
SSIS Package Componentization: One Package to Rule Them All!
By David Leibowitz
Setting Expectations
First let me be clear, this is not a beginners primer to SSIS (SQL Server Integration Services). We will assume that you have some experience, however slight, with SSIS. For some good primers, check out SQL Books Online, the samples included with your SQL Server 2005 installation and Microsoft TechNet. A particularly good starting point can be found on TechNet in a tutorial series, “Creating a Simple ETL Package Tutorial” (http://msdn2.microsoft.com/en-us/library/ms169917.aspx).
In this article I will take some leaps forward and introduce some steps to create more scalable packages. But that first relies on a definition of SSIS scalability. To understand this, think about object oriented programming or distributed SQL development. And if you’re not a developer at all, think about a warm happy place while I take this short journey into an architecture discussion.
If you were creating a thick client .NET application, would you stuff all of your code into one master function called RunItAll()? How about mashing together unrelated subroutines into a single 2000 line T-SQL stored procedure? As you mature in your development experience I’ll bet you separate code functionality into manageable chunks of views, stored procedures and triggers. There are several reasons for this:
- Code Manageability:
- It’s easier to find those needles in the haystack
- Code Reuse:
- You can use those stored procedures from thick client, thin, or call from a Web Service
- Business Logic Separation:
- You know, the whole n-tier paradigm to separate presentation layers from business logic, unless you want to go back to RPG or gasp, Classic ASP development.
So what does this have to do with SSIS? Simply put, the visual development environment allows you to be a fairly sloppy coder placing entirely too much logic in a single package. “Hello World” examples aside, you really don’t want monster sized packages holding all of your extractions, transformations and loading procedures. We’ll explore a sample SSIS package included in SQL Server 2005 that clearly illustrates just how unmanageable ETLs can become.
Aside from the sloppiness, you’ll find that the difficulty level of development increases (and your patience decreases) in direct relationship to the growth of your packages in the Visual Studio 2005 UI. This happens because control rendering takes longer and longer while the design time environment reevaluates your every movement.
These considerations are especially important in the ETL framework because the various components that you depend upon can, and will, change over time. The source of your extract can certainly change; the business logic to process that information might need to adapt, as well as your final data destination.
AdventureWorks as an Argument for Package Componentization
Let’s look at the simple AdventureWorks example. We extract data from some datasets, and populate a data warehouse. A rudimentary flow is represented in Figure 1. This follows lots of sample logic and plenty of packages I have seen in time. Load all of the data objects from a single source, perform some “ETL Magic” and deposit to a destination. This seems simple enough, so let’s add some complexity.
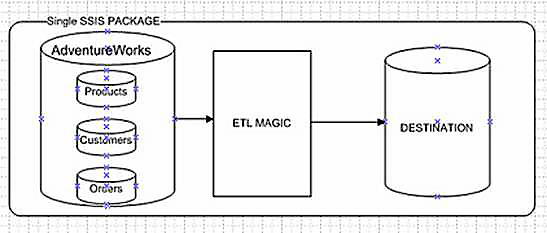
Figure 1
In this new fictional environment, AdventureWorks is just one of several divisions owned by AW, which is based in the United States. They also manage AventureWorks UK and AdventureWorks Canada. Our goal is to create a consolidated view for executive management, or an enterprise data warehouse.
We can imagine that each division is running the same application software, but that would be a real-world fairy tale. So, in order to make the example seem more real, AW USA runs the Microsoft ERP version 2.0, UK runs 2.0 with service pack 2 and Canada runs version 1.0.
Sure, you’re thinking…what’s the big deal? We can still follow the method shown in Figure 1, right? I know we can have multiple sources in a single package, Microsoft Dynamics, SAP, Lawson, CRM and load them all up at once, you’ve most likely seen demo’s that illustrate this point. An example of a single package process for that example is displayed in Figure 2.
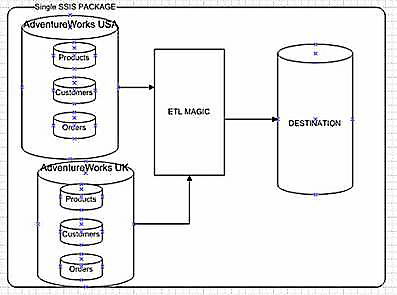
Figure 2
But proof of concept isn’t always prudent in the real world. Here’s something to consider in componentized development: What about splitting units of work to appropriate subject matter experts (or SMEs)? By distributing the extraction portion of this program we could allow the DBAs at each satellite office to write the appropriate SQL extraction (SELECT) code, while we focus on the business logic of the integration, or transformation to corporate business rules.
