Protecting production data in non-production environments
Grant Fritchey discusses the need to ‘shift left’ the database and associated database testing, while keeping sensitive data secure when it is outside the production environment, and how SQL Provision can help you achieve this.
A traditional IT problem in many organizations is that the development and operations teams each work in their own silo, and each tends to regard the other as having different, and often conflicting, goals.
Developers are focused on the needs of just one application. Operations must keep the whole maze of production systems running throughout their lifecycles, and know that they will be left to tend each of these applications long after the developers have moved on.
Of course, everyone’s goal is the same: to deliver a constant flow of valuable functionality to the business, while ensuring that those changes protect data integrity, security and availability, and avoid performance issues and system instability. Teams have struggled to find a mechanism to make this work and many have pinned their hopes on DevOps.
In this article, I’ll focus on just one aspect of achieving this shared goal, which is the need to ‘shift left’ the database and associated database testing, while keeping sensitive data secure when it is outside the production environment. I’ll discuss the use of dynamic data masking in production and pre-production servers, and then the strategies that can help us protect the data when it moves into less secure, and less well-controlled environments such as development and test. These range for manual static masking, to data generation, to producing a masked ‘clone’ of the database, using SQL Provision.
DevOps and shift left
DevOps done wrong can feel like an excuse to eliminate, or at least marginalize, the jobs of people in operations. The development team simply agrees to implement better and more automated deployment and testing mechanisms so that they can deliver changes more safely to production.
In fact, the required operational skill-set is far broader than this implies. It encompasses instrumentation, alerting and logging, high availability, disaster recovery, resilience testing, intrusion detection, compliance and standards testing, and a lot more.
DevOps done correctly requires a cross-functional development and operations team, ensuring that both Development and Operations agree on the goals, the functional and operational requirements, and then find the methodologies and tools that allow them to deliver them. The development team need to perform database testing (integration, performance, regression, acceptance and so on), with realistic data, as soon as possible in the development cycle so that they uncover as many data-related issues as possible as early as possible. The Ops team need to help them achieve this in a way that doesn’t expose sensitive data to those you have no right to see it.
‘Shift left’ is a useful concept in helping us envision what needs to happen to help us achieve these DevOps goals. A very simplified view of the path of the development and deployment pipeline, from the start of the process until it is delivered to production, will look like this:

The idea, in essence, is to shift left the production environment as far as possible. This means having production behaviors and processes not only in your pre-production or staging environments, but also extending left, as far as possible, into your test environments, and in your integration and development environments.
In cases where an application is never fully tested against real data until it’s released to production, we tend to see a lot of data-related issues. Code fails because it encounters unexpected data values (outside the expected range of values) or unexpected data types, or it performs terribly because the queries it executes were tested on a volume and distribution of data entirely different from what’s present in production.
By shifting left, we simply aim to catch data-related problems much earlier, fix the problem, put tests and error handling in place so they can’t recur, and stop them ever reaching production. However, the shift left concept also introduces security and administration issues for the people tasked with managing production data.
DevOps and the database
There are often legal or ethical reasons why certain data should be visible only to a limited set of known people. Further, the information in a database is important to the business and there are valid concerns about that information leaving the protected and secured environments of the production system. Once it lands in the much less protected, and probably not at all secure development arena, you’re open to all sorts of interesting possibilities, such as data on a developer’s laptop being left on a train.
At the same time, you want to shift left realistic data, so that the data used for development and testing work is as near to production as possible. You want there to be similar data volumes. You absolutely need similar distribution of the data, to see similar behaviors in the queries written against it. You want the data to mirror the behaviors and quirks of data in production. Finally, you need database and data provisioning to be automated, so that you get all this data quickly, and exactly when you need it during your development and testing cycle.
However, the people in charge of production data can’t, won’t, and shouldn’t give you access to that data.
What now?
Strategies to protect sensitive data outside production
How does a team responsible for the production database, who strive to meet the developers in a DevOps process, ensure that data remains secure outside the production environment, and that sensitive or personal data cannot be viewed?
This section will review the traditional approaches to provisioning databases with realistic data, and describe how they work, what they do, and where they have issues.
Protecting data in UAT: dynamic data masking
Introduced in SQL Server 2014, Dynamic Data Masking allows you to tie SQL Server database security directly to the data. You can then determine, based on permissions within the database, or even on the table, which groups or logins can see which data. It’s controlled at the database level, so no changes to application code are necessary. However, you do have to change the structure of your database.
Setting it up is easy. Let’s assume a table that looks as shown in Listing 1.
|
1 2 3 4 5 6 7 8 9 10 11 |
CREATE TABLE dbo.Agent ( AgentId INT IDENTITY(1, 1) NOT NULL, AgentName NVARCHAR(250) NOT NULL, AgentDetails NVARCHAR(MAX) NULL, EmailAddress NVARCHAR(254) NULL, SocialSecurityNumber NCHAR(11) NULL, CONSTRAINT AgentPK PRIMARY KEY CLUSTERED ( AgentId ASC ) ); |
Listing 1
There are two pieces of sensitive data here, EmailAddress and SocialSecurityNumber. Let’s assume that we decide to mask the SocialSecurityNumber using Dynamic Data Masking. There are a number of ways we could do it, but we’re going to use a simple function to turn all values to ‘X’ except the first three, as shown in Listing 2.
|
1 2 3 |
ALTER TABLE dbo.Agent ALTER COLUMN SocialSecurityNumber ADD MASKED WITH(FUNCTION='partial(4,"XX-XXXX",0)'); |
Listing 2
These DDL ALTER statements would not be included in the source code, but supplied by whoever is responsible for database security, and they would apply them separately as part of the production deployment process.
Assuming the masking required for all tables has been defined, and applied as part of the deployment to the production database, let’s now simulate an application user who only has privileges to read from the tables.
Listing 3 creates a local database user, Tim, but doesn’t require us to create a login for him, which is very useful for this type of testing. We grant Tim access to the table and then use the EXECUTE AS USER statement to change to Tim’s execution context. Having executed the query, we REVERT to our own login.
|
1 2 3 4 5 6 7 8 |
CREATE USER Tim WITHOUT LOGIN; GRANT SELECT ON dbo.Agent TO Tim; EXECUTE AS USER = 'Tim'; SELECT a.SocialSecurityNumber FROM dbo.Agent AS a; REVERT; |
Listing 3
The results look something like this:
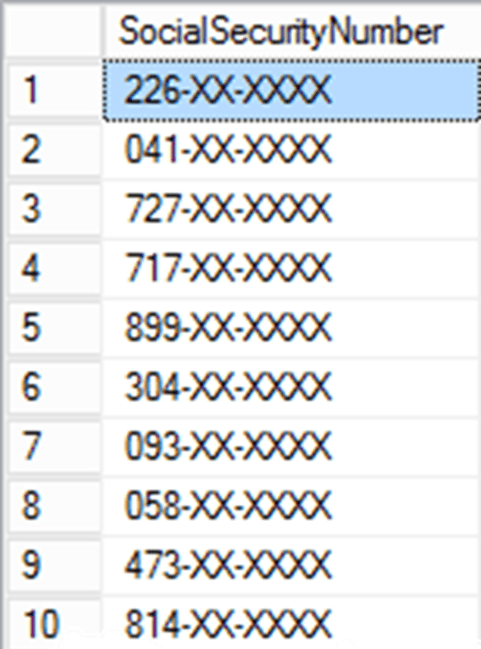
As you can see, the data is masked, ensuring that sensitive production data isn’t exposed from within the application. The masking changes are persisted with the database, so they’ll survive a backup and restore. This makes DDM a great choice for protecting sensitive data when provisioning environments such as User Acceptance Testing, where access privileges are strictly controlled through the application, and the user can’t perform ad-hoc querying.
We simply restore to UAT the latest backup of the DDM-protected production database. Of course, remember that if you have a terabyte of data in production, that’s how much data you’ll have in UAT too.
DDM was not, however, designed to protect data in environments such as development, where developers tend to work with elevated database privileges, and can perform ad-hoc querying. Firstly, any developer with ‘dbo’ or ‘sa’ privileges will not even see the masking, and secondly there are a few holes in the masking that mean that even without elevated privileges, ad-hoc querying can still expose sensitive data.
So how do we provide realistic data to our development and test environments, while still ensuring data is protected?
Protecting data in development and test: manual or static data masking
Many DBAs use custom scripts to manually mask the data from production, before making it available to development and test environments. However, production data is big and creating the scripts to carefully ‘de-identify’ this data takes time, and you also need to maintain those scripts.
If DDM is already used in production, as described above, then then you could possibly extend this technique, effectively turning the ‘dynamic’ mask into a ‘static’ mask, such that no sensitive data is available for viewing in unmasked form, in the development environment. We can use the BCP utility, authenticated as low-privilege user, to export the data, in native format, from any tables with dynamically-masked data. This means that, for example, the exported Social Security Numbers in the exported data file will be in their masked form (such as 814-XX-XXXX). We then build the latest database, from version control, and use BCP to re-import the data from the data file.
Getting the data in and out
Phil Factor has covered in separate articles a lot of the detail around both bulk importing and bulk exporting data.
This technique is probably best suited to smaller databases, but it should work well enough in cases where all tables use surrogate keys, which won’t be masked. However, if your tables use natural keys that require masking, then the resulting ‘static’ masked data will lose the distribution characteristics of the original production data, making it less useful for testing.
Generating custom data
If you can’t use either of the above techniques to mask data, or it simply isn’t permissible in your organization to reuse production data, masked or otherwise, then you’ll need to consider generating test data. Instead of attempting to shift left your production database, you can simply build the database from source control, at the correct production version, and stock it with generated data.
Redgate SQL Data Generator (SDG) is a tool specifically for creating this type of test data. As a user, we use the tool to define the data generation strategy for each of the columns in our tables (in other words, the nature and volume of the data we want the tool to generate in each case) and save it as a SQL Data Generator project file.
You’ll find basic details of all the various options and methods you can use to generate your data in this documentation, and good examples of how you can control precisely what data the tool generates, as well as how to use PowerShell to automate the data generation process, in the SDG section of the Redgate Community hub.
Essentially, you need to build a copy of the required database, on your test server and then define the SDG project to fill it with data. Having done this, we can reuse the SDG file to generate the same data, each time we need to create a fresh copy of that database for testing purposes. This means that your test data is consistent and reliable, ensuring that your tests will be as well.
This approach has several advantages. You get to control precisely, with zero surprises, the data that’s available within your non-production environment. Automating the process in this manner also means you can have a clean set of data any time you want it. You can keep the data set small so it reduces the whole space headache and speeds up the process.
The single biggest shortcoming to this approach is that the data isn’t from production. While you can ensure it is similar in nature to the production data, it likely won’t have the same distribution of data in production, and it won’t have all the same ‘quirks’ that so frequently plague real production data. You’ll also likely be working with much less data, so won’t be certain how well your queries will scale to production volumes.
Using DBCC CLONEDATABASE
One way you can mirror the behavior you see in the production database, in terms of producing realistic execution plans, without needing to copy around a lot of data, is to use the new DBCC CLONEDATABASE function, introduced in SQL Server 2016. It creates a copy of your data structure, all your statistics, and all the Query Store information. The only thing it doesn’t move is your data. The implementation is extremely easy:
|
1 |
DBCC CLONEDATABASE(MovieManagement, MovieManagementCopy); |
This will create a second database, marked as Read Only, on the server on which you run the command. Microsoft recommends that you don’t work with this on a production system. After creating it, take a backup and then move it to development or test system, then drop the read-only copy from the production system (just be careful that you drop the right database!).
Using DBCC CLONEDATABASE to shift left the database means that we can perform useful query tuning in the development and test environments, without needing to copy around all the data. With the database structure and statistics, the execution plans should match what you’d see in production.
However, there are some inherent problems too. Firstly, there is no data, so we can’t verify that our queries return exactly the data we intended. At the same time, there is potentially more data in there than you want. Both the statistics and Query Store, if you have it enabled, carry values from the production environment into this new database. Either of these could be considered a leak of protected data. This means that, depending on the nature of the data protection regulations in your organization and industry, use of DBCC CLONEDATABASE for database provisioning could be a non-starter.
SQL Provision and shift left
Having implemented a way of protecting your sensitive data when it’s outside the production environment, or a way to generate data so that it mimics as adequately as possible what’s in production, you still need to tackle the shift left problem.
Typically, you’d need to prepare the database containing masked or generated data, then restore a backup of that database to all the servers that required it, and then repeat that process nightly, or however often the data needs to be refreshed. It can be a time- and disk space-consuming task.
SQL Provision is a database provisioning tool comprising SQL Clone and Data Masker for SQL Server. SQL Clone can supply real database copies for development and testing, quickly, because it avoids the need to copy around the MDF and LDF files (for example, by restoring a backup) for each server that requires a copy of the database. Instead, it creates one image of a SQL Server database or backup, and uses it as the source for multiple clones. Each clone works just like a normal database, but takes only a few seconds to create and requires a few tens of MB of disk space. It does this using standard Windows virtualization technology to allow it to reuse the same image bytes many times, in each clone. In other words, SQL Clone will make shifting left the database a much more lightweight task, because it radically reduces the time it takes, and space that’s required, to create all the required copies of the databases, as you shift left your production data.
With Data Masker, we can build a set of data masking rules that describe, step-by-step, how each column and row that contains sensitive or personal data should be obfuscated, before it leaves the secure production environment. For example, I’ve written examples that demonstrate how you might use Data Masker’s rules to spoof credit card data, realistically, or mask address data, while retaining the distribution and characteristics of the real data. SQL Clone will apply all these rules as an integral step in your PowerShell-automated database provisioning process.
If you can’t use masking, Phil Factor describes how to use a set of Redgate tools, including SQL Data Generator, via PowerShell, to build a database from object-level source, stock it with data, document it, and then use SQL Clone to provision any number of test and development servers.
Alternatively, if you use the DDM and BCP scheme, outlined earlier, then you can create a data image from the ‘statically masked’ database and then create as many clones as you like, for work in test and development. Whichever technique you use, each of the clones will be only tens of MB in size and take little time to create. The cost savings in both disk space, speed, and data movement is what is going to make shift left more viable and easier within your environment.
Conclusion
Incorporating a DevOps approach to databases and database development can be challenging. Adopting the shift left approach necessary to make DevOps work well and successfully within your organization represents one of the largest aspects of this challenge. There are several tools and methods you can use to make this movement into DevOps work, but the most efficient is to implement SQL Provision, along with your existing encryption techniques and custom scripts.
If you’d like to find out more about SQL Provision or SQL Data Generator, you can download a 14-day, fully-functional, free trial of each tool.
Tools in this post
Data Masker
Shield sensitive information in development and test environments, without compromising data quality
You may also like
-

Article
How SQL Clone and SQL Change Automation enable seamless Database Branch Switching
Learn how SQL Clone and SQL Change Automation, used together, now allow you to branch your database in Git as quickly and simply as your code.
-

Article
How to generate realistic text data using SQL Data Generator
To get the best results, you need to provide SQL Data Generator with some hints on how the data ought to look. Phil Factor nudges it towards realistic text data.
-
Article
How to reset your development database in seconds using SQL Clone
Owen Hall describes the new "clone reset" feature, how it works and the database development and testing processes it enables, or makes simpler and quicker.
-

Article
SQL Prompt and other Tools now use a Dedicated Entra ID Application for Azure SQL Databases – Update Required
If you use Microsoft Entra ID to connect Redgate tools, such as SQL Prompt, to Azure SQL Databases, please update to the versions listed below before July 31, 2025. These versions use a new, dedicated Entra ID app to authenticate. Earlier versions use an authentication method that will no longer work after July 31st. This
-
Article
Getting Started with Automatic Database Branch Switching
Alexander Diab demonstrates how a team of developers can work on and test features in different branches of a SQL Server database development project, while their local development database automatically remains 'synchronized' with the current branch in version control.