
A number of applications can run inside a Primary Virtual Machine, which is a Virtual Machine that participates in Hyper-V Replica. Neither Hyper-V Replica nor Hyper-V are aware of what is running inside a virtual machine. Hyper-V Replica just uses its “Replication Engine” (part of Hypervisor) to replicate the changes to the “Replica Server” every 5 minutes.
There are a few applications which might not support this way of doing replication so It is not a good practice to enable replication for all virtual machines. For example, you certainly wouldn’t want to enable the replication for a virtual machine running an Active Directory Domain Controller because domain controllers already keep the exact copy of Active Directory database by utilizing their own replication mechanism. Since any domain controller available can service the authentication requests, there is no point in hosting a domain controller in Hyper-V Replica environment.
If you have not read about the Hyper-V Replica yet, I would recommend you first read this article (Hyper-V Replica article at www.simple-talk.com) which should clarify Hyper-V Replica in general, before we dive more deeply into the topic of hosting SQL Server in a virtual machine in Hyper-V Replica environment.
There is another reason not to enable the replication for all the virtual machines. Many applications need to be running all the time without any interruption if they have been configured to provide high-availability services: Hyper-V Replica cannot do that for any virtual machines configured for replication. In case of any disaster at the Primary Site, Primary Virtual Machines need to be manually turned off at the Primary Server site and switched on at the Replica Server site before the services can continue. Applications that are running with high availability configured may not like this, and application vendors may refuse to provide the necessary support. Further to this, Hyper-V Replica is a technology that is entirely focused on Disaster-recovery; In the event of a disaster at the production site, virtualized workloads are brought online at the disaster-recovery site only after manual intervention. With Hyper-V Replica, you are already achieving sufficient service continuity for the application with a little downtime. If so, there no point in hosting an application with high-availability enabled as well.
You can enable replication for all the virtual machines if it is supported by the vendor. According to Microsoft’s SQL PSS Team, Microsoft SQL Server can be supported on a Hyper-V replica so long as high availability of SQL Server is neither enabled nor used, and if SQL Server database and log files are hosted on one VHD file.
I have seen a lot of conflicting answers on the forums about whether SQL Server can be used in a Hyper-V Replica environment. This article explains how you can use SQL Server in a Hyper-V Replica environment with some limitations and what you can do so that it runs efficiently.
The following topics are discussed in the detail in this article:
- Preparations for hosting SQL Server in Hyper-V Replica environment
- Installing SQL Server 2012 in a Primary Virtual Machine
- Enabling SQL Server Primary Virtual Machine for replication
- Failover of SQL Server Primary Virtual Machine to Replica Server
Preparations for hosting SQL Server in a Hyper-V Replica environment
Before using SQL Server in a Hyper-V Replica environment you will need to be aware of the difference between the various types of backup, as this will affect the choices you make in configuring the installation:
Crash-Consistent and Application-Consistent Backup Copies
For data recovery, Hyper-V Replica provides two options for backup copies as listed below:
- Standard Replicas: This is a snapshot created with the help of VSS service for an entire virtual machine including VHD files and configuration files. The “Standard Replicas” are sometimes referred as “Crash-Consistent Backup Copies”.
- Application-Consistent Replicas: These are created with the help of Hyper-V VSS Requestor Service for applications running inside the virtual machine. This is sometimes referred to as “Application-Consistent Backup Copy”.
A simple backup of a machine is called an ‘Inconsistent backup’ because it takes place over a time period, and any large files that are being actively updated by an application whilst the backup is taking place will be in an inconsistent state. To solve this problem, all data within a crash-consistent backup set is captured at exactly the same time by means of a snapshot. The problem that this shares with the inconsistent method is that it does not save the contents of application memory or any pending I/O operations.
When using Hyper-V Replica to recover a SQL Server instance, the Primary Virtual Machine running SQL server that is hosted on the Primary Server may fail due to some problems with either the virtual machine itself or the Primary Server. When Primary Virtual Machine fails, the data loss may also occur because of the way that SQL Server writes to the databases on the local disks
Database administrators ought to understand these two types of backup copies before enabling replication for a SQL Primary Virtual Machine because they have direct repercussions for the SQL Primary Virtual Machine.