One other reason should stand out in this example. Our multinational organization spans the globe and time zones. Typically, an ETL process would be scheduled for off-hours and you’ll note that this would be impossible if all extracts were placed in a single package. Our colleagues in the UK might note some serious system degradation if we imported all data based on a Los Angeles clock.
Moving along to the business tier, corporate management might need us to perform some algorithms on the data prior to import to our data warehouse. Since corporate is a fussy bunch, we know we’ll need to change things like goals, forecasts, exchange rates, you name it…routinely as business needs dictate.
Lastly, many businesses grow via acquisition and it would be a dream to hope that each new company was using the same back-end application software. If AdventureWorks decides to purchase Northwind in the future, we’ll need to incorporate their data as well. The way corporate requires us to apply business logic might not really change, but we’ll be saving ourselves a considerable amount of effort by only requiring an extract from the Northwind database to our corporate format, having already segmented the universally adapted corporate business rules.
From Philosophy to Practice – Package Componentization
Fundamentally, the method to achieve this is something I call package componentization, as it is not unlike the componentizing of reusable code modules in .net development. In this method we will split the ETL into two main packages: an Extract and Business Logic Insert. A high level workflow is displayed in Figure 3. Imagine a 2-pair set for each data object required for the application, so this might expand to Customers, Purchase Orders, Geography and so on.
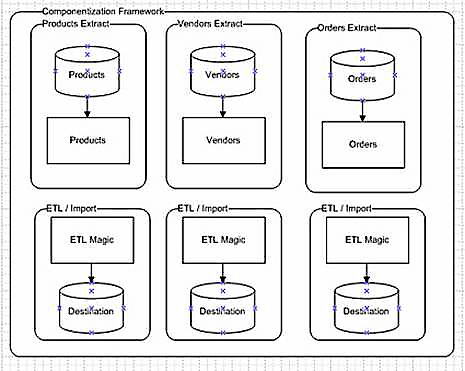
Figure 3
Conceptually, the process is evolving to a more object oriented approach. The benefits are seen in the next logical breakdown as illustrated in Figure 4. You’ll note that if more than one company runs the same source application (even if the server and/or credentials differ), we can reuse that entire package. For example, if the differences between AdventureWorks version 2 and SP2 meant no difference in the table layout, there would be no reason to create a brand new extract (or even copy/paste) for our satellite organizations. Componentization is starting to pay off. Further, as all extracts will all conform to the same canonical layout, we will only need one Business Logic Insert.
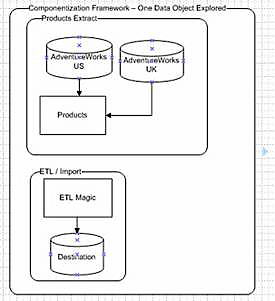
Figure 4
In comparison to this smaller workload, take a look at the sample package provided by Microsoft in Figure 5, if you have your magnifying glass handy. You can find this if you’ve installed the Samples for SQL Server 2005. This package will be saved by default in C:\Program Files\Microsoft SQL Server\90\Samples\Integration Services\Package Samples\AWDataWarehouseRefresh.
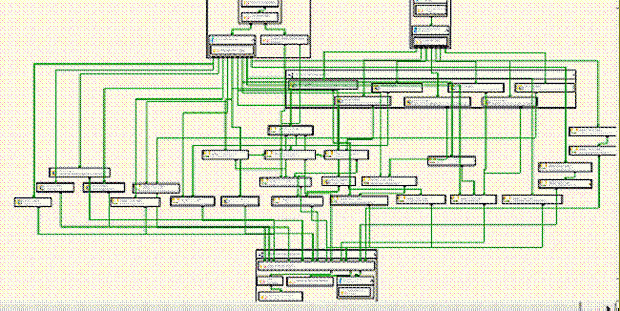
Figure 5
Look at the size of it! An import is shown for every single data object. Understandably, this is merely a proof of concept as provided in a Sample kit from Microsoft. For true componentization, we’d partition each distinct data load into a separate file. So Extract-AW USA would really be broken down into smaller separate files for Products, Vendors, Customers, Sales Reps and Sales Invoices.
That’s right, we’ll componentize those data objects as well. In larger distributed development environments you’ll find that different SMEs cover specific areas of responsibility. One well versed in the General Ledger tables might not be the same as the resource needed for the Materials Ordering extract. Again, we could include every single data object in a single package, but that would run counter to the principles of scalable and distributed application design. A change in one Data Flow component requires modification, and testing of the entire ETL package. Also importantly, you’ll find it much easier to debug individual components should one extract fail.
In effect, we are not only creating separate units of functionality; we are also creating distinct dependencies. For example, we’ll only load the ‘Products’, should the extract of ‘Products’ successfully occur. Taking this to the next obvious level, we might create logical dependencies between objects. For example, ‘Customer Ship To Locations ‘would only be loaded after first importing ‘Customers’ and their associated attributes. ‘Sales Invoices’ might only be loaded after a successful import of ‘Products’.
To manage this scalability and the ability to create custom dependencies, we wrap the entire process into a single manager – or as I like to call it, “one package to rule them all.” We could call this a “Precious Package,” but if that name has too much of the ‘Ring Trilogy geek’ about it for you, we can simply call it a “package broker.” By using this component based strategy, and a table based import system you can implement your own process control, error handling and even manage the complexities of development versus production environment testing without touching your packages.
Setting the Stage
We’ll put these concepts into practice in the following example by creating 3 packages. The first, an extract of Products from AdventureWorks, the second, our business logic tier and insert, and lastly our package broker to control their execution. Let’s assume that we need to consolidate the AdventureWorks databases from 3 satellite offices. They all run the same version, and are running SQL Server.
Quick Solution Setup Cheat Sheet
1. Copy the sample solution to c:\Temp (if you don’t copy the files here, you’ll need to change the references to the individual DTSX file paths in the OBJECT_PROCESS table)
2. In SQL Server Management Studio, execute the SQL script included in the download on the master database to create the sample database, and sample records.
3. Ensure that AdventureWorks (for SQL Server 2005) is on your database server
4. Modify the ConnectionString in the OBJECT_CONNECTIONS table if you can’t use integrated security on the AdventureWorks table
5. Open the Visual Studio Solution and execute the PackageBroker package
If you’d like to create this on your own, or simply follow along, use the script in the download package (PackageBroker-Setup.sql) to create a few tables, and add some data. The key tables are Company, Data_Object, ETL_Workflow, Object_Connections and DimProduct.
Company will hold reference to various company databases we might want to import. Data_Object will hold reference to the entities we might import, such as Product, Customers, Vendors or Sales. ETL_Workflow holds the sequence of events for each package load as well as the filepath to the associated DTSX files. As mentioned earlier, these are defaulted to your local C:\Temp directory but you can feel free to move those files anywhere. Just be sure to update the file pointer in this table.
Object_Connections will hold connection strings for each company/object. In this example, we’ll store the database connection strings to our source databases within a table and for simplicity, we’ll add the credentials needed. In your environment, you’ll probably use either Integrated Security (assuming the account SSIS uses has access to the source database), encrypt the data, or use another secure method.
With a table based approach you can easily promote changes between test environment s and production with a simple change to the appropriate record. In this scalable design you’ll note that the company table has been separated from the data objects. This allows you to provide different database connections and credentials for each object, should those entities exist on different source systems (or accessed with different security).
Lastly, DimProduct is our sample data warehouse dimension object. We’ll load this table with some sample data from AdventureWorks to simulate one pass through our componentization framework.
Creating the Package Broker
The first package we’ll tackle is the package broker. This will select a data object to import, and using package variables, control the child SSIS files to import our data. To begin, create a new SSIS project in BIDS, and name the default package PackageBroker as noted in Figure 6.
Figure 6
SSIS is a great visual environment for ETL work, but it’s possible to leave nuggets of business logic in all sorts of nooks and crannies (in property forms, in code, stored procedures, dynamic expressions, etc.) In the interest of sanity I have limited the complexity of these packages and simply embedded SQL in property forms so you’ll be able to better follow along with the downloaded package. In reality, you’ll use stored procedures and expressions where it makes sense.
