
Alex Kuznetsov is the creator of a clever technique for creating a history table that I’ll be describing in this article. It solves a common problem with declarative referential integrity constraints and needs to be known more widely, especially now that we have a DATE data type in SQL Server.
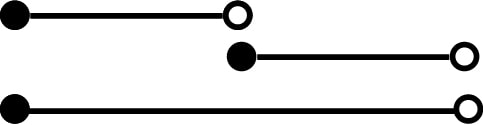
History tables reflect the nature of time in the ISO model. That is, time is a continuum and not a set of discrete points. Continua have an infinite number of elements, but subsets can be bounded. To show a duration in SQL, we store the starting point in time of a duration and the limit the duration with an end point that is not actually in the duration. This is called a half-open interval as we usually draw as a line with a solid dot on the starting point and an open dot on the end.
Half-open intervals have nice properties. You can subtract a half-open interval from the middle of another half-open interval and you get half-open intervals as a result. You can also abut half-open intervals and get a new half-open interval. That means I can chain them together and not worry about having a duplicated or missing point in a time-line.
In particular, we really like to have contiguous time periods in a history table. We would also prefer that this constraint be enforced with declarative instead of using procedural code in triggers, functions or procedures. Let’s go right to a example and discuss the code. We are going to create a table of some kind of vague Tasks that are done one right after the other, without gaps or overlaps.
Abutting half-open intervals yield a new half-open interval:
It is worth mentioning that the new DATE data type is only 3 bytes, so reading it off a disk is cheap. You will see why this is important.
A Note on Temporal and Floating Point Data
I mentioned that time is a continuum. The real numbers are also a continuum, which we model with floating point numbers in computers. Technically, there is a difference between REAL and FLOAT in Standard SQL, but nobody cares. The reason that nobody cares is that the IEEE 754 Standard is burned into chips and universally understood.
Floating point math is fuzzy and has learned to live with its imprecision. When you compare two floats for equality, the software knows about an “epsilon” — a small wiggle factor. The numbers are treated as equal if they differ by that epsilon; or less.
Temporal data in T-SQL used to be a prisoner of UNIX system clock ticks and could only go to three decimal seconds with rounding errors. The new ANSI/ISO data types can go to seven decimal seconds, have a true DATE and TIME data types. Since they are new, most programmers are not using them yet.
One of the idioms of T-SQL dialect has been to get just the date out of a DATETIME column. The traditional solution in the Sybase days was casting the column to FLOAT, taking a FLOOR() or CEILING() then casting it back. This depended on the internal representation of the DATETIME values. The rounding error was why T-SQL could not represent some times accurately. Here is the code for the date at zero hour.
|
1 |
CAST(FLOOR(CAST(@in_date AS FLOAT)) AS DATETIME) |
To get the following day, we used:
|
1 |
CAST (CEILING(CAST(@in_date AS FLOAT)) AS DATETIME) |
The reason was simple; a lot of UNIX machines had floating point hardware. Today the equally awful idiom is
|
1 |
DATEADD(DD, DATEDIFF(DD, 0, @in_date),0) |
This leaves a DATETIME with a time of zero hour. Today you can simply write “CAST (my_date_column AS DATE)” which is a lot easier to read and maintain. It also gives you a real date.
Likewise, “CAST (my_date_column AS TIME)” will return just the time fields (yes, the ANSI Standards calls them fields to make sure your do not confuse them with columns or substrings).
Rounding DATETIME and DATETIME2 columns is done the same way. This gives you the ability to do the temporal version of the floating point epsilon. Insert the data with a high precision, but compare it at a courser precision. Here is a quick example to play with.
|
1 2 3 4 5 |
SELECT CAST ('2010-10-26 12:12:12.8888888' AS DATETIME2(5)), -- nanoseconds CAST ('2010-10-26 12:12:12.8888888' AS DATETIME2(3)), CAST ('2010-10-26 12:12:12.8888888' AS DATETIME2(1)), CAST ('2010-10-26 12:12:12.8888888' AS DATETIME2(0)); -- whole seconds |
First Attempt: Single Time Table
Here is the DDL for the usual attempt that the less-experienced SQL Server developers often make to record a history in a table. I am assuming that we measure time in days and not have to worry about minutes or fractional seconds.
|
1 2 3 4 5 6 |
CREATE TABLE Tasks (task_id INTEGER NOT NULL, task_score CHAR(1) NOT NULL, task_start_date DATE DEFAULT CURRENT_TIMESTAMP NOT NULL, PRIMARY KEY (task_id, task_start_date), etc); |
The table has the starting date of the events and nothing else. The assumption is that the implicit task_end_date is the next task_start_time in temporal sequence. You can see the problems immediately. In order to compute simple durations, you need to use a self-join, which probably ought to be in a VIEW.
|
1 2 3 4 5 6 7 8 9 10 |
CREATE VIEW ContigousTasks (task_id, task_score, task_start_date, task_end_date) AS SELECT T1.task_id, MAX(T1.task_score), T1.task_start_date, DATEADD (DD, -1, MIN(T2.task_start_date)) FROM Tasks AS T1 LEFT OUTER JOIN Tasks AS T2 ON T1.task_id = T2.task_id AND T1.task_start_date < T2.task_start_date GROUP BY T1.task_id, T1.task_start_date; |
Here is some test data to play with:
|
1 2 3 4 5 6 |
INSERT INTO Tasks (task_id, task_score, task_start_date) VALUES(1, 'A', '2010-11-01'), (1, 'B', '2010-11-05'), (1, 'C', '2010-11-10'), (1, 'D', '2010-11-15'), (1, 'E', '2010-11-20'); |
The LEFT OUTER JOIN gives a NULL for the last row’s task_end_date. But a self-join becomes expensive as a table get bigger and bigger. Computing date math is also expensive. More than that, gaps are undetectable and create false data. Likewise overlaps are hidden. A row is supposed to model a complete fact. These rows have only half a fact . You will be doing this self join constantly to re-assemble what is split apart.
A clustered index on (task_id, task_start_time) will help, but you still have to do computations and grouping.
Second Attempt: Simple History Table
Here is the DDL for a classic History table. I am assuming that we measure time in days and not have to worry about minutes or fractional seconds.
|
1 2 3 4 5 6 7 8 |
CREATE TABLE Tasks (task_id INTEGER NOT NULL, task_score CHAR(1) NOT NULL, task_start_date DATE DEFAULT CURRENT_TIMESTAMP NOT NULL, task_end_date DATE, -- null means unfinished current task CONSTRAINT end_and_start_dates_in_sequence CHECK (task_start_date <= task_end_date), PRIMARY KEY (task_id, task_start_date), etc); |
The half-open interval model requires that we know the starting time of an event. The ending time cannot be known if the event it still in process, so it is NULL-able. There is a simple CHECK() constraint to assure that the two dates are in order: But nothing prevents gaps or overlaps.
Even worse, we can have multiple NULL task_end_date rows. What we want is that each task has at most one NULL task_end_date. In Standard SQL, this can be forced with a CREATE ASSERTION statement. But in SQL Server, we can use a TRIGGER or a WITH CHECK OPTION than allow access to the table only thru VIEWs.
|
1 2 3 4 5 6 7 8 9 |
CREATE VIEW SafeTasks (task_id, task_score, task_start_date, task_end_date) AS SELECT task_id, task_score, task_start_date, task_end_date FROM Tasks WHERE 1 <= ALL (SELECT COUNT(*) FROM Tasks WHERE task_end_date IS NULL GROUP BY task_id) WITH CHECK OPTION; |
A lot of SQL programmers do not know about the WITH CHECK OPTION, but combined with the INSTEAD OF trigger, you can do a lot of complex programming in a single block of DDL.
Kuznetsov’s History Table
Kuznetsov’s History Table gets around the weaknesses of the simple history table schema. It builds a temporal chain from the current row to the previous row. This is easier to show with code:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
CREATE TABLE Tasks (task_id INTEGER NOT NULL, task_score CHAR(1) NOT NULL, previous_end_date DATE, -- null means first task current_start_date DATE DEFAULT CURRENT_TIMESTAMP NOT NULL, CONSTRAINT previous_end_date_and_current_start_in_sequence CHECK (prev_end_date <= current_start_date), current_end_date DATE, -- null means unfinished current task CONSTRAINT current_start_and_end_dates_in_sequence CHECK (current_start_date <= current_end_date), CONSTRAINT end_dates_in_sequence CHECK (previous_end_date <> current_end_date) PRIMARY KEY (task_id, current_start_date), UNIQUE (task_id, previous_end_date), -- null first task UNIQUE (task_id, current_end_date), -- one null current task FOREIGN KEY (task_id, previous_end_date) -- self-reference REFERENCES Tasks (task_id, current_end_date)); |
Well, that looks complicated! Let’s look at it column by column. Task_id explains itself. The previous_end_date will not have a value for the first task in the chain, so it is NULL-able. The current_start_date and current_end_date are the same data elements, temporal sequence and PRIMARY KEY constraints we had in the simple history table schema.
