

Merge
Interval
Hello dear readers. Once again here I am to talk with you about ShowPlan operators. Over the past few weeks and months, we’ve featured the ShowPlan operators that are used by SQL Server to build the query plan. If you’re just getting started with my Showplan series, you can find a list of all my articles here.
Introduction
In my last article I wrote about the Merge Join operator, and now I would like to continue with the subject “Merge” but now is time to feature another kind of merge, the Merge Interval operator.
Last week I was working, with a customer in Finland, to optimize some queries when I saw this operator in the execution plan. Because this is not very well documented, I’ll try to cover all aspects and bugs related to this operator (a.k.a. iterators).
In short, this is used to remove duplicated predicates in a query, and to find possible overlapping intervals in order to optimize these filters so as to avoid scanning the same data more than once.
As always, I completely understand that this is not as simple as I’ve just stated. You may have to read what I wrote more than three times to understand what I mean: Don’t worry about that, because I’ll go deep into this subject step by step so as to make it easier for you to understand.
Creating sample data
To illustrate the Merge Interval behaviour, I’ll start by creating one table called “Pedidos” (which means ‘Orders’ in Portuguese). The following script will create the tables and populate them with some garbage data:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
USE tempdb GO IF OBJECT_ID('Pedidos') IS NOT NULL DROP TABLE Pedidos GO CREATE TABLE Pedidos (ID INT IDENTITY(1,1) PRIMARY KEY, ID_Cliente INT NOT NULL, Quantidade SmallInt NOT NULL, Valor Numeric(18,2) NOT NULL, Data DATETIME NOT NULL) GO DECLARE @I SmallInt SET @I = 0 WHILE @I < 10000 BEGIN INSERT INTO Pedidos(ID_Cliente, Quantidade, Valor, Data) SELECT ABS(CheckSUM(NEWID()) / 100000000), ABS(CheckSUM(NEWID()) / 10000000), ABS(CONVERT(Numeric(18,2), (CheckSUM(NEWID()) / 1000000.5))), GETDATE() - (CheckSUM(NEWID()) / 1000000) SET @I = @I + 1 END GO |
Now that we have the table, we have to create two non-clustered indexes. The first uses the column ID_Cliente as a Key, including the column Valor to create a covered index to our query. And another using the column Data as a Key and including the column Valor.
|
1 2 3 4 |
CREATE NONCLUSTERED INDEX ix_ID_Cliente ON Pedidos(ID_Cliente) INCLUDE (Valor) GO CREATE NONCLUSTERED INDEX ix_Data ON Pedidos(Data) INCLUDE (Valor) GO |
Merge Interval
Now that we have the data, we can write a query to see the merge interval. The following query is selecting the amount of sales for four customers:
|
1 2 3 4 |
SELECT SUM(Valor) AS Val FROM Pedidos WHERE ID_Cliente IN (1,2,3,4) GO |
For the query above we’ve the following execution plan:
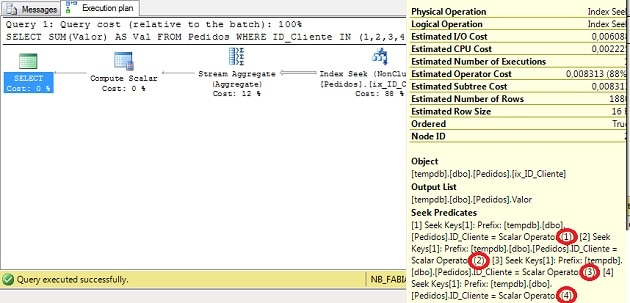
Figure 1 – Execution Plan (click on this to see it full-size)
In the execution plan above we can see that QO chose to use the index ix_ID_Cliente to seek the data for each ID_Cliente specified in the IN clause, and then uses the Stream Aggregate to perform the sum.
This is a classic Index Seek task, for each value SQL Server will read the data throw the balanced index tree searching for the ID_Cliente. For now, It doesn’t require the Merge Interval.
Now let’s looks at a similar query:
|
1 2 3 4 5 6 7 8 9 |
DECLARE @v1 Int = 1, @v2 Int = 2, @v3 Int = 3, @v4 Int = 4 SELECT SUM(Valor) AS Val FROM Pedidos WHERE ID_Cliente IN (@v1, @v2, @v3, @v4) GO |
For the query above we’ve the following execution plan:
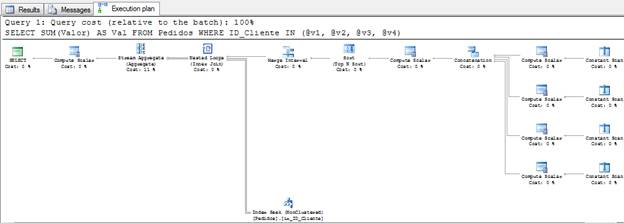
Figure 2 – Execution Plan (click on this to see it full-size)
As you can see, the only difference between the queries is that now we are using variables instead of constant values, but the Query Optimizer creates a very different execution plan for this query. So the question is: What do you think? Do you think that SQL should have used the same execution plan for this query?
The right answer is No. Why not? Because at the compile time SQL Server doesn’t know the values of the constants, and if the values turn out to be duplicates, then it will read the same data twice. Suppose that the value of the @v2 is also “1”, SQL will read the ID 1 twice, one for variable @v1 and another for variable @v2, something that we don’t expect to see since we expect performance, read the same data twice is not good. So it has to uses the Merge Interval to remove the duplicate occurrences.
Let’s wait a minute Fabiano! Are you saying that for the first query, QO automatically removes the duplicated occurrences in the IN clause?
Yes. Do want to see it?
|
1 2 3 4 |
SELECT SUM(Valor) AS Val FROM Pedidos WHERE ID_Cliente IN (1,1,3,4) GO |
For the query above we’ve the following execution plan:
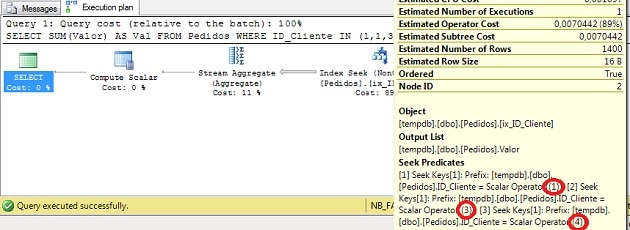
Figure 3 – Execution Plan (click on this to see it full-size)
You will see that now we only have three Seek Predicates. Perfect.
Let’s back to Merge Interval plan.
The plan is using the operators Compute Scalar, Concatenation, Sort and Merge Interval to eliminate the duplicated values at the execution plan phase.
At this time, maybe some questions are rising in your mind. First: Why SQL Server don’t just uses a DISTINCT in the IN variables to remove the joins? Second: Why this is called a “Merge”, I didn’t see anything related to a merge here.
The answer is that the Query Optimizer (QO) uses this operator to perform the DISTINCT because, with this code, the QO also recognize overlapping intervals and will potentially merge these to non-overlapping intervals that will then be used to seek the values. To understand this better let’s suppose that we have the following query that doesn’t use variables.
|
1 2 3 4 5 |
SELECT SUM(Valor) AS Val FROM Pedidos WHERE ID_Cliente BETWEEN 10 AND 25 OR ID_Cliente BETWEEN 20 AND 30 GO |
Now, let’s look at the execution plan:
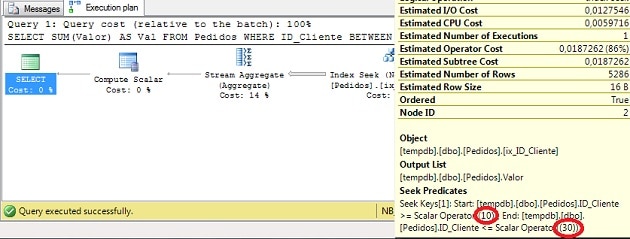
Figure 4 – Execution Plan (click on this to see it full-size)
Notice how smart the Query Optimizer was. (That’s is why I love it!) It recognizes the overlap between the predicates, and instead of doing two seeks in the index (one for each between filter), it creates a plan that performs just one seek.
Now let’s change the query to use the variables.
|
1 2 3 4 5 6 7 8 9 10 |
DECLARE @v_a1 Int = 10, @v_b1 Int = 20, @v_a2 Int = 25, @v_b2 Int = 30 SELECT SUM(Valor) AS Val FROM Pedidos WHERE ID_Cliente BETWEEN @v_a1 AND @v_a2 OR ID_Cliente BETWEEN @v_b1 AND @v_b2 GO |
For this query we’ve the following execution plan:
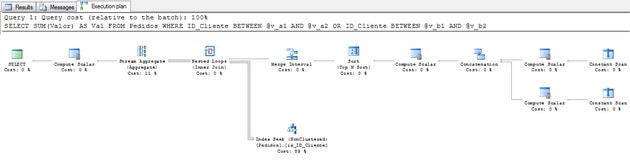
Figure 5 – Execution Plan (click on this to see it full-size)
Let’s check what the plan is doing using a different perspective. First let’s understand the overlap.
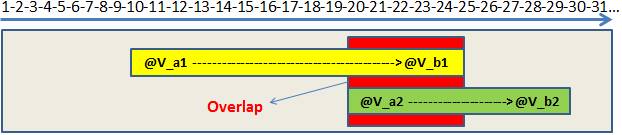
Figure 6 – Overlap between 20 and 25
In the figure 6 we can see that if SQL Server reads the ranges separately, it will read the range from 20 to 25 twice. I’ve used a small range to test with, but think in terms of a very large scan that we’d see in a production database; if we can avoid this step, then we’ll see a great performance improvement.
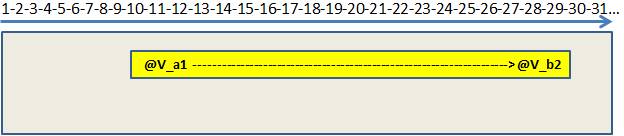
Figure 7 – After Merge Interval
After the Merge Interval runs, SQL Server can seek only the final range. It knows that is possible to go to @v_a1 to @vb_2 directly.
Finally
To finish this subject I would like to recommend you to read about a bug in SQL Server 2005 caused by a mistake in this process, you could take a better look in the blog of Mladen Prajdic a SQL Server MVP from Slovenia.
I wouldn’t miss the opportunity to congratulate the Microsoft guys that build Icons in SQL Server/Windows. I once read a book called “The Icon Book”, it was amazing how beautiful and meaningful the icons in the graphical query plan are. The Merge Interval icon is perfect, if you look at the icon you will see what it is exactly doing. Brilliant, it’s incredible how they can express something in a small picture. Well Done!
That’s all folks, I hope you’ve enjoyed learning about Merge Join operator, and I’ll see you soon with more “Showplan Operators”.





Load comments