You’ll notice the workflow in Figure 7 below.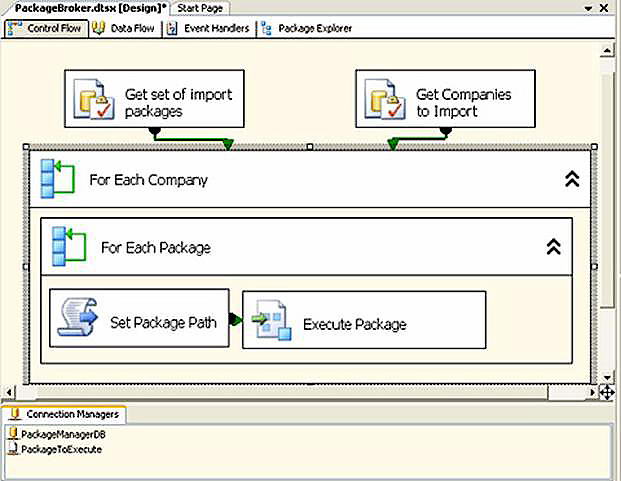
Figure 7
It doesn’t look like much, but the loops and variables will be able to control any packages thrown its way. Let’s break down the salient points of PackageBroker:
| Connection Managers | |
PackageManagerDB |
Connects to our control tables for package workflow |
| PackageToExecute | A placeholder connection to an SSIS package. Dynamically, the properties of this connection manager will change so it can run any valid dtsx |
Variables |
|
| BOKey | The Data Key we insert will instruct this package to run the appropriate workflow (ie. 1 for Products, 2 for Sales Reps, etc.) |
| PackageManagerCS | The connection string for the PackageBroker database. We can store that here or pass in as an input parameter. |
| CompanySet & PackagesToRun | These variables, of type System.Object are actually ADO.NET recordsets that will hold the return values of our initializing stored procedures. Once the results are captured in these sets, we can loop through them…which is a good thing, since we have a couple of For Each loops in our package! |
| All Others | Most of the labels (like data object description) are redundant, but are useful for debugging purposes and logging. |
As noted above, we make use of a special variable type called System.Object. This can hold any type of value, but you will mostly use it to store the results of a query as an ADO.NET Recordset. To illustrate this, take a peek at one of the first script components in Figure 8.
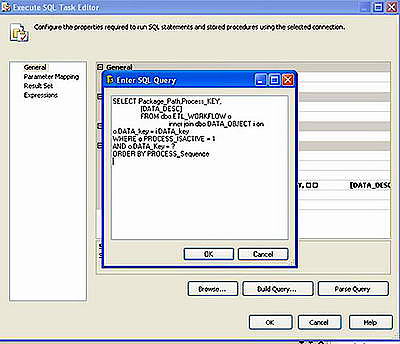
Figure 8
The T-SQL is merely looking for a set of “active” tasks for the selected data object key. Active flags (like the one we placed in the table) are extremely useful, because they allow you to easily test various tasks and scenarios with the flip of a switch in your table. Perhaps you’ve nailed the extract component of your workflow, and only need to test the import: simply change the Boolean on your table and run your import again.
On the Parameter Mapping tab, the BOKey variable is mapped to the (?) input parameter for dynamic execution. Lastly, the Result Set is mapped to the variable PackagesToRun, which is a dataset that holds the PackagePath to the dtsx files to run. The Order By in the T-SQL orders the workflow in appropriate sequence, so we run an extract of data prior to the actual transform and import.
The second script holds similar logic, but as you’ll see it merely requests a list of valid Companies. An active flag also exists (and you’ll see that I only made the first company active), which again, helps in development and testing of additional company imports.
The following pseudo-code illustrates the double looping action:
1. Loop through each ‘active’ Company
a. Loop through each ‘active’ package in our set
For each Company / Package do:
i. Assign the Package Path to our PackageToExecute connection manager
ii. Execute that SSIS Package
If we examine one of the ForEach Loops (Figure 9), you’ll see how we can use the package variable CompanySet as an ADO.NET recordset. Under the Variable Mappings tab, we assign any fields of interest (here, Company_Key) to package variables. We’ll then be able to use these variables in the scope of our scripts in the containers within the ForEach Loop container.
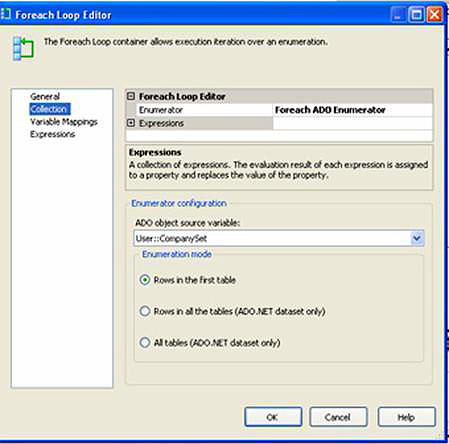
Figure 9
Finally, the assignment in the “Set Package Path” step dynamically assigns the dtsx file to run. The VB.NET code snippet embedded is shown below:
Public Sub Main()
Dts.Connections(“PackageToExecute”).ConnectionString=
Dts.Variables(“User::PackagePath”).Value.ToString
Dts.TaskResult = Dts.Results.Success
End Sub
The next step executes the package and will continue on its loop for as many companies/packages it has to run (assuming fatal errors aren’t encountered).
Create the Extract Package
As stated earlier, our simulation will extract Product data and insert into our sample data warehouse table. Use this method to extend to any additional tables you’d like to add.
To the project, select File -> Add Project and create an entry for Products. Then create two files; one for the extract and the other for the ETL/import. Your solution should look like Figure 10.
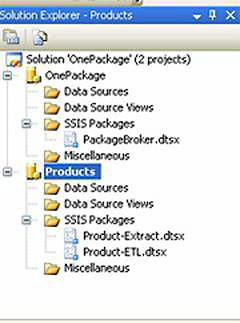
Figure 10
In the Product extract, we’ll use Package Configurations (as pictured in Figure 11) to “reach” into the parent package (the broker) in order to access some variables we’ll need: Company, ConnectionString to the PackageManager Database, and the data object key. You can reach this form by right-clicking on any empty area on the Control Flow tab and selecting Package Configurations. Technically, we know the data object key for this package, since there is but one Product load, but this information is useful if we want to add logging, or if this package gets kicked off from an entirely different process other than our broker. And why not, it’s a component now isn’t it? I’ll elaborate on this powerful feature in a future article on advanced scalability with SSIS.
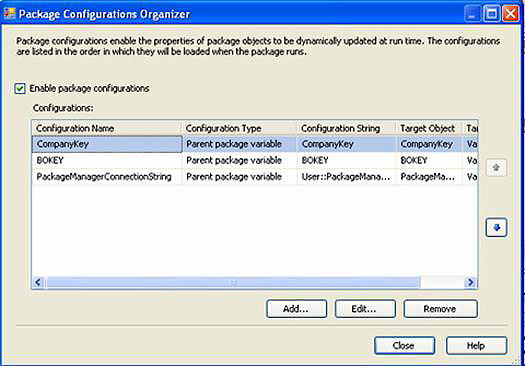
Figure 11
The rest of the package is fairly simple and looks like Figure 12.
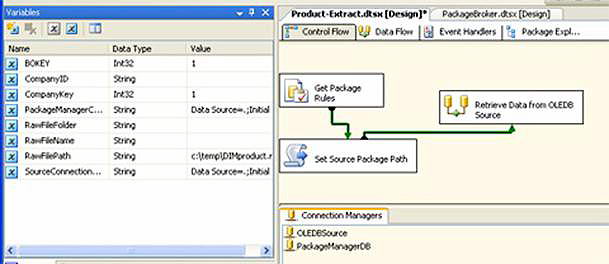
Figure 12
The control flow uses the Package Configuration variables, and a single SQL statement to capture the rest of the goodies we’ll need to connect to our source. The Connection Managers OLEDBSource (for our source SQL database) andPackageManagerDB are empty containers at design-time. At run-time, the ConnectionStrings will be set dynamically.
In “Get Package Rules,” we select the appropriate source ConnectionString for this data object and the selected company. We also create a rudimentary path to a RAW file. All of these values will be stuffed into package variables (Figure 13)
RAW files are the preferred method of moving data between packages. Since the work of source extraction and rules processing is being split, we need a vehicle to act as a middle-man while we hop from package to package. RAW files are a proprietary SSIS data store and performance is extremely fast. By default, we’ll be pointing to the C:\Temp directory. You can use any folder accessible, and you can also make it dynamic.
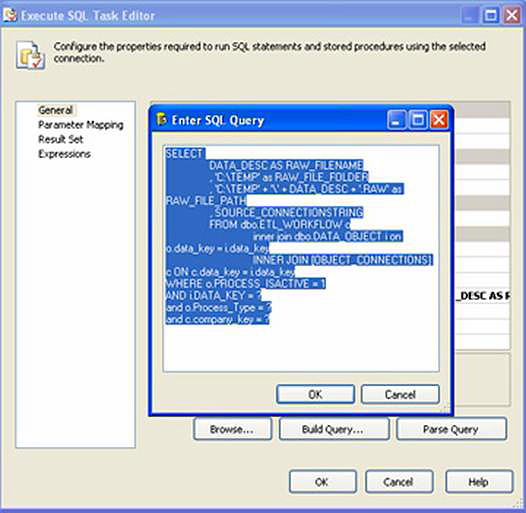
Figure 13
The next Control Flow step sets the ConnectionString on the OLEDB Source so a connection will be possible (Figure 14).
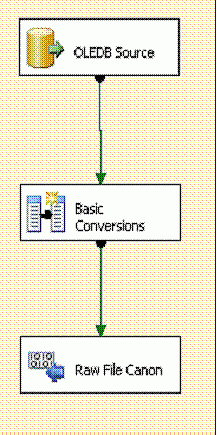
Figure 14
The intent here is to select from our source, perform some simple conversions into a canonical format (our universal input standard), and push to a raw file. This canonical format is the generalized data structure that is required for our data warehouse. In this step you might have some simple data conversions, text parsing, or appending necessary data that is not found in the original source. As this scenario assumes a consolidation of data into a data warehouse, we’ll need to store an additional component of uniqueness not found in the AdventureWorks database: a company key. As you’ll note in Figure 15, this is provided to the data stream from the package variable @User::CompanyKey.
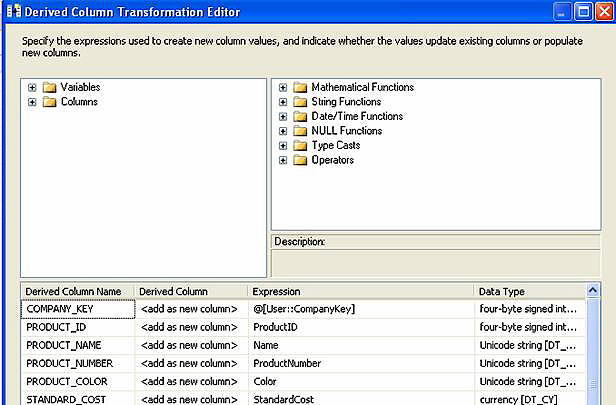
Figure 15
The very last step gets the output folder path from another package variable and outputs the data stream, to be picked up from our next package. Which brings us to…
Create the ETL Package
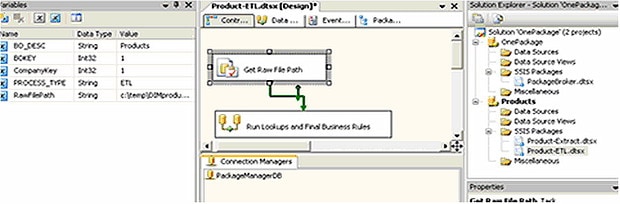
Figure 16
In SSIS, add a new package and rename it Product-ETL. Since this package will be using the previously created RAW File, only a Connection Manager to the Package Broker database is required. Again, we’ll use the same Package Configuration variables to “reach” into the parent for the connection string and data object. Finally, take note of the variables that we are using and you’ll see the Process_Type has changed to ETL (Figure 16).
The first Control Flow step is similar to the one found in the extract package; it merely gets the folder path to the RAW file. Once that it stored in the package variable, we move on to the Data Flow, as pictured in Figure 17.
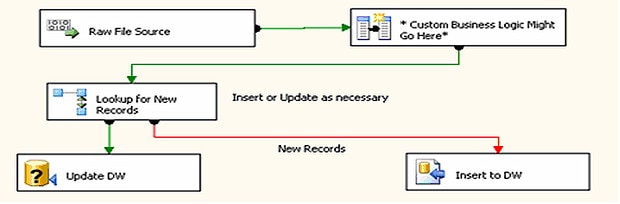
Figure 17
The Raw File Source gets its source from the value in our newly stored package variable. The Derived Columns do nothing here, but illustrate where you might add some generic business logic to apply to all Product data loads.
The next juncture determines if we should add (new) records, or update (existing) records. This is a fairly simple process that checks for the existence of a DimProduct record based upon a unique key of Company Key and Product ID (Figure 18).
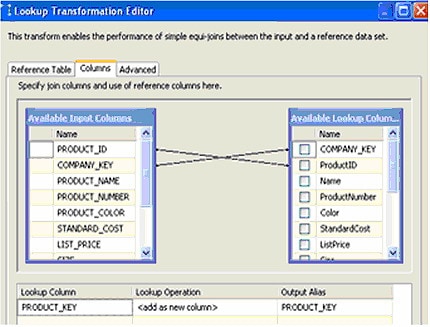
Figure 18
If a match is found, PRODUCT_KEY is populated and the Update DW stored procedure is run. If no match is found, the record is new and we add it to the data warehouse. Again, this is a fairly simple example. You could expand on this by testing to see if an existing record has changed. Knowing this could significantly limit the updates required on existing records, thus reducing process time and resources.
Figure 19 shows the Update Stored Procedure mapping:
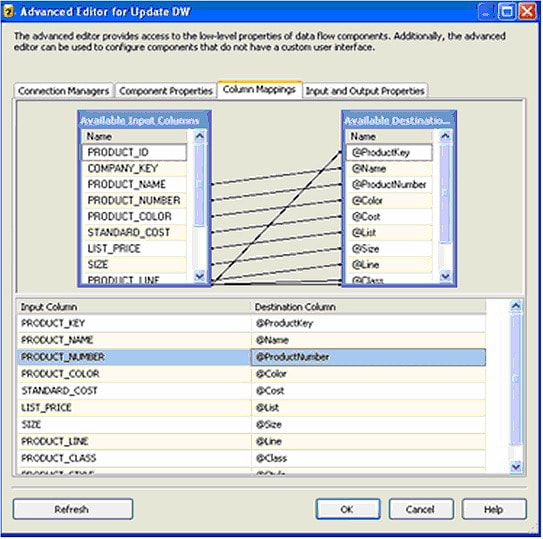
Figure 19
You’ll notice that the Insert Data Flow component is similar, but we ignore the Product_Key, as that will be created by the insert automatically.
Moment of Truth
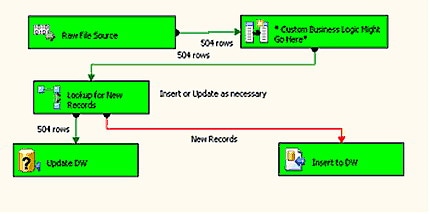
Save and close the Package, and then open the PackageBroker. With the BO_DESC and Key set to Products and 1, respectively, run the package. It will find the appropriate companies and packages to loop through, execute the Extract dtsx package, then execute the ETL and execute to insert several hundred Products. By default, the sample code has disabled all companies but one, and all data objects except Products. Feel free to add more packages and databases with the appropriate ConnectionString modifications.
Next, rerun the package and you’ll notice the package end on the update process as seen in Figure 11.
Closing the Loop
In the end, we could enable our other fictional companies by setting the flag on our database to loop through their imports using the same exact packages! If you have more than one instance of SQL Server with AdventureWorks, give this a whirl. We could also create a single extract for a newly acquired company (Northwind) on another platform and merely create a single output RAW file that matches this one. By ensuring the output is exactly the same as our defined cannon we can then apply our universal business rules.
As this entire process is table driven you can execute imports from development, QA or production servers without having to change connections from within your SSIS packages. Finally, a small change in business logic means a single change to our “ETL” packages, leaving the source extracts intact.
You could spiff this up a few ways; perhaps a simple GUI for package management, or a routine to run additional packages within a single data object process. Also, you could set some custom dependencies to be checked in your looping process: For example, only import Customer Ship To Locations if Customers have first been loaded successfully. Next, add some logging so you can monitor the progress. In a truly scalable enterprise solution, you’ll most likely set these up to run via SQL Server Agent; pass in the data object key and the connection string for unattended scheduled execution. Lastly, please whatever you do, lock down those configurations with some encryption, obfuscation or both.
Hopefully this has armed you with some new ideas on enterprise scale SSIS development. I wouldn’t suggest putting the extra effort into a package broker for simple one-off extracts from an Access database or Excel spreadsheet. But if you are working on enterprise scale systems, a variety of data sources and wish to centralize your business logic while reducing future maintenance, the time spent on package componentization will produce good dividends.
Load comments