’ve used a WITH XML NAMESPACES clause to declare the XML namespace. Declaring the namespace is necessary because the Demographics XML structure uses typed XML – its XML data is associated with an XML schema.
Now that our XML data has been shredded, the results can be stored in a table or combined with other queries.
Nodes() Method Application and Efficiency
Keep in mind that using the nodes() method in simple queries can unnecessarily reduce query efficiency. When run in the same batch, our query that used the nodes() method cost 54% of the batch, where the value()-method-only query cost just 46%:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
-- using value() method only ;WITH XMLNAMESPACES ('http://schemas.microsoft.com/sqlserver/2004/07/adventure-works/IndividualSurvey' AS ns) SELECT FirstName, MiddleName, LastName, Demographics.value('(/ns:IndividualSurvey/ns:Occupation)[1]','varchar(50)') AS Occupation, Demographics.value('(/ns:IndividualSurvey/ns:Education)[1]','varchar(50)') AS Education, Demographics.value('(/ns:IndividualSurvey/ns:HomeOwnerFlag)[1]','bit') AS HomeOwnerFlag, Demographics.value('(/ns:IndividualSurvey/ns:NumberCarsOwned)[1]','int') AS NumberCarsOwned FROM Person.Person WHERE BusinessEntityID = 15291 GO -- using nodes() method ;WITH XMLNAMESPACES ('http://schemas.microsoft.com/sqlserver/2004/07/adventure-works/IndividualSurvey' AS ns) SELECT FirstName, MiddleName, LastName, C.value('ns:Occupation[1]','varchar(50)') AS Occupation, C.value('ns:Education[1]','varchar(50)') AS Education, C.value('ns:HomeOwnerFlag[1]','bit') AS HomeOwnerFlag, C.value('ns:NumberCarsOwned[1]','int') AS NumberCarsOwned FROM Person.Person CROSS APPLY Demographics.nodes('/ns:IndividualSurvey') AS T(C) WHERE BusinessEntityID = 15291 GO |
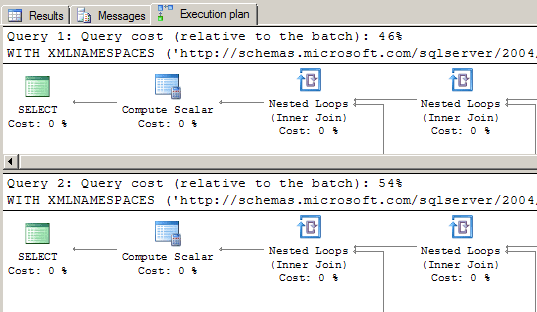
In light of this, why use the nodes() method at all? For simple queries, it’s probably better not to use it, although the batch cost or query time differences may be negligible. We’ve shown the use of nodes() in a very basic example, but it can also be used in more complex queries where it is necessary to return subsets of node sets – using nodes() on a nodes() result. It’s also very convenient to use for constructing new XML from existing nodes. Since nodes() works by rendering logical portions of XML instances as node sets, it’s ideal for when query results must be returned in node form.
Combining XML
Another, perhaps more uncommon procedure, would be to merge XML data from different instances. Let’s do just that to demonstrate – we’ll combine all of the store survey data from the Sales.Store table into one XML structure, for SalesPersonID 282. The store survey data is in the Demographics XML column. We also want to include 2 non-XML fields for each store: Name and BusinessEntityID, as node attributes in a parent ‘Store‘ node. To complete the process, we’ll wrap the final XML structure with a ‘StoreSurveys‘ root node.
Let’s get a 5-record sample from the Sales.Store table, for SalesPersonID 282:
|
1 2 3 4 5 |
--get top 5 records for SalesPerson 282 SELECT TOP 5 * FROM Sales.Store WHERE SalesPersonID = 282 GO |

The store survey XML data (Demographics column) for the Vinyl and Plastic Goods Corporation store looks like this:
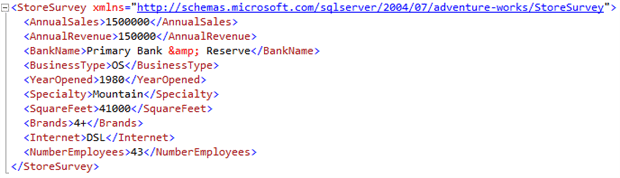
To collect all of the store survey data for one sales person into one XML instance, we can again use the FOR XML clause. As with our previous use of FOR XML, the AUTO argument will be the first one we try. Remember that the AUTO argument, by default, gathers every non-XML field into an XML structure in node attribute form. Like the PATH argument, it also nests any existing XML column data as element nodes:
|
1 2 3 4 5 6 7 8 |
-- combine store survey XML data SELECT Name, BusinessEntityID AS ID, Demographics.query('/') FROM Sales.Store AS Store WHERE SalesPersonID = 282 FOR XML AUTO GO |

We used the XQuery query() method to query starting at the root of each XML instance (by using the ‘/‘ in the path expression). It looks like we have the result we want, except that there is no root node surrounding the entire structure. We used the PATH argument in our other FOR XML example, but we cannot use it here, since we are using AUTO to obtain the node attribute values. To build the wrapper node while using the AUTO argument, we’ll use the ROOT argument:
|
1 2 3 4 5 6 7 8 |
-- combine store survey XML data using ROOT argument SELECT Name, BusinessEntityID AS ID, Demographics.query('/') FROM Sales.Store AS Store WHERE SalesPersonID = 282 FOR XML AUTO, ROOT('StoreSurveys') GO |

The addition of the ROOT argument gives us the top-level wrapper node we wanted, merging all store survey records for the sales person into one XML instance with a root node.
Separating XML
If we were to perform the converse of the previous example, we would need to pull out the individual ‘StoreSurvey‘ node block from the combined store surveys XML instance (shown above), for each store name or ID. Separating out chunks of XML data into logical records essentially involves the same procedures we use when shredding XML, but in this case we will preserve of a portion of the XML structure. To demonstrate, let’s combine the store surveys for SalesPersonID 282 again; this time, however, we will use an XML variable to store the combined store surveys:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
-- create XML instance of store survey data, using XML variable DECLARE @xml XML SET @xml = ( SELECT Name, BusinessEntityID AS ID, Demographics.query('/') FROM Sales.Store AS Store WHERE SalesPersonID = 282 FOR XML AUTO, ROOT('StoreSurveys') ) SELECT @xml |
At this point, we have the same XML structure as before:

Now we will break apart the XML into logical records, again using the XQuery nodes() method:
|
1 2 3 4 5 6 7 |
-- separate store survey XML records ;WITH XMLNAMESPACES ('http://schemas.microsoft.com/sqlserver/2004/07/adventure-works/StoreSurvey' AS ns) SELECT C.value('../@ID','int') AS BusinessEntityID, C.value('../@Name','varchar(50)') AS StoreName, C.query('.') AS Demographics FROM @xml.nodes('/StoreSurveys/Store/ns:StoreSurvey') AS T(C) GO |
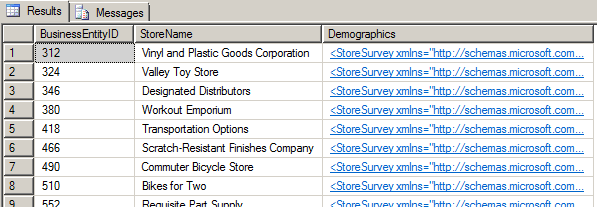
The new Demographics XML structure for BusinessEntityID 312:
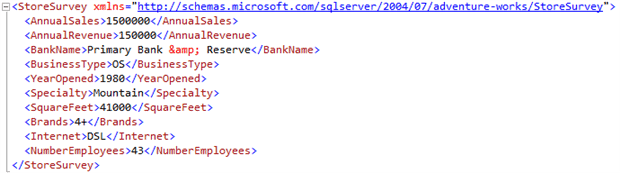
Note that we did not use CROSS APPLY this time, since the XML data was in a variable instead of an XML column in a table. Also, we used the ‘.‘, a self::node() abbreviation, in the query() method’s path expression – to pull out the store survey data. This indicates that the XML portion should be extracted from the nodes() method’s node set (the ‘Store‘ node), whereas a ‘/‘ root path expression would have caused the XML to be extracted from the root node (thus returning the entire XML structure). Also, notice that we used the parent::node() abbreviation ‘..‘ in order to reference attribute values ‘Name‘ and ‘ID‘ that are in the node above the ‘StoreSurvey‘ node (the parent ‘Store‘ node). A variation on the script that does not require a namespace declaration could be written as follows:
|
1 2 3 4 5 6 |
-- separate store survey XML records without namespace declaration SELECT C.value('@ID','int') AS BusinessEntityID, C.value('@Name','varchar(50)') AS StoreName, C.query('./child::node()') AS Demographics FROM @xml.nodes('/StoreSurveys/Store') AS T(C) GO |
The above script uses the Child axis to drill down one level further than the nodes() method’s node set, thereby eliminating the need to reference the ‘StoreSurvey‘ node directly.
Summary
We’ve taken a look at some ways to coerce XML data to fit specific needs. We handled one common request, creating XML instances from existing tables, by using the FOR XML clause – applying appropriate arguments to design the XML structure to fit specific aesthetic requirements. We demonstrated another very common procedure, shredding XML data, by employing the XQuery nodes() method. We saw that multiple XML fragments and instances can also be merged into a single instance by using the FOR XML tools. We then reversed that operation by splitting the XML instance into logical records of XML data.
Manipulating XML data to fit your needs may take creativity and some experimentation with new tools. We’ve worked out solutions for a few basic problems, but there is more to learn. The techniques that we have introduced here should help to get you started.
Load comments