
Sometimes, you just absolutely have to generate a cross tab in SQL. It won’t do to have the reporting system do it, nor is it feasible to build that functionality into the application. For example:
- You may be using a reporting solution that doesn’t provide this functionality.
- You are using a legacy application that you’d rather not fiddle with.
- You’d like to export some data, already set out in the required format, to a text file.
It is for these exceptional cases that I decided to write a dynamic cross tab stored procedure.
The exception rather than the rule
There is a general rule which states that data manipulation of this sort is best left to the application or reporting levels of the system, and for good reason. The SQL database engine’s primary role is the storage and retrieval of information, not the complex processing of it. Anyone who has tried to pound data in SQL into a meaningful set of information, using a complicated set of business rules, will probably agree that SQL tends to discourage you from doing so, and the more fancy and creative you try to make your solution, the stronger that discouragement becomes.
It has also been said that just because you can do something, it doesn’t mean you should. True, but I for one think that the opposite is also applicable. Just because it seems that you can’t do something, it doesn’t mean you shouldn’t. It’s a balancing act that demands careful consideration. I have found some applications for which this stored procedure was the ideal solution – I hinted at these in the first paragraph. However, there are just as many, if not more, where it shouldn’t be used. The stored procedure can have an adverse affect on performance if not used correctly, or used on an expensive or large data source. I leave you with the advice that the script described here should be used carefully and sparingly, and not sprinkled willy-nilly about your databases.
Requirements
All of my demonstration code will use the trusty Northwind sample database. It comes with SQL Server 2000 by default, but if you’ve gotten rid of it, or if you’re running Server 2005, you can download it from the Microsoft website.
Once Northwind has been downloaded and attached, create the sys_CrossTab stored procedure in the database and you’re on your way.
A simple cross tab query
The Northwind database has a table called Categories, which is used to partition the full compliment of products into eight distinct groups, namely Beverages, Condiments, Confections, Dairy Products, Grains/Cereals, Meat/Poultry, Produce and Seafood. If the North Wind Trading Company were a real entity, it would not be inconceivable for one of the bean counters to request a report listing the total value of orders placed, by year, by category. This would be the perfect opportunity to try out a cross tab query. The simplest way to do this is to use the CASE function.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
SELECT YEAR(ord.OrderDate) YEAR, SUM(CASE prod.CategoryID WHEN 1 THEN det.UnitPrice * det.Quantity ELSE 0 END) Beverages, SUM(CASE prod.CategoryID WHEN 2 THEN det.UnitPrice * det.Quantity ELSE 0 END) Condiments, SUM(CASE prod.CategoryID WHEN 3 THEN det.UnitPrice * det.Quantity ELSE 0 END) Confections, SUM(CASE prod.CategoryID WHEN 4 THEN det.UnitPrice * det.Quantity ELSE 0 END) [Dairy Products], SUM(CASE prod.CategoryID WHEN 5 THEN det.UnitPrice * det.Quantity ELSE 0 END) [Grains/Cereals], SUM(CASE prod.CategoryID WHEN 6 THEN det.UnitPrice * det.Quantity ELSE 0 END) [Meat/Poultry], SUM(CASE prod.CategoryID WHEN 7 THEN det.UnitPrice * det.Quantity ELSE 0 END) Produce, SUM(CASE prod.CategoryID WHEN 8 THEN det.UnitPrice * det.Quantity ELSE 0 END) Seafood FROM Orders ord INNER JOIN [Order Details] det ON det.OrderID = ord.OrderID INNER JOIN Products prod ON prod.ProductID = det.ProductID GROUP BY YEAR(ord.OrderDate) ORDER BY YEAR(ord.OrderDate) |
This will return

So, you quickly type up the query, you show the accountant how to import the data into an Excel spreadsheet, and you’re off for a pint to celebrate your ingenuity.
Shortly thereafter, the chap decides that the data report is not quite granular enough, and would like a similar report split by product name rather than category. There are 77 products, so it involves a few more CASE statements. You grumble to yourself quietly while demonstrating your cut-and-paste proficiency and generate the new report, showing the breakdown by product.
Thanks to your report, the company decides that a few of the product lines are not generating the revenue that they should, so they drop those products and add a few new ones. The accountant is dismayed to discover that the report you wrote for him still shows the old products, and has not included the new products into the report. This is where your quick solution starts to go south.
Enter the dynamic cross tab
There comes a point when maintaining all of these ‘hard-coded’ cross tabs is more effort than spending some time developing a more generic, permanent solution. The solution I arrived at still essentially uses the CASE function to cross tab the data. The only real difference is that the list of CASE statements is built up dynamically, based on the data that you wish to use to describe the columns.
The stored procedure I created started as a simple dynamic CASE statement builder, using sp_executesql. It immediately became useful and soon people were asking, “How do I get it to do…” questions. Bit by bit, it evolved to the monster it is today. The intention has always been to have a procedure that was so generic and portable, that it could be added to anyone’s database and cross tabs could be created immediately without any further setup or change in SQL code. Although simplicity of use may have suffered a little, I feel that the primary objective has been achieved.
Using the stored procedure
For starters, let’s generate a cross tab result set giving a list of companies in the first column, the name of the contact at the company in the second column and a list of the stocked products from column three onwards. Inside the grid, we’ll give the total value of the orders placed by that company, for that product. It must be sorted by company name.
The SQL query that returns the source data that we require is
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
SELECT cus.CompanyName, cus.ContactName, prod.ProductID, prod.ProductName, det.UnitPrice, det.Quantity FROM Orders ord INNER JOIN [Order Details] det ON det.OrderID = ord.OrderID INNER JOIN Products prod ON prod.ProductID = det.ProductID INNER JOIN Customers cus ON cus.CustomerID = ord.CustomerID And here's how we'll do it: EXEC sys_CrossTab 'Orders ord inner join [Order Details] det on det.OrderID = ord.OrderID inner join Products prod on prod.ProductID = det.ProductID inner join Customers cus on cus.CustomerID = ord.CustomerID', -- @SQLSource 'prod.ProductID', -- @ColFieldID 'prod.ProductName', -- @ColFieldName 'prod.ProductName', -- @ColFieldOrder 'det.UnitPrice * det.Quantity', -- @CalcFieldName 'cus.CompanyName, cus.ContactName', -- @RowFieldNames NULL, -- @TempTableName 'sum', -- @CalcOperation 0, -- @Debug NULL, -- @SourceFilter 0, -- @NumColOrdering 'Total', -- @RowTotals NULL, -- @ColTotals 'CompanyName', -- @OrderBy 'int' -- @CalcFieldType |
The first few rows and columns returned will be
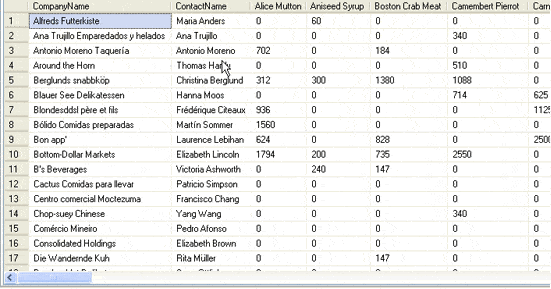
Structure of the stored procedure
If you wish to fine-tune the procedure, make it more efficient, maybe adapt it to your individual needs and cut out some of the functionality you’ll never use, you may be interested in how it was put together. If you’ve ideas of a better way of doing things, then please do share it with all of us. The stored procedure is fairly well documented and you should be able to find your way around the code.
You’ll notice that there are a good few varchar(8000) variable declarations right up front. Very early into the project, I found that varchar(8000) just wasn’t large enough for anything beyond the most trivial query. The only way around this storage problem was to create a range of these variables, and as the first one filled up, I’d start adding information into the next. A range of variables have been declared for each portion of the final query that we are building, namely the CASE statements, the select field list, the totals and so on.
The first order of business is to determine the names of the columns of the cross tab. This will be the first of two queries on your source data. We insert all distinct column names into a memory table (#Columns), in the order that they should appear in the cross tab. If you’ve chosen to show column totals, these will be calculated and stored at this point.
Next, any prefixes from the row fields are stripped out. This is important, as we’ll be grouping by these fields and the aliases, or table references, can complicate the generated query.
I then define a cursor that runs over the items that were inserted into the #Columns memory table. This generates the CASE statements that are used to perform the aggregate functions on the source data. Some work is also done on the generation of the SQL statement portions for row and column totals, as well as the insert statement into the target temporary table, if these options were selected.
Once we’ve built up the bits and pieces, we string them together and run the query. If you look into the stored procedure code, you’ll see that I’ve identified eight different scenarios, based on whether or not we’ve elected to save to a temp table or use row and column totals. The applicable scenario is determined and the final SQL statement is then pieced together appropriately, along with the debug version if debugging was enabled. This will be the second query on your data source.
It would be difficult to describe the stored procedure in more detail than this, without getting terribly long winded about it. However, I do feel that the code is adequately commented and you shouldn’t have too much hassle making modifications should you choose to do so. The best advice I have to offer is to make use of the debugging facility, as you’ll immediately see the effect of your change on the generated SQL code.