Crash-Consistent Backup Copy
A crash-consistent backup is an image of the system which has not had a chance to flush pending data in memory or pending write-out to disk. When it is restored, it will leave the data will be in the same state it would have been had the system crashed at the moment of the backup being taken. A database would have to recover any open transactions at the time to a consistent state. This would delay the recovery and add an element of risk.
When the Server that is hosting the virtual machine running a SQL Server instance is shut down unexpectedly:
- The Virtual Machine crashes unexpectedly.
- Any pending I/O operation and data in memory or any paused transactions are lost.
When you, as a SQL administrator, start up the virtual machine after such a crash. …
- SQL Server service initializes databases and log files it gets hold of.
- Since SQL Server Service does not know what happened when it was running, a soft recovery procedure is invoked to perform a recovery of the databases.
- It rolls back any uncommitted transactions, if required.
- SQL Server service starts normally.
… which is also what happens on starting the service after SQL Server service has stopped unexpectedly.
SQL Server service will almost certainly start normally, after a virtual machine or SQL Server service goes down unexpectedly, and the same is true if restored from a Crash-consistent Backup.
Application-Consistent Backup Copy
The “Application-Consistent” mechanism allows the application to put itself into a consistent state before the snapshot is taken. It uses the operating system’s VSS Service to create point-in-time snapshots of the SQL Server databases in the same way that a SQL Backup is taken. The “Application-Consistent” mechanism includes at least four components that work together in a Hyper-V environment; VSS Service on the operating system, Hyper-V VSS Writer, Application VSS Writer, and Hyper-V Integration VSS Requestor Service running inside the virtual machine.
The following steps describe the application-consistent mechanism used by the SQL Server service to capture an “Application-Consistent Backup Copy”.
Application-Consistent mechanism and steps:
- SQL Server writes its data or transactions to the memory before the data or transactions are written to the databases on local disk.
- Hyper-V VSS Writer running on the Primary Server needs to create an “Application-Consistent” snapshot for the SQL Primary Virtual Machine. This request is initiated every hour.
- The Volume Shadow Copy Service (VSS) initiates a backup or snapshot of the volumes.
- Before VSS starts the snapshot, VSS informs SQL Server VSS Writer on the operating system to flush its memory data to the disks.
- SQL Server VSS Writer receives the request and flushes any pending I/O operations or data from the memory to the disks.
- The SQL database is completely “consistent” at this stage. SQL has a good “Application-Consistent Backup Copy” and this copy can be used to recover the data in case of any disaster.
- VSS performs a routine called Copy-On-Write (COW) on all the volumes enabled for snapshotting.
- The Hyper-V VSS Requestor service running inside the virtual machine receives the request and performs a point-in-time snapshot of the volumes.
- The VSS snapshot is completed.
- VSS notifies VSS Writers of the SQL Server to resume their services normally.
- SQL Server is resumed normally.
- VSS notifies Hyper-V VSS Writer.
- Hyper-V VSS Writer receives notification and an “Application-Consistent” backup copy is saved on the local disk.
- Primary Server replicates these backup copies to Replica Server.
This will work if they are performed in a timely manner and consistent “Application-Consistent” backup copies are created before the next or subsequent snapshots are created. The “Application-Consistent” mechanism provides a number of advantages over the “Crash-Consistent” situation but there are a number of that can go wrong
- Nothing in memory should be lost as the data are flushed from memory to disks in a timely manner before the next “Application-Consistent” backup copy is created. It is up to the Application VSS Writer to decide whether it should flush the data or not. If an application is not designed to do so it is in a similar state as is the case with “Crash-Consistent”. Backup.
- It is imperative to understand that applications should register their VSS Writers (if one is available) with the operating system VSS before they can be involved in the steps defined above. If application does not have the VSS Writer then the situation is same as it occurs in case of Crash-Consistent. SQL application provides SQL VSS Writer.
- If the virtual machine closes unexpectedly or if the full set of above steps is not performed, the “Application-Consistent” backup copy is not completed. Therefore there is no guarantee of database integrity.
- Hyper-V VSS Requestor Service is not running in the Primary Virtual Machine.
- Last, and more importantly, “Application-Consistent” snapshots are created every 1 hour. So Primary Server must be able to initiate request at least once to have good “Application-Consistent” backup copy.
You saw in above steps how Hyper-V Replica helps keep a good “Application-Consistent” backup copy. This backup copy will help you maintain the database integrity if something goes wrong at the SQL Primary Virtual Machine. You can easily recover SQL Replica Virtual Machine using good backup copy. Since the Application-Consistent” backup copy is performed every 1 hour, you might loose 1 hour of data.
In a Hyper-V Replica environment, if the SQL Primary Virtual Machine goes down due to power failure of Hyper-V Primary Server or some other issues with the Primary Server, the Replica Virtual Machine will need to be brought online at the Replica site. The applications running inside the virtual machine will perform the logic I’ve just described.
Even when server, along with its SQL Server instance, has been restored to life, all data since the last Hyper-V backup will be lost. In order to recover this, and assuming the database is in full-recovery mode, then a point-in-time recovery will be needed to restore transactions up to the time of the crash. Please check out this link which explains steps to be performed for point-in-time recovery: http://technet.microsoft.com/en-us/library/ms179451.aspx
SQL Server Database and Log file location
By default, SQL Server installation configures the database data files and Log files to be stored on the same volume that SQL Server is installed on. In a virtual environment, you can configure the location of database and log files to be stored on different VHD files but before you do so, you should be aware of the impact on the SQL Server performance.
The performance of a SQL Server is affected by the location of the database and log files. Technically, there are two alternative approaches that you can follow to place database and files in a SQL Primary Virtual Machine:
- Storing Database and Log files in different volumes of a VHD file.
- Storing database and log files across multiple VHD files.
However, only the 2nd approach is supported by the Microsoft SQL PSS Team
Storing Database and Log files in different volumes of a VHD file
SQL Server databases have at least one primary database file and one transaction log file. SQL Server writes to the log files (LDF) in a sequence so as to ensure that during committing or rolling back the changes to/from database is done in the order they were logged in the transaction log file.
Writing to database (MDF) file is done in a random order.
This is what SQL Server service does when committing the changes to the databases:
- Any inserts/updates/deletes transactions are written to the log file first (LDF).
- Data is written to the actual database file (MDF).
- Finally, transactions are marked in the log file (LDF) as completed transactions.
If the MDF and LDF files are hosted on the same drive or VHD file, this would cause some performance issues because SQL Server engine performs the operations for these steps at the same time. This is because of the Disk Read/Write I/O operations occurring on the same disk at the same time. .Additionally, SQL Server will not be able to recover the data using the transactions recorded in the log file of that database if the disk hosting log file crashes.
Since Hyper-V running on Windows Server 2012 provides vNUMA functionality for the virtual machines, there will not be significant performance issues, but there will be a slight drop in the overall performance of the virtual machine hosting a SQL Server as compared to running SQL Server in a physical machine.
Storing Database and Log files across multiple VHD files
To optimize the overall I/O performance of SQL Server, it is best to host SQL database and log files on separate VHD files in a virtual environment, because the way SQL server writes transactions (inserts/updates/deletes) to both MDF and LDF files. SQL Server writes to log files in sequence to enable SQL Server to recover from crashes.
Furthermore, SQL administrators would not want to compromise with the performance of SQL Server application which is resource and/or disk intensive and they would like to have separate VHD files for storing database and log files.
Hosting database and log files location on two different VHD files in a Hyper-V Replica environment require that you take a few necessary actions. There is a flag, specifically designed for database applications, you need to set on the SQL Primary Virtual Machine to ensure replication for the VHD files which hosts database and log files happen at the “same” point-in-time.
As you know by reading from previous paragraphs, Microsoft SQL PSS Team does not provide support for SQL Servers running in a Primary Virtual Machine if the database and log files are stored on the separate VHD files. There is a reason for this. By default, replication for all VHD files does not happen at the same point-in-time. The Primary Server does not follow the write-order of an application when replicating the changes to Replica Server. There would be database integrity issues if the replication packets are processed in random orders.
To overcome this problem, Microsoft introduced a switch to be used with SQL Primary Virtual Machine. The switch makes sure that “Application-Consistent” backup copies are replicated at the same time at Primary Server. This switch ensures the Primary Server or replication to honor the write order of the SQL Server in the virtual machine instead of using the random replication order.
The switch “EnableWriteOrderPreservationAcrossDisks“ can be set on SQL Primary Virtual Machine before it is enabled for the replication. The switch settings and how to set on the Primary Virtual Machine is explained in the “Installing SQL Server 2012 in a Primary Virtual Machine” section of this article.
Always backup database using backup software which uses VSS snapshots
As you know by reading first part in this article, the Hyper-V Replica feature provides “Application-Consistent” snapshots with the help of VSS service but the “Application-Consistent” snapshots are created every 1 hour by default and this interval cannot be lesser than 1 hour. The interval is configurable up to 12 hours.
To maintain the SQL Server database integrity, you need to have at least one good copy of “Application-Consistent” snapshot which can be used at Replica Virtual Machine to bring databases online in case of any disaster at primary site. So it is recommended to perform a scheduled backup of SQL Primary Virtual Machine using the backup software of your own and do not just depend on the Hyper-V replication.
Do not enable High Availability features of SQL Server
Microsoft SQL PSS Team does not provide support for SQL virtual machine which participates in the Hyper-V replication if one of the following SQL Server high availability feature is enabled or used:
- SQL Server instances are clustered in the Virtual Machine
- AlwaysOn Availability Group on standalone instances (introduced in SQL Server 2012)
- Replication configured between SQL Server instances
- Database Mirroring configured between SQL Server instances
- Log Shipping enabled between SQL Server instances
There is a reason for imposing this limitation.
To achieve high availability, two or more instances need to communicate to keep the the SQL Server instances or databases in Sync. In a virtualization environment, clustering SQL Server instances always include two or more virtual machines. These virtual machines are configured with the Windows Failover Clustering feature and SQL Server instance is installed as a cluster resource. If the two SQL Primary Virtual Machines are clustered with Windows Failover Clustering feature, then SQL high availability feature must be removed and reconfigured after the failover.
Furthermore, Hyper-V Replica is very much a Disaster-Recovery technology rather than a way of achieving high availability. There is no point to having high availability of an application running inside the Primary Virtual Machine. If you need to enable high availability for SQL Server then I would recommend you configure an Always On Availiability group
SQL Server running in a Primary Virtual Machine-try it and see.
Microsoft developers have improved the way that SQL Server recovers from a crash. Even so, it is necessary to take a cautious approach by testing it in your setting. If your SQL Server running in a Replica Virtual Machine is always able to successfully bring the database online then you do not need to worry!
The crash-situation scenarios explained above may also occur when SQL Server is running on a physical machine. So there shouldn’t be any issues if SQL Server runs in a virtual machine. I, personally, have not seen any issues with SQL Server running on a recent operating system such as Windows Server 2008 R2 and Windows Server 2012 in a virtual machine.