The two UNIQUE constraints will allow one NULL in their pairs of columns and prevent duplicates. Remember that UNIQUE is not like PRIMARY KEY, which implies UNIQUE NOT NULL.
Finally, the FOREIGN KEY is the real trick. Obviously, the previous task has to end when the current task started for them to abut., so there is another constraint. This constraint is a self-reference that makes sure this is true. Modifying data in this type of table is easy, but requires some thought.. Fortunately, Alex has written a Simple Talk article to explain in more detail how it is done.
Disabling Constraints
Just one little problem with that FOREIGN KEY constraint. It will not let you put the first task into the table. There is nothing for the constraint to reference. In Standard SQL, we can declare constraints to be DEFERABLE with some other options. The idea is that you can turn a constraint ON or OFF during a session so the database can be in state that would otherwise be illegal. But at the end of the session all constraints have to be TRUE. or UNKNOWN.
In SQL Server, you can disable constraints and then turn them back on. It actually is restricted to disabling FOREIGN KEY constraint, and CHECK constraints. PRIMARY KEY, UNIQUE, and DEFAULT constraints are always enforced. The syntax for this is part of the ALTER TABLE statement. The syntax is simple:
|
1 |
ALTER TABLE <table name> NOCHECK CONSTRAINT [<constraint name> | ALL]; |
This is why you want to name the constraints; without user given names, you have to look up what the system gave you and they are always long and messy.. The ALL option will disable all of the constraints in the entire schema. Be careful with it.
To re-enable, the syntax is similar and explains itself:
|
1 |
ALTER TABLE <table name> CHECK CONSTRAINT [<constraint name> | ALL]; |
When a disabled constraint is re-enabled, the database does not check to ensure any of the existing data meets the constraints. So for this table, The body of a procedure to get things started would look like this:
|
1 2 3 4 5 6 |
BEGIN ALTER TABLE Tasks NOCHECK CONSTRAINT ALL; INSERT INTO Tasks (task_id, task_score, current_start_date, current_end_date, previous_end_date) VALUES (1, 'A', '2010-11-01', '2010-11-03', NULL); ALTER TABLE Tasks CHECK CONSTRAINT ALL; END; |
You will want to confirm that the constraints are all working by trying to add bad data.
- There is only one first event per task. A UNIQUE will take care of that.
- There are no duplicates allowed.
- No events overlap in a task.
- There are no gaps allowed
Conclusion
You can avoid procedural code, but it is not always immediately obvious how. Start with a list of constraints and some test data. The use of the (current_start_date , current_end_date) has been the standard idiom for history tables in SQL. Until we got the DATE data type, the use of a BETWEEN predicate was a problem. The rounding errors that occurred in the fractional seconds could cause overlaps in the old DATETIME data type. The solution was to write two predicates:
|
1 2 |
(my_time >= current_start_date AND my_time < COALESCE (current_end_date, CURRENT_TIMESTAMP)) |
It works, but it hides the BETWEEN-ness of the three-way relationship, With the new DATE data type, the BETWEEN works just fine.
The previous_end_date column feels strange at first. It seems redundant. But I will argue that it is not. A row in a table should model a complete fact. That is why we have (current_start_date , current_end_date) pairs; together, they tell us about the duration of the task as a whole thing; there is no need to read another row to find the ending date.
A Quick Note on Induction
Since one of the business rules is that we do not allow gaps, we need to have data for determining that. If I depended on the previous row to provide the previous_end_date, I would need self-joins or loops that eventually go back to the first event in the sequence of tasks. In short, it would be a lot of procedural code in a trigger. But I have a nice mathematical property to use: induction.
With the constraints, I can prove that I have no gaps using induction. t his done by proving that the first statement in the infinite sequence of statements is true, and then proving that if any one statement in the infinite sequence of statements is true, then so is the next one. If the idea of math bothers you, think about a chain of (n) dominoes set up for toppling. If I push one domino over, it topples. That is my starting point or induction basis. Assume that if I push any single domino over in the chain, then his neighbor also falls. That is the inductive hypothesis. So when I push the first domino in the chain, all of them fall down.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved






Load comments