The stored procedure parameters, explained
The prototype of the stored procedure is as follows:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
CREATE PROC [dbo].[sys_CrossTab] @SQLSource varchar(8000), @ColFieldID varchar(8000), @ColFieldName varchar(8000), @ColFieldOrder varchar(8000), @CalcFieldName varchar(8000), @RowFieldNames varchar(8000), @TempTableName varchar(200) = null, @CalcOperation varchar(50) = 'sum', @Debug bit = 0, @SourceFilter varchar(8000) = null, @NumColOrdering bit = 0, @RowTotals varchar(100) = null, @ColTotals varchar(100) = null, @OrderBy varchar(8000) = null, @CalcFieldType varchar(100) = 'int' |
My original application didn’t have need of nvarchars, and I really needed the extra storage space, so I decided to use the varchar data type. I would recommend that you alter these to nvarchars if you want code that is culture-safe.
Some detail of the purpose and usage of each parameter is given. If my description is a little too vague for you, have a look at the example script above and the output it generated, or even better, run the script for yourself and experiment with it.
@SQLSource
The first parameter, @SQLSource, is just that; the source of the data you wish to generate the cross tab from. This can be a table name, view name, function name or even the FROM clause of a SELECT statement, as we’ve used in the example. Have another look at the SQL statement I presented, and compare it to the text used for the @SQLSource parameter. It’s basically the portion of the SQL statement from after the FROM keyword, up to but not including the WHERE clause, if one exists. If you wish to use a table, view or function, use just the name and possibly its alias – leave out the SELECT keyword.
@ColFieldID
We need to decide, for each row in the source data, which column to assign the values to. The @ColFieldID parameter is used to select the column to be used for this function. The ProductID field is used in our example. The number of distinct values that this column has in the source data will tell you how many columns will be used in the cross tab. This is an important consideration, especially if you wish to use the results of the cross tab in an Excel spreadsheet, as Excel puts an upper limit on the number of columns that it can handle.
@ColFieldName
Use @ColFieldName to provide the name of the field that will contain the captions for each column of the cross tab. It can be the same field as used for @ColFieldID.
@ColFieldOrder
If you require the columns to be sorted, you can specify a field by which the ordering should occur. The @ColFieldOrder parameter should hold the name of this ordering field. This too can be the same field as @ColFieldID. You might also want to set the @NumColOrdering parameter if the ordering is important. By default, the columns will be sorted alphanumerically. If you require then to be sorted numerically, set @NumColOrdering to 1. The description of that parameter will give a little more detail.
@CalcFieldName
@CalcFieldName should contain the name of the field that will be used to create the data within the cross tab grid. This will be the base data of the count, sum, average or whichever aggregate function you choose. Naturally, you should ensure that the data type of this field matches the operation you wish to perform. You cannot perform a SUM operation on varchar field, although a COUNT operation is perfectly acceptable.
@RowFieldNames
Here you will provide a comma-separated list, consisting of one or more field names, to be used as the first few columns of the grid. The aggregate function that you intend to perform will be carried out as a function of the grouping of the fields you specify here, so choose them wisely.
@TempTableName
Occasionally, the cross tab is not the final result, but a means to an end. Maybe you’d like to perform further queries on the cross tab data generated, or you’d like to join it to other tables. The @TempTableName parameter was added for this reason. It provides a way for the cross tab data to be inserted into a temporary table that you can then use for further processing.
There are a number of caveats here though. Firstly, you’ll need to create the temp table before you call the cross tab stored procedure (because of SQL’s scoping rules). When creating a table, you’ll need to provide at least one column though. The simplest is to do something like
|
1 |
CREATE TABLE #CrossTab (Dummy TINYINT NULL) |
You will then pass in the name of the temp table (#CrossTab in this case) to the stored procedure. Once the cross tab generation has completed, your temp table will contain the cross tab information in addition to your Dummy field. If, like me, you feel that the dummy field is ‘wasted’, you can declare it as an identity field, thereby adding a sequence number to your table.
|
1 |
CREATE TABLE #CrossTab (Sequence INT IDENTITY(1,1)) |
The users of your query are a lot less likely to be perturbed by a sequence number than an empty, useless column at the front of the result set.
@CalcOperation
Here we tell the stored procedure what to do with the source data we’re providing. Acceptable values for this parameter are any of SQL’s aggregate functions, namely AVG, SUM, COUNT, MIN, MAX and their ilk. Make sure that you match the operation to the data type, i.e. no SUMming of varchar data.
@Debug
The @Debug parameter, switched off by default, can be quite handy. When enabled (set to 1), it will print out the SQL code used to generate the cross tab. If you’re not expecting the columns of your cross tab to alter, you can run the SQL printed out by the debugging code instead of using the stored procedure, which will be considerably more efficient. In this way, you can use the stored procedure as a SQL generation tool.