Installing SQL Server 2012 in a Primary Virtual Machine
The primary focus of this article is to explain how SQL Server 2012 works in a Hyper-V Replica environment and what all items to take into consideration before enabling replication for SQL Primary Virtual Machine. I’m therefore assuming that you have a set up aready that includes:
- A Primary Hyper-V Server Windows Server 2012 with Hyper-V role enabled
- A Replica Hyper-V Server running Windows Server 2012 with Hyper-V role enabled
- A Primary Virtual Machine running on the Primary Server
- Hyper-V networking set up correctly, with the firewall rules for Hyper-V Replica are enabled
There are 4 VHD files required for SQL Primary Virtual Machine if you are going to host SQL Server database and log file across multiple VHD files as shown in the figure 1 below: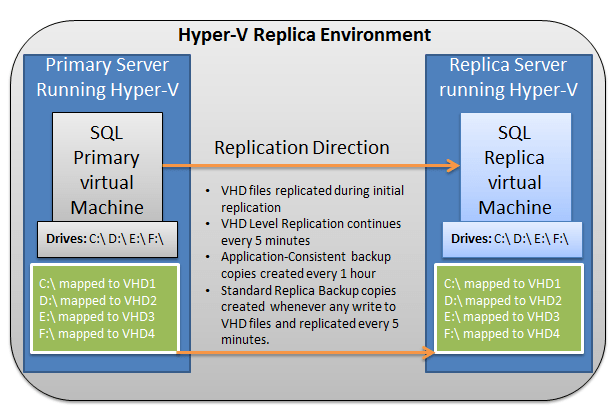
You’ll see that VHD1 will be used to store operating system files, VHD2 to store SQL Server databases, VHD3 to store SQL Server log or transaction files, and VHD4 will be used to store the operating system paging file.
If you replicate the paging file of a virtual machine, it will use more bandwidth unnecessarily. For that reason, paging file must be stored on a separate hard drive (VHD4) and excluded from the Hyper-V replication.
The SQL Primary Virtual Machine is set up in production or primary site and will be servicing client requests over the network. In case of any disaster at primary site, an administrator needs to bring SQL Replica Virtual Machine online at the disaster recovery site or replica site as shown in the figure 1 above.
VHD files, as indicated in figure 1 above, will be replicated to SQL Replica Virtual Machine during initial replication and continue to replicate the changes to SQL Replica Virtual Machine every 5 minutes. The Primary Server will also assist in creating “Application-Consistent” snapshots every 1 hour and those replicated to Replica Server. “Application-Consistent” snapshots or backup copies can be used to recover SQL Server databases in case if something goes wrong at SQL Primary Virtual Machine. Only a backup will enable you to get a point-in-time recovery. With an “Application-Consistent” snapshot for recovery, you would lose all the data since the previous snapshot.
If you’re not familiar with any of the above terms or using Hyper-V Replica for the first time, I would recommend that you read more about these terms in an article published specifically for Hyper-V Replica at www.simple-talk.com. Please use the installations and configuration steps highlighted in the article to enable Hyper-V Replica on Primary and Replica Servers.
I will be highlighting what all options you must select during the installation wizard so SQL Server installation in Hyper-V Replica environment becomes supported and it becomes easy for you to raise a ticket with the Microsoft SQL PSS Team in case of any issues. The installation explained here is same as other SQL server installation. The only difference you find is that “SQL Server Replication” is not selected and installed. There are other necessary steps to follow after the SQL installation is over which are outlined at the end of this section in this article.
Since we will use Hyper-V replication to replicate the contents of the virtual machine, we will install SQL Server in the Primary Virtual Machine as a standalone instance.
- Before you begin with the SQL installation, please make sure to have the following requirements in place for SQL Server 2012:
- .NET 3.5 SP1 is a requirement for Database Engine which you select during the installation. SQL Server 2012 setup process does not install this component any longer.
- .NET 4.0 is required for the SQL Server 2012 which is installed during the feature installation setup.
- Windows PowerShell 2.0
- Internet Explorer Version 7.0 or later is recommended.
- Configure Windows Firewall to allow SQL Server access. For more information, please check here: http://msdn.microsoft.com/en-us/library/cc646023(v=sql.110).aspx
Note The minimum supported server operating system for installing SQL Server 2012 is Windows Server 2008 R2 with Service Pack 1 or Windows Server 2012.
To begin the SQL Installation process, double-click on the Setup.exe to lunch the installation screen as shown in the figure 1 below:

Figure1 – SQL Server Installation Center
Click on the “New SQL Server stand-alone installation or add features to an existing installation” in the right-hand pane to begin the installation.
Click “Next” for SQL Server setup to verify the Setup Support Rules as mentioned in below figure.
Figure1.1 – Setup Support Roles
In next screen, SQL Server setup checks for any updates. You can click on “Skip Scan” if Primary Virtual Machine cannot access the internet as shown in the below figure.
Figure 1.2 – SQL Server Product Update
Verify the “Setup Support Roles” and check for any error or warning messages as shown in the below figure. You can ignore the warnings for “Windows Firewall” and “Microsoft Application .NET security”. Once the SQL Server installation is over, you must configure the Windows Firewall to allow SQL Server to access different components using local RPC.
“Microsoft Application .NET security” is shown if you do not have Internet access from the virtual machine. The setup connects to CRL.Microsoft.com to perform a check on signature of .NET libraries.
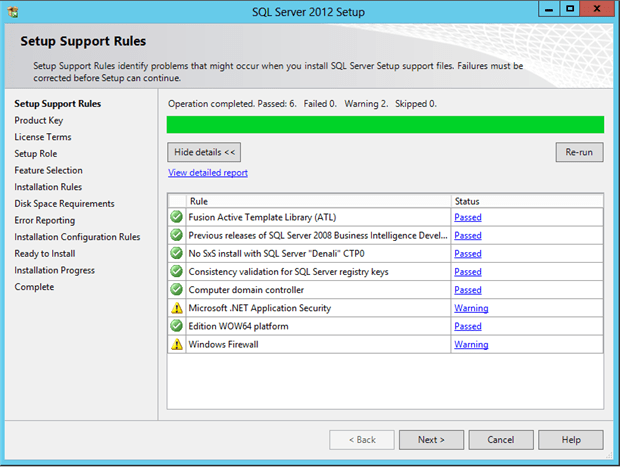
Figure 1.3 – Setup Support Roles
In the next screen, select SQL Server edition. I have selected Evaluation Edition here. You can convert Evaluation Edition to Licensed version after installation is over.
Figure 1.4 – Selecting SQL Server Production Edition
Accept SQL Server licensing and click on “Next” to proceed.
Figure 1.5 – Accepting License Terms
Please make sure “SQL Server Feature Installation” is selected in the below screen and then click “Next”.
Figure 1.6 – Setup Roles for the SQL Server
At this point of time, you should be able to select the features you would like to install as part of the SQL installation. Please note we are not going to select “SQL Replication” as shown in the below figure. We can select all other features we need.
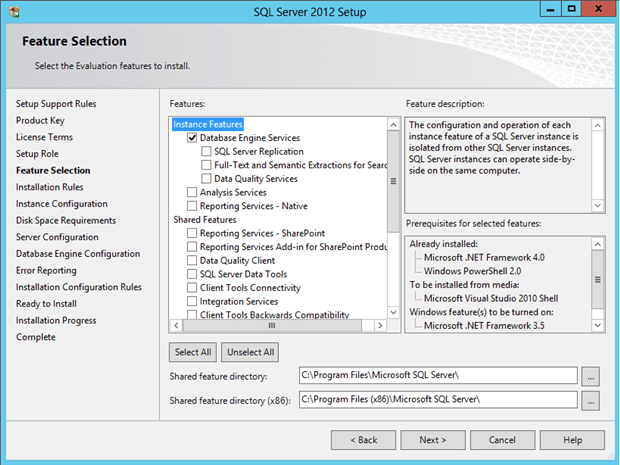
Figure 1.7 – Feature Section during SQL Server Installation
In the next screen, SQL setup will create a SQL Server instance. You can change the SQL Server instance here if you want or leave it as default.
Figure 1.8 – SQL Server Instance Configuration
When you click “Next” in the instance configuration screen, SQL Server setup will check available disk space to install the features you selected during the “Feature Selection” page.
Figure 1.9 – SQL Server Disk Space Requirement
SQL Server setup works differently from the previous versions. SQL Server 2012 setup uses already created user accounts for running various SQL Services. I would recommend that you leave it to default values and proceed next.
Figure 1.10 – SQL Server configuration Screen
In the next screen, please select how SQL Server is going to work with authentication models. There are two types of authentication available; Windows Authentication and Mixed Authentication. Select the authentication type here and click on “Add Current User” account which will add the currently logged in user account to the list to make it as a SQL Admin account.
Figure 1.12 – SQL Server Database Engine Configuration and Specifying SQL Account
Enable or disable Microsoft reporting for the SQL Server in next page and then click “Next” proceed further.
Figure 1.13 – SQL Server Error Reporting Configuration
Next, Setup will check to see if installation will succeed or will be blocked.
Figure 1.14 – Installation Configuration Rules
The “Ready to Install” page then informs you of all the features that have been selected and will be processed by SQL Setup for installation.
Figure 1.15 – SQL Server “Ready to Install” Screen
Figure 1.16 – SQL Server Installation Progress
Once the SQL Server is installed successfully in the Primary Virtual Machine, please follow these following steps to make it ready for Hyper-V replication:
1: Configuring Database and Log file location
Once the SQL installation is over, you can create and configure the databases. Since we are going to host databases across multiple VHD files, please select VHD2 for any new databases that you create as the destination location for MDF file and VHD3 as the destination location for LDF file. There are two ways you can use to relocate existing database and log files; using SQL Management Studio or using SQL Detach & Attach command.
Using SQL Management Studio, please use the steps outlined at http://msdn.microsoft.com/en-IN/library/ms190209.aspx
Note: Relocating existing database using SQL Management Studio would require a restart of the SQL Server service.
You can also use Detach and Attach SQL command to relocate existing databases and log files to VHD2 and VHD3 respectively. There is no need to restart the SQL Server service if you use this method. Please check out here for more information: http://msdn.microsoft.com/en-IN/library/ms187858.aspx
2: Configuring EnableWriteOrderPreservationAcrossDisks switch
The command syntax for the switch is as follows:
|
1 |
Set-VMReplication -VMName <VM-Name> -EnableWriteOrderPreservationAcrossDisks 1 |
Note: Replace the <VM-Name> with the name of SQL Primary Virtual Machine.
There are two settings you can use with “EnableWriteOrderPreservationAcrossDisks”:
- “1” which is equivalent to “True” can be set to honor write order of the SQL Server application.
- “2” which is equivalent to “False” can be set to create “Application-Consistent” backup changes randomly
This switch is not specifically designed for SQL Server but for applications which need to override the write-order of Hyper-V Replication for “Application-Consistent” backup copies. This switch has nothing to do with the “Standard Replica” backup copies which are created for entire virtual machine.
3: Relocating paging file to VHD4
It makes no sense to replicate paging file to SQL Replica Virtual Machine. By default, paging file is hosted on the operating system drive (VHD1). It is necessary to relocate the paging file to VHD4 to avoid unnecessary replication.
Once the paging file is relocated to VHD4, please proceed with next sections of this article which includes enabling Hyper-V replication for SQL Primary Virtual Machine and excluding the paging file from replication.
Enabling SQL Server Replica Virtual Machine for replication
Once the SQL Server 2012 is installed in a Primary Virtual Machine, it is time to configure it for replication. To enable the replication for Primary Virtual Machine, check out section “Enabling Replication for Primary Virtual Machine” in the article published at simple-talk.com.
Please follow the steps provided in above article to exclude paging file from replication.
Failover of SQL Primary Virtual Machine to Replica Server
Please explore different types of failover available in Hyper-V Replica in this article published at www.simple-talk.com. Please note that it is completely unnecessary to use the recovery points provided during the failover process. It is up to you to decide if you want to recover the SQL Replica Virtual Machine from a recovery point maintained by Hyper-V Replica or restore from a backup which you have taken already and you think it is a good backup which will bring the databases online.
Conclusion
This article primarily focused on how to setup a SQL Server in a Hyper-V Replica environment and on the decisions you need to take to ensure recovery from a crash. We learned how SQL Server is intrinsically designed to recover from database disasters. We also learned about crashes which may occur in the Hyper-V Replica Environment and how Standard Replica and Application-Consistent backup copies assist to recover the complete Replica Virtual Machine or applications running inside it respectively.
Some important items were also highlighted in the article so that SQL Administrators do not completely depend on the Standard Replica and Application-Consistent backup copies provided by Hyper-V Replica but to perform backups in a timely manner to avoid any big impact on the database.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments