

I keep telling people that they are writing magnetic tape and punch card programs in SQL. They reply that they do not know what a punch card is, and have never seen a magnetic tape drive. Therefore, they believe that their SQL is just fine.
Let’s ‘Wikipedia’ and ‘Google up’ pictures of punch cards and tape drives, so the kids can be grateful for what they have today. The physical media is not what is important; the consequences of the physical media are.
When you sit in a live theater, you cannot do a close-up, pan shot, zoom, dissolve or other effect that are common in movies today. Early silent films parked the camera in one position and mimicked a theater experience. This is a general systems principle that the new technology will first mimic the previous technology before it finds its own voice.

Look at a deck of punch cards or a reel of tape. Their records are in a sequential file structure, necessitated by the physical media. Random access in a deck of punch cards is impossible; random access in tape is impractical. Whenever you see a table with an IDENTITY property, the programmer is mimicking that sequential physical ordering and not doing RDBMS modeling.
This means that sorted order is fundamental in sequential files. It also means that we process things one record at a time; we have innate concepts of first, last, current, prior and next records. The world is “left to right” and there is no higher level abstractions. Fields are all fixed length strings that are read by an application program to get their meaning – i.e. no data types, defaults or constraints in the data itself.
Another innate property of punch cards and tapes is that you can concatenate contiguous fields to create a new field. COBOL, the classic language for this file structure, has hierarchical sub-fields when you define your records in the DATA DIVISION of a program. I know most Microsoft programmers do not know or even read COBOL, so let me give a simple address of a US mailing address.
|
1 2 3 4 5 6 7 8 9 |
01 ADDRESS. 05 ADDRESS-LINE-1 PIC X(40). 05 ADDRESS-LINE-2. 10 CITY PIC X(17). 1 10 STATE PIC XX. 10 FILLER PIC X. 10 ZIP1 PIC 9(5). 10 FILLER PIC X VALUE IS "-". 10 ZIP2 PIC 9(4). |
We have a field called “Address” at the highest level. It is a string in contiguous storage. We can access two sub-fields, named “address-line-1” and “address-line-2”, the first one is a 40 string of alpha characters. The second sub-field is made of sub-sub-fields that can also be accessed by name; FILLER is a special token that means it is ignored or replaced by a constant.
When you see "(CAST (terminal_nbr AS CHAR(5)) + CAST (transaction_seq AS CHAR(8))) AS sale_id” you know that they are still doing COBOL in SQL.
There was an excellent example of this mindset on the MS SQL Server forum recently. It was a table valued function which returned what is called a delta report. That is, a comparison of the change in a set of variables from one report period to another, usually annual. In English, these reports answer questions like “What is the change in sales for this year as compared to last year?”
The poster was having performance problems. This was no surprise. I am not going to post the full example; I do not need everything to make my points and a reduced model will serve. Here is my slimmed-down Sales table.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
CREATE TABLE Sales (sales_code INTEGER not NULL PRIMARY KEY, store_id INTEGER NOT NULL, sales_date DATE NOT NULL, sales_amt DECIMAL (8,2) NOT NULL); INSERT INTO Sales values (234, 1, '2011-01-23', 4.50), (544, 1, '2011-02-23', 14.50), (984, 1, '2011-03-23', 24.50), (924, 1, '2010-01-23', 3.50), (236, 1, '2010-02-23', 13.50), (876, 1, '2010-03-23', 23.50), (293, 2, '2011-01-23', 4.75), (543, 2, '2011-02-23', 14.75), (324, 2, '2011-03-23', 24.75), (980, 2, '2010-01-23', 3.75), (887, 2, '2010-03-23', 23.75); |
What we want to do is look at the sales in 2011 and 2010, and see how much things changed. The real table had a lot of other values, was comparing customers from this year against last year.
The first thing an old tape file programmer would do is draw a flowchart. Again, I am not sure that younger programmers have ever see a flowchart, but here is one.
The circle with a tab sticking out of it is a reel of tape. The triangle is a sequential merge operation. The rectangles are programs. The rectangle with a wavy bottom is a printout. The arrows show the flow of control and/or data. Got it?
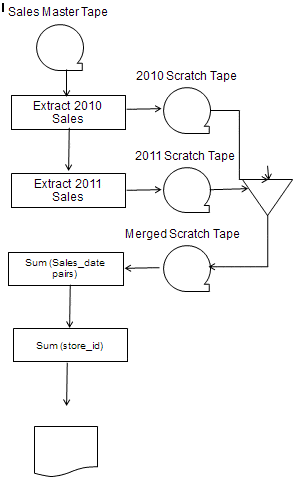 Here is how it works:
Here is how it works:
- Mount the Master Sales on a tape drive. Assume it is sorted by (store_id, sales date) rather than (sales_date, store_id); this is important– very important, and will talk about it shortly.
- We have a program that read the master and extracts the 20110 data to a scratch tape, mounted on a second tape drive. We then rewind the master tape and signal the operto4r that we are ready or the second scratch tape.
- The operator then mounts a second scratch tape and the second process which tape drive that tape is on.
- The operator tells the merge process where the first tape, second tape and final scratch (merge) tapes are mounted.
- The third scratch tape is read by a process that sums each pair of 2011-2010 values based on the dates.
- A final process does a grand total by store_id and makes a printout
Here is an anorexic re-write of the poster’s SQL function. Again, the original code was much more complicated, was implemented as a table-valued function, had other design flaws and so forth. The parameters were a date range pair in the original code.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
CREATE PROCEDURE First_Delta_Report (@in_report_start_date date, @in_report_end_date date) as WITH This_Year_Sales (sales_date, store_id, sales_amt_tot) AS (SELECT S.sales_date, S.store_id, SUM(S.sales_amt) AS sales_amt_tot FROM Sales AS S WHERE S.sales_date BETWEEN @in_report_start_date AND @in_report_end_date GROUP BY S.sales_date, S.store_id), Last_Year_Sales(sales_date, store_id, sales_amt_tot) AS (SELECT S.sales_date, S.store_id, SUM(S.sales_amt) AS sales_amt_tot FROM Sales AS S WHERE S.sales_date BETWEEN DATEADD(DAY, -364, @in_report_start_date) AND DATEADD(DAY, -364, @in_report_end_date) GROUP BY S.sales_date, S.store_id), Merge_Sales (sales_date, store_id, ty_sales_amt, ly_sales_amt, sales_delta) AS (SELECT CASE WHEN This_Year_sales.sales_date IS NULL THEN Last_Year_sales.sales_date ELSE This_Year_sales.sales_date END AS sales_date, CASE WHEN This_Year_sales.store_id IS NULL THEN Last_Year_sales.store_id ELSE This_Year_sales.store_id END AS store_id, This_Year_sales.sales_amt_tot AS ty_sales_amt, Last_Year_sales.sales_amt_tot AS ly_sales_amt, (COALESCE(This_Year_sales.sales_amt_tot, 0.00) - COALESCE(Last_Year_sales.sales_amt_tot, 0.00)) AS sales_delta FROM This_Year_sales FULL OUTER JOIN Last_Year_Sales ON This_Year_sales.sales_date = DATEADD(DAY, 364, Last_Year_Sales.sales_date) AND This_Year_Sales.store_id = Last_Year_Sales.store_id ) SELECT store_id, SUM(sales_delta) AS sales_delta_tot FROM Merge_Sales GROUP BY store_id; |
The CTE “This_Year” is the first scratch tape. The CTE ” Last_Year” is the second scratch tape. It is a direct translation of the flowchart from 1950’s into SQL. The tape merge process is translated directly into the FULL OUTER JOIN and it becomes a CTE. The main SELECT then returns the final process from the flowchart.
Yes, the CASE expressions should be COALESCE() expressions, but that is how it was done in the original because the programmer is still stuck in IF-THEN logic mindset. This lets him write SQL that looks as much like his procedural language as possible.
Do you see the magnetic tape mindset? Now let’s fix it. SQL is a data language, not a computational language, not a processing language. The first thing is that reports are done for fixed known periods in production work. It is suicide to allow date ranges as parameters because users will get “creative” and you cannot be sure they were creative in the same way. That is for ad hoc queries.
Getting back to the issue of sort order as a factor in the logic. Because the data in the Master Sales is sorted by (store_id, sales_date) we had to make two passes through the tape to get both years.
This assumes we have only two tape drives. If we had 3 or more tape drives, then we could have split out the data for 2011 and 2010 in one pass over the Master tape. In fact, you need three tape drives to do any real work. There was a horror store in a recent issue of COMPUTERWORLD’s “Shark Tank” column. The shop the writer worked in had only two old slow tape drives. They asked the boss for three newer tape drives. Instead the boss bought them two new tape drives that were twice as fast – 2 times 2 = 4 times faster, right?
So, first thing we do is create a table with our reporting periods; I am just doing the (2011-2010) delta.
|
1 2 3 4 5 6 7 8 9 |
CREATE TABLE Report_Period (report_period_name CHAR(10) NOT NULL, report_start_date DATE NOT NULL, report_end_date DATE NOT NULL, report_delta SMALLINT DEFAULT 1 NOT NULL CHECK(report_delta IN (1, -1))); INSERT INTO Report_Period VALUES ('2011-00-00', '2011-01-01', '2011-12-31', +1), ('2011-00-00', '2010-01-01', '2010-12-31', -1);---prior year |
Sneaky trick here. The two rows in the table model the two years in the 2011 report period. I happen to like the MySQL convention of using “yyyy-00-00” for a character-representation of a whole year; it makes sorting easier and it is language independent. Notice the prior year has a “report_delta” of plus or minus one. Instead of conditional logic, I use data in a data language.
Thinking in aggregates instead of sequences, we see that
|
1 2 |
SUM(this_year_sales) - SUM(last_year_sales) = SUM(this_year_sales - last_year_sales) |
Now, here is the replacement procedure, with a SQL mindset.
|
1 2 3 4 5 6 7 8 9 10 11 |
CREATE PROCEDURE Delta_Report (@in_report_period_name CHAR(10)) AS SELECT @in_report_period_name AS report_period, S.store_id, SUM(R.report_delta * S.sales_amt) AS sales_amt_tot FROM Sales AS S, Report_Period AS R WHERE R.report_period_name = @in_report_period_name AND S.sales_date BETWEEN R.report_start_date AND R.report_end_date GROUP BY S.store_id; |
That is the whole thing! One SELECT, no CTEs and no danger of a bad report range. See why I spend so much time beating up people about tables are not files, rows are not records and columns are not fields; it really matters.



Load comments