Take note that the row totals will not be calculated by the debug SQL. The stored procedure will ‘hardcode’ the totals that it calculated at the time that it was run.
@SourceFilter
@SourceFilter lets you input some SQL code to filter the source data prior to it been cross tabbed. This would be the code of the WHERE clause to match that of the SELECT clause as given to the @SQLSource parameter. There is no reason why you can’t include a WHERE clause as part of the data given to @SQLSource, although I find it easier and more maintainable to specify it separately.
@NumColOrdering
If you intend for your columns to be arranged in a particular order, you’ll give the field name to order them by to the @ColFieldOrder parameter, and you’ll use the @NumColOrdering field to specify how the ordering is to take place. A value of 0 (the default) will cause the data to be sorted alphanumerically, and a value of 1 will sort in numerically.
If you’re not sure about the difference between the two, consider the following list: 2, 1, 10, 11, 20, 100. When this is sorted numerically, it will be 1, 2, 10, 11, 20, 100. However, sorting it alphanumerically will result in 1, 10, 100, 11, 2, 20. Naturally, alphanumeric sorting will also handle A’s, B’s and C’s, whereas numeric sorting will cause a type mismatch error to be raised.
@RowTotals
If this parameter is set to something other than NULL, an additional column will be added as the final column of the result set (the column name being the value given here), and will contain the sum of the cross tab values for each row.
@ColTotals
If set to something other than NULL, an additional row will be added as the final row of the result set, and will contain the sum of the cross tab values for the each column. There are a number of things to look out for with this one though. Firstly, you’ll need to pass the field names already wrapped in quotes into the parameter. For example, if you wish the line to be marked as Total, you’ll need to set @ColTotals to ”’Total”’. Secondly, you’ll need to provide as many values as fields that you’ve specified in the @RowFieldNames parameter. In our example, we’ve used two fields, so we need to provide two values to @ColTotals. Lastly, this total row may not necessarily appear at the bottom of the result set, depending on whether you’ve given an @OrderBy parameter value. The totals are added prior to the cross tab being sorted.
If you’ve enabled the debug printing option, the SQL code given to you will also not calculate the column totals dynamically. The totals will have been determined during the initial execution of the stored procedure, and these fixed values are then joined onto the rest of the result set.
@OrderBy
The @OrderBy parameter allows you to provide an ORDER BY clause. If used, this must be one or more of the fields used in the @RowFieldnames parameter. If you’re using @ColTotals, keep in mind that the column totals row will be considered part of the cross tab data, and will be ordered along with the other rows.
@CalcFieldType
The data type of the calculated fields in the cross tab grid can be specified by the @CalcFieldType parameter. This will be INT types by default. Set the type to one that is appropriate for the type of operation being performed, and the type of data you expect to see in the cross tab.
The challenge!
If you’re going to try the stored procedure out, you may as well get something for your effort. The Simple-Talk editor, Tony Davis, has kindly offered to sponsor a prize for the first three correct responses to the challenge. It is also based on the Northwind database, and you’ll need to do the following:
Compile a cross tab report that displays the order value by customer, by quarter. You should also group the clients by the country in which they are based. Sort the list by country, and then by company name. Show both row and column totals, to appear at the right and bottom of the report respectively. I’ve included a screen shot so that you can see what the report should look like.
Post the source code for your solution in the comments to this article, (or send it to Tony at editor@simple-talk.com).
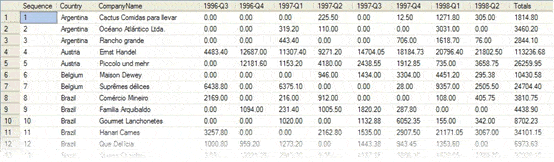
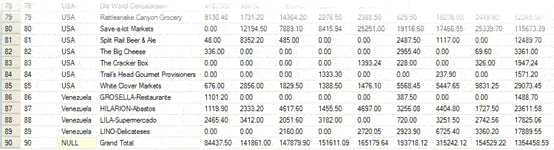
In conclusion
You’ll find that once you’ve done one cross tab, you’ve pretty much done them all. The greatest difficulty is in actually deciding what you want displayed, and then collecting the source data for the stored procedure. The actual generation of the cross tab is then simply a matter of matching the field names to the input parameters.
I hope that you’ll find this stored procedure as helpful as I have – it’s one of the more valuable items in my toolbox. If you discover some novel use for it, or a new idea on how to improve it a little, please share it with us. I for one would be interested to hear about it.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments