
Jonathan Lewis' continuing series on the Oracle optimizer and how it transforms queries into execution plans:
- Transformations by the Oracle Optimizer
- The effects of NULL with NOT IN on Oracle transformations
- Oracle subquery caching and subquery pushing
- Oracle optimizer removing or coalescing subqueries
- Oracle optimizer Or Expansion Transformations
So far, this series has examined the shape of some of the execution plans that Oracle’s optimizer can produce when there are subqueries in the where clause. It was found that the optimizer will often “unnest” a subquery to produce a join rather than using a filtering operation that repeatedly runs the subquery.
In this installment you’ll see why you might want to stop the optimizer from unnesting some subqueries and also see a way to control where in the plan the optimizer positions each subquery, a detail of timing that can affect the overall workload quite significantly.
The examples use the emp and dept tables from the scott schema ($ORACLE_HOME/rdbms/admin/utlsampl.sql), and the demonstrations run from SQL*Plus on Oracle 19.11.
Scalar subquery caching
In case you don’t have access to an instance where you can create the scott schema, here’s a query to give you the highlights of the data.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
select d.deptno, d.dname, count(sal) dept_size, round(avg(e.sal + nvl(e.comm,0)),2) earnings_avg from dept d, emp e where e.deptno(+) = d.deptno group by d.deptno, d.dname order by d.deptno / |
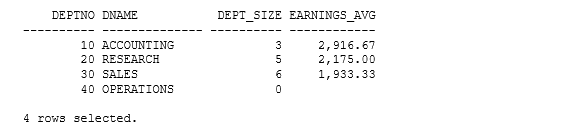
The dept table has 4 rows with a primary key on deptno. The emp table has 14 rows with a primary key on empno and a foreign key constraint to dept based on deptno. There are, however, no rows in the emp table for department 40. Both tables include a few columns that I haven’t yet mentioned.
Here’s one way to write a query to report all details about all employees who earn more than the average for their department:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
break on deptno skip 1 select /*+ qb_name(main) gather_plan_statistics */ * from emp e1 where e1.sal + nvl(e1.comm,0) > ( select /*+ qb_name(subq) */ avg(e2.sal + nvl(e2.comm,0)) from emp e2 where e2.deptno = e1.deptno ) order by e1.deptno, e1.empno / |
I’ll just point out a couple of details about the conventions used in this query:
- Because I’ve used the
emptable twice in this query I’ve used the same table alias twice but added a numeric suffix to make each use unique; then I’ve used the relevant alias with every column reference - The query consists of two query blocks, so I’ve named each query block explicitly with a
qb_name(“query block name”) hint.
Here’s the result of the query:

And here’s the execution plan that appeared by default on my instance (generated using the autotrace option from SQL*Plus):
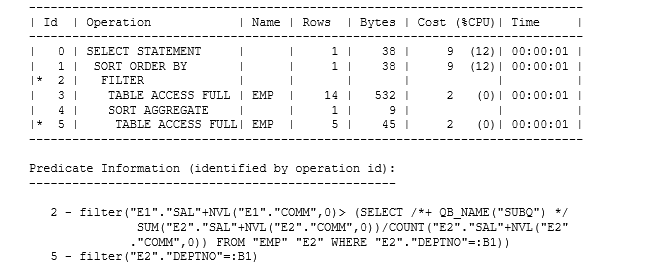
The optimizer has decided to execute this query exactly as it is written, using a correlated subquery to filter out rows from an initial table scan of emp. Operation 2 (FILTER) calls its first child to get rows from emp then for each row in turn calls the subquery passing in the current deptno as the correlation variable (the bind variable :B1 in the Predicate Information).
Here’s an important question: how many times does the correlated subquery actually run? Is it really once for every single employee, or can Oracle find a way to avoid some of the work at runtime while still following the structure of the plan?
You’ll notice that I’ve included the /*+ gather_plan_statistics */ hint in the query. If I set serveroutput off and re-execute the query, I can make a call to dbms_xplan.display_cursor() with the allstats last format option to show the rowsource execution statistics – which look like this:
|
1 2 3 |
set serveroutput off -- execute query here select * from table(dbms_xplan.display_cursor(format=>'allstats last')); |

As you can see from the Starts column for operations 4 and 5, the subquery ran only 3 times (once for each department in the emp table). This is an example of scalar subquery caching at its most effective.
Each time the correlated subquery is called session “remembers” the input value (deptno) and result (avg()) of the call in a local cache and if the subquery is called with an input that has previously been used the session gets the result from this cache rather than actually running the subquery again and, as an extra little boost, doesn’t even check the cache if the deptno for the current call is the same as the one for the immediately preceding call. This means that some queries can execute much faster than the execution plan would suggest, and that’s a good argument for blocking subquery unnesting (or even rewriting your query) if you know your data well enough to be certain that the caching feature will work in your favour. There’s a note that expands on this observation at: https://jonathanlewis.wordpress.com/2006/11/06/filter-subqueries/
There’s a threat hidden behind the benefit, though, a threat that is a side effect of the way that Oracle Corp. has implemented the caching mechanism.
For many years I used to do a demonstration where I updated one row in a much larger emp table after which a query like the one above that had previously been taking just 10 milliseconds to complete suddenly took 20 seconds of CPU time using exactly the same execution plan. The problem was that I had carefully updated a specific row in a way that “broke” the caching mechanism and resulted in the session running the subquery more than 3,000 times when it had previously been running it just 6 times.
I can’t do anything so dramatic on paper with this data set but can demonstrate the nature of the issue by recreating the data set after editing the script to modify one of the department numbers. Originally the departments were created by the statements:
|
1 2 3 4 |
insert into dept values (10, 'ACCOUNTING', 'NEW YORK'); insert into dept values (20, 'RESEARCH', 'DALLAS'); insert into dept values (30, 'SALES', 'CHICAGO'); insert into dept values (40, 'OPERATIONS', 'BOSTON'); |
I’m going to change this to:
|
1 2 3 4 |
INSERT INTO DEPT VALUES (310,'ACCOUNTING', 'NEW YORK'); INSERT INTO DEPT VALUES (20, 'RESEARCH', 'DALLAS'); INSERT INTO DEPT VALUES (30, 'SALES', 'CHICAGO'); INSERT INTO DEPT VALUES (40, 'OPERATIONS', 'BOSTON'); |
In the emp table, this means I’ve also changed three occurrences of department 10 to department 310.
With the modified data set nothing changes – except the number of times the subquery starts – here’s the plan with rowsource execution stats from the modified data:

Note that the subquery (operations 4 and 5) has now reported 5 starts rather than 3.
The reason for this is that the scalar subquery cache is based on hashing – and since hash tables are always of limited size you can end up with “hash collisions”. I’ve laboriously worked out that the hash function used by Oracle for scalar subquery caching makes 30 and 310 collide. When collisions occur the internal code for scalar subquery caching doesn’t attempt to do anything clever like creating a “hash chain”, it simply executes the subquery for the problematic second value every time it re-appears.
Department 30 appeared very early on in the initial table scan of emp so Oracle ran the subquery and cached the department number and average salary for future re-use; a few rows later department 310 appeared for the first time so Oracle ran the subquery and found that it couldn’t cache the result, and the same thing happened two more times before the end of the driving table scan: resulting in two starts more than were in the original “perfect” run.
In many cases the difference in performance may not be noticeable, but if you have some queries of this type where performance varies dramatically because of the luck of the caching effect it’s nice to understand what’s happening so that you can choose to work around the problem.
Pushing subqueries
Another feature that can affect the amount of work that takes place when a query involves a subquery is the timing of the subquery. In some cases, you may find that you can reduce the number of starts of the subquery by overriding the optimizer’s decision of where in the plan the subquery should appear; in others you may find that you can eliminate more data at an earlier point in the query and do less work overall even if the number of starts of the subquery doesn’t change.
Adding a third table from the scott schema, here’s a query that tries to identify employees of a particular salary grade by referencing the salgrade table in a subquery:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
select /*+ qb_name(main) gather_plan_statistics */ e.ename, e.sal, d.dname from emp e, dept d where d.deptno = e.deptno and exists ( select /*+ qb_name(subq) no_unnest */ null from salgrade s where s.grade = 5 and e.sal between s.losal and s.hisal ) / |
By default, Oracle has a strong tendency to run filter subqueries at the latest possible stage in the execution plan, and that’s exactly how this query behaves. Here’s the plan, with the rowsource execution stats, query block names and predicate information:
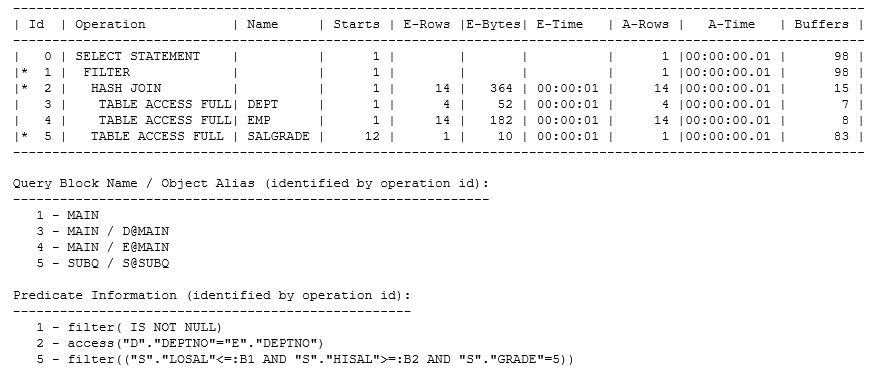
Operation 1 is the FILTER operation that says: “for each row supplied by the hash join at operation 2, start the subquery at operation 5”. Since this is a plan pulled from memory the filter predicate for operation 1 has “lost” the subquery text, of course. You can see, though, from the Query Block Name section that the original query blocks still exist, the optimizer has not transformed our subquery out of existence.
The whole of the emp data set joins to the matching dept rows before attempting to discard any data. Maybe it would be more efficient to get Oracle to test each emp row before attempting the join to dept. The mechanism for doing this is known as “subquery pushing”, and you can use the push_subq hint to force it to happen (or no_push_subq if it’s happening when you don’t want it to happen).
There are two options for the hint. It can either be put into the subquery that you want to run at the earliest possible moment, or it can go in the main query block but with the @queryblock parameter to tell Oracle which (sub)query block you want pushed. In this case I’ll add the hint /*+ push_subq(@subq) */ to the main query block, producing the following plan:
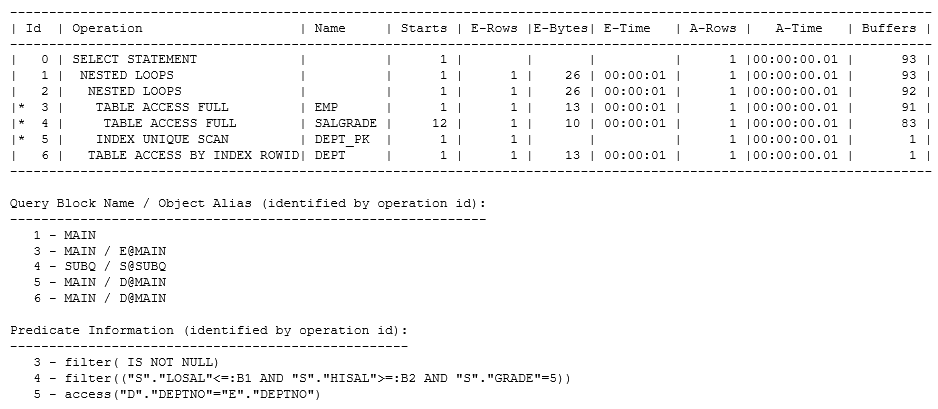
There are three important points on display here. First, although the amount of work has hardly changed and the number of starts of the subquery has not changed at all, you can see (operation 3, A-rows=1) that the number of emp rows that go into the join was reduced from 12 to just 1 which, essentially, is why the workload for this query has gone down. Secondly, because the cardinality (Rows) estimate for emp has changed so much, the optimizer has changed the join method. Finally (and the most important generic point when reading execution plans) the filter operation has disappeared, re-appearing only as a filter predicate at operation 3 although (because the plan was pulled from memory) the subquery text itself has, as in the previous example, been “lost”. In cases like this, if you’re only using the basic “first child first –move down and right” strategy for reading a plan you’ll misinterpret the plan.
The Query Block Name information shows that operation 4 represents the query block called subq. That’s the big clue showing that you need to think first about the nested loop join that is operations 1,2,3,5 and 6 (labelled MAIN) – and then worry about how to stitch the subquery that is operation 4 into that nested loop. When putting the subquery to one side and then bringing it back for later consideration, it’s easier to see that you have a nested loop from emp to dept but run the filter subquery against each emp row before joining to dept.
It’s worth noting that in this example there is a correlated subquery acting as a filter predicate against a table access operation, it is also possible for a correlated subquery to act as a filter predicate against an index operation.
Summary
This article discussed two topics – scalar subquery caching and subquery pushing. Technically, of course, neither of these is a “transformation” in that they don’t manipulate your original text to re-engineer the query blocks that need to be optimized; one of them is a built-in run-time optimization, and the other doesn’t change the query block that you’re “pushing” (or not) – even though the rest of the plan may change as a consequence of your choice.
The number of times a subquery starts can make a huge difference to the workload – you might want to subvert the optimizer’s choice because you have a better idea of how well the caching might work; conversely if you recognize that the caching benefit shows extreme variation for a critical query you might rewrite the query to work completely differently, or you might engineer a solution that guarantees you get the maximum possible benefit from the caching mechanism.
The point in a plan where a filter subquery runs can make a significant difference to the number of times it runs or to the amount of data that passes through the rest of the plan. In either case, the impact on the total workload could be enormous. When a subquery is “pushed” to run as early as possible (whether that’s by default or due to hinting) the explicit FILTER operation disappears from the plan, and the shape of the plan changes in a way that can be very misleading if you’re following the “move down and right” method of reading a plan and haven’t checked the Query Block information and Predicate Information.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments