
The series so far:
- Oracle sequences: The basics
- Oracle sequences: RAC
- Typical uses of Oracle sequences
- Oracle sequences – 12c features including “identity”
So far, in this mini-series on sequences, I have described the basic mechanics of sequences in single-instance and multi-instance (RAC) systems. I’ve explained the significance of setting the cache size in both cases and the order option for RAC. I’ve demonstrated how using sequences as synthetic/surrogate keys can lead to contention on the “right-hand”/“high-value” block of supporting indexes unless you take defensive actions. I’ve also shown how one of the typical strategies has been embedded in recent versions of Oracle in the scale and extend options. In this article, I’ll cover the most typical uses of Oracle sequences and highlight a couple of details of their behaviour that can cause some confusion.
Basic options
There are essentially only two things you can do with a sequence – you can ask for the “next value” by referencing {sequence}.nextval or ask for the “current value” by referencing {sequence}.currval. By making a statement that simple, I’ve already introduced a trap. The nextval for a sequence is a system-level request, the currval for a sequence is a session-level request. While nextval is a request for Oracle to generate the next available value according to the sequence definition, currval is a request to repeat the most recent value that the current session got on its most recent call to nextval. So, for example, this is what happens if you start a new SQL*Plus session and immediately call for {sequence}.currval:
|
1 2 3 4 5 |
SQL> select s1.currval from dual; select s1.currval from dual * ERROR at line 1: ORA-08002: sequence S1.CURRVAL is not yet defined in this session |
The session hasn’t yet called (and saved locally) s1.nextval, which is why it says that s1.currval is not yet defined. (Personally, I think the error message could have been more explicit – e.g. commenting that there has been no previous call to s1.nextval in the session.) Reconnect, do a couple of calls for s. nextval, then a couple for s1.currval, and this is what happens:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
SQL> select s1.<strong>next</strong>val from dual; NEXTVAL ---------- 3 1 row selected. SQL> select s1.<strong>next</strong>val from dual; NEXTVAL ---------- 4 1 row selected. SQL> select s1.<strong>curr</strong>val from dual; CURRVAL ---------- 4 1 row selected. SQL> select s1.<strong>curr</strong>val from dual; CURRVAL ---------- 4 1 row selected. |
I’ve used a select from dual to get a single sequence value but you can do multi-row selects to get a stream of sequence values, and you can also use simple assignments to get a value, e.g:
|
1 2 3 4 5 6 7 8 9 |
SQL> declare 2 n1 number(6,0); 3 begin 4 n1 := s1.nextval; 5 dbms_output.put_line(n1); 6 end; 7 / <strong>5</strong> PL/SQL procedure successfully completed. |
If you enable tracing on this anonymous pl/sql block, though, you will find that behind the scenes, Oracle will have executed a simple select s1.nextval from dual to acquire the value.
The basic rule of sequences is that you write code to generate a “rowsource”, and the sequence generator is called once per row; this produces results that aren’t always quite what you anticipate. Consider the position where I start a new session and continue using sequence s1 just after the point where I ended in the previous example, and execute the following three statements:
|
1 2 3 |
SQL> select s1.currval, s1.nextval from dual; SQL> select s1.nextval, s1.currval from dual; SQL> select s1.nextval, s1.nextval, s1.nextval from dual; |
Looking at the first statement, which (apparently) calls currval before it calls nextval, you might expect it to fail with the ORA-08002 error, but it doesn’t.
Looking at the second statement, you might expect the call to currval to report the previous value acquired by this session while nextval reports the next value from the global cache, but it doesn’t.
Looking at the last statement, you might expect to see three consecutive sequence values, but you won’t.
The results of the three statements are as following:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
SQL> select s1.currval, s1.nextval from dual; CURRVAL NEXTVAL ---------- ---------- 6 6 SQL> select s1.nextval, s1.currval from dual; NEXTVAL CURRVAL ---------- ---------- 7 7 SQL> select s1.nextval, s1.nextval, s1.nextval from dual; NEXTVAL NEXTVAL NEXTVAL ---------- ---------- ---------- 8 8 8 |
There is one call to the sequence generator for each row which is why 8 appears three times. If you include both currval and nextval in the select list, then nextval is called, and the return value used for both the nextval and the currval.
Some of the questions people ask about the “unexpected” behaviour of sequences can be answered very easily once the connection between “rows selected” and “calls to nextval” is clear. However, this doesn’t mean that “if you can write a select clause you can select a sequence”; there are cases where your code will run into the exception: ORA-02287: sequence number not allowed here, for example:
|
1 2 3 4 5 6 7 8 9 |
SQL> create or replace view v1 2 as 3 select object_name, owner, s1.nextval 4 from t1 5 / select object_name, owner, s1.nextval * ERROR at line 3: ORA-02287: sequence number not allowed here |
There are also cases where adding a sequence to the select list has a much greater effect than just being “another column.” Distributed queries, for example, may change their execution plan quite dramatically because the addition of a sequence has changed a query from “remote only” to genuinely distributed.
Sequences and DML
The most common use of a sequence is probably as the source of a surrogate (or synthetic) key, so you may see code like the following in an ETL or other large batch process:
|
1 2 3 4 |
insert into production_table select s1.nextval, … from staging_table where ... |
An important point to be aware of when you do this type of thing is that sequences and parallelism don’t co-operate very well. It would be very easy to decide that you needed to increase the speed at which you were generating data and that simply using parallel execution would help and write something like:
|
1 2 3 4 |
insert /*+ parallel(6) */ into production_table select s1.nextval, … from staging_table where ... |
A common mistake that people make at this point is to forget that parallel DML is not enabled by default, so if you want the insert to operate with DOP (degree of parallelism) 6, then you also need to execute
|
1 |
alter session enable parallel dml; |
(and don’t forget to disable it afterwards).
However, having flagged up this reminder on parallel DML, I’m now going to point out that if your code uses sequences, you might be in exactly the position where you want the select to run parallel, but the insert to run serially. Remember that sequence.nextval has to update a specific row in the seq$ table from time to time, and (more importantly) every call to nextval has to access the dictionary cache entry for that particular sequence. That means competition for dictionary cache mutexes (or latches for older versions of Oracle). You may find that the nominal benefit of parallel execution disappears in hugely increased CPU consumption due to contention.
End-user DML
In high-precision code (typically end-user facing( you may do something which requires re-use of a primary key as a foreign key to another table: orders and order_lines, for example, and there have been a few variations in method over the years. For example:
|
1 2 3 |
select s1.nextval into :local_variable from dual; insert into orders (id, …) values(:local_variable, …); insert into order_lines(id_ord, line, …) values(:local_variable, …) |
Of course, this type of approach might have been necessary when it wasn’t possible to use a sequence nextval as the default for a column. But now we can, so we could have something like:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
create sequence s1 start with 1e6 cache 1e3; create table orders ( id number(8,0) default s1.nextval primary key, date_made date not null ); create table order_lines( id_ord number(8,0) not null references orders, line# number(4,0) not null, id_product number(8,0) not null ); insert into orders (date_made) values (sysdate); insert into order_lines(id_ord, line#, id_product) values(s1.currval, 1, 999); |
This does require the programmer to know that the orders table has its primary key generated by a call to a sequence called s1. Be aware of Oracle’s syntax, which allows you to call sequence.currval after (even implicitly) you’ve called sequence.nextval. A slightly more generic, or programmer-friendly, variant might return the generated id to the client code:
|
1 2 3 |
variable m_id number insert into orders (date_made) values (sysdate) returning id into :m_id; insert into order_lines(id_ord, line#, id_product) values(:m_id, 1, 999); |
If you start using the 12c “identity” type, you probably have to adopt this approach to retrieve the value you’ve inserted. You’re not supposed to know that, under the covers, Oracle is simply using a sequence to supply a value, and you certainly should not assume you can work out the name of that sequence and call for its currval.
|
1 2 3 4 5 6 |
create table orders ( id number(8,0) generated always as identity start with 1e6 cache 1e3 primary key, date_made date not null ); |
The Merge Command
An increasingly popular strategy for updating one table from another is to use the merge command, which has the following skeleton:
|
1 2 3 4 5 6 7 8 |
merge into target using source on target.cols = source.cols when matched then update set {target_columns} = {source columns} where … delete where … when not matched then Insert ({target columns}) values({source columns}) where … |
A couple of points to watch out for in general with the merge command:
- Performance: rather than using table names for the source and target data sets, see if you can use in-line views with the minimum number of columns selected from the source and target. There is an oddity with the merge command that (unlike other SQL statements) it doesn’t automatically project only the columns that will be used – this means that it may carry far more intermediate data than it needs to. (See, for example, this post.)
- Determinism: you should view the merge command in much the same way as you would updateable join views. The
ONclause has a uniqueness requirement – there should be at most one row in the source table for any row in the target table, though there can be many rows in the target table for each row in the source table. If you don’t meet this requirement, updateable join views will raise a parse-time error of ORA-01779 relating to “non key preserved table”. With the equivalent data, the merge command may work, or it may raise a run-time error of “ORA-30926: unable to get a stable set of rows in the source tables”). The effect is not deterministic. (Side note: in Oracle 21c, the parse-time error has been removed, and updateable join views also follow the run-time mechanism.)
The key reason for picking the merge command is that it’s a nice example of how unpredictable the results of using a sequence might be – and it has also appeared a couple of times quite recently on various Oracle forums for exactly this reason.
Here’s a little script to create a small demonstration data set. I’m going to have a new data table which is going to be merged with an old data table. The old data will consist of just 50 rows with odd-numbered IDs between 1 and 99; the new data will consist of 100 rows with IDs (both odd and even) from 1 to 100. I’ll be updating based on matching IDs and inserting where there is no match.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
create sequence s1 minvalue 1001 start with 1001 cache 1000; create table old_data as with generator as ( select rownum id from dual connect by level <= 1e4 ) select 2 * rownum - 1 id, 'OLD' status, cast(0 as number(4,0)) seq_value, lpad('x',100,'x') padding from generator v1 where rownum <= 50 ; alter table old_data add constraint od_pk primary key(id); create table new_data as with generator as ( select rownum id from dual connect by level <= 1e4 ) select rownum id, 'NEW' status, cast(0 as number(4,0)) seq_value, lpad('x',100,'x') padding from generator v1 where rownum <= 100 ; alter table new_data add constraint nd_pk primary key(id); |
I’ll run three separate tests: in one, I’ll use only the when matched update clause, in the second, I’ll use only the when not matched insert clause, and finally, I’ll run a test with both clauses. To keep things simple, I won’t use the where or delete clauses. Here’s the statement with both clauses:
|
1 2 3 4 5 6 7 8 9 10 |
merge into old_data od using new_data nd on (nd.id = od.id) when matched then update set seq_value = s1.nextval, status ='UPD' when not matched then insert (id, status, seq_value, padding) values (nd.id, 'NEW', s1.nextval, nd.padding) ; |
In this case, I have 50 rows in the old data that will match and 50 that will not match. I expect to update 50 rows with s1.nextval and insert 50 rows with s1.nextval as the inserted sql_value column. Since the sequence s1 starts with 1,001, I expect to get to 1,100 by the end of this merge, and that’s exactly what happens.
The question is: can I say anything about the order in which the sequence values have been used? Will I have 1001 – 1050 in the ‘UPD’ rows and 1051 – 1100 in the ‘NEW’ rows, or will the value alternate between the two? A simple query to select id, status, seq_value from old_data order by id supplies the (initial) answer:
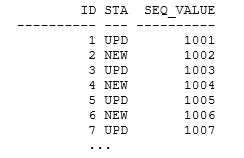
The pattern continues through the entire ordered data set – and if you check the execution plan for the query, you may be able to infer why that appears to be true in this case:
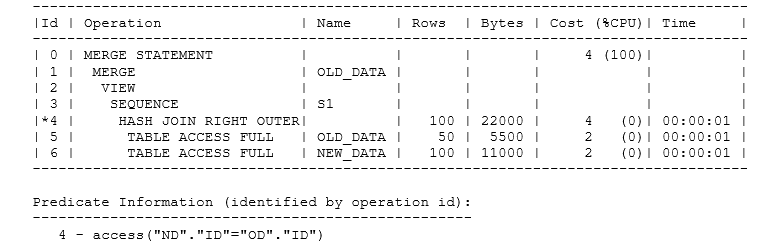
The underlying mechanism of the merge command is to join the old and new data sets. If there’s a when not matched clause, it must be an outer join. In this case, Oracle has decided to do a “right outer” hash join, which means it has used the (smaller) old_data data set as the build table and a table scan of the new_data table to probe the build table. Since every row from new_data survives the probe, the sequence numbers are applied in order to the rows in the new_data table (which, thanks to my original CTAS) gives the impression that the sequence and the id values are in sync.
But what would happen if Oracle decided to do the outer join the other way round? I checked the outline Information for this plan and changed a swap_join_Inputs() hint to a no_swap_join_inputs() hint to make this happen, changing the last three lines of the plan to:

And this is how the updated data looked:
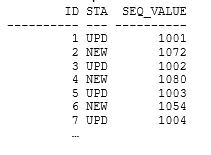
There is still a pattern. The odd IDs, when ordered, produce the sequence values 1001 to 1050 in order; again the apparent lock-step is a side effect of the original CTAS. However, the newly inserted even IDs show a random ordering of the seq_value column because of how the outer hash join works when the build table is generated from the preserved table.
The key feature here is that there’s a degree of unpredictability of how your newly arriving data may end up with sequence numbers that don’t seem to match the order of arrival very well. In a relational database, this shouldn’t really come as a surprise, but if it seems to have behaved “nicely” for a long time, it can be a big shock when things suddenly change simply because of a barely noticeable change in the execution plan.
There’s more, though, because sequence numbers get lost. Again, the many variations of the merge command (with where and delete clauses, in particular) can show several different ways in which values disappear. The simplest option is simply to create a merge command without a when matched clause.
Running the test using only the when not matched clause, the resulting output from the ordered result from the old_data table as follows:
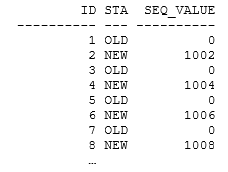
The pattern continues through the entire data set. Only the even sequence values have been used, and the odd sequence values are “lost”. Going back to my earlier comment: “you write code to generate a “row source”, and the sequence generator is called once per row.” However, it is just a little more subtle than that. In this case, the critical “row source” is the output from the hash join, and the sequence nextval is generated as each row is passed up from the hash join. Then the merge command splits the row source into two parts, the update stream and the insert stream and (in this example) discards the update stream losing half the sequence numbers.
Remote queries
Another older example of the surprises you can get if you treat sequences as if they were “just another column” is the trap of moving data from one database to another. For example, you might have some code that does a fairly simple:
|
1 2 3 4 5 |
insert into local table select {list of columns} from {list of remote tables} where {join and filter conditions} ; |
After a little tweaking, you find that you have a good execution plan, and the query runs efficiently as a “fully remote” query. Your next step is to add a (local) sequence number to the select list, but the performance takes a catastrophic nose-dive because the query is now a distributed query, and the optimizer has to optimize it locally and fails to come up with a plan that includes a remote join. An example I created for a recent note on my blog showed a plan that started efficiently like this (notice the zero selected in the second line of the statement):
|
1 2 3 |
insert into t3 (id1, id2, n0, n1, n2, v1, v2) select t1.id, t2.id, 0, t1.n1, t2.n2, t1.v1, t2.v2 from t1@orclpdb@loopback t1, t2@orclpdb@loopback t2 where t2.id = t1.id |
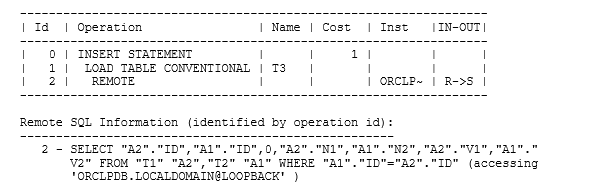
but changed to the following when the zero was replaced by a call to a local sequence:
|
1 2 3 |
insert into t3 (id1, id2, n0, n1, n2, v1, v2) select t1.id, t2.id, s1.nextval, t1.n1, t2.n2, t1.v1, t2.v2 from t1@orclpdb@loopback t1, t2@orclpdb@loopback t2 where t2.id = t1.id |
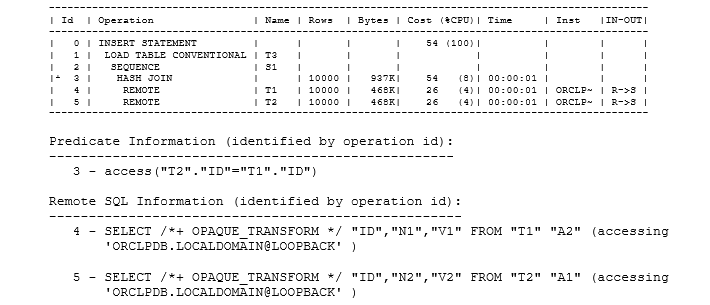
There are workarounds to this problem, but if you don’t look carefully at the things that change when you introduce a sequence, you may find that a test case on a small development system simply isn’t acceptable for a full-scale production system.
Typical uses of Oracle sequences
I’ve covered a few of the commoner examples of using sequences and highlighted four general points;
First, all you can ever do is, essentially, select the nextval and/or the currval of a sequence. If a statement includes a row source that uses a sequence, then nextval will be actioned before currval, and nextval will only be actioned once per row in that row source.
- There are row sources that do not permit the use of sequences.
- For complex execution plans, a change in the plan may give the appearance of randomizing the order of sequence values in the final output, and some plans may even give the impression that sequence values have “gone missing”.
- Finally, the presence of a sequence in a query may dictate the overall strategy of the execution plan, with the particular example of a “fully remote” query changing to a “distributed” query.
A sequence is not just another column or function – it carries some special baggage.
In the final article in this mini-series, I’ll finish with a few more comments on the latest features of sequences from 12c onwards.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments