
When I tell people that they are writing sequential file system code or Network Database code in SQL, they insist that they cannot be guilty because they never worked with those kinds of data processing. In a previous article, I showed an example from a forum posting of a tape file implemented in SQL (Mimicking Magnetic Tape in SQL). In fact, at the time I am writing this I just saw a forum posting where the poster was having trouble with a procedure:
- Use an integer (n) as the parameter. It is how many day ago to archive.
- computed (n) days back from the input date and put it in a local variable.
- Checked to see if a table for archives existed or not (Hey, people can dismount a tape, so you always checked the tape label before you write to it).
- Insert rows from the base table into the archive table. Replace “row” with “record” and “table” with “tape” and you have a classic tape file operation. Oh, the old IBM tape labels were “yyddd” from the system clock. There are good Y2K stories about that, but I digress.
- Delete the inserted rows from the base table (aka Master tape or punch card deck)
See the physical movement of punch cards from deck to another? It never occurred to the poster to simply have a status column in the table, which has ‘archive” as a possible value. A simple update everything in the procedure and we do not need a local variable to hold the computation, like we did in COBOL or assembly language.
|
1 2 3 |
UPDATE Foobars SET foobar_status WHERE creation_date <= DATEADD (D, -ABS(@in_day_back), CURRENT_TIMESTAMP); |
The ABS() is a safety in case we get a negative input.
A similar, but more complicated problem, is seeing a Network Database in disguise. The first problem is that commercial products were all different. And they all used different terms. ANSI X3H2, the Database standards committee, created a CODASYL Standard that became the NDL language. The hope was that NDL would be a reference model to get the product terminology aligned. But nobody used it. In ANSI X3H2, we approved it, forgot it and let it expire while we went to work on SQL. I might have one of the few existing copies of the NDL standard in the world; if anyone has a Gütenberg Bible, I will trade.
Network Database Basics
Network Databases use pointers. A lot of current IT people have never worked with pointers. Their languages hide them from the programmer and do all the garbage collection and dirty work for them. And in SQL, the closest thing we have is a reference, which is not a pointer.
In the simplest terms a pointer is a languages construct that resolves to a PHYSICAL address in storage. Notice that I did not say if that was primary or secondary storage. And I did not define what “resolves” means. Yes, it can be primary or secondary storage, with data pages swapping in and out of virtual memory. But resolution is a little trickier. In low level languages, a pointer simply gets you to a position on the data page, but you have no idea what it is pointing at. The program decides upon arrival. Higher level languages have pointers that are declared as to their targets, which can be simple data types (“pointer to integer”, “pointer to string”, etc.) or whole records (“pointer to parts record”). The Network Databases were based on record pointers.
The terminology “link”, “parent”, “master”, “child” and so forth all come from Network Databases. They are not part of RDBMS, but you will find new (or bad) SQL programmers inventing terms like “parent table” or “link table” because they never left a Network Database mindset.
These tools have a NEW() function to create a new, unused pointers as needed and a NIL pointer (not NULL!), which is a pointer to nothing, an end of the chain of links. To navigate the pointer chains, we also have a NEXT function that uses the pointer value to get the next record in the chain.
The target of a pointer can be changed or deleted. Two pointers could have the same target. Basically, anything you can draw with boxes and arrows can be done with pointers. Hey, why don’t we draw some boxes and arrows! I will use Chris Date’s classic “Suppliers & Parts” Database for these examples.

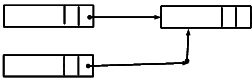
Here is a simple linked list of parts. You can start at the “Bolt”, invoke the Next() procedure and get the “Nut”; invoke Next() again and get the “Washer”; invoke Next() again and you a message that you hit a NIL, then end of the chain. You are navigating this network, procedurally.
The real power is when you have more pointers in a record. Going back to the suppliers-and-parts. Let’s put parts as children to suppliers as parents. That would look like this:
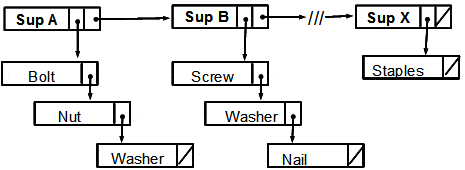
Each node has two pointers. This actually the structure used in the LISP language, with the names CAR (pronounced “car”, short for “contents of A register”) and CDR (pronounced “cudder”, short for “contents of C register”). The weird names come from the original hardware of the first implementation. They are the head and the tail respectively of a list.
What did you notice about this structure? It is quick and easy find a Supplier by going from tail to tail until you find who you wanted. You then go down the head chain to find the parts from that supplier. Bad news: If I want to find all the suppliers who stock washers, I still have to chase down the parts chain of each supplier. I also cannot go back up the chain.

I can also make a circular list, letting you get back to the start of a list by looping around.
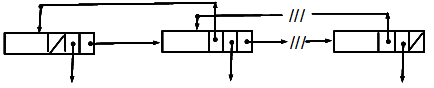
You can get around this problem with a double linked list. It has a extra pointer in each node that goes back to the prior node in the chain.
Different pointers can have the same target, so there is only one occurrence of a node in the system with many references to it.
I can also create nodes with multiple pointers and kinds of things. It can get complicated. And it is fragile. When I delete a node, I have to take pointer and make it the pointer of the prior node the chain and leave the deleted node as an orphan floating in the storage space. If a link is broken, restoring it can be a problem.
Many decades ago I worked for a bank that paid employees by starting a free checking account and making deposits to it. The checking database was a hierarchy which started with wholesale (commercial) and retail (consumer) accounts, then broke retail into internal (employees) and external accounts. The internal accounts were then broken down by department and then you finally got to the actual account. The department for which I worked was sold when banks were no longer allowed to compete with timeshare computing companies.
I went to a branch bank to see if I had gotten my final check (no on-line banking back then). The system crashed. The system crashed every time I asked for the next week. My former department had been deleted and the pointer chain was broken. It never occurred to anyone that a department would disappear while it still had valid accounts in it.
The utility programs for Network Databases had to do garbage collection and restore broken links, or misplaced links (parent Account A gets a bad link and sudden has the children of Account B).
Faking Network Database in SQL
Just as programmers mimicking tape files used IDENTITY for a sequential record number, the “Network Mimic” uses GUIDs, UNIQUEIDENTIFIER and NEWID(). It is no coincidence that NEWID() looks like the NEW() pointer function in a Network model.
Let me look at a forum posting that demonstrates the Network mindset in action. I had to provide the DDL, since the poster did not. In fact, he has a NULL-able column as a Primary Key in his narrative, so it will not compile.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
CREATE TABLE TBL_Events ( event_id UNIQUEIDENTIFIER NOT NULL PRIMARY KEY, location_id UNIQUEIDENTIFIER REFERENCES TBL_Locations (Location_id), notes_txt VARCHAR (500)); CREATE TABLE TBL_Locations ( event_id UNIQUEIDENTIFIER NOT NULL REFERENCES TBL_Events (event_id), location_id UNIQUEIDENTIFIER NULL PRIMARY KEY, notes_txt VARCHAR (500)); |
Yes, he put the “TBL-” prefix on the table names. Since Network Databases could have many different storage structures, the engine needed to know what was what. In SQL,this is redundant as well as a violation of ISO-1179 rules. We only have tables and they are in limited flavors. Yes, both his tables have the same columns.
To quote the posting: ..
>> ”Locations is the parent table with a relationship to events through Location ID.” <<
See the word “parent” instead of the SQL “Referenced” and “Referencing” tables?
To continue: …
>> Location_ID is set to be NewID() on create in Locations, and Event_ID is set to be NewID() on create in events. <<
This is pointers, not keys. GUIDs are not attributes of either events or locations. They have meaning only after you get to the target of the pointer.
>> The table, relationship, and PK format is non-changeable due to organizational policy governing replication. <<
GUIDs for replication instead of keys is a different issue. It is at a higher level than the schema and treats the whole schema and tables as the unit of work without regard to their content.
>> I’m looking for advice on how to define an INSERT TRIGGER that will create a new row in Events, with the location_id pulled from the parent Locations table, and a new unique event_id. E.g., when (by outside application with no ability to embed SQL) a new Locations record is created, it gets a location_id of 8170daed-92c8-47f1-98ca-147800329686, and the trigger creates a new event record also with a location_ID of 8170daed-92c8-47f1-98ca-147800329686 and an event_ID of cfed8fe8-b5be-4f78-b366-008672e39637. <<
Records and not rows. Oh, that’s right; Network Databases have records. The mindset always shows up in the terminology you use. What he is trying to do with procedural trigger code is Network navigation. Can you guess where 8170daed-92c8-47f1-98ca-147800329686 is on a map? I use (longitude/ latitude) or HTM (hierarchical triangular mesh) instead; both are industry standard, verifiable with the GPS on my cell phone and reproducible. Likewise, an event should have a name that a human being can understand. And they will both be shorter than GUID.
The idea that an event is BOTH an entity and an attribute of a Locations is absurd. The Events and the Locations have a relationship. What he is trying to build is a double linked list mechanism that would be part of a Network Database engine.
The right way to do this is:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
-- entity CREATE TABLE [Events] ( event_id CHAR(15) NOT NULL PRIMARY KEY, observation_txt VARCHAR (500)); -- entity CREATE TABLE Locations ( location_htm CHAR(18) NOT NULL PRIMARY KEY, observation_txt VARCHAR (500)); -- relationship CREATE TABLE Event_Calendar ( event_id CHAR(15) NOT NULL REFERENCES [Events](event_id) ON DELETE CASCADE ON UPDATE CASCADE, location_htm CHAR(18) NOT NULL REFERENCES Locations(location_htm), event_start_date DATE NOT NULL, event_end_date DATE NOT NULL, CHECK (event_start_date <= event_end_date), PRIMARY KEY (event_id, location_htm)); |
Notice that relationship has its own attributes, such as the time slot in which it occurs. I decided that this is a one-to-one relationship; the poster didn’t tell us. I can change this to one-to-many or a many-to-many relationship by changing the PRIMARY KEY. Try doing that in a Network Database! The above schema is easy to search by either location or by event. This is one many reason RDBMS beat out the navigational model of data.
“Perfecting oneself is as much unlearning as it is learning.”– Edsgar Dijkstra



Load comments